Travaux pratiques - Premiers réseaux de neurones¶
Dans cette séance de travaux pratiques, l’objectif est de vous faire implémenter par vous-même l’apprentissage d’un premier réseau de neurones simple. En pratique, il existe de nombreuses bibliothèques qui implémentent à notre place les routines qui réalisent cet apprentissage. Toutefois, il est très formateur de manipuler les concepts de base au moins une fois pour comprendre comment fonctionnent les outils que nous utiliseront plus tard, comme Keras.
Jeu de données MNIST¶
Pour cette séance, nous travaillerons avec la base de données MNIST. Elle est constituée de 70000 images (60000 images en apprentissage, 10000 en test) de chiffres manuscrits en noir et blanc. L’objectif est d’identifier automatiquement le chiffre à partir de l’image.
Commençons par importer les données. Comme il s’agit d’un jeu de données très classique et courant, il est disponible de base dans de nombreuses bibliothèques, comme Keras. Cela nous permet de l’importer directement en une ligne de code:
from keras.datasets import mnist
# Import de MNIST depuis Keras
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Transformation des images 28x28 en vecteur de dimension 784
X_train = X_train.reshape(60000, 784).astype('float32')
X_test = X_test.reshape(10000, 784).astype('float32')
# Normalisation entre 0 et 1
X_train /= 255
X_test /= 255
# Affichage du nombre de'exemples
print(f"{X_train.shape[0]} exemples d'apprentissage")
print(f"{X_test.shape[0]} exemples de test")
Question
Afficher à l’aide de matplotlib les premières images du jeu d’apprentissage. La fonction plt.imshow() (cf. sa documentation) peut vous être utile.
Correction
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
n_images = 10
for i in range(n_images):
plt.subplot(1, n_images, i+1)
plt.imshow(X_train[i].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
Question :
Quel est l’espace dans lequel se trouvent les images ? Quelle est sa dimension ?
Correction
Les images sont de dimension 28x28 et en noir et blanc. Il y a donc une valeur d’intensité pour chaque pixel, soit \(28\times28=784\) scalaires.
Régression logistique¶
Modèle de prédiction¶
Nous allons implémenter un modèle de classification linéaire simple : la régression logistique. Concrètement, la régression logistique est équivalente à un réseau de neurones à une seule couche. Il s’agit d’une projection du vecteur d’entrée \(\mathbf{x_i}\) par un vecteur de paramètres \(\mathbf{w_{c}}\), plus un biais sclaaire \(b_c\), pour chaque classe. Le schéma ci-dessous illustre le modèle de régression logistique avec un réseau de neurones.
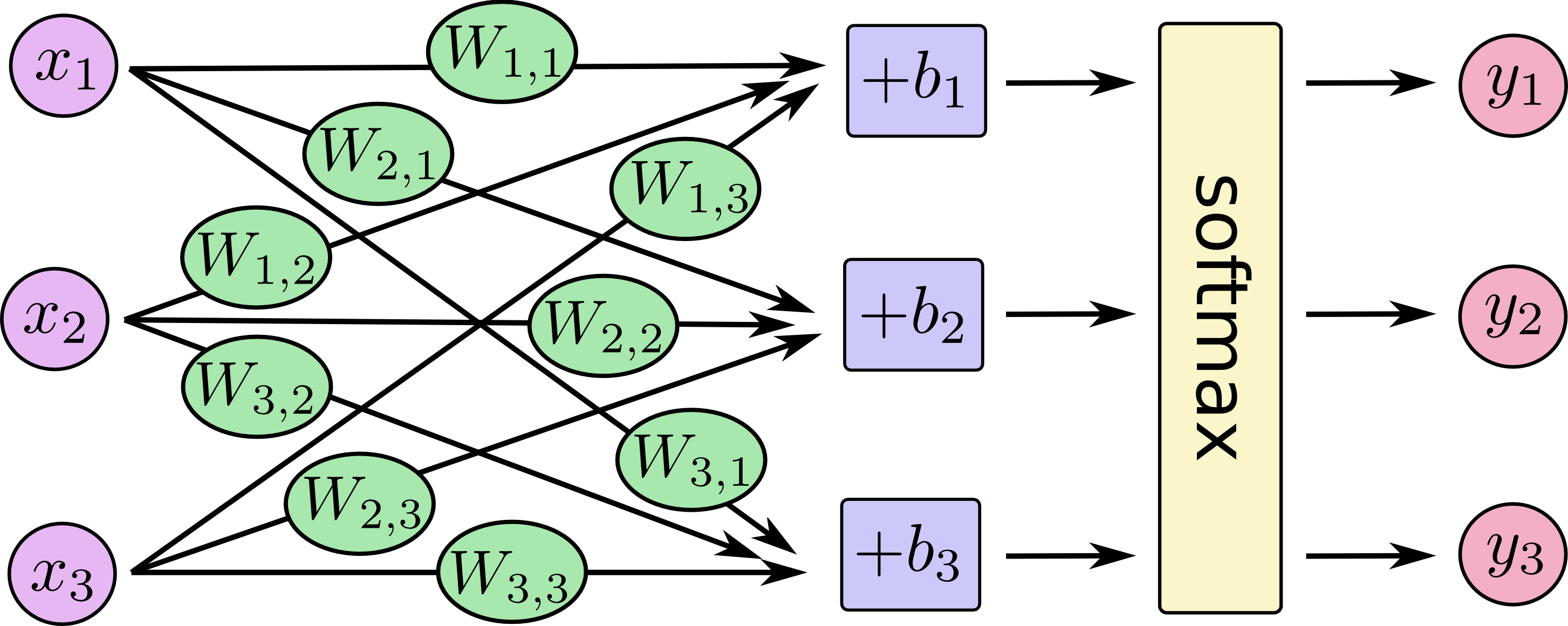
