La « vélocité » est un des multiples V qui caractérisent les données massives. Dans de nombreux cas, de nouvelles données arrivent sous forme de flux et doivent être traitées dans des délais cohérents avec le(s) flux. Cela impose de nouvelles exigences sur la latence des opérations de construction de modèle ou de prise de décision grâce à un modèle. Par latence on entend ici l’intervalle de temps entre le moment où le traitement démarre (en général, cela correspond au moment où les données deviennent disponibles) et le moment où il se termine.
Par flux on entend en général une succession de données de même type, qui arrivent à intervalles constants ou variables. Pour être traitées, ces données peuvent être découpées en « tranches » (slices), soit à partir des intervalles d’arrivée des données, soit à partir de contraintes liées au traitement (intervalles de durée fixée, tranches de volume fixé, etc.).
On peut considérer que les traitements réalisés avec des données en flux sont synchrones (« continus ») ou asynchrones. Les traitements synchrones doivent être réalisés en « temps réel » ou, du moins, leur latence doit être compatible avec le rythme du flux. Un premier type de traitement synchrone consiste à appliquer régulièrement sur les données du flux un modèle existant, pré-estimé, afin de caractériser l’évolution du flux. Dans un second type de traitement synchrone, on estime (ou on met à jour) un modèle régulièrement sur les données du flux, en général sur les dernières tranches ; ce modèle est ensuite appliqué aux données du même flux (par ex. de la tranche suivante) ou d’un autre flux. Lorsqu’elle est faite à partir de données en flux, la modélisation doit être incrémentale : il faut pouvoir mettre à jour le modèle existant sans avoir à le ré-estimer complètement (avec toutes les données accumulées) car le coût de traitement de toutes ces données serait excessif.
Les traitements asynchrones répondent à des demandes uniques ou peu fréquentes et non synchronisées avec le rythme du flux ; ils sont appliqués soit à la totalité des données du flux (si celles-ci ont été stockées et si le coût est acceptable), soit à des « résumés » (synthèses) génériques ou plus ciblés de ces données. Ces traitements peuvent être coûteux mais sont en général moins contraignants en termes de latence que les traitements synchrones. Ils peuvent toutefois reposer en partie sur certains traitements synchrones comme la création et la mise à jour de résumés du flux. Les résumés de flux peuvent être également utiles aux traitements synchrones lorsque chaque tranche du flux dépasse les capacités de stockage en mémoire vive et l’accès au stockage de masse est trop lent pour être compatible avec la latence attendue de ces traitements.
Il faut noter que la fouille de flux de données ne mène pas nécessairement à une problématique spécifique aux données massives. Par exemple, les ressources d’un ordinateur de base suffisent largement pour effectuer une fois par heure la classification automatique des quelques centaines ou milliers de tweets arrivés durant les dernières 24 heures sur certains hashtags. On considère que les traitements relèvent de la fouille de données massives de flux si, en raison à la fois du débit très élevé du flux de données, du coût des traitements à appliquer à ces données et des contraintes sur la latence, il n’est pas envisageable de traiter les données régulièrement de façon exhaustive sur une plate-forme centralisée.
Avant de regarder de plus près l’architecture d’un système de traitement de flux et différents problèmes liés à ces traitements, il est utile de considérer quelques applications actuelles ou envisageables avec, à chaque fois, une indication de la volumétrie correspondante.
Données issues de capteurs ou de réseaux de capteurs. Les capteurs sont de plus en plus utilisés dans différents secteurs industriels pour mesurer des vibrations, des bruits, des températures ou des noxes. Les données ainsi obtenues doivent permettre d’optimiser le fonctionnement des machines, d’améliorer la planification des maintenances ou de prévoir les pannes. La volumétrie peut être très élevée, par exemple les différents capteurs présents dans un seul moteur d’avion de ligne génèrent env. 1 To de données par heure de vol. Des réseaux de capteurs sont déployés pour mesurer le trafic routier dans une ville, suivre la densité de polluants atmosphériques, etc. Cela peut permettre de mieux réguler le trafic et respectivement de choisir l’emplacement ou de paramétrer des systèmes de dépollution.
Logs de moteurs de recherche génériques ou spécialisés. Ces données contiennent les requêtes, les adresses IP d’où ces requêtes ont été envoyées, éventuellement l’identité des utilisateurs ayant envoyé les requêtes (s’ils se sont identifiés sur le site) et d’autres informations issues des cookies. L’analyse de ces données peut permettre de cibler les publicités, de prévoir l’évolution d’épidémies (par ex. grippe), d’estimer l’intérêt pour différents sujets ou l’impact de divers événements, de prévoir la demande de produits ou d’informations spécifiques, etc. Pour certaines applications (comme le ciblage de publicités) la latence doit être très faible. La volumétrie est variable, par ex. Google reçoit env. 50.000 requêtes par seconde.
Données entrantes sur des sites de partage de contenus multimédia. Les données sont des contenus multimédia (images, vidéos, séquences sonores) avec d’éventuelles métadonnées (géolocalisation, date et heure, paramètres de prise de vue, etc.), les adresses IP d’où ces données sont envoyées, l’identité déclarée des utilisateurs (s’ils se sont identifiés sur le site). L’analyse peut parfois se satisfaire des données non multimédia, mais de plus en plus se développent des méthodes qui travaillent aussi sur les contenus multimédia car les autres données ne sont pas suffisantes. Comme applications nous pouvons mentionner l’estimation de popularité ou d’impact, mais également la détection d’événements (au sens très général du terme) ou le filtrage (contenus protégés, dégradants, etc.). Lorsque le contenu multimédia est analysé, la volumétrie est importante et les 300 heures de vidéo mises en ligne chaque minute sur YouTube indiquent probablement une limite supérieure de ce qu’on peut atteindre aujourd’hui sur un site de ce type.
