Le travail présenté a été inspiré par une présentation de Peter Eades, Professeur émérite de l’université de Sydney, spécialiste reconnu du sujet.
L’objectif de la modélisation d’un problème sous la forme d’un graphe, c’est de
se donner des outils conceptuels pour l’analyser (efficacement), comme nous
l’avons vu dans le chapitre d’introduction à la fouille de graphes et dans le chapitre sur la détection de communautés). Au-delà de l’obtention de résultats
avec des indicateurs classiques (densité, diamètre, etc.), puisqu’un graphe se
compose de nœuds et de liens, il est assez naturel de visualiser ceux-ci. On
peut espérer accéder à une compréhension directe (ou presque) de la structure du
graphe et du rôle que jouent les nœuds dans le système modélisé. Par exemple,
s’il s’agit d’individus, on pourra identifier quelques motifs, individuels et
collectifs : quelles sont les zones avec une forte/faible densité de connexions,
les individus isolés, ceux qui font le lien entre des zones denses, etc.
La visualisation d’un graphe avec peu de nœuds et de liens s’avère souvent
simple, puisque l’on peut choisir le positionnement des éléments à visualiser
(ou retoucher un positionnement proposé par l’ordinateur”). Mais l’augmentation des
tailles de graphes étudiés aujourd’hui conduit à rechercher des méthodes
efficaces de visualisation, c’est-à-dire permettant d’offrir le maximum de
compréhension et de lisibilité pour un minimum d’effort de la part de l’analyste
: cela passe par la mise au point d’algorithmes d’automatisation. On cherche à
passer, pour un grand nombre de nœuds, d’un placement aléatoire initial et
