Les informations pratiques concernant le déroulement de l’unité d’enseignement RCP209 « Apprentissage, réseaux de neurones et modèles graphiques » au CNAM se trouvent dans ce préambule.
Dans cette séance de cours nous présentons les arbres de décision, une classe d’algorithmes d’apprentissage se basant sur la représentation des choix sous la forme graphique d’un arbre avec les différentes décisions de classification placées dans les feuilles.
Nous commençons par quelques exemples motivant l’introduction des arbres de décision (par la suite nous écrirons AD au lieu de « arbre de décision ») ainsi qu’un nombre de définitions pour fixer la terminologie.
Ensuite nous présentons les principes de base de l’apprentissage statistique avec des arbres de décision (en classification et en régression), suivis par une description détaillée des implémentations les plus utilisées aujourd’hui (ID3, C4.5, C50 et CART).
Dans la séance de cours suivante nous présenterons plusieurs extensions, plus précisément le Bagging, les Forets Aléatoires et une introduction aux algorithmes ensemblistes (Boosting).
En théorie des graphes, un arbre est un graphe non orienté, acyclique et connexe. L’ensemble des nœuds se divise en trois catégories :
Nœud racine (l’accès à l’arbre se fait par ce nœud),
Nœuds internes : les nœuds qui ont des descendants (ou enfants), qui sont à leur tour des nœuds,
Nœuds terminaux (ou feuilles) : nœuds qui n’ont pas de descendant.
Les arbres de décision (AD) sont une catégorie d’arbres utilisée dans l’exploration de données et en informatique décisionnelle. Ils emploient une représentation hiérarchique de la structure des données sous forme des séquences de décisions (tests) en vue de la prédiction d’un résultat ou d’une classe. Chaque individu (ou observation), qui doit être attribué(e) à une classe, est décrit(e) par un ensemble de variables qui sont testées dans les nœuds de l’arbre. Les tests s’effectuent dans les nœuds internes et les décisions sont prise dans les nœuds feuille.
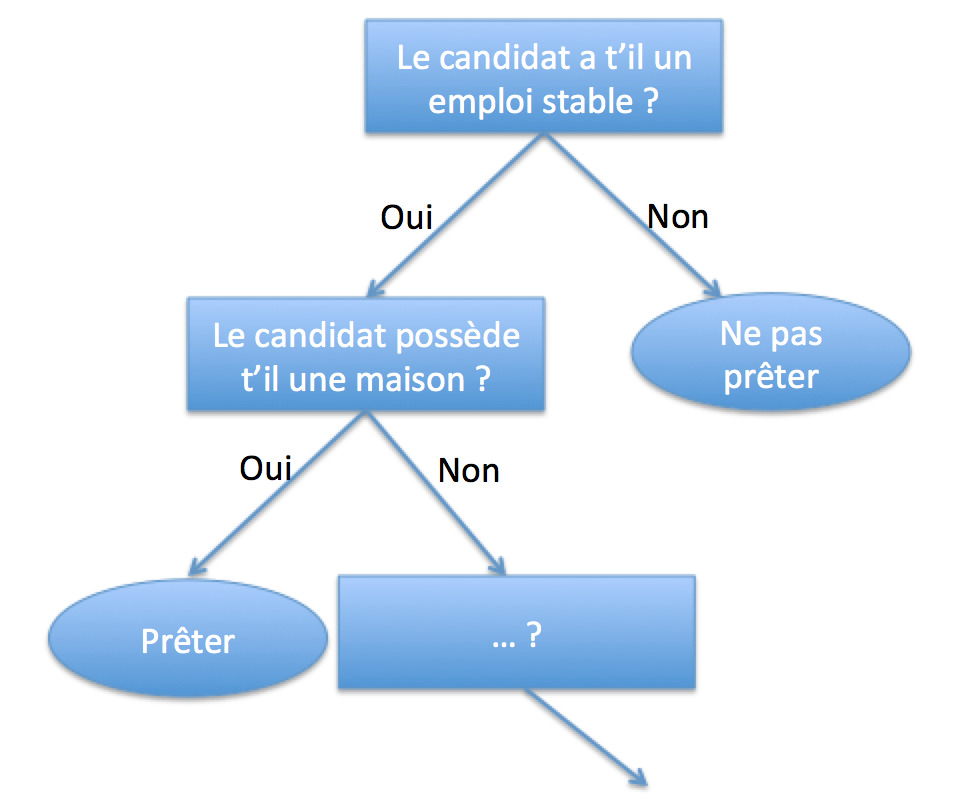
Exemple de problème adapté à un approche par arbres de décision : comment répartir une population d’individus (e.g. clients, produits, utilisateurs, etc.) en groupes homogènes selon un ensemble de variables descriptives (e.g. âge, temps passé sur un site Web, etc.) et en fonction d’un objectif fixé (variable de sortie ; par exemple : chiffre d’affaires, probabilité de cliquer sur une publicité, etc.).