En l’occurrence, pour MNIST \(\mathbf{x}_i\) est de dimension 784 et il y a dix chiffres possibles, donc 10 classes différentes. Dans notre cas, on considère que l’image d’entrée est représentée sous sa forme « aplatie », c’est-à-dire un vecteur (1, 784).
Pour simplifier les notations, on regroupe l’ensemble des jeux de paramètres \(\mathbf{w_{c}}\) pour les 10 classes possibles dans une unique matrice \(\mathbf{W}\) de dimensions \(784\times 10\). De la même façon, les biais sont regroupés dans un vecteur \(\mathbf{b}\) de longueur 10. La sortie de la régression logistique est un vecteur contenant une activation pour chaque classe, c’est-à-dire \(\mathbf{\hat{s_i}} =\mathbf{x_i} \mathbf{W} + \mathbf{b}\) de dimensions (1, 10).
Afin de transformer les activations en de sortie en probabilités pour une distribution catégorielle, on ajoute une fonction d’activation de softmax sur \(\mathbf{\hat{y_i}} = \sigma(\mathbf{s_i})\). Cela nous permet d’obtenir en sortie un vecteur de prédictions \(\mathbf{\hat{y_i}}\), de dimensions (1, 10), qui représente la probabilité a posteriori \(p(\mathbf{\hat{y_i}} | \mathbf{x_i})\) pour chacune des 10 classes :
Question
Quel est le nombre de paramètres du modèle utilisé ? Justifier le calcul.
Correction
Il y a 10 classes de sortie et 784 variables d’entrée, soit 7840 paramètres pour les connexions de l’unique couche du réseau. Il faut y ajouter les 10 paramètres du vecteur de bias, soit un total de 7850 paramètres.
Formulation du problème d’apprentissage¶
Pour entraîner le réseau de neurones, c’est-à-dire déterminer les valeurs optimales des paramètres \(\mathbf{W}\) et \(\mathbf{b}\), on va comparer pour chaque exemple d’apprentissage la sortie prédite \(\mathbf{\hat{y_i}}\) (équation (1)) pour l’image \(\mathbf{x_i}\) à la sortie réelle \(\mathbf{y_i^*}\) (vérité terrain issue de la supervision). Dans notre cas, on choisit d’encoder la catégorie de l’image \(\mathbf{x_i}\) sous forme one-hot, c’est-à-dire :
Générons les étiquettes (labels) au format one-hot ((2)) à l’aide de la fonction to_categorical (cf. documentation de Keras).
from keras.utils import to_categorical
n_classes = 10
# Conversion des étiquettes (int) au format vectoriel one-hot
Y_train = to_categorical(y_train, n_classes)
Y_test = to_categorical(y_test, n_classes)
L’erreur de prédiction sera définie à l’aide de l’entropie croisée (cross-entropy). Cette fonction de coût s’applique entre \(\mathbf{\hat{y_i}}\) et \(\mathbf{y_i^*}\) par la formule: \(\mathcal{L}(\mathbf{\hat{y_i}}, \mathbf{y_i^*}) = -\sum_{c=1}^{10} y_{c,i}^* \log(\hat{y}_{c,i}) = - \log(\hat{y}_{c^*,i})\), où \(c^*\) correspond à l’indice de la classe donnée par la supervision pour l’image \(\mathbf{x_i}\).