monochrome à une visualisation colorée et aérée (illustré avec
Fig. 116 et Fig. 117) :
Fig. 116 Placement aléatoire des sommets d’un graphe (dans Gephi)¶
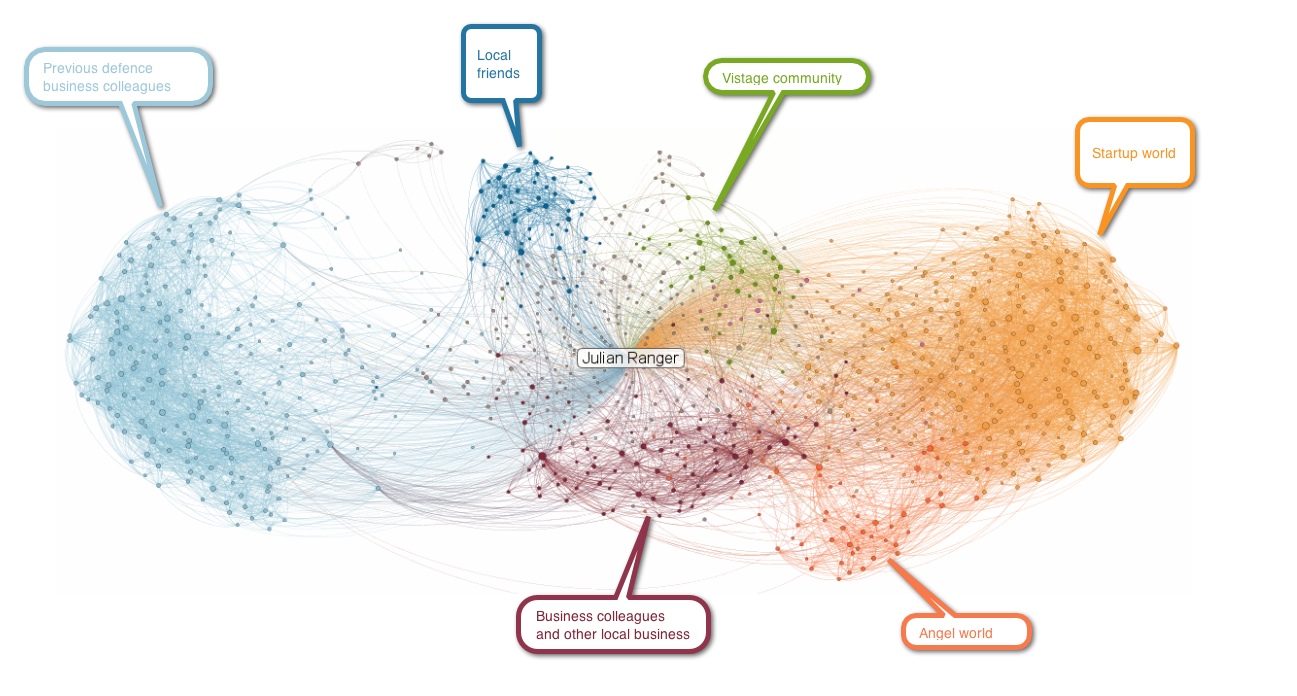
Fig. 117 Visualisation travaillée (couleurs, placement) des communautés professionnelles d’un utilisateur (LinkedIn Maps)¶
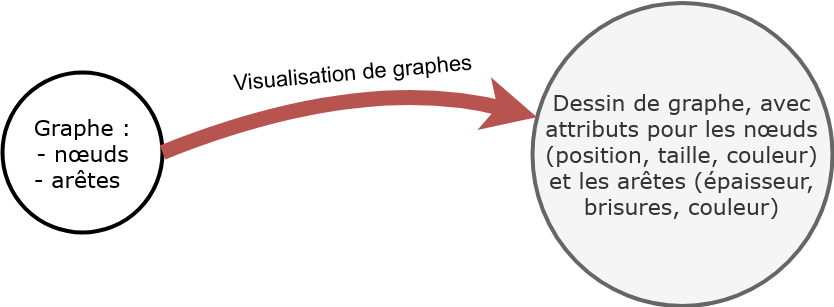
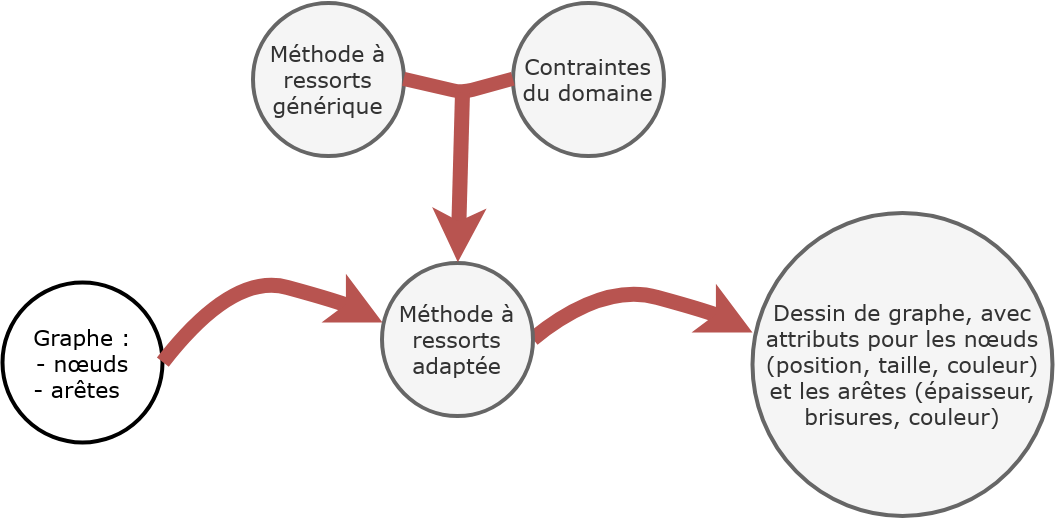
Fig. 118 Le principe de la visualisation de graphes.¶
Un graphe reposant formellement sur un ensemble \(V\) de nœuds et un
ensemble \(E\) d’arêtes, les paramètres de la modélisation seront les
attributs possibles pour les éléments de chacune de ces catégories. Ainsi,
pour les nœuds, on considèrera :
leur position,
leur taille,
leur couleur,
voire, plus rarement, leur forme (circulaire ou non).
Pour les arêtes, il sera possible d’agir sur :
leur forme (courbes, lignes droites ou brisées),
leur position (chevauchements, écart angulaire),
l’épaisseur du trait,
leur couleur.
Mais l’histoire de la discipline a axé la réflexion avant tout sur le
positionnement des nœuds et des arêtes, ainsi que la forme des ces dernières. Les
questions de couleur et de taille sont moins centrales, mais vous pouvez
consulter le chapitre Visualisation d’information pour avoir davantage de précisions.
La suite de ce cours présente les éléments du « dessin de graphes » (pour
reprendre les termes des pionniers), avec une progression proche de la
progression historique de la discipline, conclue par un panorama (évidemment non
exhaustif) des outils et bibliothèques disponibles pour produire des
visualisations. Le cours est complété par une séance de travaux pratiques.