Voici quelques exemples où on doit classer une situation ou individu en suivant une séquence de tests. Le processus de décision est équivalent à une « descente » dans l’arbre (de la racine vers une des feuilles) : à chaque étape un attribut est testé et un sous-arbre est choisi, la parcours s’arrête dans une feuille (une décision est prise).
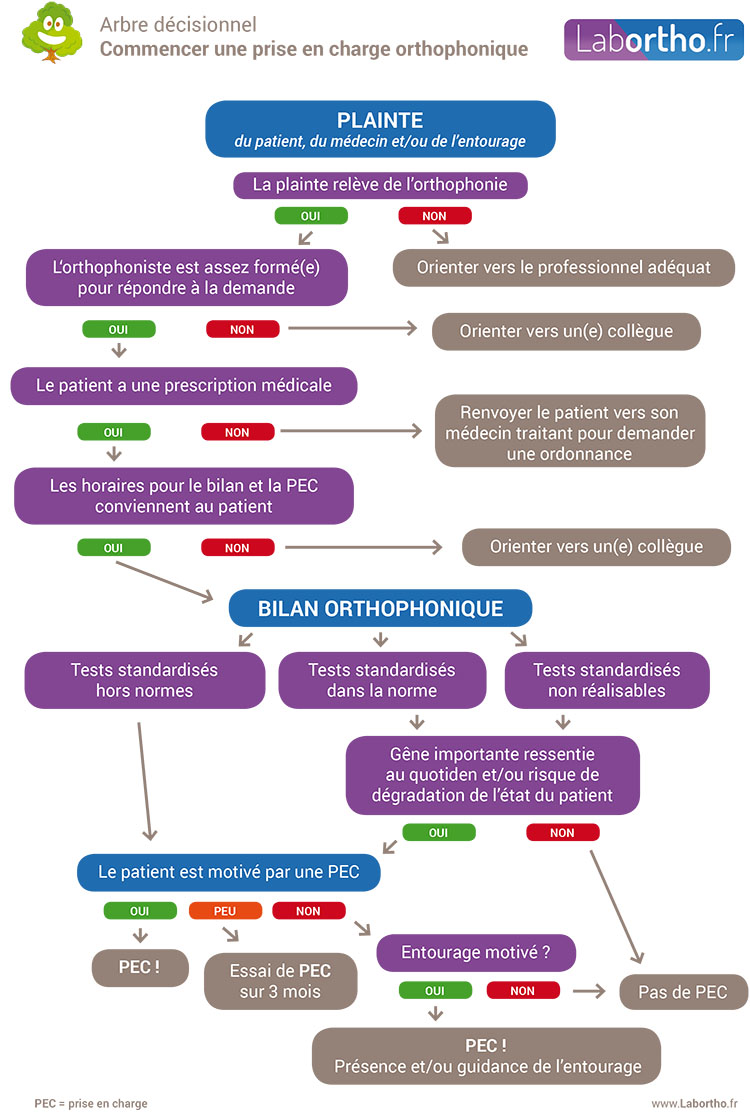
Fig. 33 Modalités de prise en charge orthophonique d’un patient. Source : http://www.labortho.fr¶
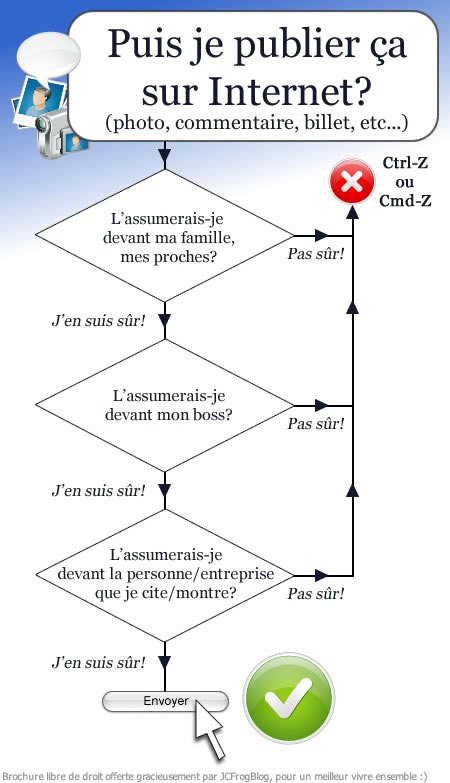
Publication d’un document sur internet
Fig. 34 La décision de publier ou non un document sur internet peut être vue sous la forme d’un arbre de décision. Source : http://jeromechoain.files.wordpress.com¶
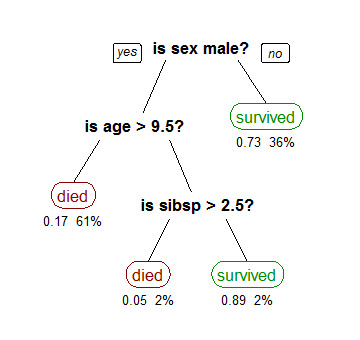
Survie des passagers sur le Titanic
Fig. 35 Classement sur la base de données des survivants du Titanic. (sibsp : number of siblings / spouses aboard the Titanic) Source : https://en.wikipedia.org¶
On considère d’abord le problème de classement. Chaque élément \(x\) de la base de données est représenté par un vecteur multidimensionnel \((x_1, x_2, ...x_n)\) correspondant à l’ensemble de variables descriptives du point. Chaque nœud interne de l’arbre correspond à un test fait sur une des variables \(x_i\) :
Variable catégorielle : génère une branche (un descendant) par valeur de l’attribut ;
Variable numérique : test par intervalles (tranches) de valeurs.
