Travaux pratiques - Fouille de réseaux sociaux, première partie¶
Environnement de travail¶
Vous trouverez ici une variante de ce TP utilisant le langage Python.
Si vous êtes inscrit au Cnam, vous avez accès au serveur JupyterHub en passant par votre espace numérique de formation. Une fois sur la page du cours, cliquez sur le lien « Accès à JupyterHub ». Vous serez automatiquement authentifié sur votre espace Jupyter personnel hébergé sur les serveurs du Cnam. Votre répertoire personnel est préservé tant que vous êtes inscrit à au moins un cours.
Une fois sur cette interface, vous pouvez y importer la version Jupyter du TP que vous aurez préalblement téléchargée en cliquant sur le bandeau en haut de cette page. Lorsque cela vous est demandé, choisissez le noyau « Apache Toree - Scala ».
Il est possible d’installer Spark et Jupyter sur votre machine personnelle en suivant ces instructions d”installation. Vous pouvez nous signaler les éventuelles difficultés rencontrées (après avoir quand même cherché vous-même des solutions dans des forums sur le web). Une fois installé, vous pouvez démarrer Jupyter puis y accéder à l’URL http://localhost:8888/.
Il est possible d’installer Spark et Zeppelin sur votre machine personnelle en suivant ces instructions d”installation. Vous pouvez nous signaler les éventuelles difficultés rencontrées (après avoir quand même cherché vous-même des solutions dans des forums sur le web). L’utilisation d’un système d’exploitation Linux ou MacOS est recommandée (mais il est possible d’effectuer l’installation sous Windows). Une fois installé, Zeppelin est accessible à l’URL http://localhost:8080/.
Si vous êtes inscrit au Cnam, vous avez accès au serveur Zeppelin RCP216 du département informatique: https://zeppelin.kali-service.cnam.fr. Vous pouvez vous y connecter à l’aide de vos identifiants Siscol. Vos identifiants sont formés de votre nom de famille (max. 6 caractères) et de la première lettre de votre prénom, séparés par un underscore _. Par exemple, pour Jeanne Dupont, l’identifiant Siscol associé serait : dupont_j.
Lorsque vous importez le cahier dans Zeppelin, indiquez comme nom votreidenfiant/lenomduTp, par exemple dupont_j/tpDonneesNumeriques. Cela permettra de regrouper vos TP dans un dossier à votre nom.
Références externes utiles :
Introduction¶
Depuis quelques dizaines d’années, des chercheurs de disciplines aussi variées que les neurosciences, la sociologie, ou les sciences politiques se sont aperçus qu’ils partageaient le besoin de comprendre finement des relations entre différentes entités organisées en réseaux (portions cérébrales, individus, institutions, etc.). Grâce à des collaborations avec des chercheurs en mathématiques et informatique, il est devenu peu à peu évident que les techniques utilisées dans chaque domaine pouvaient s’appliquer aux autres : le champ de la network science était né.
Cette dernière repose sur les outils de la théorie des graphes, branche des mathématiques née au XVIIIe siècle avec Euler et le problème des sept ponts de Königsberg. Celle-ci se concentre sur l’étude des propriétés d’objets particuliers, les graphes, composés d’entités (représentés par des noeuds ou des sommets) qui sont mises en relation (par des liens ou des arêtes). La théorie des graphes a également, comme on le voit dans le cours, des applications multiples en informatique, du routage dans l’Internet aux systèmes de recommandations, en passant par le PageRank (à l’origine de Google) et les réseaux sociaux.
Dans ces deux séances de travaux pratiques, nous allons étudier une librairie de Spark appelée GraphX, qui étend les fonctionnalités de Spark avec des algorithmes parallélisés pour traiter les problèmes de graphes. Bien qu’elle ne soit pas forcément la plus rapide comparée à certains frameworks dédiés aux graphes, elle présente l’avantage de fonctionner au sein de Spark et en rend l’utilisation d’autant plus facile. On peut ainsi combiner, comme on va le faire, des traitements classiques et des traitements spécifiques aux graphes sous-jacents dans nos données.