Données de vidéosurveillance. Ces données sont des contenus vidéo et audio, complétées par des informations de localisation, éventuellement d’orientation et de focale des caméras. L’analyse du contenu multimédia de ces flux doit permettre de détecter des événements localisés, ainsi que d’éventuelles corrélations entre faits observés par des caméras différentes, etc. La volumétrie est variable mais, par exemple, à Londres on trouve près de 500.000 flux continus de vidéosurveillance.
Imagerie satellite et aérienne. Ces flux de données, en fort développement ces dernières années, sont issus de satellites souvent en orbite héliosynchrone ou dont le positionnement est sur demande, ainsi que de drones à usage professionnel. Les données sont, en général, des séquences d’images optiques (dans le spectre visible ou non) ou radar pour les satellites et parfois des flux vidéo pour les drones. Les applications sont très diverses et incluent le suivi de l’impact de catastrophes (naturelles ou non) et la détection d’événements. Comme exemple de volumétrie nous pouvons mentionner les 2 To de données qu’envoient les deux satellites Pleiades (résolution 50 cm) chaque jour.
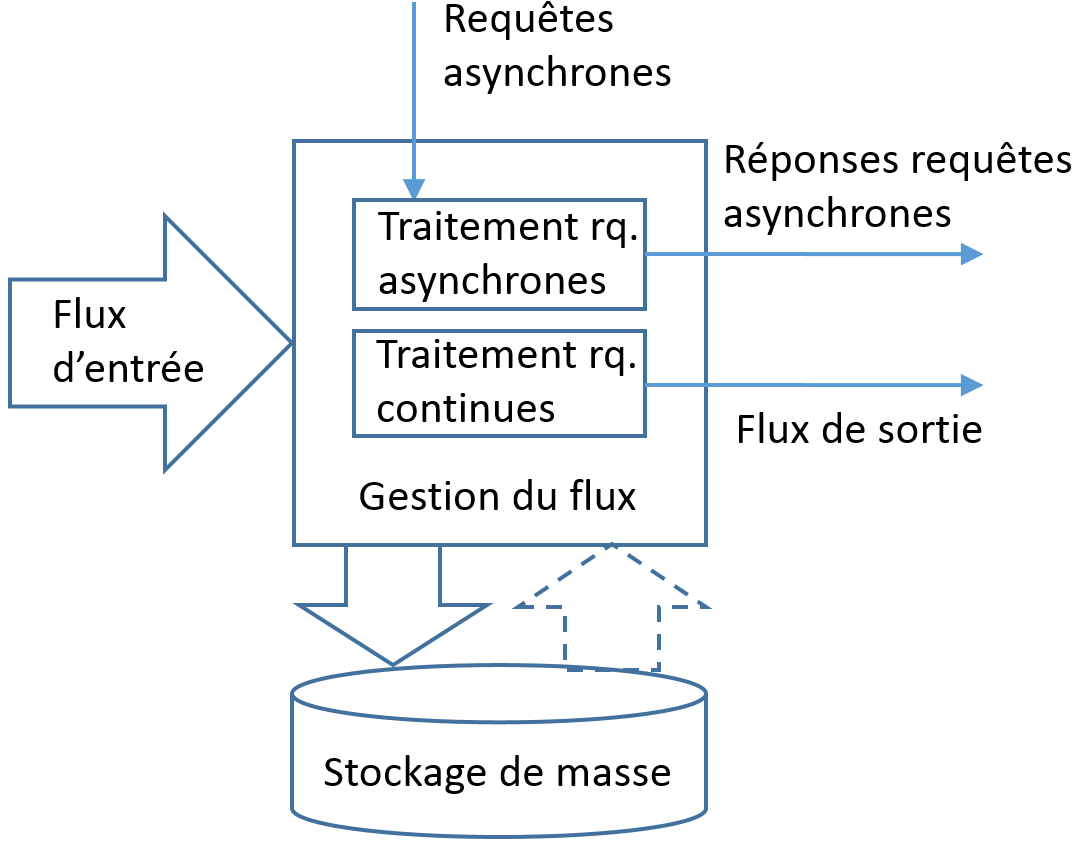
Architecture d’un système de traitement de flux de données¶
Le traitement d’un flux de données inclut plusieurs opérations, dont la création et le maintien de résumés du flux d’entrée, l’application de modèles sur le flux, la construction et mise à jour de modèles à partir du flux. La figure suivante montre l’architecture générale d’un système de traitement de flux de données.
Les différentes opérations sur le flux (résumés, construction et application de modèles) sont réalisées dans la partie « Gestion du flux ». Un système de traitement de flux doit pouvoir répondre à deux type de requêtes :
Requêtes « continues », qui impliquent des traitements synchrones avec le flux. Par exemple, à partir du flux de requêtes reçues par un moteur de recherche, obtenir le nombre de requêtes par heure concernant une thématique spécifique. Les réponses aux requêtes continues constituent un flux de données de sortie du système de traitement.
Requêtes asynchrones, qui impliquent des traitements asynchrones par rapport au flux. Par exemple, à partir des mesures réalisées par un réseau de capteurs de pollution qui couvre la région parisienne, obtenir la concentration moyenne de dioxyde d’azote sur les trois derniers jours à Paris. La réponse à une requête asynchrone a en général peu de contraintes de latence. Le traitement des requêtes asynchrones peut mobiliser ponctuellement des ressources supplémentaires, non utilisées par les traitements synchrones.
La construction et la mise à jour de résumés de flux ne sont pas explicitement représentées sur la figure, mais impliquent également des traitements synchrones, tout comme le traitement des requêtes continues.
Les données du flux d’entrée sont parfois conservées sur un stockage de masse, en totalité ou sous forme de résumés. Ce stockage est en général fait dans un but d’archivage, pour permettre de retrouver certaines données ultérieurement. Les données archivées ne sont pas utilisées dans des traitements synchrones car l’accès au stockage de masse est trop lent pour être compatible avec les contraintes de latence de ces traitements (le volume de données peut également être excessif).