Les feuilles de l’arbre spécifient les classes.
Une fois l’arbre construit, classer un nouvel candidat se fait par une descente dans l’arbre, de la racine vers une des feuilles (qui encode la décision ou la classe). A chaque niveau de la descente on passe un nœud intermédiaire où une variable \(x_i\) est testée pour décider du chemin (ou sous-arbre) à choisir pour continuer la descente.
Principe de la construction :
Au départ, les points des la base d’apprentissage sont tous placés dans le nœud racine. Une des variables de description des points est la classe du point (la « vérité terrain ») ; cette variable est dite « variable cible ». La variable cible peut être catégorielle (problème de classement) ou valeur réelle (problème de régression). Chaque nœud est coupé (opération split) donnant naissance à plusieurs nœuds descendants. Un élément de la base d’apprentissage situé dans un nœud se retrouvera dans un seul de ses descendants.
L’arbre est construit par partition récursive de chaque nœud en fonction de la valeur de l’attribut testé à chaque itération (top-down induction). Le critère optimisé est la homogénéité des descendants par rapport à la variable cible. La variable qui est testée dans un nœud sera celle qui maximise cette homogénéité.
Le processus s’arrête quand les éléments d’un nœud ont la même valeur pour la variable cible (homogénéité).
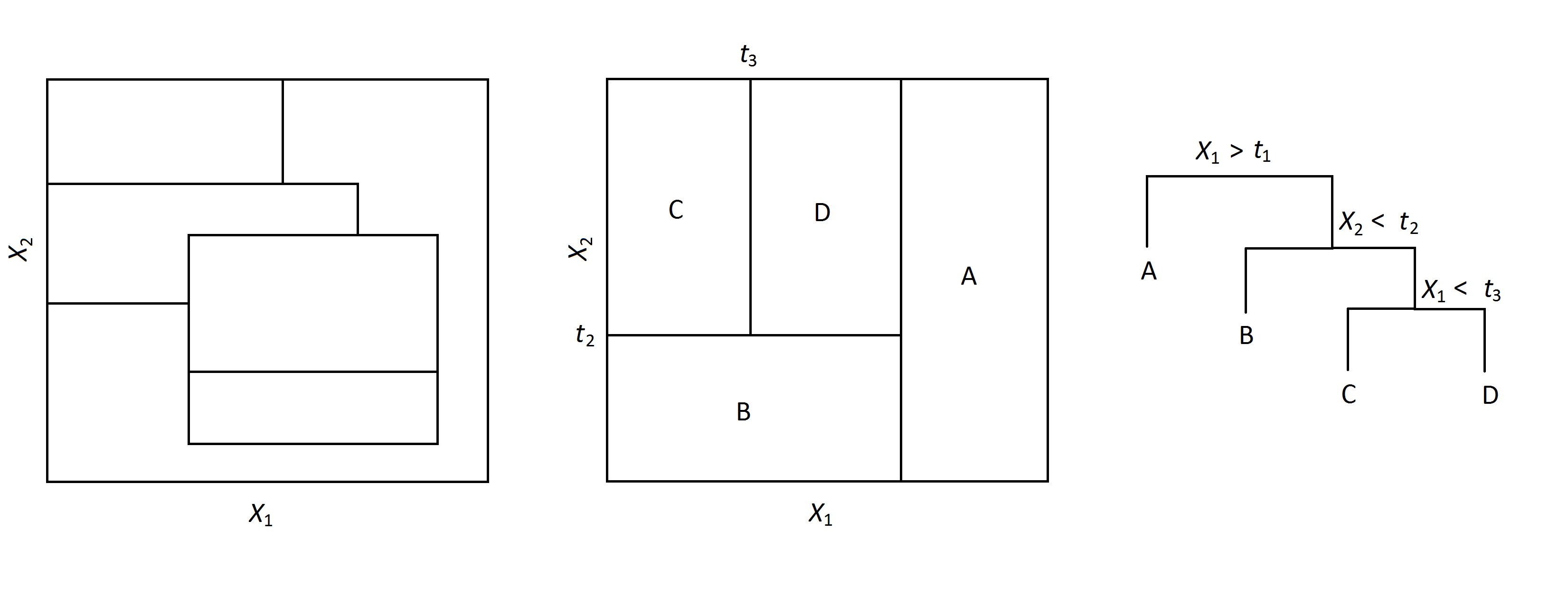
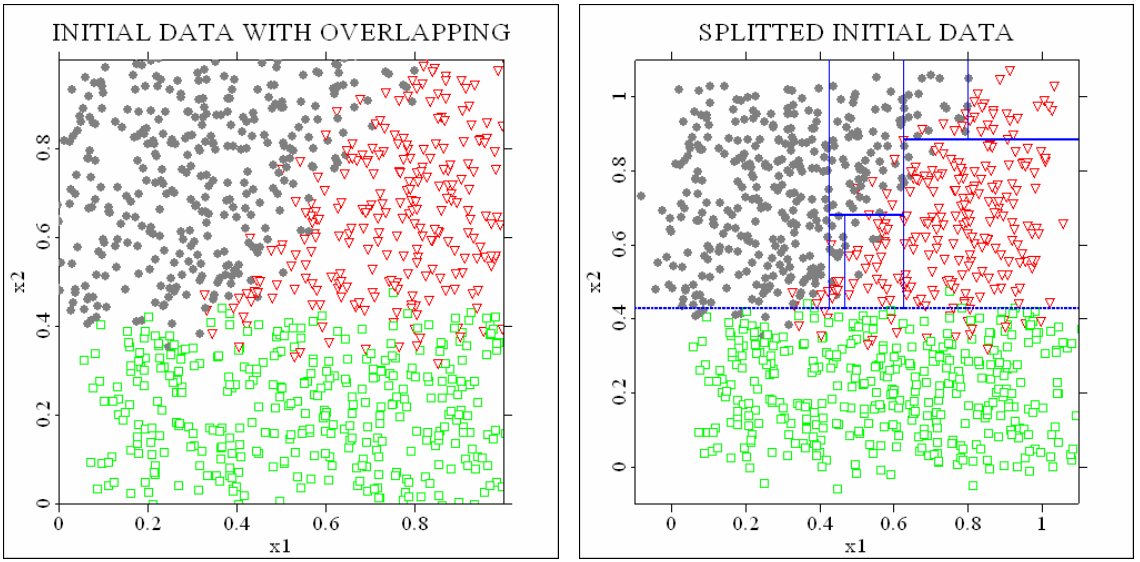