Planarité d’un graphe et qualité de la visualisation¶
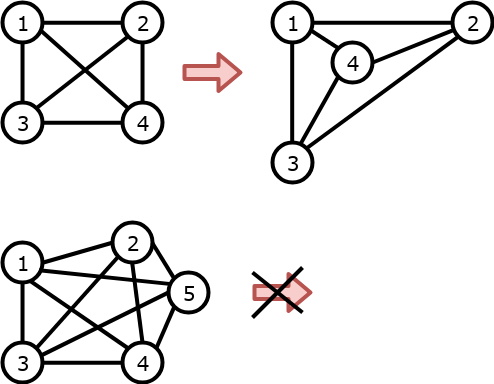
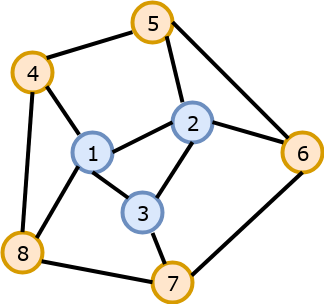
Un graphe est dit planaire s’il existe une représentation dans le plan telle
qu’aucune arête n’en croise une autre. Un graphe est dit non planaire si
toutes ses représentations dans le plan comportent au moins un croisement
d’arêtes.
Fig. 119 Le graphe de 4 sommets est planaire : même si sa représentation initiale comporte un croisement d’arêtes, il existe une représentation de ce graphe sans croisement. Le graphe de 5 sommets n’est pas planaire.¶
Cette notion de planarité, très étudiée en théorie des graphes durant le XXe
siècle pour son intérêt mathématique, est intervenue dans la partie
« visualisation des graphes » à la fin des années 1970, quand des chercheurs ont
eu l’intuition qu’elle pourrait avoir un lien avec la qualité d’une
représentation, ou du moins la faculté des humains à l’interpréter. L’idée est
la suivante : une représentation planaire permet d’obtenir des images nettes et
immédiatement compréhensibles.
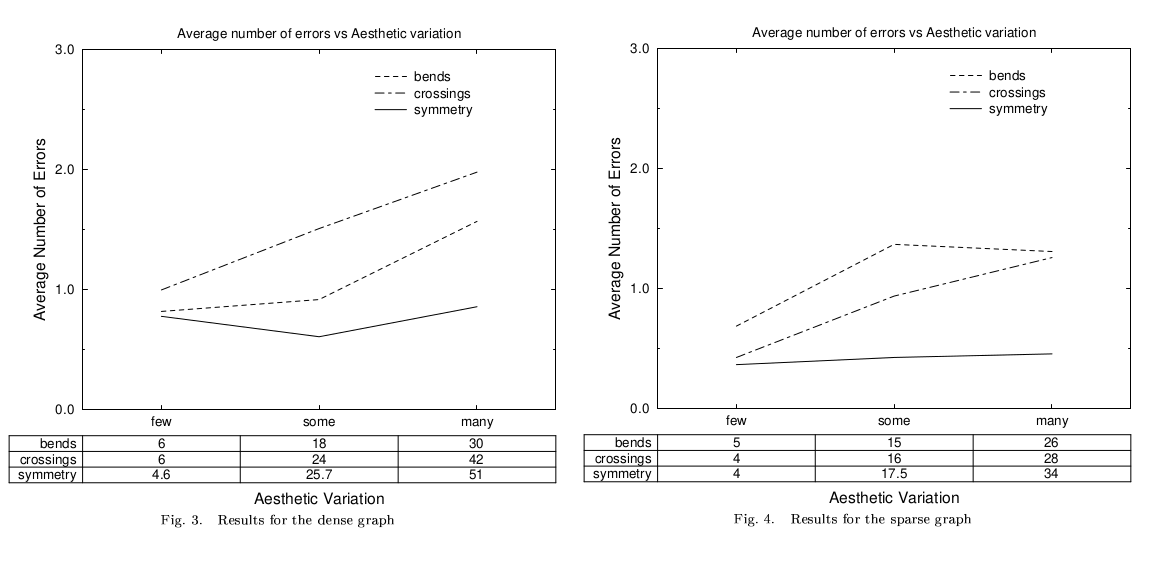
Des travaux ultérieurs ont effectivement montré qu’il y avait des corrélations
significatives entre les erreurs de compréhension et la quantité de croisements
d’arêtes [P97]. De même, les brisures de lignes sont également associées à des
erreurs.
