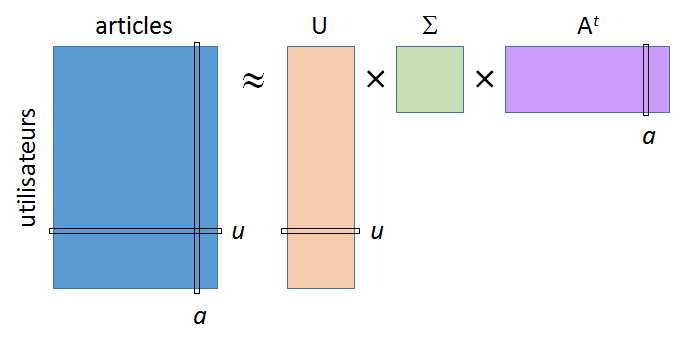Dans la première partie de ce chapitre nous examinerons de plus près la recherche et la jointure par similarité, en poursuivant d’abord l’étude de LSH par des fonctions adaptées à la distance cosinus et en considérant ensuite les phénomènes liés à la « malédiction de la dimension » (curse of dimensionality), ainsi que leur impact sur l’utilisation de la similarité.
Dans la seconde partie nous nous intéresserons aux systèmes de recommandation, qui sont une application importante de l’analyse et modélisation de données massives. Après une étude de l’utilisation dans ce contexte de méthodes basées sur la similarité, nous présenterons des méthodes plus élaborées qui emploient des factorisations matricielles.
La similarité entre données a de nombreuses applications directes et intervient également dans des opérations de modélisation à partir de données ou de prise de décision. Quelques exemples d’applications directes :
Un outil de recommandation de livres peut employer deux stratégies pour faire des propositions à un utilisateur. Une première stratégie consiste à identifier des utilisateurs dont le « profil » (issu par ex. de notes données par l’utilisateur à des ouvrages classiques, de notes données à des lectures proposées par l’outil, de caractéristiques socio-professionnelles, de liens d’amitié, etc.) est similaire au profil de l’utilisateur ciblé ; les lectures appréciées par ces utilisateurs similaires seront proposées à l’utilisateur ciblé. Une seconde stratégie consiste à proposer à l’utilisateur des ouvrages similaires (présentant des similarités de genre littéraire ou de style, ou lus et appréciés par les mêmes utilisateurs) aux ouvrages qu’il a appréciés. Nous reviendrons sur les systèmes de recommandation dans la seconde partie de ce chapitre.
Un outil de recherche de plagiat doit identifier, dans une base locale ou sur le web, la ou les sources exploitées de façon directe dans la réalisation d’un nouveau contenu (texte, image, vidéo, audio). Le contenu est segmenté et, pour chaque segment, on cherche des sources potentielles, c’est à dire des contenus antérieurs très similaires.
Un outil d’agrégation de contenus doit détecter les variantes d’un même contenu issues de sources différentes afin d’en faire une synthèse (plutôt que de les présenter comme des contenus indépendants). Pour déterminer si un contenu est une variante d’un autre contenu on définit une mesure de similarité adaptée et une valeur seuil (éventuellement dépendant du contexte) sur cette mesure.
Aussi, comme nous l’avons déjà remarqué au début du chapitre précédent, la similarité entre données peut être utilisée à la fois dans la construction d’un modèle décisionnel et dans la prise de décision (avec ou sans modèle).
Deux opérations de base exploitent la similarité directement : la recherche par similarité et la jointure par similarité. La recherche par similarité doit retourner les données similaires à une donnée « requête ». Dans les exemples qui précèdent, cette opération est employée par l’outil de recommandation (lorsqu’un utilisateur se connecte, pour identifier les utilisateurs similaires ou les ouvrages similaires) et par l’outil de recherche de plagiat (afin d’identifier les éventuelles sources pour les différents segments de contenu).
La jointure par similarité doit retourner les paires de données très similaires (il n’y a pas de donnée « requête »). Dans les exemples qui précèdent, la jointure par similarité est employée par l’outil d’agrégation pour identifier, dans une base qui regroupe les sources disponibles, les contenus redondants, c’est à dire les contenus pour lesquels des variantes sont également présentes dans la base. La jointure peut également être employée par l’outil de recommandation pour faire des propositions de façon proactive à l’ensemble des utilisateurs (connectés ou non).
Les méthodes de hachage sensible à la similarité (LSH) peuvent être employées (comme d’autres méthodes d’indexation multidimensionnelle ou métrique) pour réduire l’ordre de complexité de le recherche et de la jointure par similarité. Avant d’examiner les difficultés rencontrées par les index lorsque la dimension des données est très élevée, poursuivons l’étude de LSH en nous intéressant aux fonctions adaptées à la distance cosinus.
Les données peuvent être décrites par un nombre élevé de variables de nature différente :
Variables « ensemble » : chaque valeur d’une telle variable est un sous-ensemble d’un ensemble plus large. Par exemple, une variable peut correspondre à la description textuelle des articles en vente et une valeur de cette variable est le texte descriptif d’un article, donc un ensemble de mots de la langue. D’autres exemples de telles variables sont l’historique d’achat des clients (vu comme un simple ensemble d’articles acquis), ou la description de chaque ouvrage en vente par un ensemble d’étiquettes fournies par les utilisateurs (tags). La valeur que prend une telle variable pour une donnée particulière peut correspondre à un ensemble très grand (par ex., les mots d’un texte très long) ou très petit (par ex., les tags associés à un nouvel ouvrage). Les valeurs d’une variable étant des sous-ensembles d’un ensemble plus grand, il est possible de les comparer grâce, par exemple, à l’indice de Jaccard ou à la distance qui en est issue (voir le chapitre précédent). Une valeur (qui est un sous-ensemble) peut être représentée par la liste des éléments ou par la fonction caractéristique du sous-ensemble.
Variables nominales (à modalités) : une telle variable prend des valeurs dans un ensemble fini (et souvent d’assez faible cardinalité), des valeurs de la variable peuvent être identiques ou différentes mais nous ne pouvons pas les comparer d’une autre façon. Par exemple, une œuvre littéraire peut être caractérisée par une variable « genre littéraire » (classique, policier, SF, etc.), par une variable « pays de publication », un utilisateur par le navigateur web utilisé, par le mode de paiement, etc. Une valeur est en général représentée par un vecteur dont la dimension est égale au nombre de modalités de la variable et dont toutes les composantes sont 0 sauf celle correspondant à la modalité présente, qui est 1.
