Travaux pratiques - Deep Learning avec Keras¶
L’objectif de cette séance de travaux pratiques est de découvrir la bibliothèque Keras et ses fonctionalités pour la création et l’apprentissage de réseaux de neurones profonds. En particulier, nous allons reprendre les deux modèles vus précédemment (régression logistique et perceptron) pour montrer comment les implémenter avec Keras. Nous verrons également un premier modèle simple de réseau de neurones profonds convolutif.
Importation de Keras/TensorFlow¶
Keras est une bibliothèque logicielle open-source écrite en Python pour l’apprentissage profond. Il s’agit en réalité d’une surcouche à TensorFlow, qui implémente les briques de base (opérations matricielles, couches, fonctions de transfert). TensorFlow gère notamment la possibilité d’exécuter un réseau de neurones sur le processeur (CPU) ou sur accélérateur graphique matériel (GPU).
L’import de Keras s’effectue depuis TensorFlow :
from tensorflow import keras
En plus des fonctionnalités liées à l’apprentissage profond, Keras intègre des utilitaires
pour charger et manipuler un certain nombre de jeux de données populaires, comme MNIST :
# Chargement du jeu de données MNIST
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
# Conversion en encodage one-hot
Y_train = keras.utils.to_categorical(y_train, 10)
Y_test = keras.utils.to_categorical(y_test, 10)
# Redimensionnement des images 28x28 en vecteurs d=784
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
# Normalisation entre 0 et 1
X_train /= 255
X_test /= 255
Régression logistique avec Keras¶
Keras propose plusieurs façons différentes de définir un réseau de neurones. La façon
la plus courante pour les réseaux à propagation avant (feedforward), qui empilent les couches
de façon séquentielle, est d’utiliser la classe Sequential (voir sa documentation):
from tensorflow.keras import Sequential
model = Sequential()
model représente ainsi un réseau de neurones vide (pour l’instant). Il est possible
d’ajouter des couches à l’aide de la méthode add. De nombreuses couches sont
prédéfinies dans Keras, comme les couches entièrement connectées (couches linéaires
dites Dense) ou les fonctions d’activation standard.
Par exemple, le code ci-dessous ajoute une projection linéaire (couche entièrement connectée) de taille 10 au modèle, puis une activation de type softmax:
from tensorflow.keras.layers import Dense, Activation
model.add(Dense(10, input_dim=784, name='fc1'))
model.add(Activation('softmax'))
Le paramètre input_dim est nécessaire pour spécifier la dimension de l’entrée de la couche entièrement connectée.
On peut ensuite visualiser l’architecture du réseau à l’aide de la méthode summary() :
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
fc1 (Dense) (None, 10) 7850
_________________________________________________________________
activation (Activation) (None, 10) 0
=================================================================
Total params: 7,850
Trainable params: 7,850
Non-trainable params: 0
_________________________________________________________________
Question
Quel modèle de prédiction reconnaissez-vous ? Vérifier le nombre de
paramètres du réseau à apprendre dans la méthode summary().
Correction
Il s’agit d’une régression logistique. Le nombre total de paramètres est indiqué par la ligne Total params, qui est bien à 7850.
En plus de la définition de l’architecture, nous avons encore besoin de spécifier deux éléments à Keras avant d’entraîner
notre modèle : une fonction de coût (loss) et une méthode d’optimisation.
Ces paramètres sont spécifiés lors de la phase de compilation du modèle à l’aide de la méthode .compile().
Nous allons utiliser l’entropie croisée (categorical_crossentropy) comme fonction de coût et la descente de gradient stochastique
(stochastic gradient descent ou sgd).
optimizer = keras.optimizers.SGD(learning_rate=0.5)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
Question
À l’aide de la documentation de la méthode .compile(), déterminer à quoi correspond le paramètre metrics=.
Correction
metrics= permet de spécifier la métrique utilisée pour évaluer le modèle (ici, l’exactitude ou accuracy).
La boucle d’apprentissage du modèle sur les données d’apprentissage est automatisée par la méthode .fit() :
model.fit(X_train, Y_train, batch_size=300, epochs=10, verbose=1)
batch_sizecorrespond au nombre d’exemples utilisé pour estimer le gradient de la fonction de coût.epochsest le nombre d’époques (i.e. passages sur l’ensemble des exemples de la base d’apprentissage) lors de la descente de gradient.
Note
Pour les fonctions de coût de classification, Keras attend par convention que les étiquettes (labels) données pour la supervision soient au format one-hot encoding.