Note
L’entropie croisée correspond en réalité à la divergence de Kullback-Leiber pour des distributions catégorielles. La divergence KL est une mesure de dissimilarité entre distributions de probabilité. Autrement dit, l’erreur que l’on mesure vise à réduire l’écart entre la distribution réelle des catégories et la distribution prédite.
La fonction de coût finale correspond à l’erreur d’apprentissage, c’est-à-dire la moyenne l’entropie croisée sur l’ensemble de la base d’apprentissage \(\mathcal{D}\) constituée des \(N=60000\) images :
Question :
La fonction de coût de (3) est-elle convexe par rapport aux paramètres \(\mathbf{W}\), \(\mathbf{b}\) du modèle ? Avec un pas de gradient bien choisi, peut-on assurer la convergence vers le minimum global de la solution ?
Optimisation du modèle¶
Nous allons minimiser la fonction de coût à l’aide de l’algorithme de descente de gradient appliqué sur les paramètres \(\mathbf{W}\) et \(\mathbf{b}\) du modèle de régression logistique. Pour ce faire, nous allons avoir besoin des gradients de l’entropie croisée par rapport à \(\mathbf{W}\) ainsi que \(\mathbf{b}\). Nous pouvons nous appuyer sur la des dérivées chaînées (chain rule, ou théorème de dérivation des fonctions composées) :
Question
Montrer que :
\[\frac{\partial \mathcal{L}}{\partial \mathbf{s_i}} = \mathbf{\delta^y_i} = \frac{\partial \mathcal{L}}{\partial \mathbf{\hat{y_i}}} \frac{\partial \mathbf{\hat{y_i}}}{\partial \mathbf{s_i}} = \mathbf{\hat{y_i}} - \mathbf{y_i^*} \]
Question
En déduire que les gradients de \(\mathcal{L}\) par rapport aux paramètres du modèle s’écrivent :
où \(\mathbf{X}\) est la matrice des données (taille \(60000\times 784\)), \(\mathbf{\hat{Y}}\) est la matrice des labels prédits sur l’ensemble de la base d’apprentissage (taille \(60000\times 10\)) et \(\mathbf{Y^*}\) est la matrice des labels issue de la supervision (ground truth, taille \(60000\times 10\)), et \(\mathbf{\Delta^y}=\mathbf{\hat{Y}}-\mathbf{Y^*}\).
Implémentation de l’apprentissage¶
Les gradients obtenus par les équations (4) et (5) s’écrivent sous forme « vectorielle », ce qui rend les calculs efficaces avec des bibliothèques de calcul scientifique telles que numpy. Après calcul du gradient, les paramètres sont mis à jour de la façon suivante :
où \(\eta\) est le pas de gradient (learning rate).
En théorie, la descente de gradient nécessite de calculer les gradients de la fonction de coût sur tout le jeu de données d’apprentissage. Toutefois, ce jeu de données est assez grand et les gradients peuvent être longs à calculer. En pratique, on implémente plutôt une descente de gradient stochastique, c’est à dire que les gradients aux équations (4) et (5) ne seront pas calculés sur l’ensemble des \(N=60000\) images d’apprentissage, mais sur un sous-ensemble de \(n\) images appelé batch ou lot. Cette technique permet une mise à jour des paramètres plus fréquente qu’avec une descente de gradient classique, un temps de calcul réduit et une convergence plus rapide, au détriment d’une approximation du gradient.
Le code ci-dessous décrit le squelette de l’algorithme de descente de gradient qui va permettre l’optimisation des paramètres du modèle :
import numpy as np
N, d = X_train.shape # N exemples, dimension d
W = np.zeros((d, n_classes)) # initialisation de poids
b = np.zeros((1, n_classes)) # initialisation des biais
n_epochs = 20 # Nombre d'epochs de la descente de gradient
eta = 1e-1 # Learning rate (pas d'apprentissage)
batch_size = 100 # Taille du lot
n_batches = int(float(N) / batch_size)
# On alloue deux matrices pour stocker les valeurs des gradients
gradW = np.zeros((d, n_classes))
gradb = np.zeros((1, n_classes))
for epoch in range(n_epochs):
for batch_idx in range(n_batches):
# ********* À compléter **********
# FORWARD PASS : calculer la prédiction y à partir des paramètres courants pour les images du batch
# BACKWARD PASS :
# 1) calculer les gradients de l'erreur par rapport à W et b
# 2) mettre à jour les paramètres W et b selon la descente de gradient
...