Variables quantitatives : les valeurs d’une telle variable sont des éléments d’un ensemble (souvent \(\mathbb{R}\) ou \(\mathbb{N}\)) sur lequel on peut définir différentes métriques, un ordre total, etc., ces valeurs peuvent donc être comparées de multiples façons. Par exemple, le nombre de pages d’un ouvrage, le montant total déjà dépensé par un client, etc. Une valeur d’une variable quantitative est en général représentée telle quelle.
Pour comparer des données (observations) décrites par plusieurs types de variables il faut disposer d’une métrique qui intègre toutes les contributions dans une mesure globale et qui présente une certaine flexibilité. La distance issue de l’indice de Jaccard est adaptée aux variables « ensemble » et aux variables nominales mais pas aux variables quantitatives. Par ailleurs, cette distance ne peut pas prendre en compte d’éventuelles différences de pondération entre des éléments des ensembles. La distance euclidienne classique est souvent utilisée pour des variables quantitatives mais ne permet pas de comparer directement de grands ensembles avec de petits ensembles (représentés par leurs fonctions caractéristiques) comme valeurs de variables « ensemble », une normalisation préalable est nécessaire. La distance cosinus est souvent employée pour cumuler les contributions des différents types de variables décrivant les données. Pour chaque donnée (observation), les représentations des différentes variables sont directement concaténées dans un vecteur de dimension élevée.
Pour \(\mathbf{x}, \mathbf{y} \in \mathcal{D} \subset \mathbb{R}^m\), la distance cosinus est \(d_{\cos}(\mathbf{x}, \mathbf{y}) = \arccos \frac{\mathbf{x}^T \cdot \mathbf{y}}{\left\|\mathbf{x}\right\| \cdot \left\|\mathbf{y}\right\|}\), c’est à dire l’angle (mesuré en degrés ou en radians) entre les deux vecteurs \(\mathbf{x}, \mathbf{y}\). Cette distance permet d’intégrer facilement des pondérations pour les différentes composantes des vecteurs (par exemple, pour les différents mots employés dans un texte, comme nous le verrons de plus près dans le chapitre suivant).
On peut remarquer que la normalisation est intégrée au calcul de la distance cosinus, mais cela peut parfois s’avérer nocif. Si pour une variable « ensemble » certaines données ont des valeurs de cardinalité très élevée et d’autres des valeurs de cardinalité très faible, cette normalisation globale peut nuire à la prise en compte des autres variables. Dans un tel cas il est nécessaire de normaliser séparément les composantes correspondant aux variables « ensemble ».
Aussi, suivant la méthode d’analyse ou de modélisation décisionnelle employée, il peut être nécessaire de choisir des pondérations relatives pour les différentes variables (ou types de variables).
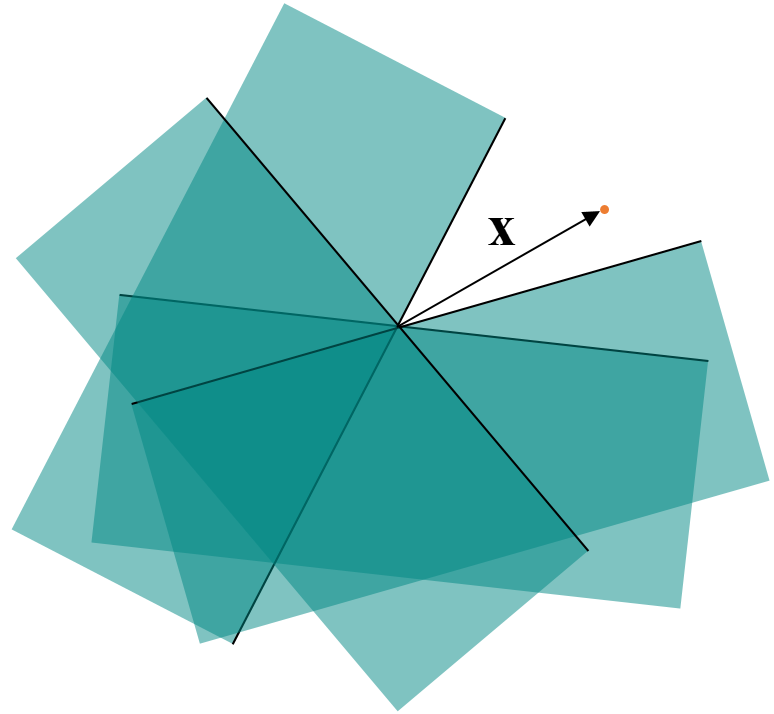
LSH pour la distance cosinus. Considérons les fonctions de hachage élémentaires \(h \in \mathcal{H}_{\cos}\), \(h:\mathbb{R}^m \rightarrow \{0, 1\}\) définies par
avec \(\mathbf{v} \in \mathbb{R}^m\) tiré suivant la loi uniforme sur l’hypersphère unité (\(\|\mathbf{v}\| = 1\)). L’ensemble \(\mathcal{H}_{\cos}\) est un ensemble de fonctions de hachage \((r_1, r_2, 1-\frac{r_1}{180}, 1-\frac{r_2}{180})\)-sensibles (les angles et les distances cosinus entre vecteurs, donc \(r_1, r_2\) également, sont ici mesurés en degrés). Une telle fonction élémentaire associe une valeur de hash égale à 0 aux données situées d’un côté de l’hyperplan de vecteur normal \(\mathbf{v}\) (et passant par l’origine des axes) et à 1 aux données situées de l’autre côté (voir la figure suivante).
Pour justifier le résultat concernant l’ensemble \(\mathcal{H}_{\cos}\), nous remarquerons que \(h_{\mathbf{v}}(\mathbf{x}) \neq h_{\mathbf{v}}(\mathbf{y})\) si et seulement si l’hyperplan de vecteur orthogonal \(\mathbf{v}\) passe entre \(\mathbf{x}\) et \(\mathbf{y}\). La probabilité pour que cela arrive est \(\frac{d_{\cos}(\mathbf{x}, \mathbf{y})}{180}\), donc la probabilité de collision (\(h_{\mathbf{v}}(\mathbf{x}) = h_{\mathbf{v}}(\mathbf{y})\)) est \(1 - \frac{d_{\cos}(\mathbf{x}, \mathbf{y})}{180}\). Si \(d_{\cos}(\mathbf{x}, \mathbf{y}) < r_1\) alors la probabilité de collision est supérieure à \(p_1 = 1 - \frac{r_1}{180}\), si \(d_{\cos}(\mathbf{x}, \mathbf{y}) \geq r_2\) alors la probabilité de collision est inférieure ou égale à \(p_2 = 1 - \frac{r_2}{180}\).