Fig. 36 Au milieu, construction par partition récursive de l’espace : tests successifs sur les \(x_1, x_2\) et \(x_1\). Chaque nœud feuille est homogène : ses éléments (points de chaque région) ont la même valeur pour l’attribut cible (la même classe). A gauche, division impossible à obtenir par partition récursive sur les attributs. (Source : wikimedia.org)¶
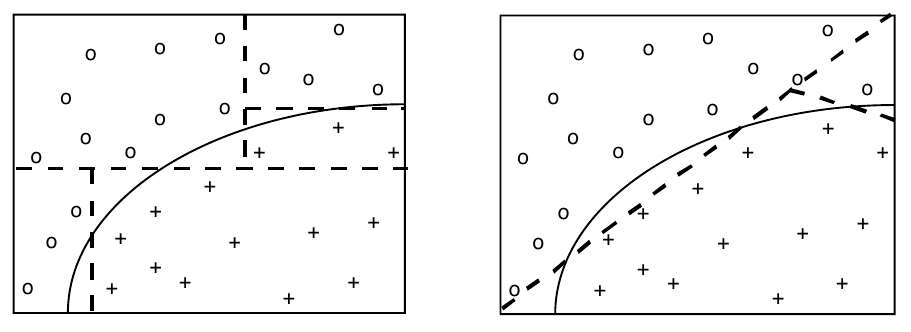
Fig. 37 A gauche, séparation de classes par partition itérative des variables. A chaque étape le but est de couper le nœud en deux régions les plus homogènes possible. A droite, séparation par combinaison linéaire de plusieurs variables (peut conduire à des arbres plus simples mais au prix de la complexité accrue des tests dans les nœuds).¶
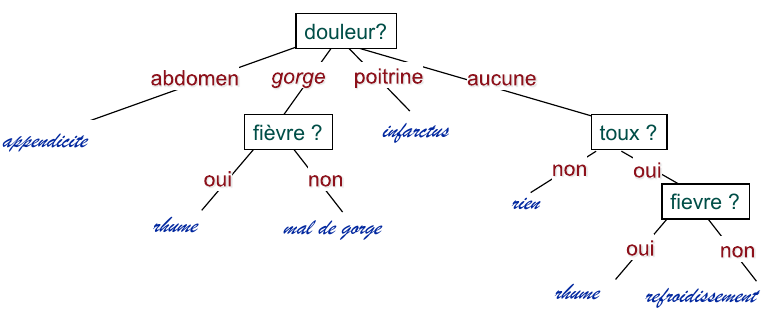
Exemple 1 : maladies
Fig. 38 Un ensemble d’individus décrits par plusieurs variables catégorielles (Toux, Fievre, Poids, Douleur). En bas on voit l’arbre de décision obtenu. La variable cible se retrouve dans les feuilles.¶
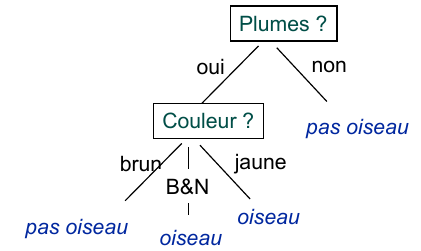
Exemple 2 : oiseaux
Fig. 39 Pour un ensemble d’éléments décrits par des variables catégorielles la classification résultante peut être vue comme une combinaison de règles booléennes.¶
Nous examinons d’abord l’algorithme ID3 (Iterative Dichotomiser 3) introduit par Quinlan dans son article [QU86]. Ensuite nous présenterons les extensions IC4.5, ID5 et l’algorithme alternatif CART proposé par Breiman dans [BF84] qui à la différence de ID3 fonctionne aussi pour des attributs à valeurs continues.