Objectif du TP¶
Nous allons travailler sur des articles scientifiques, décrits par des mots-clefs (ou tags) et étudier le graphe de ces tags (qui seront reliés si un ou plusieurs articles les possèdent en commun). Notre but sera de comprendre la structure et les propriétés du graphe. Dans cette première partie, nous allons commencer par une analyse simple des sujets principaux des articles et de leurs co-occurrences, ce qui ne nécessitera pas le recours à GraphX. On recherchera ensuite les composantes connexes, pour voir si les citations forment des petits groupes ou si, au contraire, elles sont toutes reliées. Nous aborderons ensuite la question de la distribution des degrés dans le graphe. Dans la séance de travaux pratiques de la semaine prochaine, nous poursuivrons notre exploration de ce graphe.
Description des données¶
Nous allons récupérer des données textuelles issues d’une base de données de publications scientifiques spécialisées en médecine et sciences du vivant, MEDLINE. Celle-ci est gérée par l’équivalent américain de l’INSERM, la NIH. La base disponible en ligne depuis 1996 et contient plus de 20 millions d’articles. En raison du volume important et de la fréquence élevée des mises à jour, la communauté scientifique a développé un ensemble de tags sémantiques appelé MeSH (Medical Subject Headings), appliqué à toutes les citations de l’index. Ils permettent donc d’étudier les relations entre les documents, afin de faciliter le processus de revue par les pairs et la recherche d’information.
Nous utilisons dans la suite un sous-ensemble des données de citations de MEDLINE et allons étudier le réseau des tags MeSH (restreints à ceux considérés comme « principaux »). Plus précisément, le graphe que nous allons construire aura pour sommets les tags MeSH principaux. On placera une arête entre deux sommets lorsqu’ils seront apparus simultanément comme des tags MeSH principaux dans un même article (on parle de « co-occurence »). La figure Le graphe support du TP illustre la construction de ce graphe. Les mots-clefs en rouge sont les tags MeSH principaux. La présence de « AAA », « BBB » et « CCC » comme tags dans l’article 1 induit la présence de 3 arêtes : (AAA - BBB), (BBB - CCC), (AAA - CCC). Dans cette première partie du TP, on ne tiendra pas compte de la présence de l’arête (BBB - CCC) dans l’article 2 (mais on reviendra sur ce phénomène dans la deuxième partie).
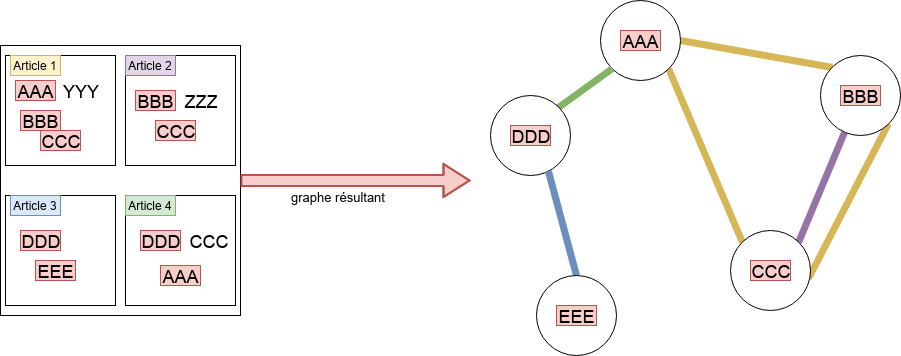
Le graphe support du TP¶
Démarche générale du TP¶
Voici les grandes étapes :
récupération des données (archives, contenant des fichiers XML)
chargement des données, comme chaînes de caractères, puis XML
filtrage, extraction des séquences de tags MeSH
création du RDD de sommets, création du RDD d’arêtes, obtention du graphe
La figure Séquence des RDD utilisés dans le TP illustre les séquences de RDD utilisés dans ces chaînes de traitements (cliquer dessus pour mieux lire les légendes, au besoin).