L’exemple suivant illustre la composition de 4 fonctions élémentaires de \(\mathcal{H}_{\cos}\) dans une même table de hachage (ou fonction composée \(h_{\texttt{AND}}\)) pour des données de \(\mathbb{R}^2\) :
Fig. 42 Composition de 4 fonctions LSH pour la distance cosinus¶
Nous avons vu dans le chapitre précédent comment LSH était employé pour réduire l’ordre de complexité de la recherche par similarité (et, par conséquent, d’autres opérations qui peuvent faire appel à la recherche par similarité). Regardons maintenant comment est réalisée la jointure par similarité avec LSH.
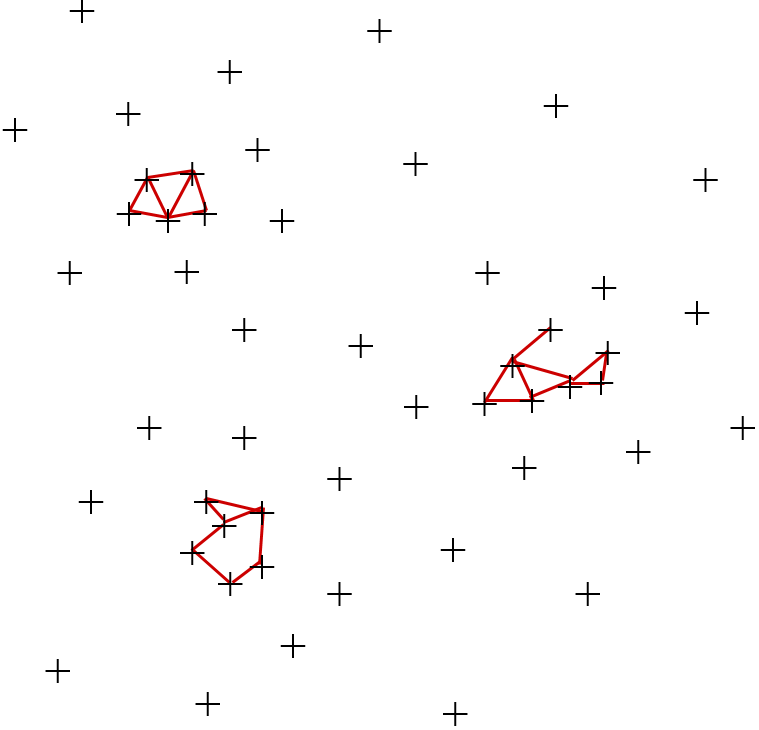
Examinons d’abord l’auto-jointure par similarité, la solution sera ensuite généralisée à la jointure. Étant donné un ensemble \(\mathcal{D}\) à \(N\) éléments et un seuil de distance \(\theta\), l’auto-jointure par similarité consiste à trouver les paires d’éléments de \(\mathcal{D}\) qui sont à une distance inférieure au seuil, c’est à dire \(K_{\theta} = \{(\mathbf{x},\mathbf{y}) | \mathbf{x}, \mathbf{y} \in \mathcal{D}, d(\mathbf{x},\mathbf{y}) \leq \theta\}\).
La figure suivante présente un exemple avec \(\mathcal{D} \subset \mathbb{R}^2\) ; les traits rouges identifient les paires de points \(\mathbf{x},\mathbf{y}\) pour lesquels \(d(\mathbf{x},\mathbf{y}) \leq \theta\}\).
LSH permet de réduire l’ordre de complexité de l’auto-jointure en évitant de calculer la distance entre des données qui ne sont pas suffisamment similaires. Plus précisément, une auto-jointure par similarité utilisant LSH se déroule suivant trois étapes :
Construction des fonctions de hachage. Une famille de fonctions LSH élémentaires est choisie suivant la nature des données et la distance employée. Ensuite, l”« amplification » est réglée en fonction du seuil de distance \(\theta\), ainsi que du coût de calcul et de stockage qui augmentent avec \(n\) (nombre de fonctions par table de hachage) et avec \(t\) (nombre de tables). On obtient la fonction \(h_{\texttt{OR,AND}}\) à utiliser.
Application de la fonction de hachage à toutes les données. Pour chaque valeur de \(h_{\texttt{OR,AND}}\), les données pour lesquelles le hash a cette valeur forment un bucket (une page).
Auto-jointure par similarité à l’intérieur de chaque bucket non vide : calcul des distances \(d(\mathbf{x},\mathbf{y})\) pour tout \(\mathbf{x} \neq \mathbf{y}\), \(\mathbf{x}, \mathbf{y} \in\)bucket.
Avec un calcul exhaustif des distances, la complexité de l’auto-jointure par similarité est \(\frac{N(N-1)}{2}\). Avec LSH, la complexité est \(O(N)\) pour l’étape (2), alors que pour l’étape (3) la complexité dépend de la cardinalité du résultat (souvent \(O(N)\) également). Rappelons que l’utilisation de LSH produit en général une solution approximative. Plus précisément, l’étape (3) éliminant les éventuels faux positifs (données éloignées mais trouvées quand même en collision avec la fonction LSH considérée), restera le problème des faux négatifs (données très similaires mais qui ne sont pas en collision par LSH). La précision sera donc égale à 1 mais le rappel en général inférieur à 1.
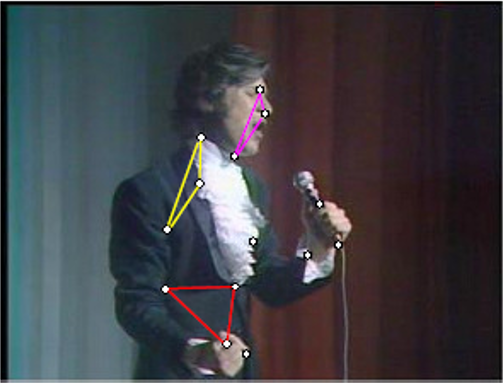
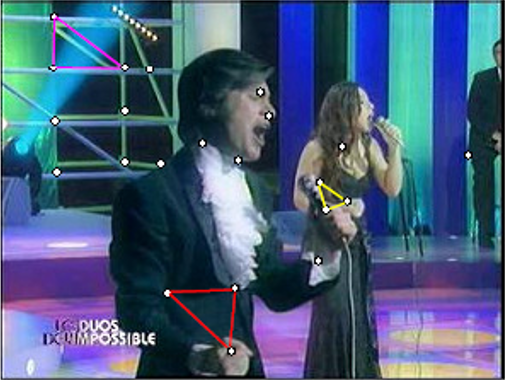
Pour illustrer l’auto-jointure par similarité avec LSH, nous présentons brièvement un exemple issu de [PCB08]. L’objectif du travail était de trouver, dans une base de vidéos, des séquences dupliquées avec transformations. La figure suivante montre une trame vidéo originale (à gauche) et une trame vidéo qui est une copie transformée de la première (le personnage de la première a été incrusté dans une autre vidéo).