L’algorithme commence par le placement de tous les exemples d’apprentissage dans le nœud racine. Ensuite, chaque nœud est coupé sur un des attributs restants (qui n’a pas encore été testé). Le choix de cet attribut se fait à travers une mesure d’homogénéité par rapport à la variable cible. Cette mesure est le gain d’information obtenu par le découpage.
On suppose que la variable cible a \(m\) valeurs distinctes (les étiquettes de classe). Pour un nœud \(S\) (interne ou feuille) on calcule son entropie par rapport à la cible comme suit :
Partitionner \(S\) sur les valeurs de la cible en \(m\) groupes : \(C_1, ..., C_m\).
Calculer \(p_i, i = 1...m\), la probabilité qu’un élément de \(S\) se retrouve dans \(C_i\) (\(p_i \approx |C_i|/|S|\) ou \(|C_i|\) est la taille du groupe \(C_i\)).
\(H(S) = -\sum_{i=1}^{m}p_i log (p_i)\) est l’entropie de \(S\).
\(H(S)\) mesure l’écart de la distribution de la variable cible par rapport à la distribution uniforme :
\(H(S) = 0\) si \(S\) est homogène (tous les éléments sont dans la même classe : toutes les probabilités \(p_i\) sont égales à 0, sauf une - qui est égale à 1).
\(H(S) = \max\) si toutes les probabilités \(p_i\) sont égales (tous les groupes \(C_i\) ont la même taille : \(p_1 = \cdots = p_n = 1/m\)).
Pour calculer le gain d’information dans un nœud interne \(S\) sur l’attribut \(a\) :
Partitionner \(S\) sur les valeurs de l’attribut \(a\) en \(k\) sous-groupes : \(S_1, ..., S_k\) (\(k\) est le nombre de valeurs distinctes de l’attribut \(a\)),
\(p_i\) : la probabilité qu’un élément de \(S\) appartient à \(S_i\) (\(p_i \approx |S_i|/|S|\)),
Calculer \(GI(S; a) = H(S)-\sum_{i=1}^{k}p_i H(S_i)\) le gain d’information sur l’attribut \(a\).
Avec ces précisions, l”algorithme ID3 commence par la racine. Ensuite pour le nœud \(S\) en train d’être testé :
Calculer le gain d’information pour chaque attribut pas encore utilisé,
Choisir l’attribut \(a\) de gain d’information maximal,
Créer un test (décision) sur cet attribut dans le nœud \(S\) et générer les sous-nœuds \(S_1,...S_k\) correspondant à la partition sur l’attribut choisi \(a\),
Récurrence sur les nœuds qui viennent d’être crées.
Sortie de la récursivité :
Tous les éléments de \(S\) sont dans la même classe (\(H(S) = 0\)) : \(S\) devient nœud feuille,
Pas d’attributs non utilisés : nœud feuille sur le classe majoritaire,
\(S = \emptyset\) : nœud feuille sur le classe majoritaire du parent (ce cas est nécessaire pour le classement de nouveaux échantillons).