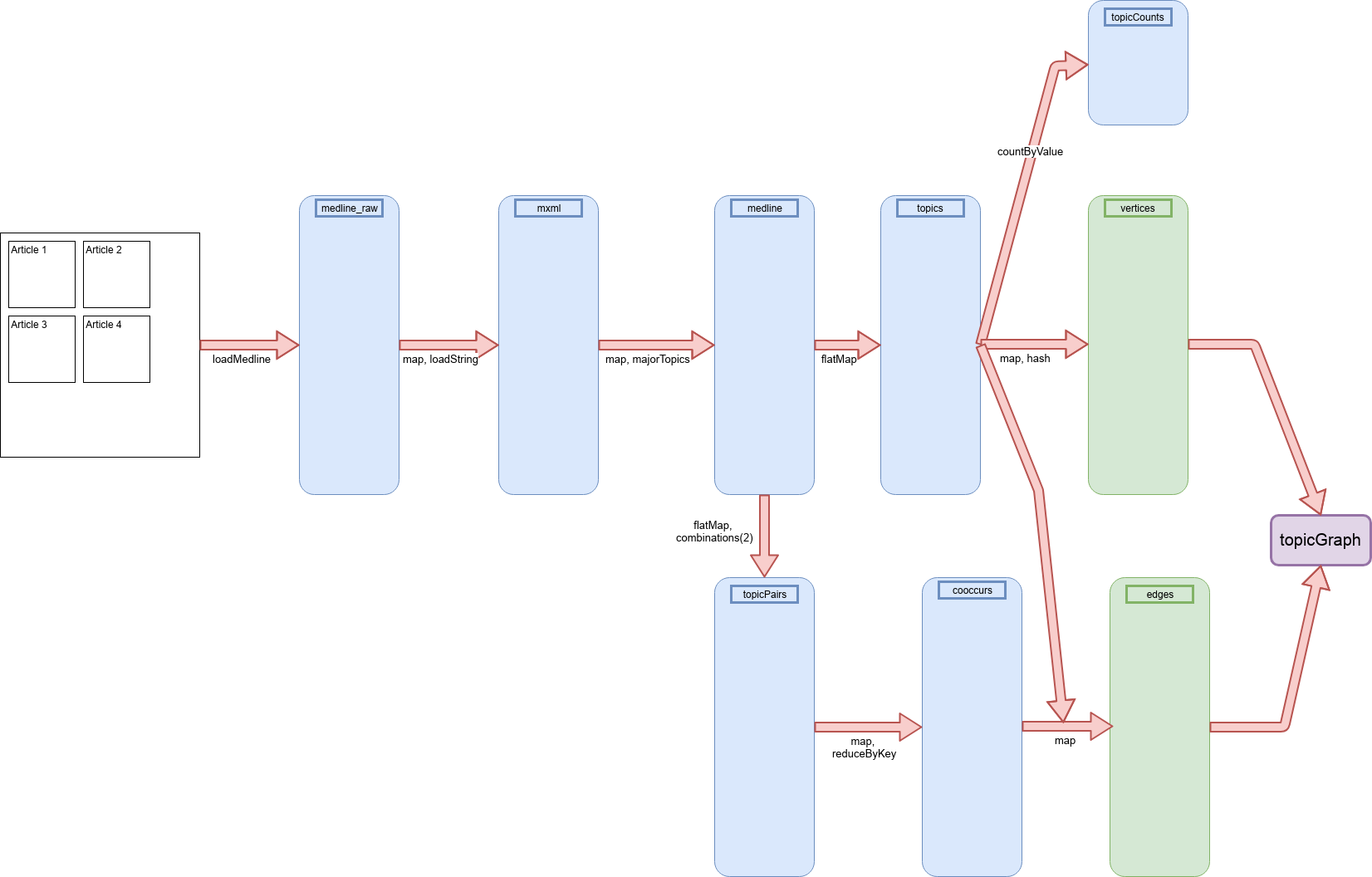
Séquence des RDD utilisés dans le TP¶

Séquence des RDD utilisés dans le TP¶
Récupération des données¶
On va récupérer quelques fichiers contenant des échantillons de l’index des citations sur le serveur FTP du NIH.
Note
Avec les notebooks Zeppelin du CNAM, la commande de téléchargement est à diviser en plusieurs étapes. Et le chemin vers les fichiers change.
%%bash
mkdir -p tpgraphes/medline_data
cd tpgraphes/medline_data
wget ftp://ftp.nlm.nih.gov/nlmdata/sample/medline/*.gz
Décompressons les fichiers et regardons leur taille.
%%bash cd tpgraphes/medline_data gunzip *.gz ls -ltr
Après décompression, il y a en tout près de 900 Mo de données au format XML.