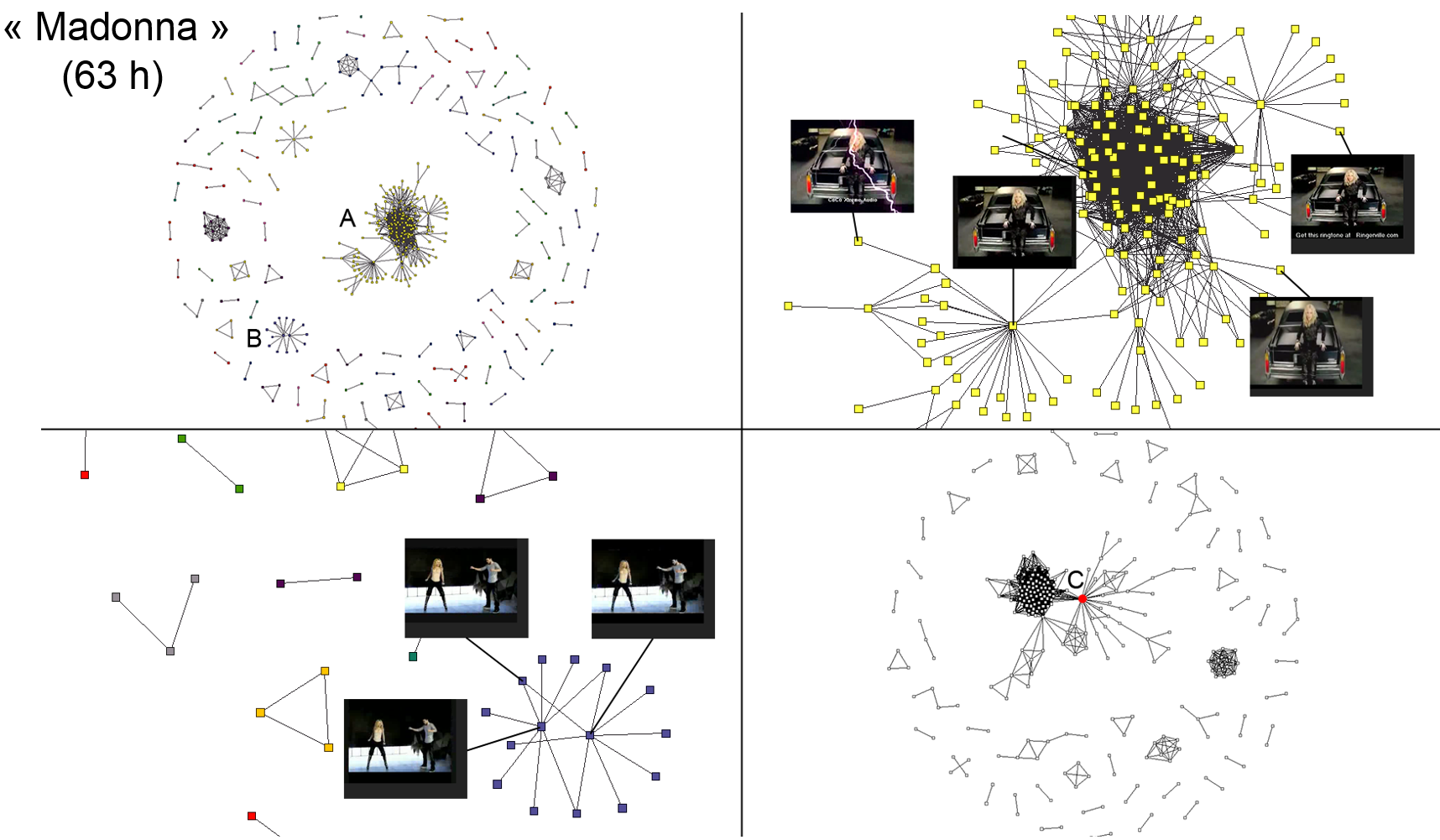
Les données sont les trames des vidéos de la base (sélectionner env. une trame par seconde suffit), décrites par un ensemble de descripteurs photométriques locaux de « points d’intérêt » (correspondant globalement à des « coins » dans l’image) détectés automatiquement. La métrique utilisée compte les triplets similaires de points d’intérêt entre les images (trames vidéo) comparées. Une famille de fonctions LSH spécifiques a été mise au point pour ce problème et est basée sur l’indice de Jaccard appliqué aux ensembles de triplets de points, avec la prise en compte d’une caractéristique géométrique simple du triplet. La figure suivante montre les résultats obtenus sur les 63 heures de vidéo qui cumulent les 1000 premières réponses de YouTube à une requête avec le mot clé « Madonna ». Chaque composante connexe correspond à des séquences similaires deux à deux. En haut à gauche le graphe est directement issu des séquences vidéo similaires, alors qu’en bas à droite le graphe est issu de vidéos entières entre lesquelles on trouve des séquences similaires ; le point rouge correspond à une compilation vidéo.
Fig. 46 Auto-jointure par similarité avec LSH pour l’extraction de quasi-duplicats dans une base de vidéos¶
L’utilisation de LSH peut être facilement généralisée au traitement des jointures par similarité. Une jointure entre \(\mathcal{D}_1\) (de cardinalité \(N_1\)) et \(\mathcal{D}_2\) (de cardinalité \(N_2\)), avec un seuil de distance \(\theta\), permet de trouver les paires d’éléments des deux ensembles qui sont à une distance inférieure au seuil\(K_{\theta} = \{(\mathbf{x},\mathbf{y}) | \mathbf{x} \in \mathcal{D}_1, \mathbf{y} \in \mathcal{D}_2, d(\mathbf{x},\mathbf{y}) \leq \theta\}\). La jointure avec LSH suit les mêmes trois étapes indiquées pour l’auto-jointure :
Construction des fonctions de hachage. Pour qu’une distance soit calculée entre \(\mathbf{x} \in \mathcal{D}_1\) et \(\mathbf{y} \in \mathcal{D}_2\), les deux ensembles doivent être des sous-ensembles d’un même espace métrique. Une même fonction \(h_{\texttt{OR,AND}}\) sera employée pour les deux espaces.
Application de la fonction de hachage à toutes les données de \(\mathcal{D}_1\) et \(\mathcal{D}_2\).
Jointure par similarité à l’intérieur de chaque bucket (non vide) : calcul des distances \(d(\mathbf{x},\mathbf{y})\) pour tout \(\mathbf{x} \in \mathcal{D}_1, \mathbf{y} \in \mathcal{D}_2\), avec \(\mathbf{x}, \mathbf{y} \in\)bucket.