Question
Compléter ce code. Vous devez notamment :
Écrire une fonction
forward(batch, W, b)qui calcule la prédiction (vecteur de sortie \(\hat{\mathbf{y}}\) pour chaque exemple d’un batch de données. Si on considère un batch des données de taille \(tb\times 784\), les paramètres \(\mathbf{W}\) (taille \(784\times 10\)) et \(\mathbf{b}\) (taille \(1\times 10\)), la fonctionforwardrenvoie la prédiction \(\mathbf{\hat{Y}}\) sur le batch (taille \(tb\times 10\)). La fonctionforwardsera appelée pour chaque itération de la double boucle précédente.Utiliser la fonction
softmaxci-dessous pour calculer le résultat du passage du softmax sur chaque élément de de la matrice de la projection linéraire (taille \(tb\times 10\)) :def softmax(X): # Entrée: matrice X de dimensions batch x d # Sortie: matrice de mêmes dimensions E = np.exp(X) return (E.T / np.sum(E,axis=1)).T
Correction
import numpy as np
N, d = X_train.shape # N exemples, dimension d
W = np.zeros((d, n_classes)) # initialisation de poids
b = np.zeros((1, n_classes)) # initialisation des biais
n_epochs = 20 # Nombre d'epochs de la descente de gradient
eta = 1e-1 # Learning rate (pas d'apprentissage)
batch_size = 100 # Taille du lot
n_batches = int(float(N) / batch_size)
# On alloue deux matrices pour stocker les valeurs des gradients
gradW = np.zeros((d, n_classes))
gradb = np.zeros((1, n_classes))
for epoch in range(n_epochs):
for batch_idx in range(n_batches):
# Extraction du batch
batch = X_train[batch_idx*batch_size:(batch_idx+1)*batch_size]
# Extraction des labels
labels = Y_train[batch_idx*batch_size:(batch_idx+1)*batch_size]
# FORWARd: calcul de la prédiction ŷ
predictions = forward(batch, W, b)
# Calcul de ŷ - y*
diff = predictions - labels
# BACKWARD: calcul des gradients
gradW = 1.0/batch_size * np.matmul(np.transpose(batch, diff)
gradb = 1.0/batch_size * (diff.sum(axis=0)).reshape((1, 10))
# Mise à jour des paramètres
W = W - eta * gradW
b = b - eta * gradb
# Calcul des scores (train, test)
train_accuracy = accuracy(W, b, X_train, Y_train)
test_accuracy = accuracy(W, b, X_test, Y_test))
# Affichage du score
print(f"Epoch {epoch}/{n_epochs}: accuracy (train)={train_accuracy*100:.2f}, accuracy (test)={test_accuracy*100:.2f}")
Question
Évaluer les performances du modèle de régression logistique entraîné sur MNIST. On utilisera le taux de bonne classification (accuracy) comme métrique. Commencer par mesurer l’évolution des performances du modèle au cours de l’apprentissage (calcul de l”accuracy à chaque époque), puis évaluer sur le modèle sur la base de test. Vous pouvez utiliser la fonction de scikit-learn ou la fonction accuracy ci-dessous (qui effectue également la phase de prédiction).
Vous devriez obtenir un score de l’ordre de 92% sur la base de test pour ce modèle de régression logistique.
def accuracy(W, b, images, labels):
""" W: matrice de paramètres
b: vecteur de biais
images: images de MNIST
labels: étiquettes de MNIST pour les images
Renvoie l'accuracy du modèle (W, b) sur les images par rapport aux labels
"""
pred = forward(images, W, b)
return np.where(pred.argmax(axis=1) != labels.argmax(axis=1), 0.,1.).mean()
Correction
# Version avec scikit-learn
from sklearn.metrics import accuracy_score
predictions_one_hot = forward(X_test, W, b)
predictions = np.argmax(predictions_one_hot, axis=1)
print(accuracy_score(y_test, predictions))