Exemple (Quinlan 1986) :
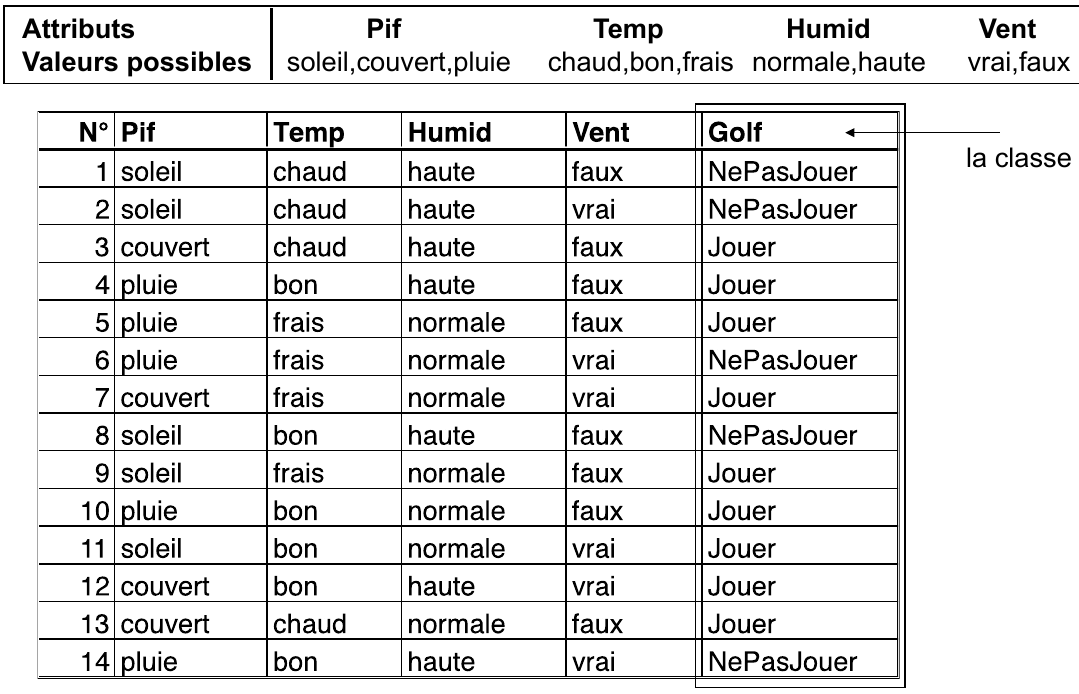
Classification d’un ensemble de jours (J1, …, J14) en deux catégories : « Adapté pour jouer au golf », et « Pas adapté ».
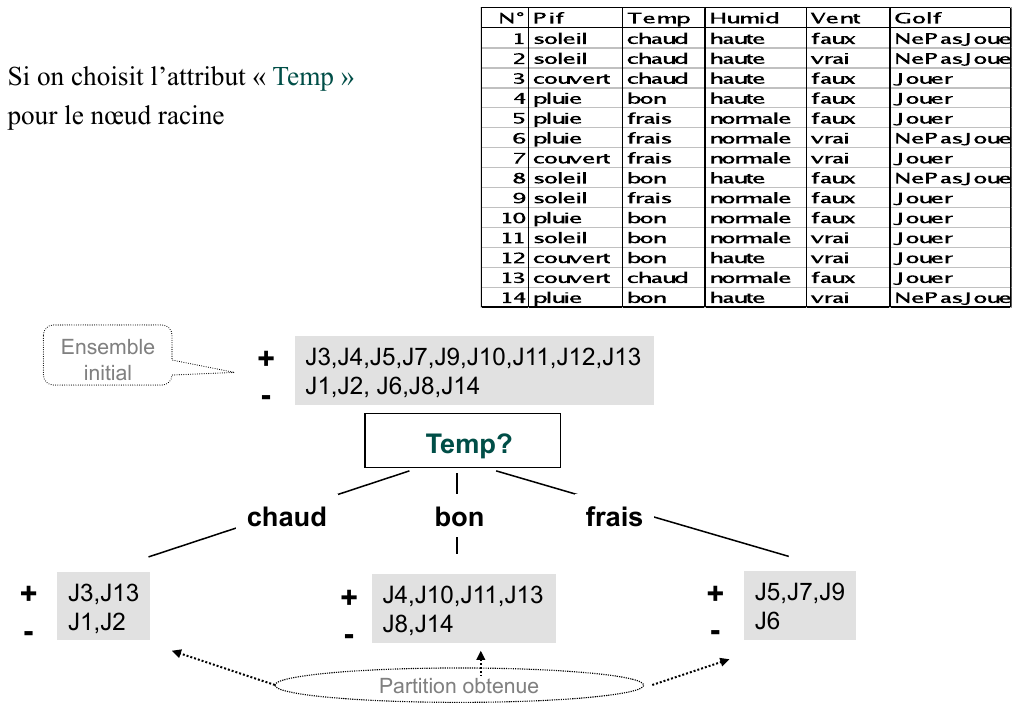
Si on fait un découpage de la racine sur l’attribut « Temp » on obtient la partition suivante :
Au départ, le noeud racine contient tous les elements \(S = \{J_1, J_2, ..., J_{14}\}\). L’entropie de ce node par rapport à la variable cible (Classe + : Jouer, Classe - : Ne pas jouer) est :
Après la division du noeud sur l’attribut temperature on obtient trois sous-groupes : \(S_1\) (Temp = “chaud”), \(S_2\) (Temp = “bon”) et \(S_3\) (Temp = “frais”), avec le probabilités \(p_1 = 4/14, p_2 = 6/14\) et \(p_3 = 4/14\). Les entropies des noeuds \(S_1, S_2\) et \(S_3\) par rapport à la cible sont :
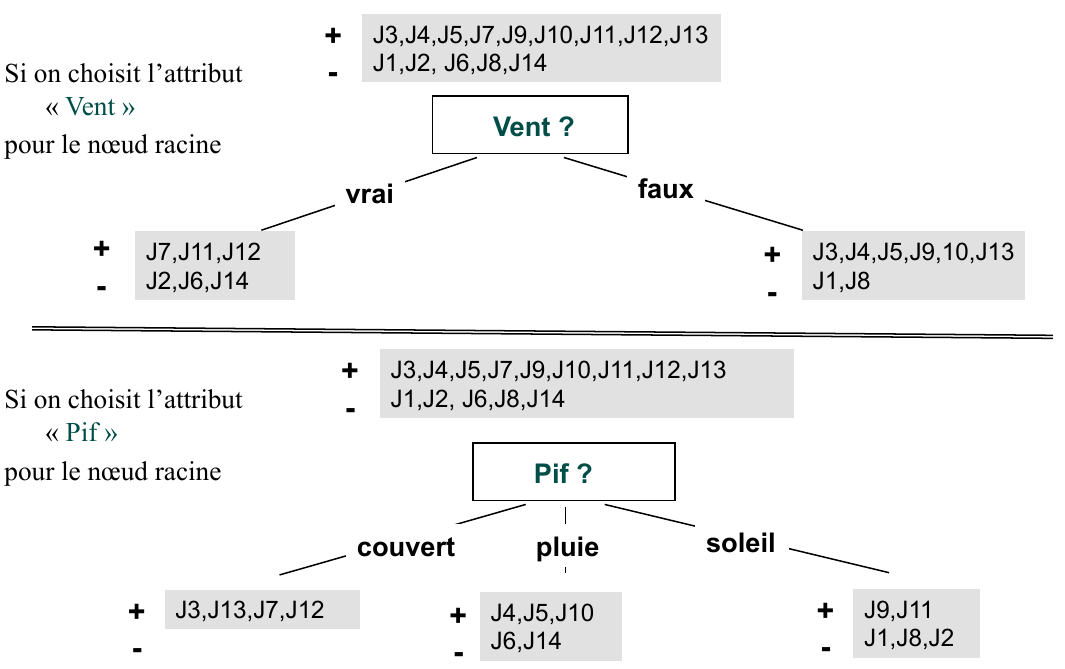
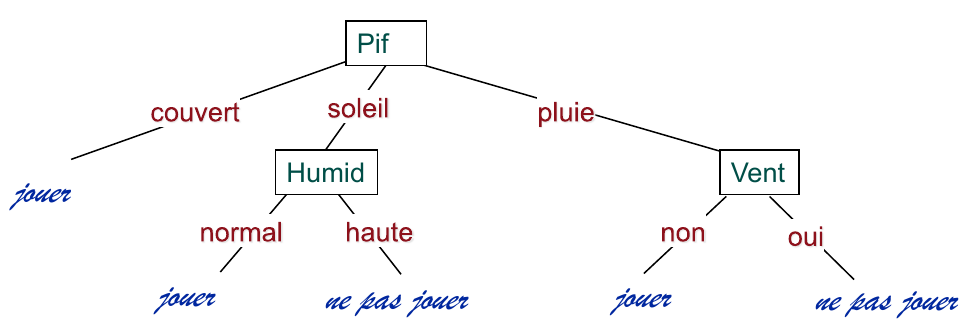
On decide de couper le noeud racine sur l’attribut « Pif » car il offre le plus grand gain d’information (par rapport à la cible). La procedure continue sur les sous-noeuds ainsi obtenus, jusque quand on obtient des noeuds uniforms. L’arbre final obtenu est :
Solution globale non garantie (la solution trouvée est un optimum local ; une amélioration possible : backtracking pour tenter d’obtenir une meilleure solution).
Sur-apprentissage (overfitting) : pour l’éviter il faut préférer les arbres de taille réduite (problème de élagage de l’arbre).
Pas adapté pour des données numériques continues (ces données doivent être quantifiées avant d’être utilisée avec cet algorithme, mais comment faire cette quantification de façon optimale ?).