Les données massives sont souvent caractérisées par un nombre élevé de variables, dont certaines peuvent exiger un nombre élevé de dimensions pour être représentées. C’est le cas, par exemple, pour une variable nominale qui a de nombreuses modalités ou pour une variable « ensemble » pour laquelle l’ensemble total est de grande cardinalité.
La grande dimension de la représentation des données engendre un certain nombre de difficultés regroupées sous le nom de « malédiction de la dimension » (ou « fléau de la dimension », curse of dimensionality). Ces difficultés peuvent être majeures et concernent aussi bien la modélisation statistique des données que l’efficacité des algorithmes d’organisation ou de recherche dans ces données. Nous résumons ici quelques-unes de ces difficultés :
A nombre de données fixé, la densité diminue exponentiellement avec la dimension. Les données deviennent « rares » ou « isolées » dans l’espace. Il n’est plus possible d’estimer la densité de façon fiable et différents tests statistiques deviennent inexploitables. Le nombre de données devrait augmenter de façon exponentielle avec la dimension pour conserver les capacités de modélisation.
Les données uniformément distribuées dans des volumes en dimension \(d\) sont proches des hypersurfaces externes (de dimension \(d-1\)). Par exemple, si on considère une (hyper-)sphère inscrite dans un (hyper-)cube, comme dans la figure suivante (illustration en 2D), le rapport entre le volume de l’hypersphère et le volume de l’hypercube diminue rapidement avec l’augmentation de la dimension, comme indiqué dans le tableau qui suit. Cela implique que la plupart des données de l’hypercube ne sont pas dans l’hypersphère mais plutôt dans les « coins » de l’hypercube. Supposons qu’on utilise LSH pour la distance euclidienne afin de retourner les données situées dans un rayon autour d’une requête qui serait le centre de l’hypersphère. On constate que la plupart des données du même bucket que la requête (bucket qui sera, dans le meilleur des cas, un hyper-parallélépipède) ne seront pas dans l’hypersphère et devront être filtrées par des calculs de distance pour conserver une bonne précision (éliminer les faux positifs). Quand la dimension augmente, le nombre de données à filtrer sera beaucoup plus grand que celui des données utiles.
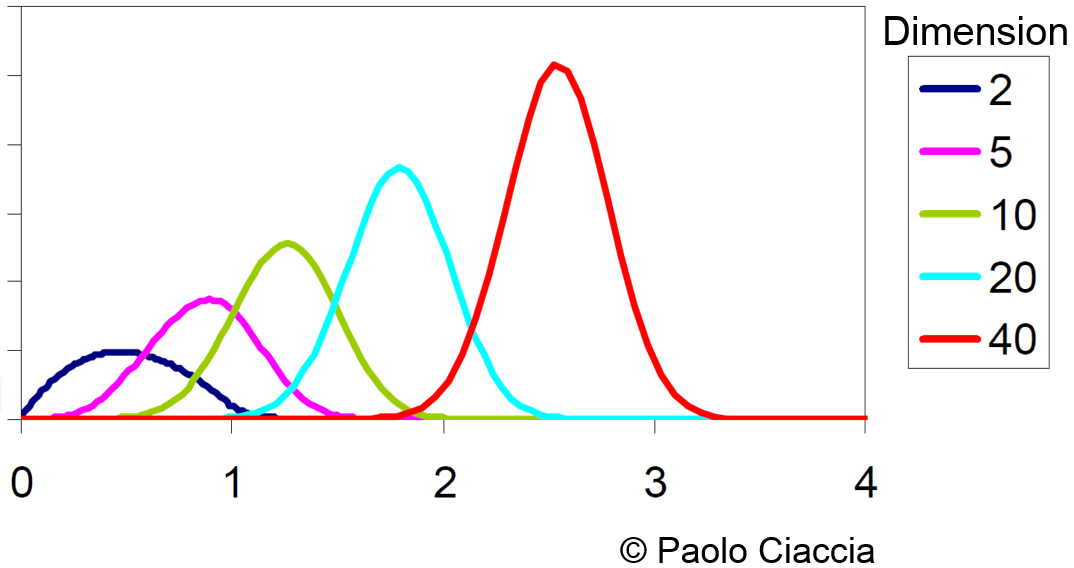
La variance de la distribution des distances entre données diminue avec l’augmentation de la dimension (voir la figure suivante). Cette difficulté, qui est une des manifestations de la « concentration des mesures », peut rendre inexploitable la décision sur la base des k plus proches voisins car la représentativité de ces voisins pour une donnée devient comparable à la représentativité des autres données. Aussi, il devient difficile de trouver des regroupements dans les données (les données à l’intérieur d’un groupe ne sont pas tellement plus proches entre elles que des données d’autres groupes), donc l’intérêt de la classification automatique diminue. Enfin, la troisième condition que nous avons mentionnée dans le chapitre précédent (« les données proches de la requête sont bien plus proches que les autres ») devient fausse et les index perdent leur efficacité dans la réduction de la complexité de la recherche.
Fig. 47 Concentration des mesures pour des données qui suivent une distribution uniforme¶
Il est important de mentionner ici deux facteurs modérateurs de la malédiction de la dimension :
La distribution des données a une grande importance dans la gravité de la malédiction de la dimension. Plus la distribution des données est non uniforme, plus élevée est la dimension à partir de laquelle les capacités de modélisation et l’efficacité des index diminuent de façon sensible.
La dimension des données peut éventuellement être réduite par différentes méthodes, comme nous l’avons vu dans un cours précédent. La dimension qui compte sera la « dimension intrinsèque » des données, qui peut être bien plus faible que la dimension apparente. Plusieurs définitions formelles existent pour la notion de « dimension intrinsèque », certaines proposent des estimateurs opérationnels.
« Don’t listen to your feelings, listen to the algorithm, it knows you better. »
(an algorithm)
Les systèmes de recommandation (SRec) visent à proposer des « articles » (items) à des « utilisateurs » (users). Employés au départ dans le commerce en ligne, leur domaine d’application ne cesse de s’élargir : musique, films, livres, sites web, blogs, destinations de voyages, applications pour mobiles, publications de recherche, etc. Les SRec intègrent des informations de différents types, issues de plusieurs sources, explicites ou implicites : caractéristiques des utilisateurs et des articles, filtrage collaboratif, liens sociaux entre utilisateurs, données issues des capteurs (par ex. GPS), etc.
Nous examinerons dans la suite de ce chapitre la problématique des SRec et passerons en revue les principales familles de méthodes utilisées pour obtenir des recommandations. Une synthèse des premières approches employées pour les SRec en général peut être trouvée dans [BOH13]. Quelques méthodes qui exploitent l’apprentissage profond sont présentées dans [ZYS17]. Il est également intéressant de lire [BGL15], une synthèse sur les SRec de publications de recherche.