L’évaluation des performances du modèle sur le jeu de test est également automatique, en fonction de la métrique choisie lors de la compilation, grâce à la méthode .evaluate() :
scores = model.evaluate(X_test, Y_test, verbose=0)
print(f"{model.metrics_names[0]}: {scores[0]*100:.2f}")
print(f"{model.metrics_names[1]}: {scores[1]*100:.2f}")
Le premier élément de la liste scores correspond à l’erreur de test (valeur de la fonction de coût sur
(X_test, y_test)) tandis que le deuxième élément correspond au taux de bonne classification (accuracy).
Question
Comparer les performances obtenues par cette régression logistique implémentée avec Keras avec celles obtenues lors du premier TP. Conclure.
Perceptron avec Keras¶
Nous pouvons maintenant enrichir ce modèle de régression logistique en insérant une couche de neurones cachés complètement connectée ainsi qu’une fonction d’activation non linéaire de type sigmoïde entre la couche d’entrée et la couche de sortie. Ce nouveau modèle va ainsi correspond au réseau de neurones à une couche cachée (perceptron) vu précédemment.
Question
Créer un nouveau modèle model = Sequential() et le compléter en lui
ajoutant :
une couche entièrement connectée avec 100 neurones cachés,
une activation sigmoide,
une couche entièrement connectée avec 10 neurones de sortie,
une activation softmax,
de sorte à retrouver le multi-layer perceptron du TP précédent.
Correction
model = Sequential()
model.add(Dense(100, input_dim=784, name='fc1'))
model.add(Activation('sigmoid'))
model.add(Dense(10, name='fc2'))
model.add(Activation('softmax'))
Question
Combien ce modèle a-t-il de paramètres ? Justifier le calcul et vérifier à l’aide de la méthode .summary().
Correction
Ce modèle a \(784 \times 100 + 100\) paramètres pour la première couche cachée puis \(100 \times 10 + 10\) paramètres pour la couche de sortie, soit un totale de 79510 paramètres à optimiser.
L’entraînement de ce nouveau modèle s’effectue de façon strictement identique à ce que nous avons vu précédemment. En effet, Keras s’inspire de l’interface de scikit-learn : tous les modèles se manipulent de la même façon une fois compilés. L’algorithme de rétropropagation du gradient et l’optimisation par descente de gradient sont implémentés dans Keras et il n’est plus nécessaire de les écrire à la main.
Question
Compiler le perceptron multi-couche puis l’entraîner sur la base d’apprentissage de MNIST. On utilisera la même fonction de coût et le même optimiseur que pour la régression logistique.
Correction
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=300, epochs=10, verbose=1)
Question
Évaluer les performances du perceptron multi-couche sur le jeu de test de MNIST et comparer à celles obtenues lors du précédent TP. Conclure.
Correction
scores = model.evaluate(X_test, Y_test, verbose=0)
print(f"{model.metrics_names[0]}: {scores[0]*100:.2f}")
print(f"{model.metrics_names[1]}: {scores[1]*100:.2f}")
Question
À l’aide de la documentation de Keras, déterminer comment sont initialisés les paramètres du modèle pour les couches entièrement connectées.
Correction
Par défaut, c’est l’initialisation de Glorot uniforme qui est utilisée.
Une fonctionnalité utile de Keras est la possibilité de sauvegarder des modèles sur le disque pour les partager
ou les réutiliser plus tard. Cette opération se fait simplement à l’aide de la méthode .save() :
model.save('MLP.h5')
Il est possible de charger un modèle sur le disque à l’aide de la fonction load_model :
from tensorflow.keras.models import load_model
model = load_model('MLP.h5')
Réseaux de neurones convolutifs avec Keras¶
Pour cette dernière partie, nous allons passer du réseau entièrement connecté à un modèle convolutif. En effet, les réseaux de neurones convolutifs profonds (Convolutional Neural Networks ou CNN) sont particulièrement adaptés à la reconnaissance d’images.
Les réseaux convolutifs manipulent des images multi-dimensionnelles en entrée (des tenseurs). Comme nous avions initialement transformé nos images en vecteurs, nous allons les redimensionner de sorte à ce que chaque observation du jeu de données MNIST soit bien une image carrée de 28 pixels de côté en niveaux de gris, c’est-à-dire de dimensions \(28\times 28\times 1\).
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
Par rapport aux réseaux complètement connectés, les réseaux convolutifs utilisent les briques élémentaires suivantes :
Des couches de convolution, qui transforment un tenseur d’entrée de taille \(n_x \times n_y \times p\) en un tenseur de sortie \(n_{x'} \times n_{y'} \times n_H\), où \(n_H\) est le nombre de filtres choisi.