Pour essayer de pallier à ces insuffisances deux extensions on été proposées, l’algorithme C4.5 et l’algorithme C5.0 (version commerciale de C4.5). Dans la suite nous examinons les principales différences par rapport à ID3.
Élagage après la construction de l’arbre : C4.5 utilise une procedure qui permet transformer en feuilles des sous-arbres qui ne contribuent à un meilleur résultat (score « accuracy ») de l’apprentissage.
Limitation de la profondeur de l’arbre par la taille minimale du noeuds (paramètre de construction).
Chaque attribut peut avoir un poids (coût).
Traitement des variables continues en cherchant des seuils qui maximisent le gain d’information (découpage binaire).
Il existe une implémentation alternative des arbres de décision, proposée par Breiman et al. dans [BF84].
Les principales différences sont les suivantes :
CART pose seulement de questions-test binaires (arbres binaires).
Fonctionne pour des attributs aux valeurs continues (variables quantitatives).
CART cherche tous les attributs et tous les seuils pour trouver celui qui donne la meilleure homogénéité du découpage.
Quand un nœud interne \(S\) est coupé sur l’attribut \(j\), seuil \(a_j\), il donne naissance à deux descendants :
Sous-nœud gauche \(S_g\) (\(p_g \approx |S_g|/|S|\)) qui contient tous les éléments qui ont les valeurs de l’attribut \(v_j \leq a_j\),
Sous-nœud droit \(S_d\) (\(p_d \approx |S_d|/|S|\)) qui contient tous les éléments qui ont les valeurs de l’attribut \(v_j > a_j\).