Dans un SRec nous sommes en présence de deux types d’entités, les utilisateurs et les articles. Chaque utilisateur peut choisir et/ou noter un ou plusieurs articles. Les données disponibles concernant les choix passés (ou les notes) sont représentées sous la forme d’une matrice d”« utilités », chaque utilisateur étant associé à une ligne et chaque article à une colonne, comme dans la figure suivante :
Lorsque les données disponibles correspondent à des informations explicites, par ex. issues d’achats effectués ou de notes données, cette matrice est très creuse. Si des informations implicites sont également présentes, par ex. issues des durées de visualisation des pages décrivant des articles (un utilisateur a tendance à regarder plus longtemps la description d’un article qui l’intéresse et éventuellement à revenir sur cette description lors de sessions successives), alors la matrice sera (un peu) moins creuse.
L’objectif général d’une méthode de recommandation est de prédire les valeurs manquantes de la matrice, c’est à dire les choix que ferait chaque utilisateur s’il devait se prononcer sur chaque article ou les notes qu’il donnerait s’il devait évaluer tous les articles. Naturellement, lorsque la matrice contient des notes, ce sont en général les valeurs élevées prédites qui intéressent car elles correspondent (si la prédiction est fiable) à des articles que l’utilisateur apprécierait et que le SRec pourrait donc utilement lui proposer.
Les SRec emploient une des approches suivantes :
Recommandation par similarité de contenu (content-based filtering). Pour ces méthodes, un accès à des descriptions des articles est indispensable. Le principe est le suivant : à partir des descriptions des articles choisis ou notés par un utilisateur (ainsi que d’éventuelles informations concernant l’utilisateur directement), un profil de l’utilisateur est construit ; sont ensuite proposés à l’utilisateur des articles dont les caractéristiques sont similaires à son profil. Plus le nombre d’article choisis ou notés par un utilisateur est élevé, plus le profil ainsi obtenu est fiable (et donc les recommandations faites sur la base de ce profil). La recommandation étant réalisée à partir des caractéristiques des articles, il est facile d’identifier des articles de substitution lorsque l’article envisagé n’est plus disponible. En revanche, il est clairement difficile d’extrapoler d’un domaine à un autre. Par exemple, connaître les lectures préférées d’un utilisateur donne peu d’indications sur ses goûts musicaux.
Recommandation par filtrage collaboratif (collaborative filtering). Ces méthodes se basent uniquement sur la matrice d’utilités, aucune connaissance intrinsèque des articles n’est nécessaire. La matrice d’utilités permet de définir des similarités entre utilisateurs à partir des articles choisis, ainsi que des similarités entre articles à partir des utilisateurs qui les ont choisis. Le principe est alors de proposer à un utilisateur des articles similaires à ceux qu’il a déjà choisi (ou bien noté), ou alors des articles choisis (ou bien notés) par les utilisateurs similaires. Les similarités n’étant pas liées aux caractéristiques intrinsèques des articles, les prédictions dans un domaine peuvent être faites à partir de données concernant d’autres domaines (l’hypothèse d’une cohérence relative inter-domaines est sous-jacente). En revanche, l’ignorance des caractéristiques des articles rend difficile la substitution d’articles manquants.
Recommandation hybride. Bien entendu, lorsque l’on possède à la fois des descriptions des articles et une matrice d’utilités il est souhaitable de tirer profit de ces deux sources d’information pour améliorer les prédictions. Les SRec actuels emploient en général des combinaisons de méthodes suivant les deux approches précédentes.
Suivant la nature des articles, leur description peut inclure des variables diverses. On rencontre souvent des variables ensemble, par ex. pour des films de cinéma les acteurs, les prix obtenus ou l’ensemble de mots d’une description textuelle. Les variables nominales, dont les modalités correspondent souvent aux sous-catégories d’une catégorie, sont également présentes (par ex. le genre d’un film). Enfin, des variables quantitatives peuvent avoir leur importance, par ex. pour des films de cinéma le budget de réalisation ou les recettes lors de la sortie en salles.
Les variables qui interviennent dans les descriptions peuvent être pondérées par des méthodes simples, par ex. term frequency x inverse document frequency (degré de présence x « potentiel discriminant ») pour les éléments d’ensembles, voir le chapitre suivant. D’autres méthodes de pondération tiennent compte d’un « potentiel explicatif » défini par exemple à partir de l’homogénéité des notes données par des utilisateurs similaires. Enfin, des méthodes de pondération plus complexes peuvent être utilisées lorsque, plutôt qu’une simple recherche par similarité, des modèles décisionnels sont mis en œuvre.
Des méthodes de réduction de dimension sont souvent appliquées en présence de variables de type ensemble avec un grand nombre d’éléments (par ex. description textuelle). Cela permet de résumer les variables initiales par un plus petit nombre de variables (révéler des « facteurs »), ce qui diminue en général le « bruit » présent dans les descriptions et réduit la gravité de la malédiction de la dimension.
La recommandation par similarité de contenu peut employer
La recherche par similarité : sont proposés à l’utilisateur des articles dont les descriptions sont les plus similaires au profil de l’utilisateur. Dans ce cas, le profil d’un utilisateur possède les mêmes variables que les descriptions des articles afin de permettre une comparaison directe avec ces descriptions. La représentation d’un profil est un vecteur qui a la même structure que les représentations des descriptions des articles. Le profil d’un utilisateur est en général obtenu comme la moyenne des descriptions des articles choisis et/ou notés par cet utilisateur. Dans le calcul de la moyenne, les descriptions des articles notés sont pondérées par les notes accordées par l’utilisateur. Des variantes de calcul consistent à approcher le profil des articles bien notés par l’utilisateur tout en l’éloignant des articles qu’il a mal notés. L’utilisation typique est la suivante : lorsqu’un utilisateur se connecte, son profil est employé comme une requête dans la base des articles disponibles et les articles les plus similaires sont affichés. Il est toutefois possible d’utiliser de façon différente les vecteurs qui représentent les descriptions des articles et les profils des utilisateurs. Par exemple, une jointure par similarité entre l’ensemble des descriptions d’articles et l’ensemble des profils d’utilisateurs peut retourner un ensemble de paires <article, utilisateur> très pertinentes qui peuvent faire l’objet d’une campagne promotionnelle passant par l’envoi de courriels (push) alors que les utilisateurs ne sont pas connectés.