Keras implémente bien entendu par défaut les couches convolutives. Il s’agit de la classe Conv2D.
Par exemple, une couche de convolution pour traiter les images d’entrée de MNIST peut être créée de la manière suivante :
from tensorflow.keras.layers import Conv2D
Conv2D(32, kernel_size=(5, 5), activation='sigmoid', input_shape=(28, 28, 1), padding='same')
Dans l’instanciation de cette classe, on retrouve de nombreux arguments :
32 correspond au nombre de filtres souhaité pour cette couche convolutive.
(5, 5) sont les dimensions spatiales du noyau de convolution de chacun des filtres.
padding='same'ajoute des 0 à l’image d’entrée de sorte à conserver la même taille en sortie qu’en entrée (\(n_x = n_x'\)).
Note
On remarque qu’il est possible de spécifier directement dans la couche de convolution la non-linéarité qui sera appliquée en sortie des activations. Dans notre cas, nous avons choisi d’appliquer une fonction d’activation sigmoide après la convolution.
Des couches d’agrégation spatiale (pooling), afin de permettre une invariance aux translations locales. Elles sont implémentées par la classe
MaxPooling2Dde Keras :
from tensorflow.keras.layers import MaxPooling2D
MaxPooling2D(pool_size=(2, 2))
(2, 2) est la taille spatiale sur laquelle l’opération d’agrégation est effectuée.
Ces deux briques élémentaires peuvent être ajoutées à n’importe quel modèle séquentiel en Keras à l’aide de la méthode .add().
Question
Implémenter un réseau de neurones convolutif reprenant l’architecture suivante, similaire à celle du modèle historique LeNet5 [LBD+89], illustré ci-dessous :
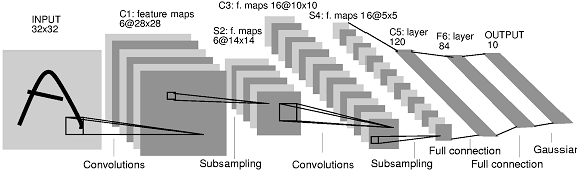
Une couche de convolutions avec 16 filtres de taille \(5 \times 5\), suivie d’une non-linéarité sigmoïde puis d’une couche de max pooling \(2 \times 2\).
Une couche de convolutions avec 32 filtres de taille \(5 \times 5\), suivie d’une non-linéarité sigmoïde puis d’une couche de max pooling \(2 \times 2\).
Une seconde couche de convolution avec 64 filtres de taille \(5 \times 5\), suivie d’une non linéarité sigmoïde puis d’une couche de max pooling \(2 \times 2\).
Comme dans le réseau LeNet, on considérera la sortie du second bloc convolutif comme un vecteur, ce que revient à « mettre à plat » les couches convolutives précédentes (
model.add(Flatten())).Une couche complètement connectée de taille 100, suivie d’une sigmoide.
Une couche complètement connectée de taille 10, suivie d’une activation softmax.
Correction
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Flatten
model = Sequential()
model.add(Conv2D(16, 5, input_shape=(28, 28, 1), activation="sigmoid"))
model.add(MaxPooling2D(pool_size=(2, 2))
model.add(Conv2D(32, 5, activation="sigmoid"))
model.add(MaxPooling2D(pool_size=(2, 2))
model.add(Conv2D(64, 5, activation="sigmoid"))
model.add(MaxPooling2D(pool_size=(2, 2))
model.add(Flatten())
model.add(Dense(100))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
Question
Compiler puis entraîner le modèle sur le jeu d’apprentissage de MNIST. On reprendra la même fonction de coût et le même optimiseur que précédemment.
Correction
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=300, epochs=10, verbose=1)
model.save('LeNet.h5')
Question
Évaluer les performances du modèle sur le jeu de test de MNIST. Vous devriez obtenir un score proche de 99% pour ce modèle.
Correction
scores = model.evaluate(X_test, Y_test, verbose=0)
print(f"{model.metrics_names[0]}: {scores[0]*100:.2f}")
print(f"{model.metrics_names[1]}: {scores[1]*100:.2f}")
Accélération par GPU¶
Question
(pour aller plus loin) Combien de temps de calcul dure époque avec ce modèle convolutif ? Comparer sur votre propre machine dotée d’une carte graphique (GPU), sur JupyterHub GPU ou sur Google Colab.
[LBD+89] Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4):541–551, 1989.