Soit \(I(S)\) une fonction qui mesure l’impureté de \(S\) par rapport à la classe cible. CART étudie le changement de l’impureté par rapport au seuil et pour tous les attributs :
\(E[I(S_{gd})] = p_g I(S_g) + p_d I(S_d)\) ou \(E[\cdot]\) est l’opérateur de moyenne statistique,
CART choisit donc l’attribut et le seuil qui maximisent la décroissance de l’impureté du nœud par rapport à la cible.
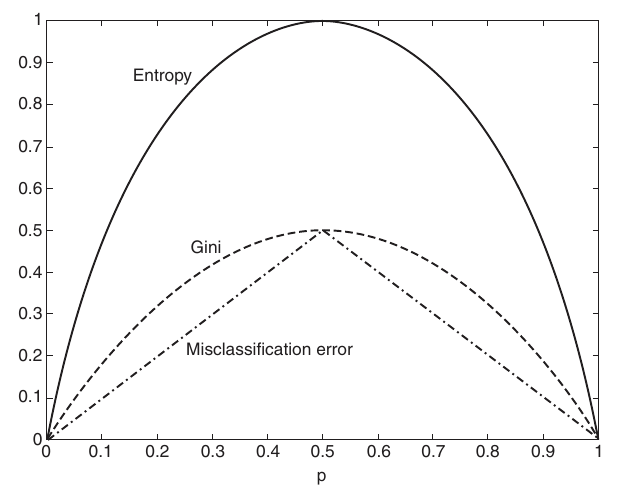
En classification (classement) la mesure de l’impureté utilisée est l’index (ou impureté) de Gini qui est la vraisemblance qu’un élément du nœud soit incorrectement étiquetté par un tirage aléatoire qui respecte la loi statistique de la cible estimée dans le nœud.
L’impureté (ou l’index de Gini \(I_G(S)\)) pour un noued \(S\) est calculée comme suit :
Partitionner \(S\) sur les valeurs de la cible en \(n\) groupes : \(C_1, ..., C_n\),
Calculer \(p_i\) : probabilité estimée qu’un élément de \(S\) se retrouve dans \(C_i\) (\(p_i \approx |C_i|/|S|\)),
Pour des problèmes non-linéaires les arbres générés peuvent être de grande taille avec beaucoup de feuilles qui ont peu d’éléments (souvent un seul). Les premiers splits sont généralement les plus importants et les moins dépendants de l’échantillon, tandis que les suivants décrivent des particularités plus subtiles, pouvant être spécifiques à l’échantillon. Dans ce cas on parle de sur-apprentissage : le modèle généralise mal.
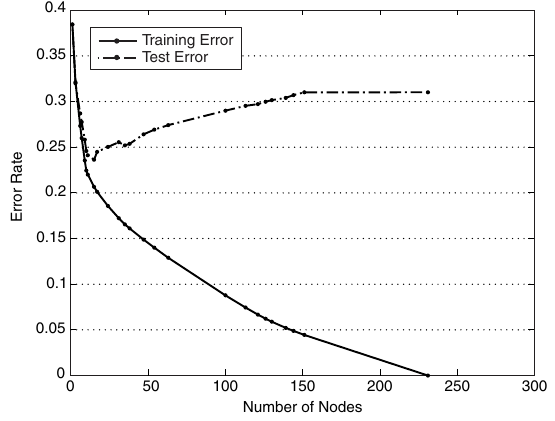
Pour pallier à ce problème il est souhaitable, afin de garder un niveau correct de généralité, d’élaguer l’arbre construit. Pour cela un taux d’erreur de prédiction par validation croisée est calculé pour différentes tailles de l’arbre (i.e., différents nombres de feuilles terminales) : l’arbre est alors à élaguer au niveau offrant l’erreur minimale.
Fig. 42 Erreur de test versus erreur d’apprentissage. Pour des arbres de grande taille, on voit que l’erreur de test ne suit pas l’erreur d’apprentissage (mauvaise généralisation). Dans ce cas, un arbre de petite taille (25 nœuds ici) généralise mieux qu’un arbre plus grand.¶
Dans le cas de données manquantes, la technique la plus utilisée est celle des surrogate splits ou variables-substituts : l’opération continue sur un autre attribut qui, à l’apprentissage, a donné un découpage (split) similaire.
Pour mieux approfondir ces aspects consulter par exemple les ouvrages de référence [RM15] et [HTF06].
Il existe plusieurs extensions développées principalement pour résoudre le problème de la variance élevée des estimateurs fournis par les arbre de décision. Dans la séance de cours suivante nous regarderons :
Bagging decision trees : construction de plusieurs arbres par re-échantillonnage avec remise ; prise de décision par vote consensuel.
Forêts d’arbres décisionnels (ou forêts aléatoires) : apprentissage sur de multiples arbres de décision entraînés sur des sous-ensembles de données légèrement différents.