Des modèles décisionnels : sont proposés à l’utilisateur les articles pour lesquels le modèle décisionnel spécifique à l’utilisateur prédit les meilleures notes. Dans ce cas, le profil d’un utilisateur est un modèle décisionnel construit à partir des articles choisis et/ou notés par cet utilisateur. Ce modèle peut employer aussi des variables prédictives spécifiques aux utilisateurs (par ex. catégorie socio-professionnelle, plate-forme matérielle et logicielle employée pour se connecter au site, âge, localisation géographique, etc.) et non simplement leurs choix d’articles. L’emploi de modèles décisionnels permet d’obtenir des fonctions de décision (de recommandation) plus complexes que la simple similarité vectorielle. En revanche, la construction d’un modèle décisionnel fiable exige un volume de données plus important par utilisateur qu’une simple recherche par similarité. Pour disposer de plus de données, il est préférable de développer un modèle par groupe d’utilisateurs très similaires plutôt que par utilisateur individuel.
La disponibilité de descriptions des articles permet de définir des critères pragmatiques complémentaires pour améliorer les recommandations, par ex. réduire la redondance des propositions (éviter de proposer plusieurs articles très similaires entre eux) ou augmenter la diversité (proposer des articles appartenant à des « familles » différentes plutôt que plusieurs articles d’une même famille).
Ces méthodes considèrent que les utilisateurs, comme les articles, sont décrits essentiellement (ou exclusivement) par le contenu de la matrice de données \(\mathbf{X}\) (issue des notes ou des choix passés) :
Chaque utilisateur est associé à une ligne et chaque article à une colonne. On note par \(n_u\) le nombre d’utilisateurs et par \(n_a\) le nombre d’articles. \(\mathbf{X}\) est donc une matrice \(n_u \times n_a\). La matrice de données peut subir diverses transformations (par exemple des normalisations) avant d’être utilisée pour obtenir les recommandations.
Nous pouvons mentionner plusieurs familles de méthodes de filtrage collaboratif :
Méthodes basées sur la similarité (memory-based) : la similarité entre utilisateurs ou entre articles est employée pour obtenir des recommandations. Nous remarquerons que les utilisateurs (lignes de la matrice de données) et les articles (colonnes de la matrice de données) ne sont pas directement comparables.
La matrice de données est « normalisée » : la moyenne des notes présentes devrait être nulle pour chaque utilisateur (ligne de la matrice) afin d’équilibrer les « niveaux d’exigence » des utilisateurs. Les moyennes des notes présentes restent en général différentes entre articles (colonnes de la matrice), ces écarts reflètent des différences de (perception de la) « qualité intrinsèque » entre articles. On parle de « profils » lignes (ou « profils » utilisateurs) et de « profils » colonnes (ou « profils » articles). Pour comparer les lignes entre elles ou les colonnes entre elles sont employées en général la distance cosinus ou la corrélation linéaire (qui est une mesure de similarité et non une distance). On peut distinguer deux types de méthodes :
User-based (la similarité est calculée entre utilisateurs) : (i) trouver les utilisateurs les plus « représentatifs » (par ex. les k les plus similaires) pour l’utilisateur cible \(u\), ensuite (ii) agréger leurs choix pour faire des propositions à \(u\) (par ex. les articles les plus choisis ou les mieux notés par ces \(k\) « voisins »). Une difficulté importante de cette approche est la présence d’une grande diversité parmi les utilisateurs : par ex. \(x\) apprécie la musique classique et le jazz, alors que \(u\) apprécie la musique classique mais pas le jazz ; si la matrice de données contient pour \(u\) uniquement des données concernant la musique classique, \(u\) recevrait des propositions de jazz (faites à partir de \(x\) qui est très similaire à \(u\)) qui seraient erronées.
Item-based (la similarité est calculée entre articles) : (i) répertorier les articles \(a_i\) choisis (ou bien notés) par l’utilisateur \(u\), ensuite (ii) proposer à \(u\) les articles les plus similaires aux \(a_i\) (c’est à dire choisis ou bien notés ensemble par d’autres utilisateurs). Comme le nombre d’utilisateurs est souvent supérieur au nombre d’articles, la dimension des « profils » articles est supérieure à la dimension des « profils » utilisateurs, la malédiction de la dimension peut donc se manifester avec plus de force pour les « profils » articles.
Méthodes basées sur un modèle (model-based) : un modèle (par ex. catégorisation des utilisateurs et des articles, facteurs explicatifs latents) est obtenu à partir de la matrice de données et sert à la prise de décisions de recommandation. Une telle méthode est présentée avec plus de détails dans la suite.
Méthodes hybrides. Ces méthodes sont des combinaisons de méthodes des deux familles précédentes.
Le « démarrage à froid » (cold start) est l’étape initiale de fonctionnement d’un système de recommandation, durant laquelle la matrice des utilités est vide ou vraiment très creuse car très peu d’utilisateurs ont employé le système. Le démarrage à froid exige des approches spécifiques, comme par exemple exploiter le profil démographique des utilisateurs et des connaissances a priori qui lient profil démographique et préférences, ou tirer profit des préférences explicitement renseignées par certains utilisateurs lors de la création de leurs profils. Il est également envisageable de proposer à tous les utilisateurs comme recommandation « par défaut » les items les plus populaires et/ou les plus récents.
Filtrage collaboratif basé sur la factorisation matricielle¶
Le principe de ces méthodes est de chercher des facteurs latents, en nombre relativement faible (souvent de l’ordre de \(10^2\)), qui « expliquent » le contenu de la matrice de données. Dans ce cadre, les articles comme les utilisateurs sont décrits par des vecteurs de même dimension, cette dimension étant donnée par le nombre de facteurs latents considérés. Dans la description d’un article, les composantes correspondent aux valeurs prises par les facteurs latents respectifs pour cet article. Dans la description d’un utilisateur, les composantes correspondent aux contributions des facteurs latents respectifs à la note que l’utilisateur donnerait à un article.
Une des premières méthodes de factorisation explorées a été la décomposition en valeurs singulières (Singular Value Decomposition, SVD) de la matrice de données (ou utilisateurs-articles) \(\mathbf{X}\), avec approximation de rang réduit \(m\) :
Ici \(\Sigma\) est une matrice diagonale \(m \times m\) qui donne sur sa diagonale principale les poids des \(m\) facteurs. Chacune des \(n_a\) colonnes de \(\mathbf{A}^t\) est la représentation « réduite » (de dimension \(m\), égale au nombre de facteurs) d’un article. Chacune des \(n_u\) lignes de \(\mathbf{U}\) (de dimension \(m\)) est la représentation « réduite » d’un utilisateur. La figure suivante illustre cette factorisation :
Cette méthode souffre d’un problème majeur : la décomposition exige une matrice complète, or la matrice utilisateurs-articles (\(\mathbf{X}\)) est très creuse, les valeurs absentes sont manquantes et non équivalentes à des 0. Une décomposition qui assimilerait les valeurs absentes à 0 donnerait une solution non pertinente.