Fig. 120 Les deux ensembles de courbes, extraits de [P97], montrent que le nombre d’erreurs de compréhension de l’image du graphe par des humains croît avec l’augmentation des brisures d’arêtes (bends) et des chevauchements (crossings).¶
En somme, il est naturel de rechercher des représentations d’un graphe où l’on
minimise :
les croisements d’arêtes,
les lignes brisées.
Le théorème de Fáry, du
nom de István Fáry (mais prouvé par d’autres dans la même période), énonce
qu’un graphe simple planaire peut être dessiné sans chevauchements d’arêtes,
avec des lignes droites. Cependant, un théorème assurant l’existence d’une
représentation sans croisements ne donne pas immédiatement accès à celle-ci,
ce théorème a donc peu d’utilité pratique. Par ailleurs, la seule préoccupation pour
l’absence de chevauchements d’arêtes ne garantit pas une interprétation facile de
la structure du graphe. Pour un graphe composé de communautés, par exemple, il peut
être plus important de regrouper les sommets de chaque communauté et de les
éloigner visuellement des sommets des autres communautés plutôt que de privilégier
une représentation sans chevauchements d’arêtes.
Enfin, beaucoup de graphes que l’on rencontrera ne seront pas planaires.
La discipline de la représentation de graphes naît véritablement en 1963 avec la
publication d’un article fondateur, « How to draw a graph » [T63]. Son auteur,
William Tutte, est un
mathématicien anglais brillant, qui était aux côtés d’Alan Turing pour
déchiffrer les codes allemands à Bletchley Park. Il introduit un algorithme
barycentrique pour construire une représentation d’un graphe, capable de
produire des dessins avec des lignes droites (qui se chevauchent
éventuellement).
L’algorithme prend en entrée un graphe \(G = (V,E)\). La sortie de
l’algorithme est une représentation avec les lignes droites dudit graphe, que
l’on appellera \(p\) (et on note \(p(u)\) la position de \(u\) dans
\(p\)).
Voici les étapes de l’algorithme :
on choisit un sous-ensemble de sommets, \(A\), de \(V\)
on choisit une position \(p(a)\) pour chaque sommet \(a \in A\).
pour chaque sommet \(u \in V-A\), on a :
\[p(u) = \frac{1}{deg(u)} \sum_{v \in N(u)} p(v) \quad \mbox{avec }N(u)\mbox{ l'ensemble des voisins de } u\]
Il s’agit de trouver les vecteurs \(\begin{bmatrix} x_{1} \\ x_{2} \\
x_{3} \end{bmatrix}\) et \(\begin{bmatrix} y_{1} \\ y_{2} \\ y_{3}
\end{bmatrix}\) tels que :
Ainsi, le cœur de l’algorithme de Tutte consiste à inverser une matrice. Et il
ne s’agit pas de n’importe quelle matrice, mais de la matrice laplacienne du