Regardez les données, avec un éditeur de texte (comme kwrite ou gedit
par exemple). Chaque entrée est une notice, appelée MedlineCitation, qui
contient les informations relatives à la publication de l’article, telles que :
le nom du journal, le numéro, la date, les noms des auteurs, et un ensemble de
mots-clefs MeSH. Chacun de ces mots a un attribut pour dire s’il s’agit d’un
sujet principal (MajorTopic, en anglais) de l’article, ou d’une
thématique secondaire. Dans l’exemple ci-dessous, Intelligence n’est pas un
majorTopic, à l’inverse de Maternal-Fetal Exchange. Remarquez au
passage que nous parlons de « mots-clefs MESH », mais qu’un mot-clef peut être
en fait composé de plusieurs termes.
<MedlineCitation Owner="PIP" Status="MEDLINE"> <PMID Version="1">12255379</PMID> <DateCreated> <Year>1980</Year> <Month>01</Month> <Day>03</Day> </DateCreated> ... <MeshHeadingList> ... <MeshHeading> <DescriptorName MajorTopicYN="N">Intelligence</DescriptorName> </MeshHeading> <MeshHeading> <DescriptorName MajorTopicYN="Y">Maternal-Fetal Exchange</DescriptorName> </MeshHeading> ... </MeshHeadingList> ... </MedlineCitation>
Lors du TP sur la fouille de texte, nous étions intéressés à l’étude du texte non structuré. Ici, nous allons examiner les valeurs contenues dans le champ DescriptorName en parsant le XML directement. Scala fournit un très bon support d’XML, nous allons en profiter.
Retrouvez le fichier lsa.jar du TP sur la fouille de texte (récupérez-le
avec la dernière commande de ce bloc), copiez-le dans le dossier
tpgraphes (ou retéléchargez-le avec la commande ci-dessous):
%%bash cd tpgraphes wget http://cedric.cnam.fr/~ferecatu/RCP216/tp/tptexte/lsa.jar
Vous pouvez ensuite lancer le spark-shell avec le jar lsa, comme ceci :
spark-shell --driver-memory 1g --jars lsa.jar
Avec Spark, on commence par importer les paquetages nécessaires :
import com.cloudera.datascience.common.XmlInputFormat import org.apache.spark.SparkContext import scala.xml._ import org.apache.hadoop.io.{Text, LongWritable} import org.apache.hadoop.conf.Configuration import org.apache.spark.rdd.RDD
Puis, on crée une fonction chargée d’extraire les entrées dans les fichiers
XML contenus dans le dossier medline_data.
Vous devez pour cela utiliser le chemin absolu de ce dossier sur votre machine, que vous pouvez récupérer avec la commande suivante :
%%bash echo ~/tpgraphes/medline_dataVous devriez pouvoir copier-coller (avec le clic-molette) le chemin obtenu dans la commande ci-dessous, après le
file://(il devrait donc y avoir 3/consécutifs).
def loadMedline(sc: SparkContext, path: String) = {
@transient val conf = new Configuration()
conf.set(XmlInputFormat.START_TAG_KEY, "<MedlineCitation ")
conf.set(XmlInputFormat.END_TAG_KEY, "</MedlineCitation>")
val in = sc.newAPIHadoopFile(path, classOf[XmlInputFormat], classOf[LongWritable], classOf[Text], conf)
in.map(line => line._2.toString)
}
// changer le chemin dans la commande ci-dessous
val medline_raw = loadMedline(sc, "file:///home/licencep/tpgraphes/medline_data")
Regardez ensuite ce que vous avez récupéré dans medline_raw.
val raw_xml = medline_raw.take(1)(0)
val elem = XML.loadString(raw_xml)
Avec Scala, la manipulation de l’arbre XML est assez aisée. L’opérateur « \ » permet d’obtenir les enfants directs d’un nœud par leur nom. Les enfants indirects ce sera avec « \\ ». Essayez avec :
elem \ "MeshHeadingList" (elem \\ "DescriptorName").map(_.text)
On va donc, une fois ce mécanisme compris, pouvoir récupérer les sujets principaux des articles avec la fonction suivante :
def majorTopics(elem: Elem): Seq[String] = { val dn = elem \\ "DescriptorName" val mt = dn.filter(n => (n \ "@MajorTopicYN").text == "Y") mt.map(n => n.text) } majorTopics(elem)
Appliquons-la à toutes nos données et extrayons les sujets. Attention, le bloc est assez long à exécuter, en raison de l’évaluation paresseuse de Spark.