Il est donc nécessaire de tenir compte exclusivement des données présentes dans la matrice. Avec une matrice utilisateurs-articles très creuse le problème est sous-déterminé, une solution de régularisation est nécessaire.
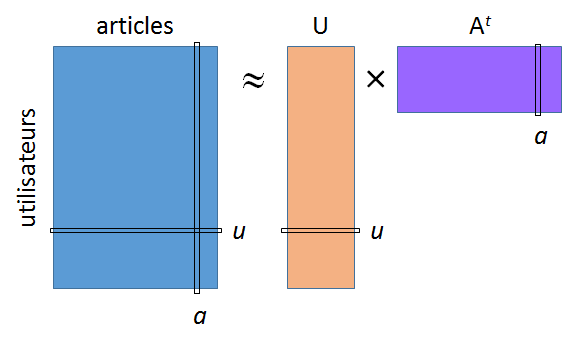
La factorisation régularisée (voir par ex. [Pat07], [KBV09]) correspond à une famille de méthodes qui cherchent une approximation de rang \(m\) réduit tenant compte seulement des valeurs présentes dans la matrice \(\mathbf{X}\) et incluant une technique de régularisation. Le problème d’optimisation correspondant fréquemment employé est le suivant :
Cette factorisation est illustrée dans la figure suivante :
Ici \(\mathbf{u}_i\) est la représentation « réduite » (de dimension \(m\), égale au nombre de facteurs) d’un utilisateur et \(\mathbf{a}_j\) est la représentation « réduite » (de dimension \(m\)) d’un article. La constante \(\lambda\) contrôle la régularisation.
Le problème de minimisation est résolu par des algorithmes itératifs comme les moindres carrés alternés (dans Spark, par exemple) ou la descente de gradient stochastique.
Après avoir trouvé les \(\mathbf{u}_i\) et \(\mathbf{a}_j\) pour tous les utilisateurs et respectivement tous les articles, la prédiction de la note que devrait donner l’utilisateur \(k\) à l’article \(l\) (note inconnue) est :
La factorisation régularisée (3) et l’algorithme de résolution itérative associé permettent d’intégrer dans le modèle d’autres aspects (voir par ex. [KBV09]) comme :
La modélisation d’un biais par utilisateur et d’un biais par article. Plutôt que d’employer la solution simple, mentionnée plus haut, de « normalisation » de la matrice de données (imposer, pour chaque ligne, une moyenne nulle pour les notes présentes afin d’équilibrer les niveaux d’exigence des utilisateurs), il est possible d’estimer les biais de notation par utilisateur et par article. Le problème d’optimisation correspondant est
où \(\mu\) est la moyenne globale des notes présentes, \(b_{\mathbf{u}_i}\) le biais pour l’utilisateur \(i\) et \(b_{\mathbf{a}_j}\) le biais pour l’article \(j\).
La modélisation de niveaux de confiance dans les notes présentes dans la matrice de données. En effet, il peut être nécessaire de moduler l’impact des différentes notes à partir de connaissances concernant les utilisateurs, le mode d’acquisition de l’information, etc. Le problème d’optimisation est dans ce cas
où \(c_{ij}\) est la confiance dans la note donnée par l’utilisateur \(i\) à l’article \(j\) ou, plus généralement, une pondération (dont la signification n’est pas nécessairement celle de degré de confiance) de cette note. Les \(c_{ij}\) sont des données d’entrée de l’algorithme et non obtenus par l’optimisation.
où \(n_i\) est le nombre total de notes données par l’utilisateur \(i\) et \(n_j\) est le nombre total de notes reçues par l’article \(j\).
Ce problème de minimisation est résolu par l’algorithme itératif Alternating Least Squares (ALS). A chaque itération de l’algorithme on alterne deux phases :
avec \(\mathbf{u}_i\) fixés, \(1 \leq i \leq n_u\), on obtient les \(\mathbf{a}_j\), \(1 \leq j \leq n_a\), comme solution d’un système linéaire (de façon similaire à la solution des moindres carrés pour une régression linéaire) ;
avec \(\mathbf{a}_j\) fixés, \(1 \leq j \leq n_a\), on obtient les \(\mathbf{u}_i\), \(1 \leq i \leq n_u\), comme solution d’un système linéaire (de façon similaire à la solution des moindres carrés pour une régression linéaire).
La fonction à minimiser (5) n’est pas convexe dans ses arguments \(\mathbf{u}_i\) et \(\mathbf{a}_j\) mais pour \(\mathbf{u}_i\) fixés elle est convexe en \(\mathbf{a}_j\) et pour \(\mathbf{a}_j\) fixés convexe en \(\mathbf{u}_i\). ALS converge donc vers un minimum qui n’est pas nécessairement global, il est donc utile de faire plusieurs essais avec des initialisations différentes.
Beel, J., B. Gipp, S. Langer, C. Breitinger. Research-paper recommender systems: a literature survey. International Journal on Digital Libraries, pages 1–34, 2015.
Paterek, A. Improving regularized singular value decomposition for collaborative filtering. Dans Proc. KDD Cup Workshop at SIGKDD’07, 13th ACM Int. Conf. on Knowledge Discovery and Data Mining, pages 39–42, 2007.
Poullot, S., Crucianu, M., Buisson, O. Scalable Mining of Large Video Databases Using Copy Detection, Dans Proceedings of ACM Multimedia 2008, Vancouver, Canada, 27-30 octobre 2008, pp. 61-70.
Zhou, Y., D. Wilkinson, R. Schreiber, R. Pan. Large-scale parallel collaborative filtering for the netflix prize. Dans Proceedings of the 4th International Conference on Algorithmic Aspects in Information and Management, AAIM’08, pages 337–348, Berlin, Heidelberg, 2008. Springer-Verlag.


 \[\begin{split}\begin{array}{|c|l|} \hline \textrm{Dimension} & \textrm{Volume sphère / volume cube englobant}\\ \hline 1 & 1\\ 2 & 0,78732\\ 4 & 0,329707\\ 6 & 0,141367\\ 8 & 0,0196735\\ 10 & 0,00399038\\ \hline \end{array}\end{split}\]
\[\begin{split}\begin{array}{|c|l|} \hline \textrm{Dimension} & \textrm{Volume sphère / volume cube englobant}\\ \hline 1 & 1\\ 2 & 0,78732\\ 4 & 0,329707\\ 6 & 0,141367\\ 8 & 0,0196735\\ 10 & 0,00399038\\ \hline \end{array}\end{split}\]