graphe (plus précisément : de la sous-matrice correspondant à l’ensemble \(V-A\)
des sommets restant à placer), qui est définie formellement comme suit :
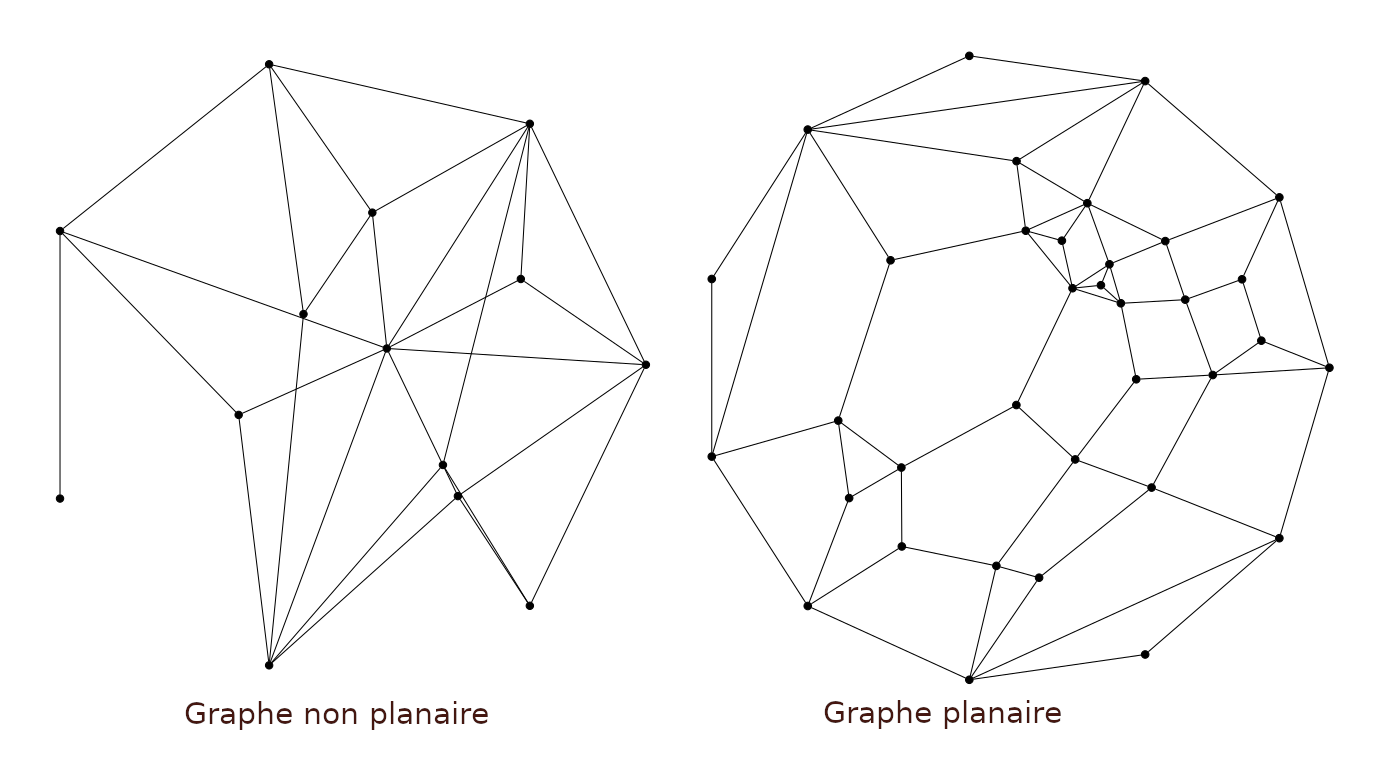
La Fig. 122 présente deux exemples de dessins de graphes
obtenus avec cet algorithme, dans le cas d’un graphe planaire, et dans le cas
d’un graphe non-planaire.
Fig. 122 Exemples de dessins obtenus avec l’algorithme de W. Tutte. Au-delà de la bonne qualité générale de l’ensemble, on constate que dans certains cas des liens sont trop proches et difficiles à distinguer (visible en bas à droite pour le graphe non planaire).¶
L’algorithme de Tutte peut également être vu comme un problème de
minimisation de l’énergie d’un système. On fait l’analogie avec la mécanique
classique. L’énergie d’une représentation \(p\) est la somme des énergies
des arêtes, et l’énergie d’une arête est définie comme :
Cette analogie avec la mécanique peut amener à considérer chaque arête comme un
ressort, d’une longueur naturelle \(l_0 = 0\) (voyez la page Ressort
de Wikipedia pour rafraîchir vos souvenirs de physique de lycée). La première
étape de l’algorithme est la même. La seconde étape, où l’on choisit des
positions pour les sommets, consiste maintenant à les fixer (« clouer »). Au début
de la 3ème étape, on se trouve en présence d’un ensemble de ressorts dont
certaines extrémités sont fixées (choix des positions initiales pour certains
sommets). On libère le système, qui devrait osciller avant d’atteindre une
position d’équilibre : l’énergie est minimisée.
La minimisation de l’énergie correspond à un état unique, tel que :
\[\begin{split}\left\{\begin{array}{ll}
\frac{\partial E(p)}{\partial x_u} & = & 0 \\
\frac{\partial E(p)}{\partial y_u} & = & 0
\end{array}
\right.~\mbox{ , pour chaque } u \in V-A.\end{split}\]
La complexité de l’algorithme est théoriquement en \(\mathcal{O}(n^{1.5})\),
pour les graphes planaires. En pratique, avec les méthodes de résolution
numérique d’équation, il est assez rapide. L’algorithme est également simple à
comprendre et plutôt facile à implémenter, reposant sur des bibliothèques
numériques efficaces pour les parties difficiles.
En terme de visualisation, on obtient des représentations planaires pour les
graphes planaires et des lignes droites.
Mais l’algorithme souffre d’un défaut technique, dit de « résolution sommitale limitée »
(poor vertex resolution). C’est-à-dire que des sommets peuvent se placer très
près les uns des autres.
Par ailleurs, le choix du sous-ensemble de sommets fixés initialement, ainsi que le choix de leurs positions, n’est pas simple.