val mxml: RDD[Elem] = medline_raw.map(XML.loadString) val medline: RDD[Seq[String]] = mxml.map(majorTopics).cache() val medline_count = medline.count() val topics: RDD[String] = medline.flatMap(mesh => mesh) topics.take(10)
Co-occurrences des sujets principaux de MeSH¶
Nous avons maintenant extrait les tags MeSH des données MEDLINE, nous allons commencer par calculer quelques statistiques simples, comme le nombre d’enregistrements et un histogramme des fréquences des sujets principaux.
val topicCounts = topics.countByValue() val topiccounts_size = topicCounts.size println(s"Taille de topicCounts : ${topiccounts_size}\n") val tcSeq = topicCounts.toSeq tcSeq.sortBy(_._2).reverse.take(10).foreach(println)
Nous cherchons ici les co-occurrences des sujets principaux. Chaque entrée de
medline est une liste de chaînes de caractères qui sont les sujets attribués à
chaque article. Il nous faut donc générer tous les sous-ensembles de deux
éléments de ces listes. Pour cela, Scala nous fournit heureusement une méthode
appelée combinations, qui permet d’obtenir le résultat escompté. Voici, sur
un exemple simple, comment utiliser cette méthode :
val list = List(1, 2, 3) val combs = list.combinations(2) combs.foreach(println)
On doit cependant se méfier : les listes retournées par combinations tiennent compte de l’ordre des éléments, et deux listes comportant les mêmes éléments dans le désordre ne sont pas égales :
val combs = list.reverse.combinations(2) combs.foreach(println) List(3, 2) == List(2, 3)
Il faudra donc que l’on s’assure que les listes de sujets sont triées avant d’appeler combinations, d’où le sorted ci-dessous.
val topicPairs = medline.flatMap(t => t.sorted.combinations(2)) val cooccurs = topicPairs.map(p => (p, 1)).reduceByKey(_+_) cooccurs.cache() cooccurs.count()
Question :
Quel est le nombre total de co-occurrences possible ? Combien en obtenez-vous ?
Regardons quelles sont les paires les plus fréquentes :
val ord = Ordering.by[(Seq[String], Int), Int](_._2) cooccurs.top(10)(ord).foreach(println)
Construction d’un graphe de co-occurrences avec GraphX¶
Les outils standard d’analyse nous fournissent donc pour l’instant assez peu d’informations sur les relations entre les mots-clefs. Les paires qui apparaissent le plus (ou le moins fréquemment) sont souvent celles qui nous importent le moins. On va donc maintenant changer de paradigme de penser et voir les différents sujets comme les sommets d’un graphe, et l’existence d’un article comportant deux sujets nous permettra d’établir une arête entre ces deux sujets. On pourra ainsi calculer des métriques orientées graphes et mieux comprendre la structure du réseau.
On utilise pour cela GraphX, qui requiert l’emploi d’un Long pour identifier chacun des sommets de notre graphe. Comme nous disposons pour le moment seulement de chaînes de caractères, une façon simple d’obtenir une valeur unique pour chacune est d’utiliser une fonction de hachage (ce qui présente l’avantage de pouvoir être fait en distribué).
On travaille avec un graphe relativement petit pour le moment (environ 13 000 sujets), donc la probabilité de collision est encore assez faible avec 32 bits (mais elle est de 70% pour 100 000 noeuds). On va donc utiliser du 64 bits, en important une librairie fournie par Google :
import com.google.common.hash.Hashing def hashId(str: String) = { Hashing.md5().hashString(str).asLong() }
On crée les listes d’identifiants et on vérifie l’unicité pour être sûrs de l’absence de collisions.
val vertices = topics.map(topic => (hashId(topic), topic)) vertices.take(5) val uniqueHashes = vertices.map(_._1).countByValue() val uniqueTopics = vertices.map(_._2).countByValue() println(s"egalité des tailles de uniqueHashes et uniqueTopics: ${uniqueHashes.size == uniqueTopics.size}\n")
On peut ensuite créer le graphe :
import org.apache.spark.graphx._ val edges = cooccurs.map(p => { val (topics, cnt) = p val ids = topics.map(hashId).sorted Edge(ids(0), ids(1), cnt) }) val topicGraph = Graph(vertices, edges) topicGraph.cache()
L’API de GraphX s’est occupée de convertir les RDD standards en VertexRDD et EdgeRDD nécessaires, sans que l’on ait besoin d’enlever les doublons.