Dans la suite nous nous intéressons à certains traitements synchrones typiques : échantillonnage dans un flux, filtrage de flux, modélisation à partir de flux et application de modèle sur un flux.
Si un flux à un débit élevé, employer la totalité de ses données pour répondre à des requêtes (synchrones ou asynchrones) n’est pas possible en général car le coût des calculs et la latence imposée par l’accès au stockage de masse seraient excessifs. Parfois, il n’est même pas envisageable de stocker la totalité des données du flux pour archivage. La question de l’échantillonnage des données du flux se pose alors. L’objectif est d’extraire du flux un échantillon qui soit suffisamment représentatif pour permettre de répondre aux différentes requêtes prévues et d’assez faible volume pour pouvoir être conservé sur une durée relativement longue en stockage rapide (par ex. dans la mémoire vive des nœuds de calcul, même si un stockage non volatile est aussi assuré).
En général, chaque donnée (ou observation) d’un flux comporte des valeurs pour plusieurs attributs (ou variables) :
Réseau de capteurs : l’identifiant du capteur (ou sa position GPS), une étiquette temporelle de la mesure, la (les) valeur(s) du (des) paramètre(s) mesuré(s). Le flux est une succession de mesures envoyées par les capteurs disponibles, dans l’ordre d’arrivée, qui ne correspond pas nécessairement à un tri des valeurs d’un des attributs (pas même à l’étiquette temporelle de la mesure, car la durée du transit entre le capteur et le système de traitement peut être variable).
Log d’un moteur de recherche : l’adresse IP de l’utilisateur, une étiquette temporelle, les mots clés de la recherche, le type de navigateur employé, etc. Le flux est une succession de requêtes, dans l’ordre dans lequel elles ont été enregistrées dans le log du moteur de recherche.
Imagerie satellite : la position du satellite, les paramètres de prise de vue (domaine spectral, orientation du capteur, focale, résolution, etc.), une étiquette temporelle de la prise de vue, l’image captée, etc. Le flux est une succession d’images avec des méta-données, en général dans l’ordre des étiquettes temporelles.
L’échantillonnage simple d’un flux considère une même probabilité de sélection \(p_s\) pour chaque donnée du flux, indépendamment des valeurs des différents attributs. Regardons maintenant, en revenant aux trois exemples de flux mentionnés, dans quelle mesure un tel échantillonnage permet de répondre à certaines requêtes.
Réseau de capteurs : on souhaite estimer, à partir de l’échantillon, le pourcentage de capteurs qui indiquent une variation journalière supérieure à un seuil (\(\theta\)) du paramètre mesuré. Si la probabilité de sélection est \(p_s = 0,1\) (ou même \(p_s = 0,01\)), si chaque capteur transmet une mesure chaque seconde et si le paramètre mesuré varie lentement (par ex., la température ambiante), alors l’échantillon devrait permettre d’obtenir une bonne estimation. Mais les capteurs isolés sont souvent soumis à des contraintes fortes de consommation d’énergie, dans ce cas ils réalisent (et transmettent) seulement une mesure par heure ou même moins. Avec \(p_s = 0,1\), pour bon nombre de capteurs nous ne trouvons plus qu’une seule mesure par jour dans l’échantillon, il n’est donc plus possible de mesurer une variation pour ces capteurs et l’estimation est fortement affectée. La solution est de sélectionner dans l’échantillon 10% des capteurs pour lesquels on conserve toutes les mesures, plutôt que 10% des mesures sans tenir compte du capteur ; le volume de données de l’échantillon est le même (10% du flux) mais cet échantillon permet de bien répondre à la requête.
Logs de moteurs de recherche : on cherche à estimer, à partir de l’échantillon, le pourcentage des requêtes de l’utilisateur typique qui sont répétées durant un intervalle d’un mois (voir aussi [LRU11]). Supposons que la probabilité de sélection est \(p_s = 0,1\) (nous souhaitons avoir un échantillon de 10% des requêtes) et que cette sélection est faite sans tenir compte des valeurs des attributs (adresse IP, étiquette temporelle, mots-clés de la recherche, etc.). Supposons que l’utilisateur typique fait en moyenne \(s\) requêtes non répétées par mois, \(d\) requêtes répétées une fois et un nombre négligeable de requêtes répétées plusieurs fois. Sur les \(s\) requêtes non répétées dans le flux, \(s/10\) seront présentes (une fois) dans l’échantillon. Sur les \(d\) requêtes répétées (une fois) dans le flux, seulement \(1/100\)\((= \frac{1}{10} \cdot \frac{1}{10}\)) seront répétées (une fois) dans l’échantillon. En effet, chaque requête répétée dans le flux a deux occurrences, chacune de ces occurrences a une probabilité de \(\frac{1}{10}\) d’être retenue dans l’échantillon (\(p_s = 0,1\)), pour que la requête soit répétée dans l’échantillon il faut que chacune de ses deux occurrences soit retenue et les tirages correspondants sont indépendants. Aussi, sur les \(d\) requêtes répétées une fois dans le flux, \(18/100\)\((= \frac{1}{10} \cdot \frac{9}{10} + \frac{9}{10} \cdot \frac{1}{10})\) seront présentes dans l’échantillon une seule fois (soit la première occurrence est présente et la seconde absente, soit la première est absente et la seconde présente). A partir de l’échantillon nous obtenons donc une estimation \(\frac{\frac{d}{100}}{\frac{s}{10}+\frac{18 d}{100}+\frac{d}{100}} = \frac{d}{10 s + 19 d}\), très éloignée de la valeur obtenue à partir de toutes les requêtes, qui est de \(\frac{d}{s + d}\). La solution consiste à sélectionner dans l’échantillon non 10% des requêtes mais plutôt 10% des utilisateurs, pour lesquels on conserve toutes les requêtes ; ici encore, le volume de données de l’échantillon reste le même (10% du flux) mais l’échantillon obtenu en sélectionnant les utilisateurs nous donne la possibilité de répondre à la requête. Par ailleurs, cet échantillon de 10% des utilisateurs permet de répondre également à d’autres questions concernant le comportement des utilisateurs.
Imagerie satellite : on souhaite estimer, à partir de l’échantillon, le pourcentage de positions pour lesquelles les paramètres de prise de vue sont identiques. La relation recherchée (ici, identité entre paramètres de prise de vue) ne peut pas être présente à un taux proche dans la population entière et dans un échantillon réduit (\(p_s = 0,1\), par ex.) si celui-ci est constitué sans tenir compte des valeurs des attributs concernés par la relation (ici, les paramètres de prise de vue). Dans cet exemple, il sera en revanche possible d’obtenir la réponse si l’échantillon est constitué en sélectionnant \(p_s \cdot 100\%\) des valeurs prises par l’attribut « paramètres de prise de vue ».
Pour pouvoir répondre à des requêtes à partir de l’échantillon, il est donc souvent nécessaire de tenir compte des valeurs d’un ou plusieurs attributs pour réaliser l’échantillonnage d’un flux. Dans le premier exemple il est nécessaire de sélectionner 10% des capteurs, dans le deuxième exemple 10% des utilisateurs et dans le troisième 10% des valeurs prises par l’attribut « paramètres de prise de vue ».
Cette sélection peut être réalisée soit par la recherche de la valeur dans une liste, soit en utilisant une méthode de hachage. La liste des valeurs qui doivent se retrouver dans l’échantillon du flux peut être obtenue a priori, en choisissant un échantillon des valeurs possibles lorsque leur domaine est bien connu. Cette liste peut également être construite progressivement, en y insérant avec une même probabilité \(p_s\) chaque valeur nouvellement observée.
Si la conservation de la liste des valeurs et la recherche dans cette liste sont trop coûteuses, il est possible d’utiliser une méthode de hachage. On définit une fonction de hachage qui a comme domaine l’ensemble des valeurs possibles de l’attribut visé et peut prendre \(1/p_s\) valeurs de hash différentes ; on conserve une valeur de l’attribut dans l’échantillon si le hash est égal à une valeur fixée a priori (par ex. 0). Bien entendu, la fonction de hachage doit prendre chacune des valeurs de hash avec une même probabilité \(p_s\).
Cette solution de hachage peut être facilement étendue pour permettre, entre autres :
Un réglage plus fin de \(p_s\) (pour enlever la contrainte, implicite ci-dessus, que \(1/p_s\) soit une valeur entière). Ainsi, avec 100 valeurs de hash différentes, en conservant la valeur de l’attribut si la valeur de hash fait partie d’un ensemble fixé a priori de \(x\) valeurs, un échantillon de \(x\%\) est obtenu (\(p_s = x/100\)).
Une variation dans le temps du pourcentage lorsque, par exemple, le débit augmente. Dans un tel cas, \(p_s\) doit diminuer pour que le débit des données sélectionnées dans l’échantillon reste constant. Un hachage choisi pour obtenir un réglage fin permet facilement de réduire progressivement \(p_s\) (on choisit un ensemble de \(x-1\) valeurs sur les 100 lorsque le débit augmente, puis de \(x-2\) valeurs sur les 100 lorsque le débit augmente encore, et ainsi de suite).
Une sélection tenant compte des valeurs de plusieurs attributs. Si un hachage est mis en place pour la sélection par rapport à chaque attribut dont la valeur compte, il est possible de construire des échantillons par rapport à des attributs individuels ou des groupes d’attributs (à condition que les valeurs des différents attributs puissent être choisies de façon indépendante).
Il est souvent nécessaire d’appliquer des traitements particuliers aux données issues d’un flux et qui satisfont certaines conditions. Un filtrage qui vérifie ces conditions doit être mis en place. Les conditions dont la vérification est peu coûteuse (comme par ex. le fait que la valeur d’un attribut soit dans un intervalle spécifique, ou la valeur d’un autre attribut dans un ensemble prédéfini réduit de valeurs) ne posent pas de difficulté particulière. En revanche, pour celles dont la vérification est très coûteuse, des solutions simples doivent être trouvées, au prix d’éventuelles approximations.
Considérons le cas où la condition de filtrage est l’appartenance de la valeur d’un attribut à un très grand ensemble de valeurs. Lorsque cette condition ne peut être vérifiée que par comparaison aux valeurs de cet ensemble ou à une partie des valeurs de l’ensemble, le coût (en termes de temps et de capacité mémoire mobilisée) peut être excessif par rapport aux exigences du traitement du flux. Ainsi, si pour résoudre ce problème on applique une méthode classique de hachage employée dans les bases de données relationnelles pour la recherche par identité, il sera nécessaire de comparer la valeur recherchée à toutes les valeurs stockées dans la « page » identifiée par le hash de cette valeur. Si la table de hachage est stockée sur disque il faudra d’abord lire la page concernée (après un temps d’accès comparativement élevé), si la table est conservée en mémoire alors l’occupation mémoire risque d’être excessive.
Considérons l’exemple d’un site de partage vidéo qui souhaite interdire, pour diverses raisons (présence d’incitations à la haine, contenus dégradants, non respect du droit d’auteur, etc.), la mise en ligne de vidéos répertoriées au préalable (de nouvelles vidéos peuvent néanmoins être ajoutées à cet ensemble). Sachant que les données textuelles accompagnant une vidéo peuvent être falsifiées par celui qui dépose la vidéo afin d’empêcher une détection facile par titre ou par mots clés, nous considérerons que les vidéos sont identifiées par un ensemble de descripteurs extraits de certaines trames vidéo particulières. Pour chaque vidéo, l’ensemble des descripteurs (nous l’appellerons « signature » de la vidéo) est volumineux. Aussi, supposons que le nombre de vidéos « interdites » est très élevé.
L’objectif est, dans ce cas, d’effectuer le filtrage
Rapidement et avec relativement peu de ressources mémoire, afin de pouvoir traiter à un coût acceptable les données du flux. Pour avoir une idée de l’ordre de grandeur, rappelons que 300 h de vidéo sont mises en ligne chaque minute sur YouTube.
En garantissant que les vidéos « interdites » ne se retrouvent pas en ligne. Dans le contexte décrit plus haut, cette garantie ne pourra toutefois être apportée que si le contenu des vidéos n’est pas modifié ou l’est suffisamment peu pour que la « signature » reste inchangée.
En acceptant éventuellement que certaines autres vidéos (« bénignes ») soient également supprimées. Les cas litigieux peuvent éventuellement être résolus par des échanges explicites entre l’utilisateur qui souhaite déposer une vidéo et le service de modération du site.
Examinons maintenant ce qu’est un filtre de Bloom et de quelle manière il permet d’atteindre cet objectif.
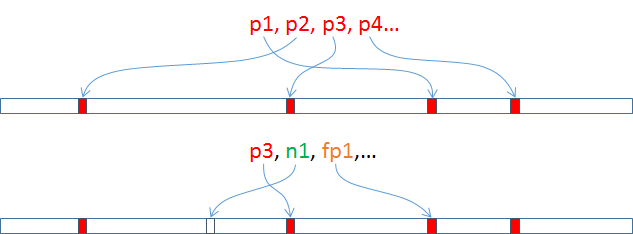
La Fig. 126 illustre le fonctionnement d’un filtre de Bloom. Supposons que nous cherchons à filtrer certaines valeurs d’un attribut décrivant chaque donnée du flux et que la zone mémoire disponible pour réaliser le filtrage a une capacité de \(N\) bits (\(N/8\) octets). Considérons une fonction de hachage qui prend en entrée une valeur de cet attribut (dans la Fig. 126, p1, p2, p3, p4, n1, fp1, etc.) et lui associe un hash entre 0 et \(N-1\). Appliquée à une même valeur de l’attribut, la fonction de hachage produira le même hash. Il suffit alors de positionner au départ à 1 les bits identifiés par les hash des valeurs à filtrer (en rouge dans la Fig. 126) et à 0 les autres bits (en blanc dans la Fig. 126) pour pouvoir facilement filtrer les données. Appliquée à une valeur qui fait partie de l’ensemble à filtrer (p1, p2, p3 et p4 dans la Fig. 126), la fonction de hachage produit un hash qui correspond à un bit à 1 et permet ainsi de détecter l’appartenance à l’ensemble à filtrer. Appliquée à une autre valeur, la fonction de hachage produit en général (comme pour n1 dans la Fig. 126) un hash qui correspond à un bit à 0 et indique que la valeur ne doit pas être filtrée. Dans certains cas (comme pour fp1 dans la figure), il y a néanmoins « collision » avec un hash de valeur à filtrer, par ex. la valeur fp1 est filtrée (car de même hash que p1 ici) bien que n’appartenant pas à l’ensemble à filtrer ; nous sommes en présence d’un « faux positif ».
Pour réduire la probabilité de collision et donc le nombre de faux positifs il faut soit modifier la fonction de hachage pour augmenter le nombre de valeurs de hash différentes, soit employer plusieurs fonctions de hachage indépendantes. Dans ce dernier cas, une valeur est considérée appartenir à l’ensemble à filtrer si et seulement si pour chaque fonction de hachage le bit identifié par le hash est 1. Dans les deux cas, il est nécessaire d’utiliser plus d’espace mémoire pour réaliser le filtrage. On peut montrer que, pour \(M\) valeurs à filtrer et \(k\) fonctions de hachage, chacune avec \(N\) valeurs de hash différentes, le taux de faux positifs est \(\approx (1 - e^{-k M / N})^k\) pour une occupation mémoire de \(k N\) bits (\(N\) bits par fonction). Le temps nécessaire pour filtrer une valeur correspond aux calculs des \(k\) fonctions de hachage pour obtenir les \(k\)hash, à la lecture des \(k\) cases mémoire identifiées et au calcul d’un ET logique entre leurs valeurs.
Revenons à l’exemple décrit plus haut, celui du filtrage de vidéos « interdites ». Pour réaliser ce filtrage avec un filtre de Bloom, il faut définir une fonction de hachage qui prend en entrée une signature de vidéo et lui associe un hash entre 0 et \(N-1\), où \(N\) est le nombre de bits de la zone mémoire utilisée pour le filtrage. Tous les bits de cette zone mémoire sont mis à 0. La fonction de hachage est ensuite appliquée à la signature de chaque vidéo interdite et le bit identifié par le hash obtenu est à chaque fois mis à 1. Supposons que la fraction de bits à 1 est \(0 < r \ll 1\) (\(r = M/N\), \(M\) étant le nombre de vidéos interdites).
Lorsqu’une vidéo arrive (par upload), sa signature est calculée et ensuite la fonction de hachage est appliquée à cette signature. Si la valeur du bit identifié par le hash obtenu est 1 alors la vidéo n’est pas mise en ligne, si la valeur est 0 alors la vidéo est mise en ligne.
Pour toute vidéo qui fait partie de l’ensemble des vidéos interdites, le bit identifié par le hash est 1 par construction, il n’y a donc pas de faux négatifs ! Pour une vidéo qui ne fait pas partie de l’ensemble, la probabilité pour que le bit identifié par le hash soit 1 (et donc que la vidéo soit à tort interdite) n’est pas nulle mais proche de \(r\), il y a donc des faux positifs. En augmentant le nombre de fonctions de hachage, comme expliqué plus haut, on peut diminuer le taux de faux positifs (sans impact sur le taux de faux négatifs qui sera toujours de 0) au prix d’une augmentation de la consommation mémoire. Le temps nécessaire pour le filtrage d’une vidéo correspond au calcul de la signature, au calcul de la (des) fonction(s) de hachage du filtre de Bloom et à la lecture de la (des) case(s) mémoire identifiée(s).
Que ce soit pour des traitements synchrones ou pour répondre à des requêtes asynchrones, on pourrait considérer nécessaire de traiter toutes les données du flux (ou d’un échantillon extrait du flux). Il y a au moins deux bonnes raisons pour ne pas employer systématiquement la totalité de l’historique conservé.
Même avec un échantillonnage du flux, le volume de l’échantillon accumulé sur une longue période peut être tel que le coût de traitement soit excessif. Ce sera vraisemblablement le cas, par exemple, pour le flux de requêtes reçues par un site très populaire ou pour le flux d’images issues d’un satellite d’observation de la Terre.
Les distributions des valeurs des différents attributs qui décrivent les données du flux sont souvent non stationnaires, remonter loin dans l’historique peut être non pertinent pour l’indication recherchée. Par exemple, pour estimer la popularité d’un sujet d’actualité ou celle d’un film sorti en salles, cumuler depuis le début les nombres de messages échangés par heure ou respectivement le nombre d’entrées par jour ne permet pas d’obtenir une indication très utile. Mieux vaut s’intéresser (ou du moins privilégier) la période récente (les deux derniers jours pour le sujet d’actualité ou la dernière semaine pour le film sorti en salles).
La solution est de se limiter au traitement des données du flux qui sont situées dans une fenêtre temporelle glissante. Si \(l\) est la longueur de la fenêtre, les données des tranches \(i, i-1, i-2, \ldots, i-l+1\) du flux sont prises en compte (la tranche \(i\) est la dernière tranche reçue) alors que les données des tranches qui précèdent (\(i-l, i-l-1, \ldots\)) sont ignorées.
Fig. 127 Fenêtre temporelle glissante appliquée à un flux de données¶
La fenêtre glissante peut être
de longueur fixe \(l\) prédéfinie : techniquement la solution la plus simple, bien adaptée quand c’est la non stationnarité qui motive l’emploi de fenêtres temporelles ;
de volume fixe (la longueur \(l_i\) variera donc suivant les volumes de données des tranches successives) : cas préférable lorsque c’est plutôt le trop grand volume de données qui justifie l’utilisation de fenêtres.
Les fenêtres définies plus haut sont « nettes », une tranche est soit dans la fenêtre (donc prise en compte), soit en dehors de la fenêtre (donc ignorée). Il peut être utile de pondérer les tranches, afin de prendre plus en compte les tranches récentes et moins les tranches plus anciennes (tout en évitant de les ignorer complètement). Nous obtenons ainsi des fenêtres avec oubli (decaying windows) : la pondération d’une tranche diminue avec l’augmentation de l’écart temporel entre cette tranche et la tranche courante (dernière tranche reçue). Cette diminution continue des pondérations a également comme conséquence un « lissage » des estimations obtenues à partir des fenêtres du flux.
Un cas fréquent est celui de la décroissance exponentielle des pondérations. Prenons l’exemple de l’estimation de la popularité d’un sujet d’actualité ou d’un film sorti en salles. Considérons que chaque tranche est caractérisée par une valeur numérique, \(m_i\) pour la tranche \(i\), correspondant au nombre de messages échangés par heure (pour un sujet d’actualité) ou respectivement au nombre d’entrées par jour (pour un film sorti en salles). Si on note par \(s_i\) la mesure de popularité obtenue après l’arrivée de la tranche \(i\) (donc de la valeur \(m_i\)), une décroissance exponentielle des pondérations correspond à la relation de définition suivante (pour \(i \geq 1\)) :
\[s_i = \sum_{j=1}^i{d^{i-j} \cdot m_j}\]
où \(0 < d < 1\) est le « facteur d’oubli » (decay factor). La borne inférieure \(j=1\) indique que la somme est calculée depuis le début du flux. Heureusement, pour faire ce calcul avec une décroissance exponentielle des pondérations il n’est pas nécessaire de conserver les données depuis le début du flux car la relation de récurrence suivante permet d’arriver au même résultat (la vérification est facile) :
\[s_i = m_i + s_{i-1} \cdot d, \ \ s_0 = 0\]
Mise à jour et application de modèles : l’exemple de Streaming K-means¶
Deux traitements synchrones importants sur les données d’un flux sont
l’application d’un modèle existant, pré-estimé, sur les tranches successives du flux,
la mise à jour d’un modèle en utilisant les données de chaque tranche du flux.
Lorsqu’elle est faite à partir de données en flux, la construction d’un modèle doit être incrémentale : il faut pouvoir mettre à jour le modèle existant avec les données d’une tranche sans avoir à le ré-estimer complètement car le coût de calcul avec toutes les données du flux (depuis le début) serait incompatible avec un traitement synchrone.
Par ailleurs, si les données du flux ont une distribution qui évolue dans le temps (n’est pas stationnaire), il peut être intéressant de donner des pondérations plus fortes aux données récentes du flux et des pondérations plus faibles aux données plus anciennes. Pour que cela soit compatible avec la mise à jour du modèle à partir des données de la dernière tranche, il faut pouvoir sous-pondérer le modèle antérieur (obtenu après la tranche précédente, qui intègre donc l’impact des données plus anciennes) dans la construction du nouveau modèle.
Considérons un cas concret simple, celui de la classification automatique avec k-means des données d’un flux. On souhaite pouvoir appliquer le modèle courant aux données de la dernière tranche afin de les affecter aux groupes déjà trouvés et ensuite mettre à jour ce modèle en tenant compte de ces données.
Rappelons-nous que pour k-means un modèle consiste en l’ensemble des centres de gravité des \(k\) groupes, \(\mathcal{C} = \{\mathbf{m}_j, 1 \leq j \leq k\}\). Le flux correspond à une séquence d’ensembles \(\mathcal{E_t}\) de \(n_t\) données de \(\mathbb{R}^p\), où \(t = 1, 2, \ldots\) est l’indice des tranches successives du flux. Nous cherchons à affecter chaque donnée de chaque tranche à un groupe (celui du centre le plus proche de la donnée) et ensuite à mettre à jour le modèle (les centres) à partir des données de la dernière tranche. L’algorithme global sera le suivant :
Entrées : tranches du flux, c’est à dire ensembles \(\mathcal{E}_t\) de \(n_t\) données de \(\mathbb{R}^p\), pour \(t = 1, 2, \ldots\) ;
Sorties : après chaque tranche, \(k\) groupes (clusters) disjoints \(\mathcal{E}_{1,t},\ldots,\mathcal{E}_{k,t}\) (qui sont des sous-ensembles de \(\mathcal{E}_t\)) et ensemble \(\mathcal{C_t}\) de leurs centres ;
Initialisation des centres \(\mathbf{m}_{j,1}\), \(1 \leq j \leq k\), à partir des données de la première tranche (par exemple, avec k-means||) ;
pour (chaque tranche \(\mathcal{E}_t\) du flux) faire
Affectation de chaque donnée de la tranche au groupe du centre le plus proche ;
Mise à jour des centres et remplacement des anciens centres par les nouveaux ;
finpour
L’affectation de chaque donnée de chaque tranche au groupe du centre le plus proche (parmi les centres courants, donc de \(\mathcal{C_t}\)), étape 2.1 de l’algorithme, ne pose pas de difficulté particulière, toutes les distances entre les données de la tranche et les centres courants doivent être calculées, comme pour k-means.
En revanche, la mise à jour des centres (étape 2.2) doit se faire uniquement avec les données de la dernière tranche, tout en tenant compte des données plus anciennes indirectement, à travers les anciens centres. La relation de mise à jour est
où \(\mathbf{m}_{j,t+1}\) est le centre \(j\) mis à jour dans l’itération courante, \(\mathbf{m}_{j,t}\) est le centre \(j\) avant sa mise à jour, \(n_{j,t}\) est le nombre de données de la tranche courante affectées à ce centre, \(N_{j,t}\) est le nombre de données affectées au centre \(j\) depuis le début, \(\mathbf{x}_{j,t}\) est le centre correspondant calculé uniquement avec les données de la tranche courante et \(0 \leq \alpha \leq 1\) est le « facteur d’oubli ».
Après l’affectation des données de la dernière tranche aux centres dans l’étape 2.1, pour chaque groupe \(j\) on détermine d’abord le centre de gravité \(\mathbf{x}_{j,t}\) des données de cette tranche affectées à ce groupe. Ensuite, le nouveau centre \(\mathbf{m}_{j,t+1}\) du groupe \(j\) est calculé comme une moyenne pondérée entre l’ancien centre \(\mathbf{m}_{j,t}\) (contribution des données des tranches précédentes) et \(\mathbf{x}_{j,t}\) (contribution des données de la dernière tranche).
Si \(\alpha = 1\), les anciennes données du flux « pèsent de tout leur poids » sur l’évolution des centres, si les rapports \(\frac{n_{j,t}}{N_{j,t}}\) sont faibles alors les centres évoluent très peu d’une itération à la suivante (sauf au démarrage du flux). Si \(\alpha = 0\) alors les anciens centres sont ignorés dans le calcul des nouveaux centres, l’impact des données de la tranche précédente se retrouve seulement dans l’étape d’affectation des nouvelles données aux centres issus de l’itération précédente (étape 2.1 de l’algorithme).
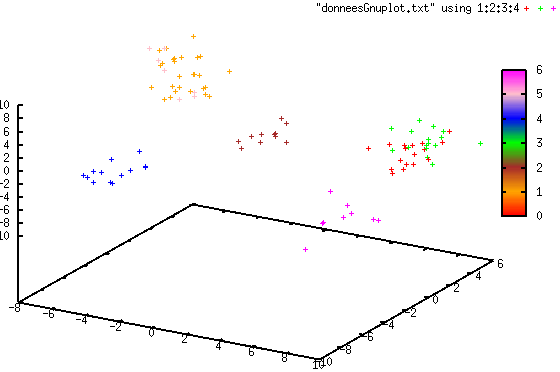
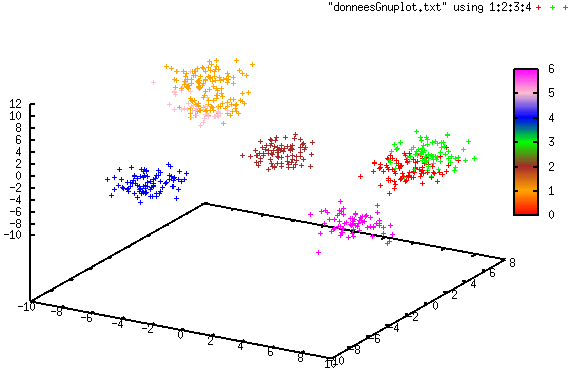
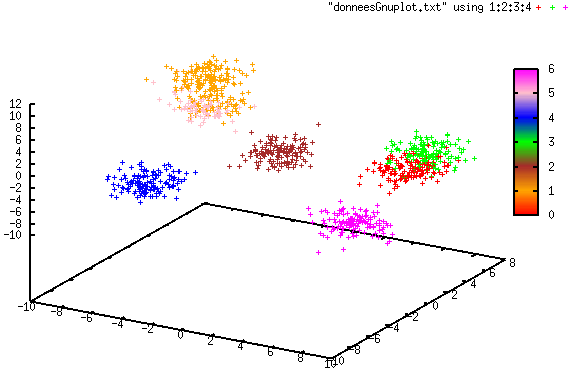
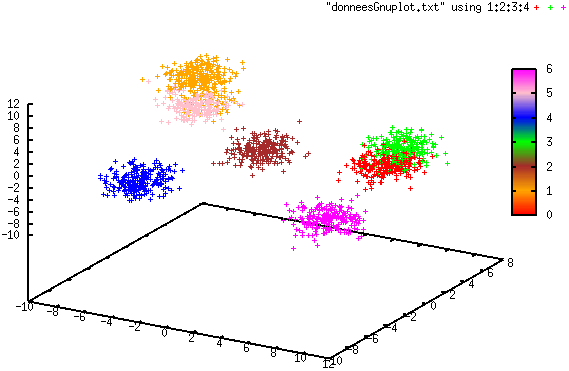
Les quatre illustrations suivantes montrent un cas simple de classification automatique avec streaming K-means d’un flux de données de \(\mathbb{R}^3\). Les données ont été générées à partir de sept lois d’assez faible variance, ensuite sérialisées dans les tranches successives d’un flux. La distribution des données est ici stationnaire et \(\alpha = 0.5\). Une couleur différente est utilisée pour chaque groupe.
Fig. 128 Groupes après l’arrivée des premières données¶
Fig. 129 Groupes après l’arrivée de 30% des données¶
Fig. 130 Groupes après l’arrivée de 60% des données¶
Fig. 131 Groupes après l’arrivée de toutes les données¶
Spark Streaming est une interface de programmation qui permet de traiter des flux de données sur une plate-forme Spark. Les données peuvent être reçues de différentes façons : transferts dans le système de fichiers (voir l’exemple donné dans la séance de travaux pratiques), réception sur des sockets TCP (connexions réseau génériques), ou obtenues de Twitter (X), Kafka, Flume, etc.
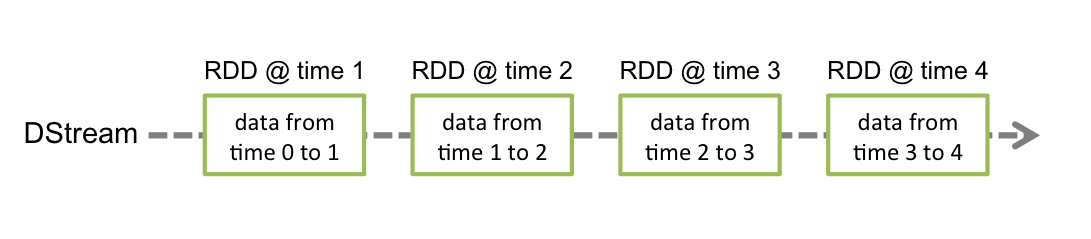
Un flux de données correspond dans Spark Streaming à une abstraction appelée flux discrétisé (DStream). Chaque DStream est représenté par une séquence de RDD (structure de données distribuée générique de Spark). Un DStream est créé à partir d’un StreamingContext, en précisant la durée d’une tranche (slice). Les données reçues (par un des moyens mentionnés plus haut) sont découpées en tranches en respectant cette durée. Chaque tranche est un RDD qui peut être traité ou transformé comme un RDD quelconque.
Fig. 132 Un DStream est une séquence de RDD (figure issue de la documentation de Spark)¶
Plusieurs opérations peuvent être directement appliquées aux flux, chaque flux étant représenté par un DStream : transformation d’un flux pour obtenir un autre flux, fusion de plusieurs flux en un seul, jointure de flux, jointure entre un flux et un RDD unique, filtrage d’un flux à partir d’un autre flux, mise à jour d’un « état » à partir d’un flux, etc. Ces opérations peuvent être appliquées aussi bien à travers spark-shell qu’à partir d’un programme.
Toute source de données en flux (à l’exception de la source « système de fichiers ») doit avoir un Receiver associé pour récupérer les données reçues, les découper en tranches et distribuer le contenu de chaque tranche (représentée par un RDD) aux nœuds de calcul.
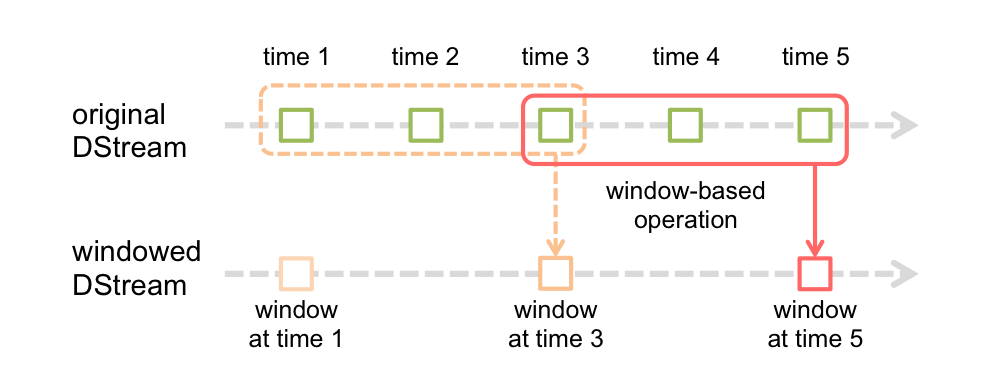
Spark Streaming permet d’employer des fenêtres glissantes sur un flux. Les fenêtres sont définies par deux valeurs (entières) : le nombre de tranches qui se trouvent dans la fenêtre à chaque moment (longueur de la fenêtre) et le nombre de tranches de décalage à chaque déplacement de la fenêtre (pas du glissement). Les RDD correspondant aux tranches qui sont dans la fenêtre sont regroupés avant d’être traités ; les opérations appliquées sur les RDD individuels (tranches) sont étendues aux fenêtres (par ex. reduceByKeyAndWindow).
Fig. 133 Utilisation de fenêtres glissantes dans Spark (figure issue de la documentation de Spark)¶