Au cours des années 1980, les motivations pour disposer d’algorithmes de
visualisation de graphes ont changé, passant d’une « curiosité mathématique » à un
besoin (éventuellement commercial) de fouille visuelle de données.
L’industrie du logiciel (pour le reverse engineering), la biologie (pour les réseaux de
régulation de gènes), ainsi que d’autres domaines (CRM, gestion de risques) ont
commencé à représenter de grands graphes, en espérant améliorer leur
compréhension du système modélisé grâce à la visualisation.
Ces besoins ont amené la création de nouveaux algorithmes, pour améliorer les
visualisations, car le défaut de l’algorithme de Tutte le rendait insuffisant.
Après Tutte, deux grandes orientations ont été suivies :
des développements autour des graphes planaires ;
de nouvelles méthodes reposant sur des analogies physiques (force-directed methods).
Les méthodes autour de la planarité ont abouti d’abord à des algorithmes
linéaires, avec des approches efficaces… mais qui souffraient toujours du
problème de résolution sommitale limitée ([R86], [CYN84]).
En 1990, de Fraysseix, Pach et Pollack [FPP90] ont énoncé le théorème suivant :
« Tout graphe planaire peut être représenté avec des lignes droites avec les sommets sur une grille de \(2n \times 4n\). »
Cela résout la question de la résolution, puisque la distance minimale entre
deux sommets est au minimum de \(\frac{\mbox{taille écran}}{4n}\). Et un
algorithme linéaire a rapidement été trouvé [CP90], ce qui a amené de
nombreuses améliorations dans la décennie qui suivit. Cependant, ces algorithmes
souffrent d’un problème de résolution angulaire, et aboutissent à des positions
peu conventionnelles.
Ainsi, bien que la planarité soit un critère esthétique fondamental, aujourd’hui
presque aucun algorithme reposant sur la planarité n’est adopté commercialement,
au profit des méthodes « orientées forces », que nous allons voir maintenant.
Méthodes et algorithmes modernes de spatialisation¶
De manière indépendante au développement des algorithmes liés à la planarité,
des améliorations de l’algorithme de Tutte ont été proposées, en poursuivant
l’analogie avec la mécanique. Pour éviter que les sommets puissent être trop
proches les uns des autres, il a été proposé de modifier le système en
introduisant deux nouvelles forces :
une force reposant sur une longueur naturelle non nulle pour les ressorts,
une force répulsive, proportionnelle à l’inverse du carré de la distance entre
les sommets.
Formellement, la force \(\mathbf{F}_{ressort}\) s’applique pour des sommets voisins
\(u\) et \(v\), elle vaut :
Un minimum local d’énergie correspond, comme précédemment, au cas où \(F(u)
= 0\), pour chaque sommet \(u\). On obtient un système d’équations
non-linéaires. En général, la solution de ce système n’est pas unique, il y a des
minima locaux qui peuvent ne pas être des minima globaux. Il existe diverses
méthodes pour résoudre de tels systèmes.
Le modèle avec des forces contient des constantes qui peuvent permettre de
contraindre la représentation, pour tenir compte des objectifs liés au domaine
du graphe. Par exemple, si les liens sont importants, on peut choisir un
\(k_{uv}\) grand et \(l_0\) faible.
On peut également utiliser d’autres analogies mécaniques pour introduire de
nouvelles équations dans le système et agir sur la visualisation :
des « clous » peuvent maintenir la position de certains nœuds,
des forces magnétiques peuvent agir sur des sommets (par exemple pour les
aligner sur une grille),
des forces attractives peuvent agir sur des groupes de sommets pour les
maintenir proches les uns des autres.
Purchase, Helen C. Cohen, R. F., and James, M. I. 1997. An experimental study of the basis for graph drawing algorithms. J. Exp. Algorithmics 2, Article 4 (January 1997). DOI: https://doi.org/10.1145/264216.264222
Di Battista, G., Eades, P., Tamassia, R., & Tollis, I. G. (1994). Algorithms for drawing graphs: an annotated bibliography. Computational Geometry, 4(5), 235-282.
Read, R. C. (1986). A new method for drawing a planar graph given the cyclic order of the edges at each vertex. Faculty of Mathematics, University of Waterloo.
Chrobak, M., & Payne, T. H. (1990). A Linear Time Algorithm for Drawing Planar Graphs on the Grid. Tech. Rep. UCR-CS-90-2, Dept. of Mathematics and Computer Science, University of California at Riverside.