Vous pouvez regarder :
topicGraph.vertices.count()
Comprendre la structure du graphe¶
Composantes connexes¶
Une des choses éléentaires à regarder sur un graphe pour commencer d’en comprendre la structure est de regarder sa connexité. Dans un graphe connexe, il est possible d’atteindre un sommet depuis n’importe quel autre en suivant un chemin (une séquence de sommets). Si le graphe n’est pas connexe, il est divisé en plusieurs composantes connexes, des sous-parties du graphes qui sont connexes, que l’on peut examiner individuellement. La connexité étant une propriété importante, GraphX fournit une méthode directement.
val connectedComponentGraph: Graph[VertexId, Int] = topicGraph.connectedComponents()
Les objets retournés ici sont de type Graph.
Voici une méthode pour les trier par taille.
def sortedConnectedComponents(connectedComponents: Graph[VertexId, _]): Seq[(VertexId, Long)] = { val componentCounts = connectedComponents.vertices.map(_._2).countByValue componentCounts.toSeq.sortBy(_._2).reverse }
On peut maintenant examiner notre graphe et ses composantes connexes, d’abord leur nombre puis la taille des 10 plus grandes.
val componentCounts = sortedConnectedComponents( connectedComponentGraph) //componentCounts.size println(s"nombre de composantes connexes: ${componentCounts.size}\n") componentCounts.take(10).foreach(println)
Question :
Qu’observez-vous ? Qu’en concluez-vous ?
Distribution de degrés¶
Un graphe connecté peut prendre des formes multiples (étoile, boucle géante). On essaie d’aller plus loin sur la compréhension du réseau de tags, en examinant la distribution de degrés, c’est-à-dire le nombre de sommets qui sont de degré \(n\) pour \(n\) entier.
val degrees: VertexRDD[Int] = topicGraph.degrees.cache() degrees.map(_._2).stats()
Commentez les résultats.
Question :
Il y a une différence entre le count obtenu ici et le nombre de sommets calculé auparavant, pourquoi ?
Nœuds de fort degré¶
Il y a des noeuds de fort degré, on se donne la méthode suivante pour trouver leurs noms.
def topNamesAndDegrees(degrees: VertexRDD[Int], topicGraph: Graph[String, Int]): Array[(String, Int)] = { val namesAndDegrees = degrees.innerJoin(topicGraph.vertices) { (topicId, degree, name) => (name, degree) } val ord = Ordering.by[(String, Int), Int](_._2) namesAndDegrees.map(_._2).top(10)(ord) }
On utilise cette méthode sur nos données :
topNamesAndDegrees(degrees, topicGraph).foreach(println)
On retrouve les termes les plus fréquents, ils sont aussi les plus connectés. On pourrait ensuite filtrer ces noeuds de très fort degré (connectés à tout le monde, ils n’apportent que peu d’information), et observer si la structure du graphe reste la même, si la composante connexe géante se désagrège petit à petit, ou s’il y a un moment où l’on a enlever suffisamment de noeuds et que la structure actuelle disparaît.
Avertissement
Ce sujet de TP se prolonge dans la séance Travaux pratiques - Fouille de réseaux sociaux, deuxième partie.
Bibliographie¶
Karau, H., A. Konwinski, P. Wendell et M. Zaharia, Learning Spark, O’Reilly, 2015.
Ryza, S., U. Laserson, S. Owen and J. Wills, Advanced Analytics with Spark, O’Reilly, 2010.
Large-Scale Structure of a Network of Co-Occurring MeSH Terms: Statistical Analysis of Macroscopic Properties, by Kastrin et al. (2014),
% vim: set fdm=marker fmr=<<<,>>> fdl=0: