Jusqu’ici nous nous sommes principalement intéressés à deux aspects :
L’analyse des données, qui consiste à explorer les relations présentes entre multiples variables, afin de mettre en évidence des relations importantes (redondances, complémentarités) entre groupes de variables ou entre groupes d’observations. Nous avons examiné les méthodes d’analyse factorielle linéaire (ACP, étape descriptive de l’AFD, AFCB, ACM) mais aussi la réduction non linéaire de dimension (t-SNE, UMAP) et la classification automatique (K-means, DBSCAN).
La modélisation descriptive des données, qui consiste à construire des modèles synthétique de la distribution des observations. Nous avons ainsi examiné la classification automatique (les groupes ou clusters identifiés sont des modèles descriptifs synthétiques des données) et l’estimation de densités.
Ces méthodes permettent de mieux comprendre les données, d’évaluer leur pertinence, d’ajuster leurs représentations, etc.
Dans la plupart des applications, l’objectif ultime est de prédire les valeurs d’une variable expliquée (ou de sortie) à partir des valeurs de variables explicatives (ou d’entrée). Cela fait l’objet de la modélisation prédictive (ou décisionnelle) ; l’analyse des données et la modélisation descriptive sont en général des étapes préparatoires de la modélisation prédictive.
Examinons maintenant quelques exemples d’applications pour mieux appréhender la notion de prédiction qui est parfois comprise de façon trop restrictive.
Pour décider d’accorder ou non un prêt bancaire, un établissement de crédit doit savoir si le prêt a de bonnes chances d’être remboursé.
Pour conduire un véhicule, un système de conduite autonome doit savoir si une partie de l’image de la caméra frontale représente un piéton, un poteau ou une chaise laissée au bord du trottoir.
Le même système de conduite autonome doit prévoir si un piéton s’apprête à traverser la rue.
Pour faire des suggestions pertinentes, un système de recommandation doit prédire la position qu’occuperait un film dans l’ordre des préférences d’un abonné.
Pour choisir la route, un système de guidage GPS doit prévoir la densité du trafic automobile sur chaque tronçon.
Pour prévoir le développement de différentes espèces de poissons, un organisme de surveillance doit estimer la pollution marine à 10 mètres de profondeur à partir de la pollution de surface, des courants marins et de la température en surface de l’océan.
Pour s’assurer contre la hausse du cours d’une matière première critique pour son activité, un industriel doit prédire l’évolution du cours de cette matière première à horizon d’un an.
Pour alimenter une plate-forme d’information personnalisée, un système doit extraire les entités nommées mentionnées dans des textes provenant de différents médias.
Nous pouvons constater que la prédiction ne concerne pas seulement un fait qui est inconnu car il ne s’est pas encore produit (remboursement d’un prêt, trajectoire du piéton, densité du trafic, cours d’une matière première) et qu’on cherche à prévoir à partir du comportement passé et présent de diverses variables. On parle également de prédiction lorsqu’on cherche à estimer la valeur d’une variable qui serait trop coûteuse à mesurer (pollution en profondeur) ou qui n’est pas directement accessible (interprétation d’une image, ordre de préférences, extraction d’entités nommées), à partir des valeurs prises par différentes variables accessibles.
Par ailleurs, suivant la nature de la variable à prédire, nous pouvons rencontrer différents types de problèmes de prédiction :
Classification (ou discrimination, plus traditionnellement appelé « classement ») : la variable expliquée est une variable nominale, chaque observation possède une modalité (appelée en général classe). Plusieurs exemples précédents sont dans cette catégorie : le prêt sera remboursé ou non, la partie d’image représente une personne ou un poteau ou une chaise, etc.
Régression : la variable expliquée est une variable quantitative (son domaine est en général \(\subset \mathbb{R}\)). Parmi les exemples précédents, rentrent dans cette catégorie la prévision de la densité de trafic, l’estimation de la pollution en profondeur, la prévision du cours d’une matière première.
Ranking (« classement » en français, attention à éviter la confusion avec « classification » ci-dessus) : la variable expliquée est une variable ordinale. Le classement d’un article dans l’ordre de préférence d’un utilisateur fait partie de cette catégorie.
Prédiction structurée : la variable expliquée prend des valeurs dans un domaine de données structurées (dans lequel les relations entre parties comptent). Parmi les exemples précédents, rentrent dans cette catégorie la segmentation d’une image en régions qui possèdent des sémantiques spécifiques, ainsi que l’extraction d’entités nommées d’une phrase.
Afin de caractériser la notion de modèle prédictif, examinons la relation entre prédiction et décision.
Prenons d’abord un exemple simple : comment un banquier du dix-septième siècle décidait-il d’accorder un prêt à un armateur pour monter une expédition (préparer le navire, payer l’équipage, acheter des marchandises) ? Le banquier avait intérêt à accorder un prêt seulement s’il prévoyait un bon remboursement du prêt, c’est à dire un retour du navire avec des marchandises dont la vente permettrait à l’armateur de couvrir les dépenses. Différentes conditions pouvaient éventuellement permettre de conclure à une probabilité élevée de remboursement :
L’armateur a de quoi garantir le prêt en cas d’échec de l’expédition.
L’armateur a un navire récent avec un capitaine expérimenté.
(Un peu) plus complexe : l’armateur a déjà bien remboursé un autre prêt et a un navire récent avec un capitaine expérimenté, en plus il a de quoi garantir 50% du prêt.
Des règles [condition satisfaite \(\rightarrow\) probabilité élevée de remboursement] avec des conditions plus complexes pouvaient également être définies, ce qui rendait alors nécessaire un traitement algorithmique (humain).
Il était possible d’obtenir une telle règle
A partir d’une parfaite compréhension du problème. Par exemple, le prêt est accordé si le débiteur (l’armateur) donne des garanties à hauteur de 100% du montant. Dans la pratique, on ne peut avoir une « parfaite compréhension » que si le nombre de facteurs considérés est très réduit et des aléas sont exclus, les règles résultantes sont alors trop limitatives pour être exploitables.
A partir de données : à partir de constats réalisés sur un (grand, si possible) nombre de cas antérieurs, pour lesquels on connaît à la fois les valeurs prises par un ensemble de facteurs qui comptent (taux de garantie du prêt, âge du capitaine, etc.) et l’issue (remboursementdu prêt ou défaillance). Les « facteurs qui comptent » sont les variables explicatives (ou prédictives, ou d’entrée) et l’issue est la variable expliquée (ou prédite, ou de sortie).
Avant de poursuivre, une clarification de la relation entre prédiction et décision est nécessaire.
En général, une décision s’appuie sur une prédiction. Par exemple, on décide d’accorder un prêt si on prévoit son bon remboursement, ou on décide d’arrêter le véhicule si on prévoit que le piéton traverse la route. En revanche, le passage d’une prédiction à une décision n’est pas toujours simple. La prédiction peut être un score (valeur entre 0 et 100%) alors que la décision qui s’appuie sur cette prédiction est binaire, par exemple issue de la comparaison du score à un seuil (à définir). Aussi, la décision peut être humaine à partir (entre autres…) d’une prédiction obtenue par une règle (qu’on appelle le plus souvent modèle prédictif).
Malgré cette distinction et le passage parfois complexe d’une prédiction à une décision, on parle souvent indifféremment de modèle prédictif ou décisionnel.
Par modèle prédictif nous entendrons ici une fonction \(f\) qui, à partir des valeurs observées des variables explicatives, calcule une valeur (non observée) pour la variable expliquée :
Un modèle \(f\) appartient à une famille \(f \in \mathcal{F}\) et est en général défini par un ensemble de paramètres.
Dans la suite de ce cours nous aborderons les questions majeures suivantes dans le cas des réseaux de neurones :
Dans quelle famille \(\mathcal{F}\) de fonctions chercher le modèle \(f\) ?
Quelles dépendances entre les variables explicatives et la variable expliquée peut représenter (ou approcher) une famille \(\mathcal{F}\) ?
Les capacités d’approximation d’une famille \(\mathcal{F}\) sont-elles suffisantes pour les données qui décrivent le problème que nous cherchons à modéliser ?
Comment trouver le modèle \(f\) dans la famille \(\mathcal{F}\) ?
Quel(s) critère(s) optimiser pour trouver les paramètres qui définissent le modèle optimal \(f^*\) ?
Avant d’étudier dans quelle famille \(\mathcal{F}\) de fonctions chercher le modèle \(f\) il est important de préciser comment sont représentées (ou codées) les variables explicatives et la variable expliquée. Nous avons déjà abordé ce sujet dans le chapitre introductif, nous reprenons ici les méthodes de codage adaptées aux réseaux de neurones pour des variables quantitatives, des variables ordinales et des variables nominales.
Pour les variables quantitatives, un codage numérique direct de leurs valeurs est tout à fait justifié. Différents pré-traitements peuvent être appliqués avant codage, notamment la réduction des variables (moyenne nulle et écart-type égale à 1) pour s’assurer que la même « importance » a priori est accordée aux différentes variables quantitatives.
Pour les variables ordinales, le codage privilégié est le codage unaire qui consiste à représenter une variable ordinale à \(k\) modalités par \(k\) variables binaires, telles que la première modalité est codée par des 0 pour toutes les variables binaires et lorsqu’on avance dans l’ordre des modalités de la variable ordinale une variable binaire supplémentaire prend la valeur 1, comme dans l’exemple suivant :
Pas du tout d’accord
0 0 0 0
Pas d’accord
0 0 0 1
Ni en désaccord ni d’accord
0 0 1 1
Plutôt d’accord
0 1 1 1
Tout à fait d’accord
1 1 1 1
Pour les variables nominales, le codage privilégié est le codage disjonctif (one-hot) qui consiste à représenter une variable nominale à \(k\) modalités par \(k\) variables binaires, telles que la modalité \(i\) est codée par une valeur de 1 pour la variable binaire \(i\) et la valeur 0 pour toutes les autres :
Enseignant
1 0 0 …0 0 0
Médecin
0 1 0 …0 0 0
Technicien
0 0 1 …0 0 0
…
…
Dans la suite nous ferons appel aux notations suivantes :
Variables explicatives (en nombre de \(d\)) : \(X_1, \cdots, X_d\)
Variable expliquée: \(Y\)
Observations (en nombre de \(n\)) : \(o_i = (x_{i1}, \cdots, x_{id}, y_i)\), \(1 \leq i \leq n\)
Nous nous intéressons d’abord aux capacités de représentation des familles \(\mathcal{F}\) candidates pour trouver le modèle (la fonction) \(f\) tel(le) que
Pour les problèmes de régression (la variable \(Y\) est quantitative), une famille largement utilisée est celle des modèles linéaires, \(f(x_{1}, \cdots, x_{d}) = w_0 + \sum_{j=1}^d w_j x_j\), où \(w_j \in \mathbb{R}, 0 \leq j \leq d\) sont les paramètres qui individualisent (ou définissent) un modèle parmi les autres de la même famille.
Pour les problèmes de classification à deux classes (la variable \(Y\) est binaire), la famille correspondante est celle des fonctions linéaires seuillées, \(f(x_{1}, \cdots, x_{d}) = \theta\left(w_0 + \sum_{j=1}^d w_j x_j\right)\), où \(\theta\) est la fonction de Heaviside.
Nous verrons que ces familles sont parfois suffisantes mais peuvent s’avérer limitées, ce qui nous aménera à nous intéresser aux familles de fonctions qui présentent des capacités d’approximation universelle.
Un exemple simple et très bien connu de problème de classification à deux classes est celui des iris (de Anderson ou Fisher). Les données sont constituées de 150 observations de fleurs d’iris, caractérisées par quatre variables quantitatives explicatives (les longueurs et largeurs en centimètres des sépales et des pétales) et une variable nominale expliquée qui est la variété : Iris Setosa, Iris Versicolo(u)r ou Iris Virginica. Chaque variété possède 50 observations dans cet ensemble de données.
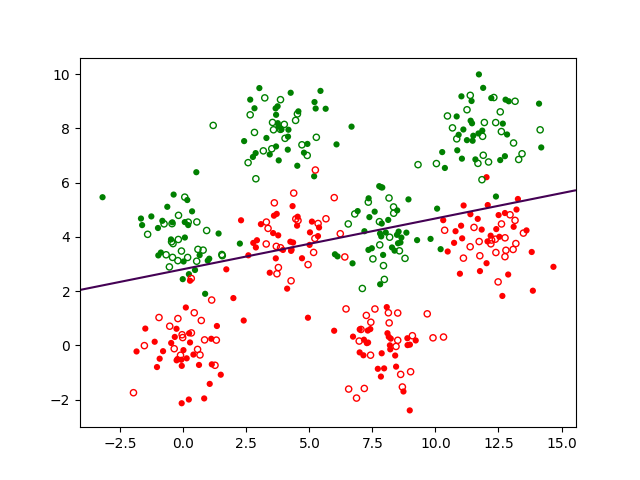
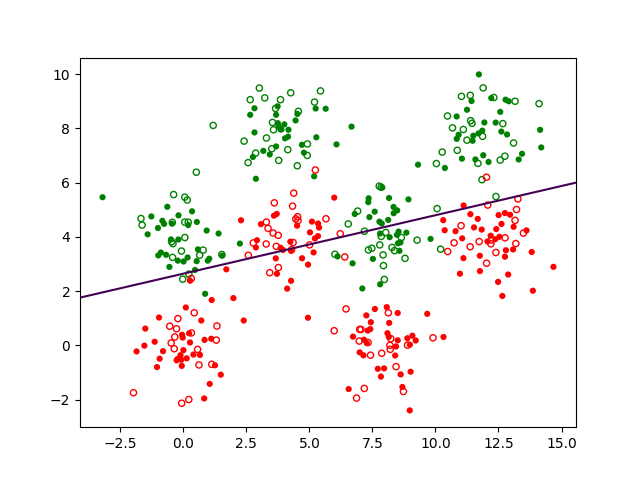
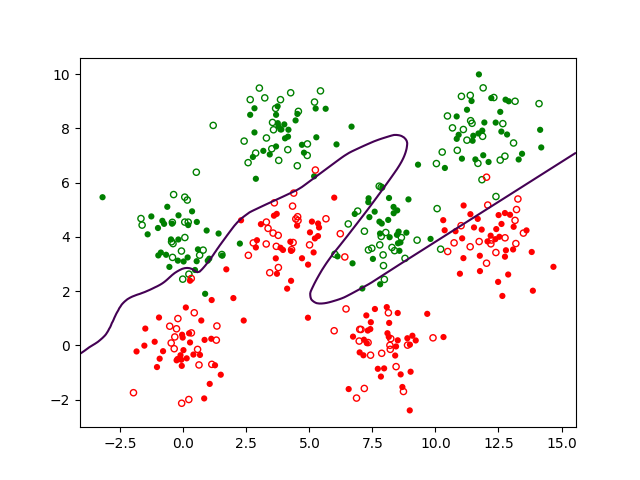
Pour une première illustration, nous considérons une variante simplifiée de ce problème : seulement deux variables explicatives qui sont la longueur des pétales (\(X_1\), en abscisse dans la Fig. 152 suivante) et la largeur des pétales (\(X_2\), en ordonnée), et une classification à 2 classes seulement, Setosa (observations en vert dans la Fig. 152, classe représentée par le code 1) et Versicolor ou Virginica (observations en rouge, classe représentée par le code 0) :
Fig. 152 Illustration : classification à 2 classes des Iris, Setosa (vert) et Versicolor ou Virginica (rouge) à partir de la longueur et de la largeur des pétales¶
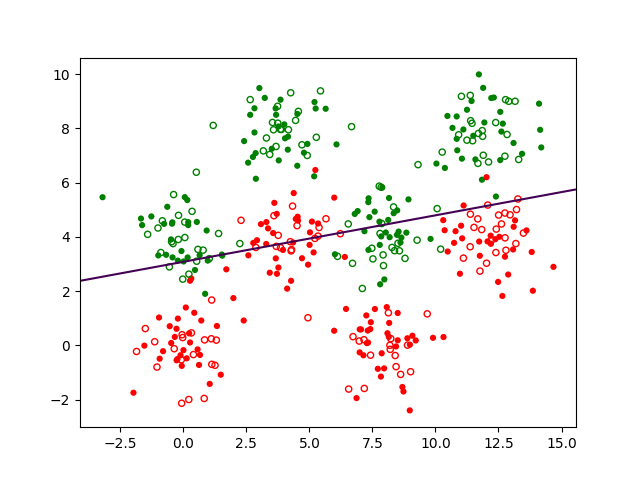
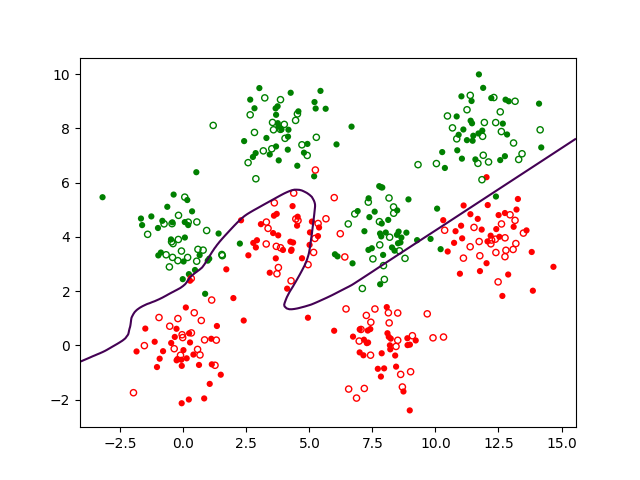
Dans la famille des fonctions linéaires seuillées il est possible de trouver des fonctions qui associent aux valeurs prises par les variables explicatives pour une observation le code de la bonne étiquette de classe pour cette observation. Une frontière de séparation obtenue à partir d’une telle fonction est illustrée dans la Fig. 153 suivante :
La fonction peut être écrite \(f(x_1,x_2) = \left\{ \begin{array}{ll}1 & \textrm{si } z = w_0 + x_1 w_1 + x_2 w_2 \geq 0\\ 0 & \textrm{sinon} \end{array} \right.\) (cette fonction n’est pas explicitement représentée dans la Fig. 153). Dans la figure, le plan gris correspond à l’équation \(z = w_0 + x_1 w_1 + x_2 w_2\), le plan orange est d’équation \(z = 0\) et l’intersection entre ces plans indique la frontière, qui est une droite. Nous pouvons observer que si \(x_1 = x_2 = 0\) alors \(z = w_0\).
Nous pouvons avoir une autre perspective en considérant la frontière directement dans le plan \(z = 0\) : avec les notations \(\mathbf{x} = [x_1, x_2]^\top\) et \(\mathbf{w} = [w_1, w_2]^\top\), l’équation de la frontière \(w_0 + x_1 w_1 + x_2 w_2 = 0\) peut s’écrire \(\mathbf{w}^\top \mathbf{x} + w_0 = 0\). Une telle frontière est illustrée dans la Fig. 154 suivante :
Lorsqu’une frontière linéaire (une droite en 2D, un plan en 3D ou un hyper-plan en dimension supérieure) permet de séparer parfaitement les classes, nous avons affaire à des classes linéairement séparables. Nous examinerons ultérieurement des cas où les classes ne sont pas linéairement séparables.
Il est important de remarquer que si les observations sont écartées entre les deux classes, comme dans la Fig. 154, plusieurs frontières linéaires différentes (et même une infinité de frontières linéaires) séparent parfaitement les classes :
Modèle 1
Modèle 2
Modèle 3
\(w_0, w_1, w_2\):
25.3, -9.51, -2.69
15.6, -4.58, -5.55
11.8, -2.07, -10.44
En examinant l’équation qui doit être satisfaite pour les points se trouvant sur la frontière nous pouvons remarquer également qu’une frontière ne change pas si tous les \(w_j\) sont multipliés par une meme constante \(c \neq 0\).
qui indique une projection de \(\mathbf{x}_i\) sur \(\mathbf{w}\), suivie de la soustraction du seuil \(w_0\).
On constate facilement que la frontière définie par \(\hat{y}_i = 0\) dans l’espace des vecteurs d’entrée reste linéaire quelle que soit \(\phi\).
Pour éviter de séparer le seuil \(w_0\) des autres paramètres on introduit une « variable » d’entrée supplémentaire \(X_0\) dont la valeur est toujours égale à -1 (donc constante) et on note par \(w_0\) le poids de la connexion avec cette entrée ; nous pouvons aussi considérer \(X_0\) toujours égale à 1 et changer le signe de \(w_0\). Le vecteur d’entrée redéfini est alors \(\mathbf{x}_i = [x_{i0}=-1, x_{i1}, \cdots, x_{id}]^\top\) et le vecteur de poids redéfini \(\mathbf{w} = [w_0, w_1, \cdots, w_d]^\top\). L’expression de la sortie devient
Celle-ci est l’expression d’une fonction affine (fonction linéaire suivie d’une translation) des entrées, suivie par l’application de la fonction d’activation\(\phi\).
Parmi les fonctions d’activation nous pouvons mentionner :
Fonction identité
\(\phi(x) = x\)
Fonction de Heaviside
\(\theta(x) = \left\{ \begin{array}{ll}1 & \textrm{si } x \geq 0\\ 0 & \textrm{sinon} \end{array} \right.\)
Rectified Linear Unit (ReLU)
\(\theta(x) = \left\{ \begin{array}{ll}x & \textrm{si } x \geq 0\\ 0 & \textrm{sinon} \end{array} \right.\)
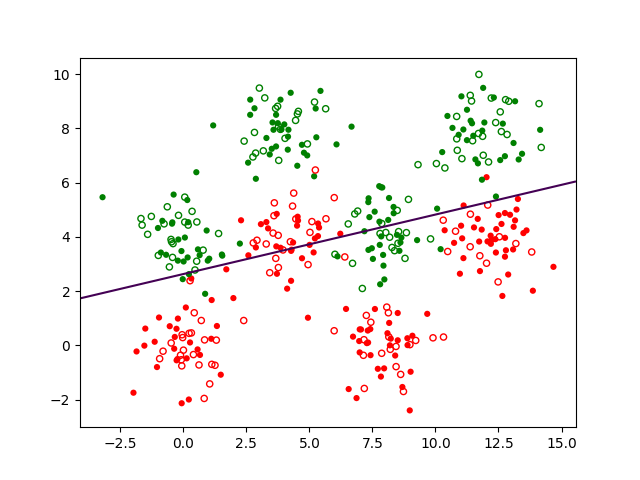
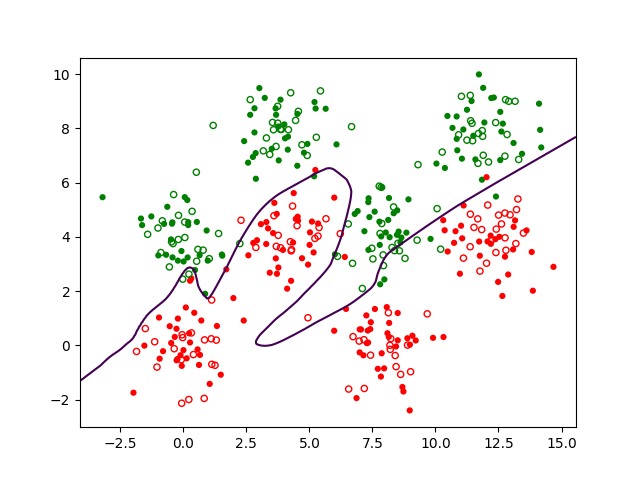
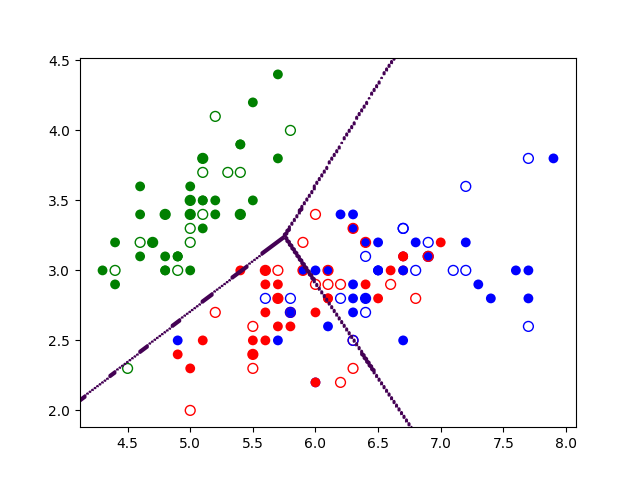
Et si nous souhaitons réaliser une séparation plus difficile, par exemple séparer Iris Versicolor (en vert) des autres classes (en rouge), comme dans la Fig. 156 suivante ?
Fig. 156 Classification à 2 classes des Iris, Versicolor (vert) et Setosa ou Virginica (rouge) à partir de la longueur et de la largeur des pétales¶
Nous constatons que dans un tel cas une frontière linéaire ne suffit plus. Dans cet exemple il serait envisageable de combiner deux frontières linéaires, une entre Versicolor et Setosa (en bas à gauche), l’autre entre Versicolor et Virginica (en haut à droite). Une telle solution est seulement possible si la classe « non Versicolor » a un partitionnement favorable, l’approche n’est donc pas valable dans un cas général.
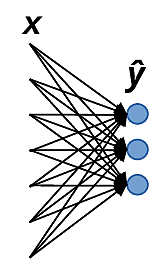
Au-delà de la séparation linéaire : introduction de couche(s) cachée(s)¶
Une solution générale consiste à ajouter une couche de neurones (ou plusieurs couches) pour obtenir un perceptron multi-couches (PMC) qui possède ainsi au moins une couche dite « cachée » car elle n’est ni d’entrée, ni de sortie. La Fig. 157 suivante montre l’architecture d’un réseau à une couche cachée :
Fig. 157 Structure (ou architecture) d’un réseau à une couche cachée¶
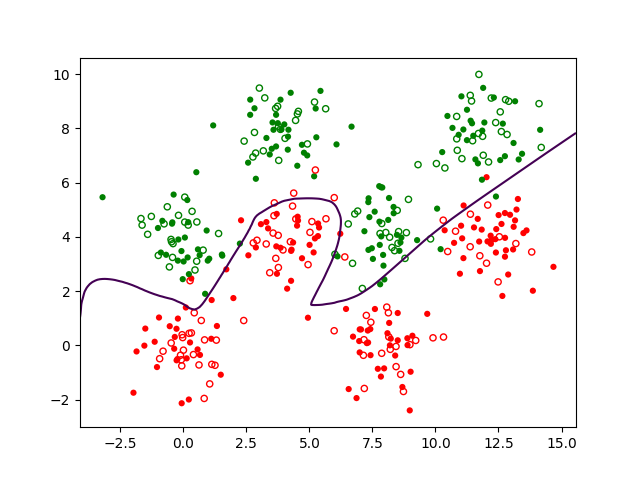
La ou les couches intermédiaires augmentent la capacité de séparation entre classes, comme on peut le voir dans la Fig. 158 suivante :
Fig. 158 Frontière de séparation obtenue en utilisant une couche cachée¶
On parle également d’augmentation de la capacité de représentation du réseau, ou capacité à représenter des séparations possibles entre classes.
Le seul fait d’ajouter une couche cachée permet d’augmenter la capacité de séparation dans tous les cas ? Pour le savoir il est nécessaire d’expliciter les calculs réalisés dans ce cas.
Considérons le vecteur d’entrée (de dimension \(d\)) \(\mathbf{x} = [x_{0}=-1, x_{1}, \cdots, x_{d}]^\top\) et la matrice de poids des \(c\) neurones de la première couche (cachée)
Le vecteur des sorties de la première couche est alors \(\mathbf{h} = \Phi_1\left(\mathbf{W} \mathbf{x}\right)\), où dans \(\Phi_1\) nous avons regroupé l’application des fonctions d’activation aux neurones de la première couche.
En notant le vecteur de poids du neurone de sortie par \(\mathbf{u} = [u_{1}, \cdots, u_{h}]^\top\), alors l’activation de ce neurone peut s’écrire \(\hat{y} = \phi_2\left(\mathbf{u}^\top \mathbf{h} + u_{0}\right)\). Remarquons que \(u_{0}\) peut être intégré à \(\mathbf{u}\) suivant le même procédé que pour la première couche.
Si les neurones de la première couche (couche cachée) ont des fonctions d’activation identité, alors \(\hat{y} = \phi_2\left(\mathbf{u}^\top \mathbf{h} + u_{0}\right) = \phi_2\left(\mathbf{u}^\top \mathbf{W} \mathbf{x} + u_{0}\right)\) qui est une fonction affine (linéaire suivie de translation) des entrées, ce qui implique que la frontière définie par ce réseau à une couche cachée est toujours linéaire !
Employer des fonctions non linéaires dans les neurones de la couche cachée est donc indispensable pour obtenir des frontières de séparation non linéaires.
Il est utile de déterminer quelles fonctions de transfert entre l’entrée et la sortie du réseau peuvent être calculées suivant le nombre de couches cachées, le nombre de neurones dans les différentes couches cachées et les fonctions d’activation des neurones des différentes couches cachées. Ces classes de fonctions de transfert sont obtenues par la composition de fonctions affines et fonctions d’activation.
Ce qui s’avère être encore plus utile est de déterminer les limites de ces calculs, c’est à dire ce qui ne peut pas être calculé. Comme dans le cas précédent, où nous avons montré que si les fonctions d’activation des neurones cachés sont l’identité alors la fonction de transfert du réseau reste affine quel que soit le nombre de neurones dans la couche cachée. Il est facile d’étendre ce résultat en montrant qu’il reste valable quel que soit le nombre de couches cachées à fonctions d’activation identité.
Plusieurs résultats d’approximation universelle ont été obtenus pour les perceptrons multi-couches (PMC). Dans [Cyb89], [BH89], [Hor91], [Pin99] on montre ainsi que, quelle que soit \(f\) une fonction continue sur des ensembles compacts de \(\mathbb{R}^d\) (c’est à dire des ensembles bornés et fermés), une approximation aussi bonne que souhaité de cette fonction \(f\) peut être obtenue avec un PMC ayant un nombre fini de neurones dans une unique couche cachée et une fonction d’activation non polynomiale (donc aussi non linéaire, le cas linéaire correspondant à un polynôme de degré 1).
Deux remarques sont importantes :
Une couche cachée suffit pour obtenir cette capacité d’approximation universelle à condition qu’elle contienne un nombre suffisant de neurones avec une fonction d’activation non linéaire appropriée.
Si les fonctions d’activation des neurones sont polynomiales alors la fonction de transfert du PMC est également polynomiale.
Nous pouvons mentionner que d’autres résultats d’approximation existent (et peuvent être facilement trouvés), concernant par exemple le nombre de couches cachées de taille bornée.
Un seul neurone de sortie suffit pour aborder un problème de classification à deux classes car le niveau d’activation du neurone peut indiquer la classe prédite :
pour une fonction d’activation identité ou \(\tanh\), une classe correspond à \(\hat{y} >\) 0 et l’autre classe à \(\hat{y} <\) 0,
pour une fonction de Heaviside ou sigmoïde (asymétrique), une classe correspond à \(\hat{y} > 0.5\) et l’autre classe à \(\hat{y} < 0.5\).
En revanche, cette solution n’est évidemment pas généralisable à plus de deux classes. Une solution généralisable consiste à employer un codage one-hot pour la variable expliquée « classe » et à avoir un neurone de sortie par classe, celui qui a l’activation la plus grande indiquant à quelle classe est affectée l’observation présentée en entrée. C’est cette solution qui est la plupart du temps également employée pour la classification à deux classes.
Dans le cas de la classification il est en général utile d’avoir une interprétation de probabilités pour les activations des neurones de sortie, ce qui implique que l’activation de chaque neurone doit rester dans l’intervalle \([0, 1]\) et que la somme des activations de tous les neurones de sortie doit être égale à 1 (condition de normalisation). Cette dernière condition implique qu’il n’est plus possible de calculer l’activation de chaque neurone de sortie indépendamment des autres.
L’emploi d’une fonction d’activation softmax permet de répondre à ces exigences. Il faut noter que la fonction softmax s’applique à un ensemble de neurones pour respecter la condition de normalisation. Pour définir cette fonction, considérons un problème de classification à \(K\) classes et donc un réseau à \(K\) neurones de sortie. Soit \(\mathbf{x}\) le vecteur d’entrée de tous les neurones de sortie et, pour chaque neurone de sortie \(k\), soit \(\mathbf{w}_k\) son vecteur de poids et \(w_{0k}\) son seuil. On note par \(s_k = \mathbf{w}_k^\top \mathbf{x} + w_{0k}\) la sortie du neurone \(k\)avant application de la fonction softmax. La sortie du neurone \(k\) avec softmax est définie par
Il est facile de constater que softmax garantit le respect de la condition de normalisation : \(\forall\mathbf{x}, \sum_{k=1}^K P(k | \mathbf{x}) = 1\).
La sortie du neurone \(k\) est souvent interprétée comme la probabilité a posteriori de la classe \(k\) : \(P(k | \mathbf{x}) = \hat{y}_k(\mathbf{x})\). Nous remarquerons que si le respect de la normalisation autorise à traiter ces valeurs comme des probabilités, rien ne garantit en général qu’après l’apprentissage du réseau ces valeurs soient vraiment les probabilités a posteriori des classes !
Pour illustrer notre propos, considérons les données Iris avec les trois classes, Setosa, Versicolor et Virginica, et examinons les frontières entre classes obtenues à partir des longueurs et largeurs des pétales (figure suivante, côté gauche), ou à partir des longueurs et largeurs des sépales (figure suivante, côté droit) en utilisant des réseaux avec trois neurones en sortie (et activation softmax) mais sans couche cachée :
Sur longueurs et largeurs pétales
Sur longueurs et largeurs sépales
Nous pouvons remarquer que sans couche cachée les frontières entre classes deux à deux restent linéaires.
La Fig. 159 suivante montre les sorties des trois neurones, avec activation softmax, d’un réseau sans couche cachée qui classe les Iris en trois classes :
Fig. 159 Surfaces en 3D représentant les sorties des trois neurones d’un réseau sans couche cachée qui classe les Iris en trois classes à partir des longueurs et largeurs des pétales. La couleur de chaque surface correspond à la couleur de la classe à laquelle le neurone est associé. Les points pleins sont les observations d’apprentissage employées, les points creux sont les observations de test (voir explications plus loin).¶
Pour l’évaluation des performances d’un modèle il est nécessaire de pouvoir mesurer l’écart entre les prédictions réalisées par le modèle et les prédictions correctes supposées connues (sorties désirées du modèle). Si on considère une observation \((\mathbf{x},\mathbf{y})\), où \(\mathbf{x} = [x_{1}, \cdots, x_{d}]^\top\), la façon de mesurer l’écart entre la prédiction \(\hat{\mathbf{y}}(\mathbf{x})\) du modèle et la sortie désirée \(\mathbf{y}\) dépend de la nature du problème mais aussi de l’objectif de cette mesure (rapporter les performances ou apprendre le modèle).
Pour un problème de classification on emploie couramment :
L’entropie croisée (cross-entropy) : pour \(K\) classes et un codage one-hot, avec un neurone de sortie par classe, le neurone \(k\) prédit la probabilité d’appartenance de l’observation \(\mathbf{x}\) à la classe \(k\). L’entropie croisée entre les prédictions faites par le modèle, \(\hat{\mathbf{y}}\), et les sorties désirées correspondantes du modèle, \(\mathbf{y}\), est alors :
La classe correcte pour l’observation \(\mathbf{x}\) est \(k^*\), donc \(y_{k^*} = 1\) et \(y_k = 0\) pour tout \(k \neq k^*\), donc la définition devient :
Observation 1 : nous pouvons avoir l’impression que seule compte la sortie du neurone correspondant à la bonne classe ; mais comme on emploie en général l’activation softmax en sortie, la sortie du neurone de la bonne classe dépend aussi des sorties des autres neurones !
Observation 2 : si \(\hat{y}_{k^*} \rightarrow 0\), la pénalité augmente sans limite \(\mathcal{E}_{ce} \rightarrow +\infty)\).
Pour un problème de régression on emploie habituellement
L’erreur quadratique entre les prédictions faites par le modèle, \(\hat{y}\), et les sorties désirées correspondantes du modèle, \(y\) :
\[\mathcal{E}_2(\hat{y},y) = \|\hat{y} - y\|^2\]
Cette erreur est calculée pour chaque variable expliquée (ou prédite) si nous sommes en présence de plusieurs variables expliquées.
Le choix d’une fonction d’erreur dépend aussi de l’objectif de la mesure : certaines fonctions sont utiles pour rapporter de façon succincte les performances d’un modèle (comme l’erreur 0-1 pour un problème de classification), d’autres permettent aussi d’apprendre le modèle (comme l’entropie croisée) car elles sont différentiables.
Comment obtenir un modèle à partir de données ? Il est d’abord nécessaire de disposer d’un ensemble d’observations (ou exemples) d’apprentissage qui sont étiquetées, c’est à dire pour lesquelles sont connues à la fois les valeurs des variables explicatives et la valeur correspondante de la variable expliquée.
Par « apprentissage » d’un modèle nous entendons le fait de trouver le modèle, ce qui revient en général à trouver les valeurs des paramètres du modèle (valeurs qui individualisent ce modèle dans sa famille). Par exemple, pour un réseau de neurones d’architecture donnée les paramètres à trouver sont les poids des connexions (\(w_j\)) et les seuils des neurones (\(w_0\)).
Afin de trouver les paramètres du modèle il est nécessaire de disposer d’un bon critère. L’objectif de la construction du modèle est de faire les meilleures prédictions sur de futures observations, inconnues lors de l’apprentissage mais supposées issues de la même distribution que les exemples d’apprentissage. Comme ces futures observations sont inconnues, l’optimisation explicite des performances du modèle sur ces observations ne peut pas servir de critère. Le critère retenu le plus souvent est la minimisation des erreurs faites sur les exemples d’apprentissage, en ajoutant toutefois à ces erreurs un terme de régularisation supposé permettre de maîtriser la complexité du modèle résultant. Comme nous le verrons dans Apprentissage et généralisation, sans maîtrise de la complexité il y a un risque élevé de sur-apprentissage (ou « d’apprentissage par cœur » des exemples d’apprentissage).
Le critère étant défini, comment déterminer les valeurs optimales paramètres ? Dans la plupart des cas, les valeurs optimales sont trouvées par l’application d’un algorithme itératif d’optimisation. Dans certains cas, comme par exemple pour la régression linéaire, les valeurs optimales des paramètres peuvent être calculées analytiquement (voir par ex. ici).
Un algorithme d’optimisation itérative procède de la façon suivante :
Initialisation des paramètres par tirages aléatoires suivant une distribution « convenable », c’est à dire une distribution qui facilite les étapes itératives suivantes.
A chaque itération, modification des paramètres pour se diriger vers un minimum (si possible global mais plus fréquemment local) de la fonction de coût considérée (par ex. l’erreur d’apprentiussage + terme de régularisation). Si on note par \(\mathbf{w}\) le vecteur de paramètres (regroupant les poids et les seuils des différentes couches de neurones pour un réseau neuronal) et par \(t\) l’itération, la modification s’exprime sous la forme suivante :
Différentes méthodes peuvent être employées pour trouver une modification \(\Delta \mathbf{w}_{t}\) adéquate, nous examinerons dans la suite la descente de gradient.
Un critère d’arrêt de l’algorithme itératif doit également être défini. L’algorithme peut s’arrêter lorsque l’optimisation ne peut pas se poursuivre (\(\Delta \mathbf{w}_{t} \approx 0\)), ou après un nombre maximal pré-déterminé d’itérations, ou lorsqu’une autre fonction commence à augmenter (par ex. l’erreur sur des données de validation, voir Régularisation par « arrêt précoce » (early stopping)), etc.
Une méthode d’optimisation itérative fréquemment employée est la descente de gradient. Dans le cas des réseaux de neurones, cette méthode peut s’appliquer si les conditions suivantes sont satisfaites :
L’architecture du réseau de neurones est fixée.
La fonction de transfert entre l’entrée et la sortie du réseau est différentiable.
Pour illustrer la descente de gradient, considérons d’abord le cas simple d’une fonction de coût \(\mathcal{E}\) dépendant de deux paramètres, \(w_1\) et \(w_2\). La Fig. 160 suivante montre la surface correspondant au critère \(\mathcal{E}\) à minimiser en fonction des valeurs des deux paramètres (représentés par les axes du plan horizontal).
A l’itération \(t\) le vecteur de paramyètres est \(\mathbf{w}_{t}\) et la valeur correspondante de \(\mathcal{E}\) est relativement élevée. On applique au vecteur de paramètres \(\mathbf{w}_{t}\) une modification (indiquée par la flêche) dans la direction opposée au gradient du critère par rapport aux paramètres, c’est à dire dans la direction de la décroissance la plus rapide de \(\mathcal{E}\). La courbe dans le plan des paramètres indique la trajectoire lors des itérations successives, jusqu’au vecteur de paramètres \(\mathbf{w}_{f}\) (final) correspondant à un minimum local de \(\mathcal{E}\). La courbe sur la surface indique l’évolution correspondante du critère \(\mathcal{E}\) lors des itérations successives.
Fig. 160 Descente de gradient : illustration simple¶
Afin de mieux comprendre, considérons d’abord le cas unidimensionnel illustré dans la Fig. 161. Soit une fonction \(g: \mathbb{R} \rightarrow \mathbb{R}\), notons son argument par \(w\).
Fig. 161 Descente de gradient : illustration pour un seul paramètre¶
Le gradient de \(g\) dans \(w = w_t\) est un scalaire dans ce cas unidimensionnel : la dérivée de \(g\) par rapport à \(w\) dans \(w = w_t\), \(\frac{dg}{dw}(w_t)\). La dérivée de \(g\) par rapport à \(w\) est positive dans \(w = w_t\), en appliquant une modification \(w_{t+1}\)\(= w_t + \Delta w_t\), où \(\Delta w_t = \eta \frac{dg}{dw}(w_t)\) avec \(\eta > 0\), on augmente la valeur de \(g\) (remontée de gradient). Pour se diriger plutôt vers un minimum de \(g\), la modification à appliquer est \(\Delta w_t = - \eta \frac{dg}{dw}(w_t)\) avec \(\eta > 0\) (descente de gradient).
Un cas bidimensionnel simple devrait permettre de mieux appréhendfer le gradient comme vecteur. Comme illustré dans Fig. 162, considérons la fonction \(g: \mathbb{R}^m \rightarrow \mathbb{R}\), d’argument vectoriel \(\mathbf{w} = \left[w_1 \atop w_2\right]\). Le gradient de \(g\) pour l’argument \(\mathbf{w} = \mathbf{w}_t\) est le vecteur des dérivées partielles de \(g\) par rapport à chaque composante de \(\mathbf{w}\) dans \(\mathbf{w} = \mathbf{w}_t\), c’est à dire
Fig. 162 Descente de gradient : illustration pour deux paramètres (\(g: \mathbb{R}^2 \rightarrow \mathbb{R}\)) ; courbes de niveau représentées en bleu¶
Comment choisir la valeur de la constante \(\eta > 0\) appelée « vitesse de convergence » (ou vitesse d’apprentissage) ? Il faut d’abord remarquer que la convergence de la descente de gradient suivant \(\Delta \mathbf{w}_t = - \eta \nabla g(\mathbf{w}_t)\) vers minimum (global ou local) de \(g\) est assurée si \(\eta\) est suffisamment faible pour que \(\Delta \mathbf{w}\) soit infinitésimal. Bien entendu, avec une valeur \(\eta\) trop faible la convergence serait trop lente. En revanche, avec \(\eta\) trop élevé la convergence peut être lente aussi car \(\Delta \mathbf{w}\) peut être trop élevé, comme on peut le voir dans la figure suivante, et n’est plus assurée.
Fig. 163 Descente de gradient : vitesse trop élevée¶
Enfin, quelle que soit la valeur fixe de \(\eta\), si le gradient est élevé (= pente forte) alors \(\Delta \mathbf{w}\) est potentiellement trop élevé, alors que si le gradient est faible (= pente faible) \(\Delta \mathbf{w}\) est faible et donc la convergence lente. Il est donc important de pouvoir régler la vitesse lors du processus de convergence, ce que nous examinerons un peu plus loin avec des méthodes d’amélioration de la convergence.
Avant cela, regardons comment on procède pour la descente de gradient (calcul de l’erreur, de son gradient et modification des poids) sur les \(n\) exemples d’apprentissage \(\{(\mathbf{x}_1, \mathbf{y}_1), \ldots, (\mathbf{x}_i, \mathbf{y}_i), \ldots, (\mathbf{x}_n, \mathbf{y}_n)\}\). Nous avons le choix entre les solutions suivantes :
Par lot global (batch) : l’erreur est cumulée sur la totalité des \(n\) exemples (l’ordre de présentation des exemples n’a donc pas d’importance), \(\mathcal{E} = \sum_{i=1}^n \mathcal{E}(\hat{\mathbf{y}}_i, \mathbf{y}_i)\), ensuite les paramètres sont mis à jour \(\Delta \mathbf{w}_t = - \eta \nabla \mathcal{E}\) ; à l’itération suivante un nouveau calcul de l’erreur est réalisé sur le lot global et on continue.
Stochastique (online) : on choisit aléatoirement un exemple, on met à jour les paramètres après un calcul de l’erreur sur cet exemple, \(\Delta \mathbf{w}_t = - \eta \nabla \mathcal{E}(\hat{\mathbf{y}}_i, \mathbf{y}_i)\) ; à l’itération suivante on fait un nouveau choix aléatoire d’un exemple et on continue.
Par mini-lot (mini-batch) : on choisit un (petit par rapport à \(n\)) échantillon d’exemples \(\mathcal{S}_j\), l’erreur est cumulée sur cet échantillon, les paramètres sont mis à jour \(\Delta \mathbf{w}_t = - \eta \nabla \mathcal{E}(\mathcal{S}_j)\) ; à l’itération suivante on fait un nouveau choix d’échantillon et on continue.
Nous pouvons remarquer qu’en mini-batch le gradient de l’erreur globale (sur les \(n\) exemples) n’est jamais calculé et ne peut donc être suivi que de façon très approximative. On constate dans la pratique que le nombre d’itérations est en général plus élevé que par lot global mais le coût total (nombre d’itérations \(\times\) coût de chaque itération) est plus faible.
On parle de descente de gradient stochastique (Stochastic Gradient Descent, SGD) dans les cas 2 et 3. Noter que souvent lorsqu’on parle de batch on entend plutôt mini-batch, car il est très rare de procéder par lot global.
Par époque d’apprentissage on entend un passage (calcul de l’erreur, de son gradient et modification des poids) sur la totalité des \(n\) exemples d’apprentissage. Si on procède par lot global alors une époque permet de traiter tous les exemples d’apprentissage (une fois) et de mettre à jour les poids (une fois), et correspond donc à une seule itération d’apprentissage. Si on procède par mini-batch de taille \(m \ll n\), alors une époque correspond au passage sur \(n\) exemples d’apprentissage mais le gradient est calculé et les poids sont mis à jour sur chaque mini-batch, une époque correspond donc à \(\frac{n}{m}\) itérations !
Amélioration de la convergence de la descente de gradient¶
La fonction à minimiser par descente de gradient peut être très complexe, comme l’indique par ex. la Fig. 164 (obtenue pour un réseau de neurones réel où tous les paramètres sont fixés à l’exception des deux paramètres en fonction desquels la surface est tracée).
Fig. 164 Coût à minimiser - cas réel (illustration issue de [Ulm21])¶
Il est facile de voir que dans une telle situation la descente de gradient peut rencontrer de multiples difficultés pour converger : convergence trop lente si la pente est faible, « traversée de la valée » si la pente est trop forte, nombreux minima locaux, etc. De nombreux travaux ont permis de proposer diverses solutions pour faciliter la convergence.
Les travaux sur l’adaptation de la vitesse \(\eta\) sont motivés par :
La convergence de la descente de gradient est démontrée lorsque les modifications sont infinitésimales ou \(\eta\) tend vers 0, ce qui aurait pour conséquence une convergence extrêmement lente.
Lors de la traversée d’un « plateau », une valeur \(\eta\) pas assez élevée rendrait la traversée du plateau trop longue.
Une valeur trop élevée pour \(\eta\), surtout si la norme du gradient est élevée, rendrait l’exploration de l’espace quasi-aléatoire, les modifications \(\Delta \mathbf{w}\), de forte amplitude, ne permettant plus de réduire \(g(\mathbf{w})\).
Si le minimum recherché dans un « puits » étroit à paroies abruptes, une valeur pas assez faible pour \(\eta\) ne permettrait pas de descendre dans le puits.
Des méthodes très diverses prennent en compte une ou plusieurs de ces motivations. Dans Scikit-learn, par exemple, learning_rate=’adaptive’ permet de diviser la vitesse \(\eta\) par 5 si, lors de 2 époques successives, la fonction à minimiser \(f\) ne diminue pas d’au moins tol. Cette méthode répond aux motivations 3 et 4.
Une solution intéressante permettant d’améliorer la convergence consiste à ajouter un terme d”« inertie » (momentum) dans le calcul de la modification à apporter aux poids à partir de la valeur du gradient. Les motivation prises en compte sont les suivantes :
Si la pente est faible alors le gradient est faible, accumuler les modifications apportées précédemment permet de rendre la convergence plus rapide (sans changer la valeur de \(\eta\)).
Lorsque la direction du gradient change fortement à chaque itération, une composante d”« inertie » devrait lisser la trajectoire et ainsi accélérer la convergence.
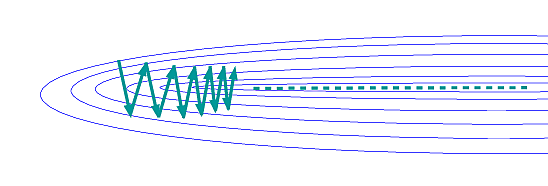
pour \(\beta > 0\), en tenant donc compte à l’itération \(t\) non seulement du gradient calculé à l’itération \(t\) mais également de la modification \(\Delta \mathbf{w}_{t-1}\) appliquée à l’itération précédente \(t-1\). Le coefficient \(\beta\) est typiquement dans l’intervalle \([{0.8}, {0.9}]\). L’illustration suivante permet de voir l’impact de l’utilisation de l’inertie dans le cas où la direction du gradient change fortement à chaque itération car le minimum se trouve dans une vallée étroite.
Trajectoire sans inertie :
Trajectoire avec inertie :
Il est important de noter que l’inertie a également un autre effet qui s’avère souvent utile dans le cas de la descente de gradient stochastique (SGD). En l’absence d’inertie, la trajectoire suivrait les gradients par mini-batch, qui changent fréquemment de direction entre mini-batches successifs, et non le gradient de l’erreur totale. L’inertie a un effet de lissage de la trajectoire et, en général, d’accélération de la convergence.
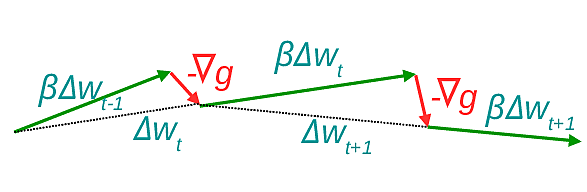
La prise en compte de l’inertie consiste à calculer le gradient pour la valeur courante de \(\mathbf{w}_t\) et ensuite ajouter la contribution de l’inertie, \(\beta \Delta \mathbf{w}_{t-1}\), à la contribution du gradient \(- \eta \nabla g(\mathbf{w}_t)\).
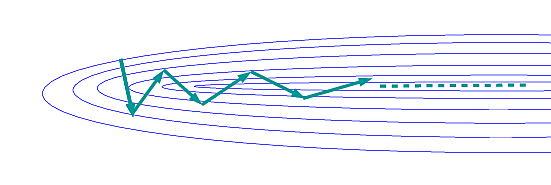
Il serait peut-être plus intéressant de suivre d’abord l’inertie, ensuite de calculer le gradient dans le point d’arrivée après modification des poids par application de l’inertie (plutôt que dans le point de départ) et appliquer la modification due au gradient (voir par ex. [SMDH13]). Comme indiqué dans la Fig. 165, on suit d’abord l’inertie (flèche verte), ensuite on calcule le gradient dans le point d’arrivée (le point intermédiaire \(\mathbf{w}_t + \beta \Delta \mathbf{w}_{t-1}\)) et on corrige (flèche rouge).
Fig. 165 Dans la méthode de Nesterov, calcul du gradient dans le point d’arrivée après application de l’inertie¶
La mise à jour des poids se fait dans ce cas suivant
La méthode Adam [KB15] est issue de plusieurs constats réalisés en examinant des problèmes complexes d’optimisation :
Le gradient contient beaucoup de « bruit » en raison de la complexité de la fonction à optimiser et de l’aspect stochastique de la SGD, ce qui implique qu’il est en général utile de lisser la trajectoire.
Toutes les composantes de \(\mathbf{w}\) ne sont pas modifiées avec la même fréquence (par ex. en raison de vecteurs d’activation creux provenant des couches précédentes), il est donc utile d’individualiser par paramètre la vitesse d’apprentissage plutôt que d’utiliser une constante unique.
Adam s’appuie sur un calcul de moyennes décroissantes (ou « avec oubli ») par des relations de récurrence :
Moyenne du gradient, qui est donc un vecteur (et permet de faire un lissage de la trajectoire) :
Moyennes des carrés des composantes des gradients, qui sont des scalaires qui dépendent ainsi du carré de la composante correspondante du gradient (et permettent une individualisation de la vitesse d’apprentissage) :
Ces estimations présentent des biais qu’il est possible de corriger par : \(\hat{\mathbf{m}}_t = \frac{\mathbf{m}_t}{1-\beta_1}\), \(\hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1-\beta_2}\).
Avec Adam, la mise à jour au moment \(t\) d’un paramètre \(w_{i}\) (poids ou seuil) se fait suivant
où \(\hat{v}_{it}\) et respectivement \(\hat{m}_{it}\) sont les composantes correspondant à \(w_{i}\) dans les vecteurs \(\hat{\mathbf{m}}_t\) et respectivement \(\hat{\mathbf{v}}_t\) calculés plus haut.
Nous pouvons constater dans (63) que la modification de \(w_{i}\) suit la moyenne lissée du gradient, mais la vitesse d’apprentissage est individualisée et modifiée de façon inversement proportionnelle à la moyenne lissée des amplitudes des modifications précédentes. Le rôle de \(\epsilon=10^{−8}\) est d’éviter la division par zéro.
Pour les (hyper-)paramètres, des valeurs typiques sont \(\eta=.001\), \(\beta_1=.9\), \(\beta_2=.999\) et \(\epsilon=10^{−8}\).
Dans cette section nous examinons le calcul du gradient de l’erreur par rapport aux différents paramètres d’un réseau de neurones multi-couches, qui sont les poids des connexions et les seuils.
Calcul du gradient pour un réseau sans couche cachée¶
Considérons d’abord le cas le plus simple, celui d’un réeau sans couche cachée, et déterminons le gradient de l’erreur par rapport aux poids des connexions de la seule couche de neurones.
Fig. 166 Réseau sans couche cachée. Lorsque le vecteur \(\mathbf{x}\) est présenté en entrée, le vecteur de sortie obtenu est \(\hat{\mathbf{y}}\).¶
Nous avons décrit plus haut comment l’erreur était cumulée sur la totalité des données d’apprentissage (dans le cas d’un batch global) ou sur un mini-batch. Ce cumul se transfère directement au calcul du gradient de l’erreur car la dérivation est une opération linéaire. Pour éviter de surcharger les notations, dans la suite nous considérerons le calcul du gradient de l’erreur faite sur un seul exemple d’apprentissage.
Pour fixer les choses, supposons que le réseau possède \(K\) neurones dans son unique couche, avec une activation softmax pour faire de la classification en \(K\) classes mutuellement exclusives. Supposons également que la fonction d’erreur est l’entropie croisée. Aussi, considérons que le seuil \(w_{0k}\) d’un neurone est intégré dans son vecteur de poids \(\mathbf{w}_k\).
Pour un vecteur d’entrée \(\mathbf{x}\), la sortie du neurone \(k\) est alors
où nous avons utilisé la notation \(s_k(\mathbf{x}) = \mathbf{w}_k^\top \mathbf{x}\).
Si la classe correcte pour \(\mathbf{x}\) est \(k^*\), alors avec un codage one-hot de la sortie désirée \(\mathbf{y}\) nous avons \(y_{k^*} = 1\) et \(y_k = 0\) pour \(k \neq k^*\). L’erreur entropie croisée du neurone \(k\) est alors
Il est utile de rappeler ici la règle de dérivation d’une fonction composée de fonctions scalaires (chain rule) \((f \circ g \circ h)(z) = f(g(h)))(z)\): \(\frac{df(g(h))}{dz} = \frac{df}{dg} \frac{dg}{dh} \frac{dh}{dz}\).
En appliquant cette règle aux dérivées partielles de l’erreur par rapport aux poids des connexions (c’est à dire aux composantes du gradient recherché) nous obtenons :
Dans cette expression nous avons précisé les points où les dérivées respectives étaient calculées (\(\mathbf{w}_t\), \(\mathbf{\hat{y}}_t\), \(\mathbf{s}_t\)), ainsi que l’itération \(t\).
Pour faciliter les calculs, il est très utile d’exprimer le gradient en fonction de quantités déjà calculées.
Pour le premier facteur de l’expression précédente,
(où \(\delta_{k^*k} = \left\{\begin{array}{ll} 1 & \textrm{si} \, k = k^* \\ 0 & \textrm{sinon} \end{array} \right.\) permet d’écrire le résultat sous une forme plus compacte)
Calcul du gradient pour un réseau à couche(s) cachée(s)¶
Lorsqu’il y a au moins une couche cachée, nous devons déterminer comment l’erreur dépend de chaque poids de chaque neurone de chaque couche. Nous verrons que le calcul peut être fait en partant de la couche de sortie et en remontant vers l’entrée du réseau, couche après couche.
Fig. 167 Réseau à couche(s) cachée(s). Voir le texte pour les notations.¶
Nous employons les notations suivantes :
La matrice de poids des neurones de la couche \(l\) est notée \(\mathbf{W}_l\) (les seuils des neurones sont intégrés à la matrice).
Les sorties des neurones de la couche \(l\) sont notées \(\mathbf{h}_l\).
La fonction activation de la couche \(l\) est \(\phi_l\).
La première étape consiste à calculer l’activation des neurones, en partant de la première couche et en allant vers la couche de sortie (forward pass) :
Les activations des neurones de la couche 1 à partir du vecteur d’entrée \(\mathbf{x}\) : \(\mathbf{h}_1 = \phi_1 (\mathbf{u}_1)\), avec \(\mathbf{u}_1 = \mathbf{W}_1 \mathbf{x}\).
Les activations des neurones de la couche \(l\) à partir des activations des neurones de la couche \(l-1\) : \(\mathbf{h}_l = \phi_l (\mathbf{u}_l)\), avec \(\mathbf{u}_l = \mathbf{W}_l \mathbf{h}_{l-1}\).
Les activations des neurones de sortie à partir des activations des neurones de la couche \(l\) (dernière couche cachée) : \(\hat{\mathbf{y}} = \phi_{out} (\mathbf{u}_{l+1})\), avec \(\mathbf{u}_{l+1} = \mathbf{W}_{l+1} \mathbf{h}_{l}\).
Pour les poids des neurones de la couche de sortie, en notant par \(w_{kj(l+1)}\) le poids de la connexion qui relie la sortie du neurone \(j\) de la couche \(l\) à une entrée du neurone \(k\) de la couche de sortie :
Pour une fonction d’activation \(\phi_{out}\)softmax et une erreur entropie croisée (cas typique de la classification multi-classes, c’est à dire avec des classes mutuellement exclusives) nous trouvons un résultat similaire au cas sans couche cachée mais \(h_{jl}\) remplace \(x_j\) :
Pour une fonction d’activation \(\phi_{out}\) sigmoïde \(\sigma\left(u_{k(l+1)}\right) = \frac{1}{1+e^{-u_{k(l+1)}}}\) et une erreur quadratique \(\mathcal{E} = \|\hat{\mathbf{y}} - \mathbf{y}\|^2\) (cas typique de la classification multi-label, c’est à dire avec des classes qui ne sont pas mutuellement exclusives) :
Plus généralement, pour une fonction d’activation \(\phi_{out}\) quelconque, calculée indépendamment pour chaque neurone de sortie, et une fonction d’erreur \(\mathcal{E}\) quelconque :
Examinons maintenant le cas général du calcul de la dérivée partielle de l’erreur par rapport à un poids \(w_{kjl}\) de la connexion qui relie la sortie du neurone \(j\) de la couche \(l-1\) à une entrée du neurone \(k\) de la couche \(l\). Pour calculer \(\frac{\partial \mathcal{E}}{\partial w_{kjl}}\), en considérant l’activation \(h_{kl}\) comme fonction scalaire intermédiaire, nous avons :
Reste à déterminer \(\frac{\partial \mathcal{E}}{\partial h_{kl}}\). Nous pouvons constater que \(\mathcal{E}\) dépend de \(h_{kl}\) à travers les activations de tous les neurones de la couche suivante \(l+1\), donc à travers la fonction vectorielle\(\mathbf{h}_{l+1}\). Par une généralisation de la règle de dérivation des fonctions composées nous avons :
Or, \(\frac{\partial \mathcal{E}}{\partial h_{i(l+1)}}\) ont déjà été calculées pour les neurones de la couche \(l+1\). Donc, sachant que \(\frac{\partial h_{i(l+1)}}{\partial h_{kl}} = \frac{\partial h_{i(l+1)}}{\partial u_{i(l+1)}} \frac{\partial u_{i(l+1)}}{\partial h_{kl}}\), nous obtenons :
Nous pouvons donc constater que les gradients de \(\mathcal{E}\) par rapport aux activations\(h_{i(l+1)}\) sont ainsi rétro-propagés (propagés de la sortie vers l’entrée du réseau) pour le calcul du gradient de \(\mathcal{E}\) par rapport aux poids :
car \(\frac{\partial h_{i(l+1)}}{\partial u_{i(l+1)}} = \frac{d \phi_{l+1}}{d u_{i(l+1)}}\), où \(\phi_{l+1}\) est la fonction d’activation des neurones de la couche \(l+1\), et \(\frac{\partial u_{i(l+1)}}{\partial h_{kl}} = w_{ik}\), avec \(w_{ik}\) le poids de la connexion qui relie la sortie du neurone \(k\) de la couche \(l\) à une entrée du neurone \(i\) de la couche \(l+1\).
Pour finir, déterminons la dérivée partielle de l’erreur par rapport au poids \(w_{kj1}\) de la connexion entre la composante \(j\) du vecteur d’entrée et le neurone \(k\) de la première couche de neurones (couche 1) :
avec \(\frac{\partial \mathcal{E}}{\partial h_{k1}}\) et \(\frac{\partial h_{k1}}{\partial u_{k1}}\) obtenus comme dans le cas général pour \(l \leftarrow 1\), et \(\frac{\partial u_{k1}}{\partial w_{kj1}} = x_j\), la composante \(j\) du vecteur d’entrée.
Erreur d’apprentissage et erreur de généralisation¶
Rappelons d’abord que par modèle nous entendons une fonction \(\mathbf{x} \overset{f}{\longrightarrow} \mathbf{y}, f \in \mathcal{F}\) déterminée (« apprise ») à partir des données d’apprentissage \(\mathcal{D}_n=\{(\mathbf{x}_i,\mathbf{y}_i)\}_{1,\ldots,n}\). Notre objectif, en revanche, est de faire les meilleures prédictions sur de futures observations, inconnues lors de l’apprentissage mais supposées issues de la même distribution que les exemples d’apprentissage, donc d’obtenir la meilleure généralisation possible.
L’erreur de généralisation peut être estimée par l’erreur sur un échantillon dit de test, différent de l’échantillon d’apprentissage mais issu de la même distribution. Une estimation de l’erreur de généralisation par l’erreur d’apprentissage serait trop optimiste.
Dans quelle famille \(\mathcal{F}\) de fonctions devons-nous chercher \(f\) ?
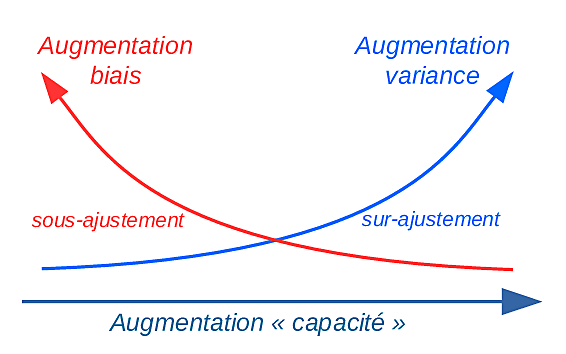
Plus la « capacité » de \(\mathcal{F}\) est élevée, plus il est probable d’avoir dans \(\mathcal{F}\) un modèle \(f^*\) qui approche la bonne dépendance (entrée \(\rightarrow\) sortie). Nous aurions donc intérêt à choisir une famille \(\mathcal{F}\) de « capacité » aussi grande que possible. La notion de capacité d’une famille de modèles sera étudiée un peu plus dans cette section de l’UE RCP209.
En revanche, nous verrons que plus la « capacité » de \(\mathcal{F}\) est élevée, plus il est difficile de trouver le modèle \(f^*\) (qui pourtant est dans \(\mathcal{F}\)) à partir des seules observations disponibles, c’est à dire les observations d’apprentissage. Choisir une famille \(\mathcal{F}\) de « capacité » aussi grande que possible ne serait donc pas une si bonne idée.
Nous pouvons comparer, sur un problème simple de classement à deux classes de données bidimensionnelles, deux familles de modèles, les modèles \(\mathcal{F}_l\) linéaires et des modèles \(\mathcal{F}_{nl}\) non linéaires (perceptrons multi-couches), en regardant les frontières de séparation obtenues, les erreurs d’apprentissage et les erreurs de test (estimations des erreurs de généralisation).
Nous considérons pour chaque famille de modèles quatre échantillons d’apprentissage différents, les échantillons de test étant à chaque fois les données restant de l’ensemble des données disponibles. Dans les illustrations suivantes les deux couleurs correspondent aux deux classes, les données d’apprentissage sont représentées par les points pleins et les données de test par les points creux. Les scores sont les taux de bon classement, les valeurs les plus élevées correspondent donc aux meilleures performances.
Résultats pour différents échantillons dans le cas des modèles \(\mathcal{F}_l\) linéaires :
Score apprentissage: 0.8
Score apprentissage: 0.837
Score test: 0.856
Score test: 0.8
Score apprentissage: 0.837
Score apprentissage: 0.86
Score test: 0.81
Score test: 0.775
Résultats pour différents échantillons dans le cas des modèles \(\mathcal{F}_{nl}\) non linéaires (PMC) :
Score apprentissage: 0.946
Score apprentissage: 0.966
Score test: 0.906
Score test: 0.93
Score apprentissage: 0.96
Score apprentissage: 0.946
Score test: 0.94
Score test: 0.918
Nous pouvons observer que :
Pour les modèles linéaires (famille \(\mathcal{F}_l\)) la frontière varie peu avec l’échantillon mais les performances restent médiocres car on n’arrive pas à approcher la bonne frontière. Les modèles linéaires sont ici sous-ajustés ou présentent un fort biais.
Pour les modèles non linéaires (famille \(\mathcal{F}_{nl}\)) les performances sont meilleures sur les données d’apprentissage comme sur les données de test, mais la frontière varie beaucoup avec l’échantillon d’apprentissage, il y a une forte variance. Les performances de test sont ici en général sensiblement inférieures aux performances d’apprentissage, les modèles non linéaires « sur-apprennent » ici, ou sont sur-ajustés à l’échantillon.
Le constat que nous avons fait est typique et exprimé souvent par le dilemme biais-variance : pour réduire le biais il faut élargir la famille de modèles et on est alors confrontés à une augmentation de la variance ; cela rend plus difficile l’identification, à partir des seules données d’apprentissage, d’un modèle qui généralise bien.
Fig. 168 L’augmentation de la « capacité » permet une réduction du biais mais engendre une augmentation de la variance.¶
Pour améliorer les performances du modèle tout en réduisant l’écart de performance entre apprentissage et généralisation il est nécessaire de chercher le modèle \(f\) dans une famille \(\mathcal{F}\) de capacité suffisante (réduire le biais) tout en « maîtrisant » la complexité du modèle sélectionné, en évitant les modèles « trop complexes » de \(\mathcal{F}\).
La régularisation lors de l’apprentissage consiste en général à pénaliser la complexité additionnelle au sein d’une famille \(\mathcal{F}\). La solution la plus courante est de minimiser conjointement l’erreur d’apprentissage et une pénalité qui augmente avec la complexité du modèle :
Ici \(\mathcal{R}(f)\) est un terme de régularisation explicite, pondéré par la constante de régularisation \(\alpha\). Une valeur optimale doit être trouvée pour l’hyper-paramètre\(\alpha\), comme nous le verrons plus loin. En effet, si la valeur de \(\alpha\) est trop faible alors la régularisation est insuffisante et le sur-apprentissage probable. Si la valeur de \(\alpha\) est trop élevée alors la régularisation est trop forte et le biais excessif.
Cette formulation du problème d’optimisation montre que le meilleur modèle doit faire un compromis entre la réduction de l’erreur d’apprentissage (le risque empirique) et la réduction de la complexité. On parle de Minimisation du Risque Empirique Régularisé (MRER).
Régularisation \(L_2\) ou par « oubli » (weight decay)¶
Une expression courante pour la pénalité est
\[\mathcal{R}(f) = \|\mathbf{w}\|^2\]
où \(\mathbf{w}\) correspond à un vecteur qui contient tous les paramètres (poids des connexions et biais des neurones) du réseau.
On parle dans ce cas de régularisation \(L_2\). Ce type de régularisation est employé très largement dans l’apprentissage à partir de données et non seulement pour les réseaux de neurones.
Le risque empirique régularisé (65) étant minimisé par descente de gradient, il est nécessaire de pouvoir calculer le gradient de \(\mathcal{R}(f)\) par rapport aux paramètres (poids et biais), ce qui est très facile :
Le terme \(- 2\alpha w_t\) justifie le nom de régularisation par « oubli » (ou weight decay).
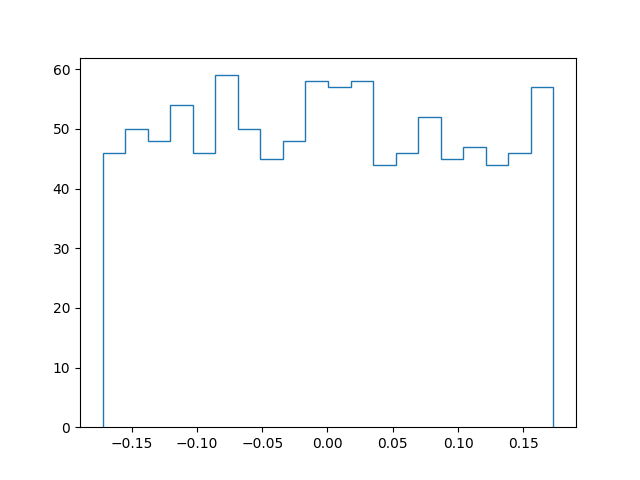
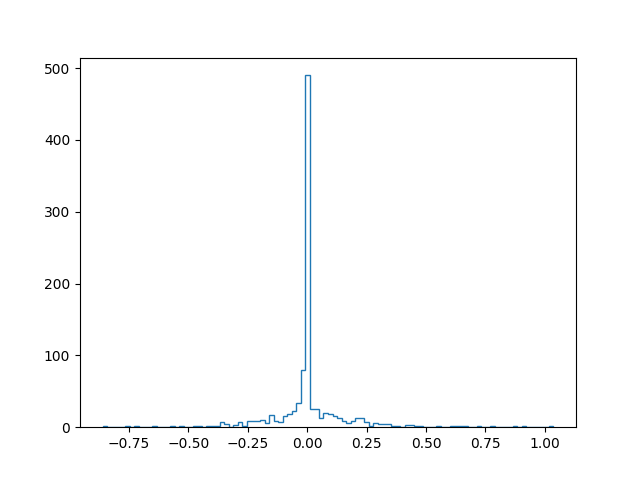
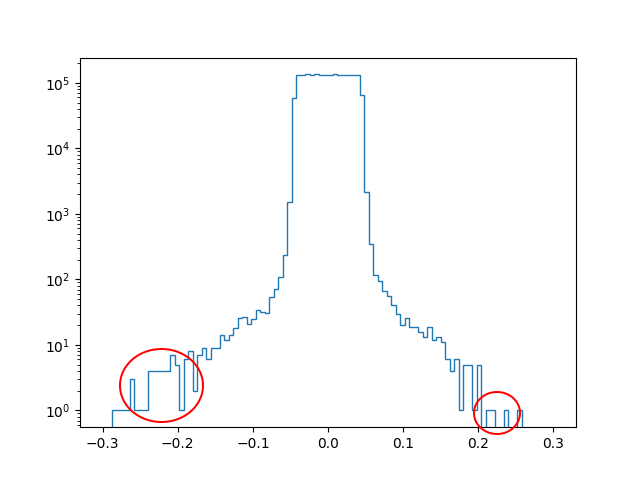
Pour mieux appréhender l’effet de la régularisation par « oubli », considérons un réseau de neurones et examinons l’histogramme des poids des connexions dans différentes situations. D’abord après initialisation aléatoire des poids (avant toute modification par descente de gradient), ensuite après apprentissage sans régularisation (\(\alpha = 0\)) :
Après initialisation :
Alpha : 0.0
Score apprentissage: 0.844
Score test: 0.683
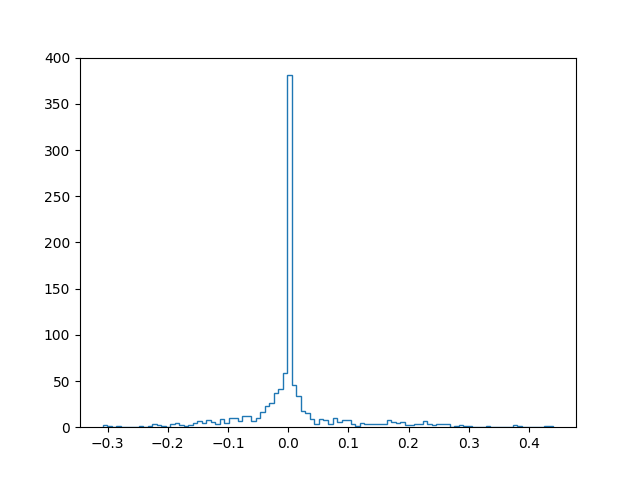
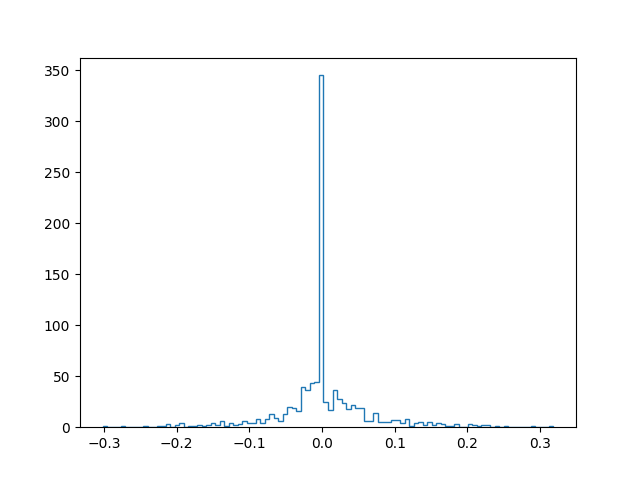
Enfin, après apprentissage avec régularisation, pour différentes valeurs de l’hyper-paramètre \(\alpha\) (attention, dans les figures, l’échelle de l’axe horizontal est de plus en plus dilatée lorsque \(\alpha\) augmente) :
Alpha: 0.5
Alpha: 5.0
Alpha: 10.0
Score apprentissage: 0.866
Score apprentissage: 0.822
Score apprentissage: 0.744
Score test: 0.716
Score test: 0.733
Score test: 0.683
Lorsque \(\alpha\) augmente nous pouvons constater que :
L’histogramme des poids se concentre de plus en plus autour de 0.
L’écart entre l’erreur d’apprentissage et l’erreur de test diminue.
Pour une valeur de \(\alpha\) trop élevée, les erreurs d’apprentissage et de test augmentent (le biais augmente), la régularisation devient donc excessive.
Pourquoi la régularisation \(L_2\) fonctionne-t-elle ?
Pour les réseaux de neurones, les valeurs des poids restent plus proches de 0 et donc les fonctions d’activation travaillent plus dans leur partie quasi-linéaire (c’est plus facile à voir pour des fonctions d’activation de type sigmoïde), ce qui implique que la fonction de transfert du réseau est plus « lisse ».
Dans un cas général, on considère qu’elle permet de réduire la sensibilité au « bruit » en entrée.
Régularisation par « arrêt précoce » (early stopping)¶
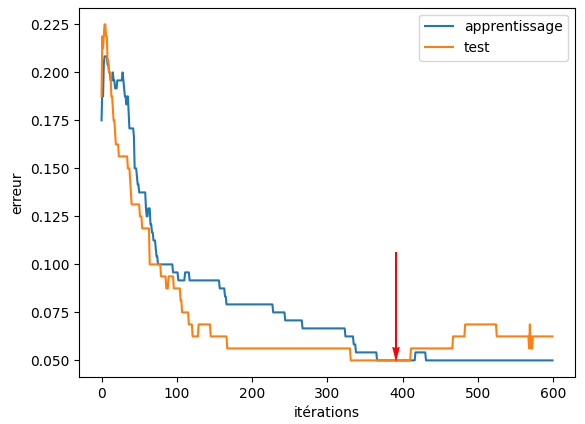
En examinant comment évolue l’erreur sur l’échantillon d’apprentissage et respectivement sur l’échantillon de test (rappelons que l’erreur de test est une estimation de l’erreur de généralisation) lors des itérations d’apprentissage successives, nous constatons que l’erreur de test commence à remonter assez nettement à partir d’un certain point alors que l’erreur d’apprentissage continue de diminuer (même si de plus en plus faiblement). Ce comportement est illustré dans la Fig. 169 suivante. Bien entendu, si la vitesse d’apprentissage est trop élevée, des fluctuations peuvent apparaître dans l’évolution de l’erreur, mais en lissant ces fluctuations on retrouve le même comportement.
Fig. 169 Évolution de l’erreur d’apprentissage et de l’erreur de test lors des itérations d’apprentissage¶
Un « arrêt précoce » (early stopping) consiste à arrêter l’apprentissage lorsque l’erreur sur un échantillon différent de l’échantillon d’apprentissage est minimale, sans chercher à atteindre un minimum de l’erreur d’apprentissage. Ce moment correspond à la flèche rouge dans la Fig. 169. L’échantillon sur lequel on « surveille » l’erreur permettant l’arrêt précoce ne peut pas être l’échantillon de test car cet arrêt précoce revient à une sélection de modèle et si l’échantillon ayant permis la sélection de modèle était employé pour estimer la généralisation alors l’estimation serait optimiste. Cet échantillon porte en général le nom d’échantillon de validation et est différent à la fois de l’échantillon d’apprentissage et de l’échantillon de test.
L’arrêt précoce est bien une technique de régularisation, même si la minimisation par descente de gradient porte sur le risque empirique (erreur d’apprentissage) seul, sans pénalité \(\mathcal{R}(f)\) explicite.
Quel est le phénomène qui se produit lors des itérations d’apprentissage et pourquoi la régularisation par arrêt précoce fonctionne-t-elle ? On constate que lors de l’initialisation aléatoire les valeurs des poids sont faibles (en valeur absolue) et lors de l’apprentissage ces valeurs s’écartent de 0. Certaines connexions notamment voient les valeurs de leurs poids diverger fortement pour arriver à bien classer des exemples d’apprentissage atypiques et cela permet donc au réseau d’apprendre ces exemples « par cœur », donc de sur-apprendre et ainsi de dégrader sa capacité de généralisation. L’arrêt précoce permet d’arrêter cette divergence des poids lorsque l’erreur sur l’échantillon de validation, qui sert lors de l’apprentissage d’estimation de l’erreur de généralisation, est minimale.
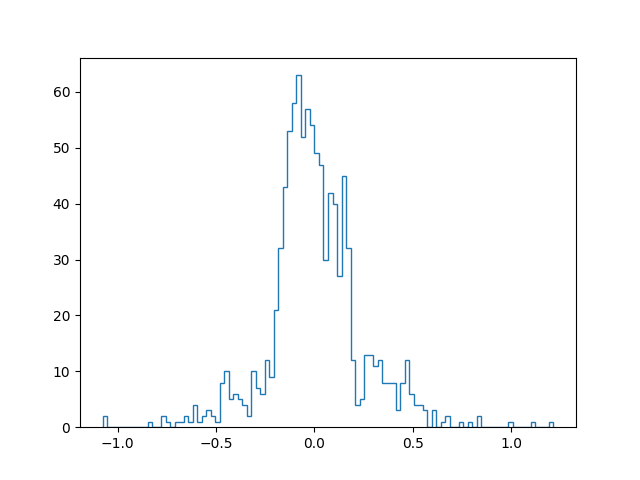
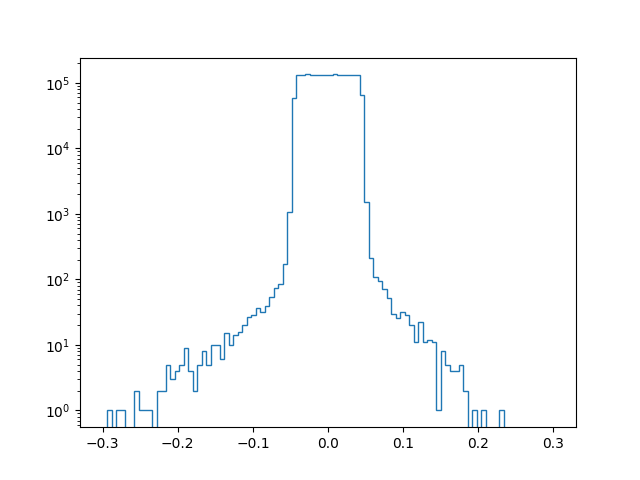
Les illustrations suivantes permettent de comparer l’histogramme des poids d’un réseau arrêté par cette méthode (à droite) à l’histogramme correspondant au même réseau qui a poursuivi son apprentissage (à gauche). Si les différences entre les histogrammes des valeurs des poids sont moins saillantes que celles constatées avec l’utilisation de la régularisation par « oubli », on observe quand même que les queues de distribution sont moins fournies lorsque l’arrêt précoce est employé.
500 itérations
400 itérations (arrêt précoce)
Score apprentissage : 0.951
Score apprentissage : 0.946
Score test : 0.928
Score test : 0.937
On observe par ailleurs que l’arrêt précoce permet d’améliorer le score (ici, le taux de bon classement) sur l’échantillon de test (différent de celui de validation sur lequel l’arrêt précoce à été fait) et de réduire l’écart entre l’erreur d’apprentissage et l’erreur de test.
Pour finir cette section, nous pouvons mentionner brièvement (liste non exhaustive) d’autres méthodes de régularisation employées avec les réseaux de neurones, qui seront étudiées plus dans l’UE RCP209 :
L’utilisation de mini-batch (par opposition à batch) : on observe que l’introduction d’une dose de stochasticité dans la minimisation de la fonction de coût fait converger le réseau vers des minima plus « larges », associés à une meilleure généralisation.
Normalisation des activations par couche : permet d’éviter l’explosion de certaines valeurs d’activations qui peut avoir comme effet la saturation de neurones dans des couches suivantes, avec comme conséquence une augmentation de la non linéarité, donc potentiellement du sur-apprentissage, ainsi qu’une poursuite plus difficile de l’apprentissage en raison de l’annulation des gradients rétro-propagés.
Dropout (traduit par « décrochage » ou « abandon ») : désactivation aléatoire de neurones, avec une probabilité \(p\), lors de l’apprentissage ; a comme effet la réduction de la « coadaptation » de différents neurones dans des couches successives, or cette coadaptation permet au réseau de bien classer des exemples d’apprentissage atypiques et dégrade la capacité de généralisation.
Il est important de noter qu’en général plusieurs méthodes de régularisation sont utilisées simultanément !
Représentations apprises par les réseaux de neurones¶
Dans les perceptrons multi-couches (PMC) les prédictions sont obtenues grâce à des changements de représentation des données, couche après couche. Pour mieux comprendre le fonctionnement des PMC il est utile d’examiner ces changements de représentation. Nous nous intéressons dans la suite à deux cas différents :
Problème de régression « auto-supervisé » : le PMC doit apprendre à reproduire en sortie le vecteur d’entrée, à travers des couches cachées dont au moins une est de dimension inférieure (bottleneck) à la dimension de l’entrée ; on parle d’autoencodeur car la représentation obtenue dans cette couche cachée pour un vecteur d’entrée peut être vue comme un encodage plus compact de sa représentation d’entrée. Il a été montré que dans un tel cas le PMC effectuait une version non linéaire de l’analyse en composantes principales (ACP).
Problème de classification supervisée multi-classe : le PMC doit apprendre à affecter chaque vecteur d’entrée à une classe parmi plusieurs. Il a été montré que dans un tel cas le PMC effectuait une version non linéaire de l’analyse factorielle discriminante (AFD).
Représentations internes développées pour l’auto-encodage¶
L’objectif de la tâche d’auto-encodage est d’obtenir, pour chaque vecteur d’entrée, un code de dimension plus faible mais conservant le plus d’information permettant de reconstruire au mieux ce vecteur
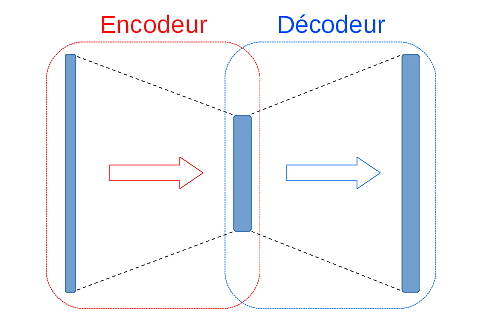
Un autoencodeur est constitué, comme le montre la Fig. 170, d’une partie encodeur suivie d’une partie décodeur. L’encodeur transforme un vecteur d’entrée \(\mathbf{x}\) en un « code » \(\mathbf{h}\) (de dimension inférieure à celle de \(\mathbf{x}\)). Le décodeur reconstitue, à partir d’un code \(\mathbf{h}\), un vecteur de sortie \(\hat{\mathbf{y}}\) qui doit se rapprocher le plus possible du vecteur d’entrée \(\mathbf{x}\) qui est encodé dans \(\mathbf{h}\).
L’apprentissage d’un auto-encodeur est un apprentissage auto-supervisé (self-supervised), car la sortie désirée \(\mathbf{y}\) coincide avec l’entrée \(\mathbf{x}\).
Examinons d’abord l’auto-encodeur linéaire qui emploie l’analyse en composantes principales (ACP). Nous utilisons les notations suivantes :
\(\mathbf{X}\) (matrice \(n \times d\)) est la matrice des données centrées, dont chaque ligne \(\mathbf{x}^{\top}_i\) est une observation et chaque colonne \(\mathbf{x}_j\) correspond à une des \(d\) variables.
\(\mathbf{U}_k\) (matrice \(d \times k\)) est la matrice qui a comme colonnes les vecteurs propres unitaires \(\mathbf{u}_j, 1 \leq j \leq k\) associés aux \(k\) plus grandes valeurs propres de la matrice des covariances empiriques des \(d\) variables.
\(\mathbf{h}^{\top}_i\) est le code de dimension \(k < d\) qui encode l’observation \(\mathbf{x}^{\top}_i\) ; chaque code est une ligne de la matrice \(\mathbf{H}_k\) (de dimensions \(n \times k\)).
Un auto-encodeur linéaire basé sur une ACP est composé d’un encodeur linéaire suivi d’un décodeur linéaire :
L’encodeur projette orthogonalement chaque observation \(\mathbf{x}_i\) sur les \(k\) composantes principales de l’analyse du nuage d’observations pour obtenir le code correspondant, \(\mathbf{h}_i\). Cette projection est une transformation linéaire qui peut être écrite sous la forme \(\mathbf{H}_k = \mathbf{X} \mathbf{U}_k\).
Le décodeur reconstruit (approximativement) l’observation \(i\), \(\hat{\mathbf{y}}_i \approx \mathbf{x}_i\) à partir de son code \(\mathbf{h}_i\). Cette transformation peut être écrite sous la forme \(\hat{\mathbf{X}}^* = \mathbf{H}_k \mathbf{U}_k^{\top}\), qui montre que la transformation est linéaire.
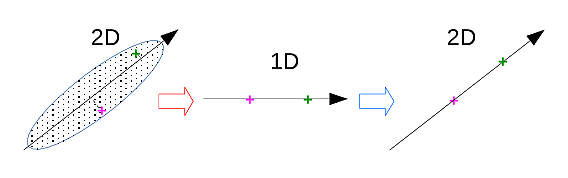
La Fig. 171 montre pour des données bidimensionnelles simples comment est réalisé l’encodage, par projection sur l’axe principal (et donc réduction de la dimension de 2 à 1), et ensuite le décodage, avec re-projection dans l’espace bidimensionnel initial :
Fig. 171 Illustration de l’encodage (projection sur le premier axe principal) et du décodage avec un auto-encodeur linéaire (re-projection dans l’espace initial 2D).¶
Cette solution est optimale (parmi les solutions linéaires possibles avec une valeur de \(k\) fixée) car, suivant le théorème de Eckart-Young-Mirsky, \(\hat{\mathbf{X}}^*\) est la meilleure approximation de rang \(k\) de \(\mathbf{X}\) : \(\hat{\mathbf{X}}^* = \arg \min_{\hat{\mathbf{X}}} \|\hat{\mathbf{X}} - \mathbf{X}\|_F\), \(\|\cdot\|_F\) étant la norme de Frobenius.
L’approximation des observations par leur projection sur un sous-espace linéaire n’est pas toujours un bon choix, comme le montre la Fig. 172 :
Fig. 172 Un sous-espace non linéaire (à droite) peut « ajuster » le nuage des observations mieux qu’un sous-espace linéaire (au milieu).¶
Un sous-espace non linéaire qui « ajuste » mieux les observations (se rapproche plus des observations) permettrait de mieux reconstituer les données de départ, malgré un passage par des codes de dimension faible. Ce sous-espace doit néanmoins rester assez « simple » pour bien ajuster la distribution des données et non seulement l’échantillon d’apprentissage !
Examinons maintenant de plus près le fonctionnement d’un auto-encodeur PMC. Nous considérons donc un PMC dont la couche de sortie est de même dimension que l’entrée et qui contient une seule couche cachée de dimension inférieure à celle de l’entrée. Par code on entend ici le vecteur d’activation des neurones de la couche cachée. L’apprentissage est auto-supervisé : on cherche à prédire, pour l’entrée \(\mathbf{x}\), une sortie désirée qui est idéntique à l’entrée \(\mathbf{y} = \mathbf{x}\), en minimisant l’erreur quadratique entre la sortie obtenue \(\hat{\mathbf{y}}\) et l’entrée présentée \(\mathbf{x}\).
Dans le cas le plus simple nous pouvons employer une couche cachée de \(k\) neurones avec une fonction d’activation identité, ce qui permet d’obtenir l’expression suivante pour la sortie du réseau (encodeur sans couche cachée suivi de décodeur sans couche cachée) : \(\hat{\mathbf{x}} = \mathbf{W}_2 \mathbf{h} = \mathbf{W}_2 \mathbf{W}_1 \mathbf{x}\). Si on note \(\mathbf{W} = \mathbf{W}_2 \mathbf{W}_1\) alors il est possible de montrer (voir par exemple [BH89]) que
L’erreur est minimisée lorsque la fonction de transfert entre l’entrée et la sortie de l’auto-encodeur PMC est la projection orthogonale sur le sous-espace engendré par les vecteurs propres associés aux \(k\) plus grandes valeurs propres de l’ACP des observations d’apprentissage.
La représentation des données sur la couche cachée correspond (à une transformation linéaire de rang maximal près) à la projection orthogonale sur ces \(k\) vecteurs propres.
Ce minimum de l’erreur est global et il est également unique [BH89] dans le sens où la solution \(\mathbf{W}\) est unique (noter toutefois qu’une même matrice \(\mathbf{W}\) peut être obtenue à partir d’une infinité de matrices \(\mathbf{W}_1, \mathbf{W}_2\)).
Considérons maintenant un cas plus général, où l’encodeur et le décodeur comportent chacun au moins une couche cachée avec une fonction d’activation non linéaire, et comparons cet auto-encodeur non linéaire à un auto-encodeur par ACP et à l’auto-encodeur par PMC linéaire sur lequel nous venons de mentionner les résultats théoriques.
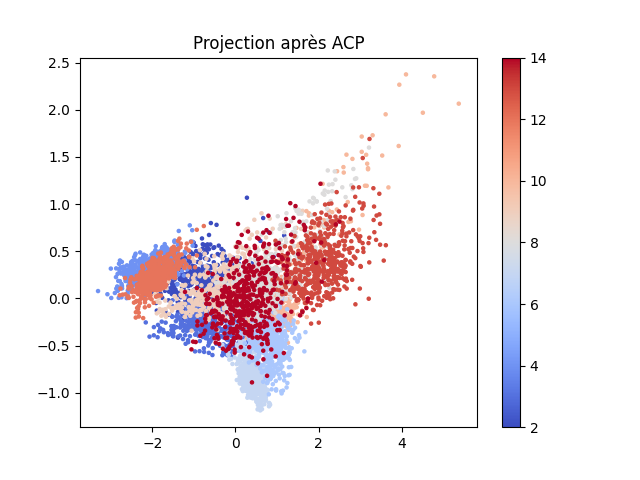
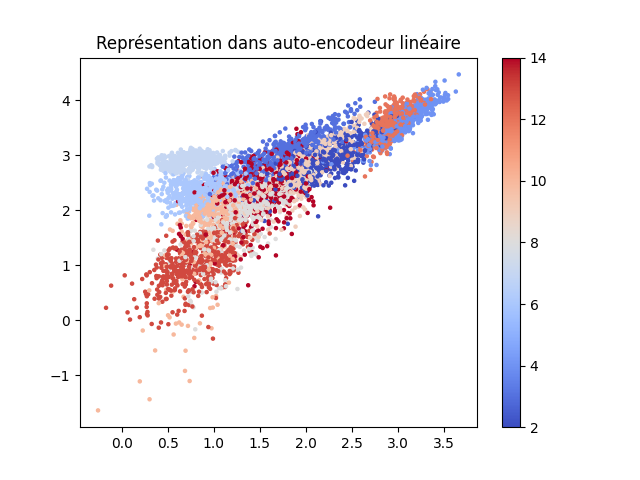
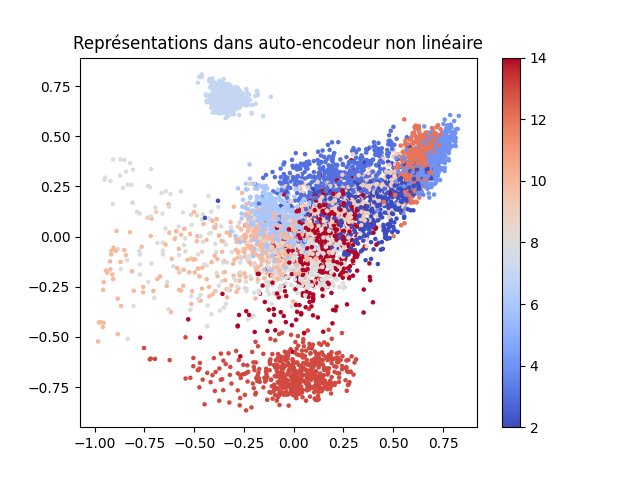
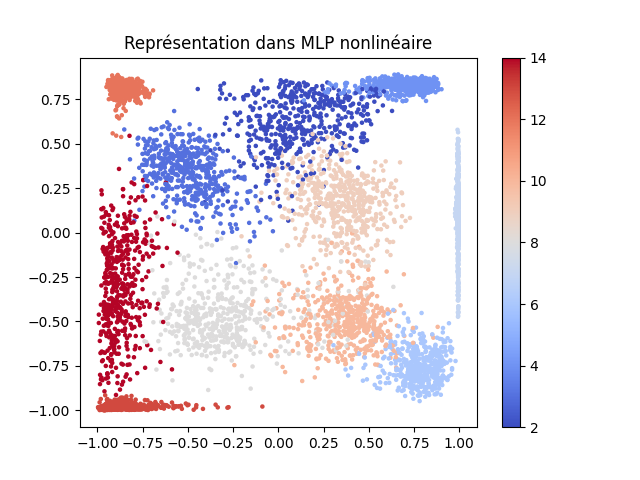
L’illustration suivante montre, sur les données Textures (11 couleurs différentes pour les 11 classes) que nous avons déjà employées dans ce cours, les codes obtenus pour les données de test ainsi que les erreurs de reconstruction (EQM pour erreur quadratique moyenne) sur ces données de test. Pour l’ACP la projection est faite sur les 2 premiers axes factoriels. Les codes correspondent aux activations des neurones de la couche cachée de 2 neurones pour le PMC linéaire a deux neurones dans l’unique couche cachée à activations idéntité, ainsi que pour le PMC non linéaire a 3 couches cachées 20-2-20 (dont l’encodeur et le décodeur ont chacun une couche cachée de 20 neurones).
ACP :
PMC linéaire :
PMC non linéaire 20-2-20 :
EQM test : 0.0088
EQM test : 0.0089
EQM test : 0.0072
Pour l’auto-encodeur PMC linéaire, le nuage des codes est lié par une transformation linéaire de rang maximal au nuage des codes de l’auto-encodeur ACP, alors que pour l’auto-encodeur PMC non linéaire on observe assez bien que la transformation est non linéaire, les dilatations sont plus fortes dans certaines parties de l’espace des codes. Nous pouvons constater également que l’erreur de reconstruction est plus faible pour l’auto-encodeur non linéaire que pour les auto-encodeurs linéaires.
Les « codes » obtenus par un auto-encodeur conservent l’information principale permettant de reconstruire approximativement les entrées correspondantes. Nous pouvons alors nous demander si le décodeur peut générer des données similaires aux données d’apprentissage à partir de vecteurs de l’espace des codes qui ne sont pas des codes appris.
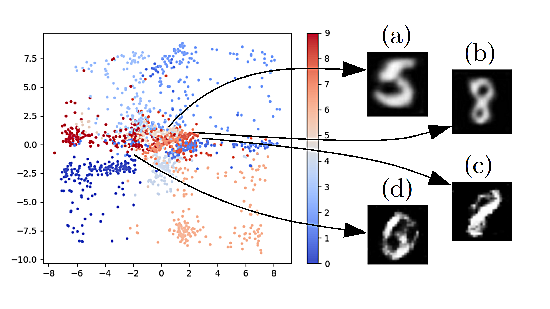
Considérons, par exemple, un ensemble de données qui représentent des images de chiffres manuscrits entre 0 et 9. Prenons un auto-encodeur composé d’un encodeur PMC et d’un décodeur PMC. L’encodeur a une couche cachée et une couche de sortie de 2 neurones, et projette l’image du chiffre présenté en entrée dans l’espace bidimensionnel. Le décodeur a aussi une couche cachée et cherche à reconstruire l’image du chiffre à partir de son code bidimensionnel. A supposer que l’apprentissage de cet auto-encodeur permet d’obtenir d’assez bonnes reconstructions des chiffres de l’échantillon d’apprentissage comme de ceux de l’échantillon de test, on peut se demander quelles sorties sont produites par le décodeur à partir d’autres vecteurs pris directement dans l’espace des codes, sans passer par la présentation d’un chiffre à l’entrée de l’encodeur. L’organisation des codes bidimensionnels correspondant aux données d’apprentissage est présentée dans la Fig. 173.
Fig. 173 Génération à partir de l’espace des codes, en utilisant le décodeur d’un auto-encodeur non linéaire¶
A partir des exemples montrés dans cette illustration nous pouvons constater que :
Pour des vecteurs très proches de projections d’entrées apprises, les sorties sont en général similaires aux reconstructions de ces entrées (cas a et b).
Pour d’autres vecteurs de l’espace des codes, les sorties peuvent être intermédiaires entre les entrées correspondant aux codes les plus proches (cas c : sortie intermédiaire entre 1 et 8), ou alors différentes de toutes les entrées (cas d).
Représentations internes développées pour la classification¶
Après avoir examiné les représentations internes développées dans un réseau de neurones pour résoudre un problème assez particulier, l’auto-encodage, regardons maintenant les représentations permettant de traiter un problème bien plus connu, la classification.
Nous avions déjà remarqué plus tôt que la couche de sortie d’un perceptron multi-couches (PMC) pouvait être vue comme un réseau de neurones sans couche cachée. Par conséquent, cette couche de sortie permet de réaliser des séparations linéaires entre les projections des classes sur la (dernière) couche cachée, comme illustré dans la figure suivante pour un problème de classification à trois classes.
Fig. 174 Séparation linéaire réalisée par la couche de sortie d’un PMC entre les représentations internes d’exemples issus de trois classes¶
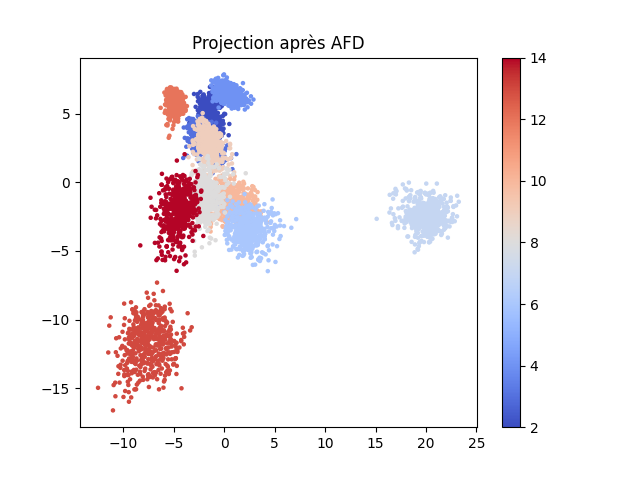
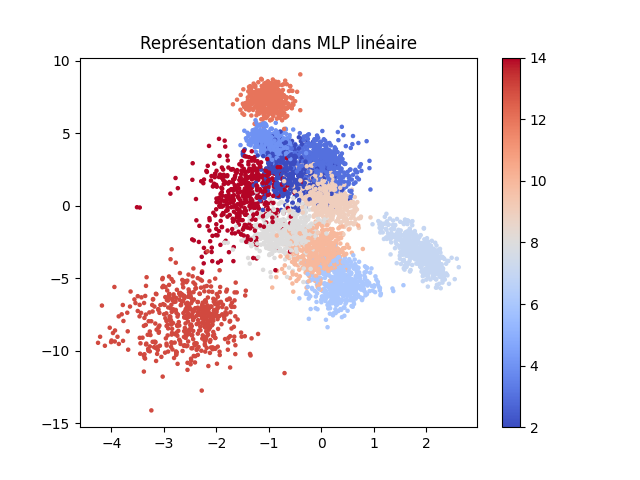
Pour que la couche de sortie puisse bien séparer linéairement les représentations d’exemples de classes différentes, il est donc nécessaire que dans la dernière couche cachée les représentations des données d’une même classe soient suffisamment bien regroupées entre elles et surtout séparées des représentations des données d’autres classes. Cet objectif rappelle celui de l’analyse factorielle discriminante (AFD) et d’ailleurs des résultats théoriques ont établi des liens entre les représentations internes développées par un PMC pour la classification et l’AFD.
Des résultats théoriques ont été obtenus dans les conditions suivantes :
Problème de classification avec codage one hot pour les sorties \(\mathbf{y}_i\).
Fonction d’activation identité pour la couche de sortie, donc \(\hat{\mathbf{y}}_i = \mathbf{W}_s \mathbf{h}_i\).
Erreur quadratique à minimiser (et non erreur softmax) : \(\|\hat{\mathbf{y}} - \mathbf{y}\|^2\).
Dans ces conditions, on s’intéresse aux représentations \(\mathbf{h}_i\) obtenues dans la dernière couche cachée d’un PMC. Considérons d’abord le cas d’un PMC linéaire, avec une couche cachée de \(k\) neurones et fonctions d’activation identité, le vecteur d’activation de cette couche cachée est alors \(\mathbf{h} = \mathbf{W}_1 \mathbf{x}\). Dans ce cas, le lien avec l’AFD linéaire est très fort :
L’erreur est minimisée lorsque la fonction de transfert entre l’entrée et la couche cachée du PMC est la projection orthogonale sur le sous-espace engendré par les vecteurs propres associés aux \(k\) plus grandes valeurs propres de l’AFD des observations d’apprentissage (voir [WL90], [GTBFS91]).
La représentation des données (ou observations) d’entrée sur la couche cachée correspond (à une transformation linéaire de rang maximal près) à la projection orthogonale sur ces \(k\) vecteurs propres.
Dans le cas général, où le PMC possède une ou plusieurs couches cachées avec des fonctions d’activation non linéaires, l’erreur d’apprentissage est minimisée lorsque les activations de la dernière couche cachée satisfont la relation \(\max \mathop{\mathrm{Tr}}\left(\mathbf{E}_H \mathbf{S}^+_H\right)\) (voir [WL90], [GTBFS91]). Ici \(\mathbf{E}_H\) est la matrice des covariances pondérées interclasse et \(\mathbf{S}^+_H\) l’inverse Moore-Penrose de la matrice des covariances totales des vecteurs d’activation de la couche cachée ; si \(\mathbf{S}^{-1}_H\) existe alors \(\mathbf{S}^+_H = \mathbf{S}^{-1}_H\). Ce critère est différent de celui de l’AFD linéaire classique mais reste un critère d’optimisation de la séparation entre classes.
Nous pouvons comparer, sur les données Textures (11 couleurs différentes pour les 11 classes), la projection des observations d’entrée obtenue par AFD linéaire sur les 2 premiers axes discriminants, la projection sur la couche cachée d’un PMC linéaire qui possède 1 couche cachée de 2 neurones, et la projection sur la couche cachée d’un PMC non linéaire qui possède 1 couche cachée de 2 neurones :
AFD :
PMC linéaire :
PMC non linéaire :
Score test : 0.82
Score test : 0.87
Score test : 0.93
Le score est ici le taux de bon classement, le taux le plus élevé indique donc les meilleures performances.
Nous pouvons constater que le PMC non linéaire cherche à améliorer la séparabilité linéaire des projections des données d’entrée sur la couche cachée, même au détriment de la compacité des classes. Par ailleurs, le résultat de la classification des données de test (mesuré par le taux de bon classement) est bien amélioré par le PMC non linéaire.
Nous constatons donc que les réseaux de neurones multi-couches présentent un grand potentiel d’approximation de fonctions. Pour exploiter ce potentiel il est néanmoins nécessaire de disposer de méthodes d’optimisation de fonctions non convexes et en général complexes à minimiser. La minimisation de ces fonctions emploie en général la méthode de descente de gradient, caractérisée par un paramétrage difficile, qui rend souvent nécessaires plusieurs essais dans le cas de problèmes complexes. Etant donné le grand potentiel d’approximation de fonctions des réseaux de neurones, l’emploi de (souvent plusieurs) méthodes de régularisation est indispensable pour obtenir une bonne généralisation. Enfin, nous pouvons voir certaines des représentations internes développées dans les PMC comme des améliorations non linéaires de celles obtenues par l’analyse factorielle.
Baldi, P. and K. Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural Networks, 2(1): 53–58, 1989.
Gallinari, P., S. Thiria, F. Badran, and F. Fogelman-Soulie. On the relations between discriminant analysis and multilayer perceptrons. Neural Networks, 4(3): 349–360, jun 1991.
Kingma, D. P. and J. Ba. Adam: A method for stochastic optimization. In Y. Bengio and Y. LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
Sutskever, I., J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ICML’13, page III–1139–III–1147. JMLR.org, 2013.
Webb, A. R. and D. Lowe. The optimised internal representation of multilayered classifier networks performs nonlinear discriminant analysis. Neural Networks, 3(4) :367–375, jul 1990.
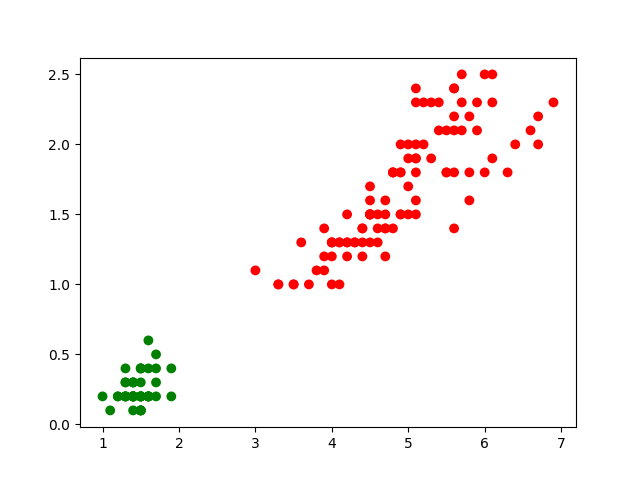
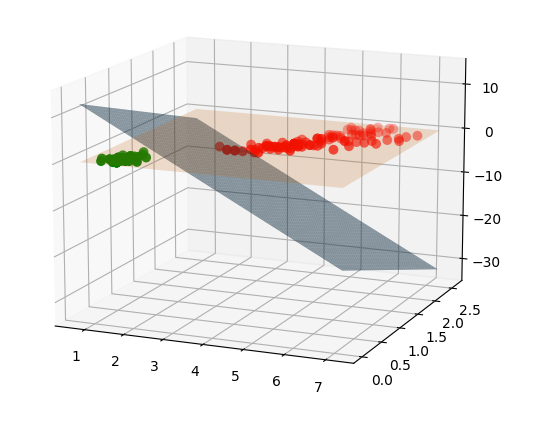
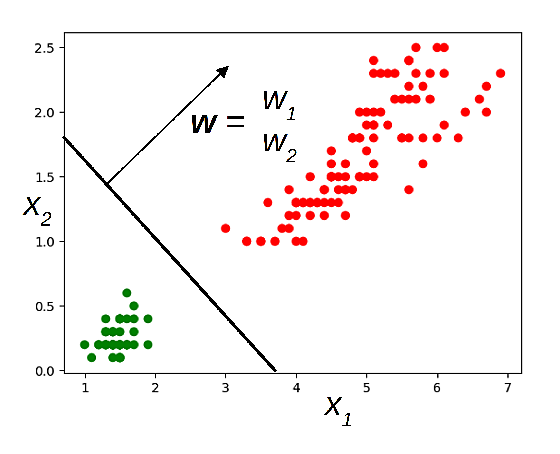
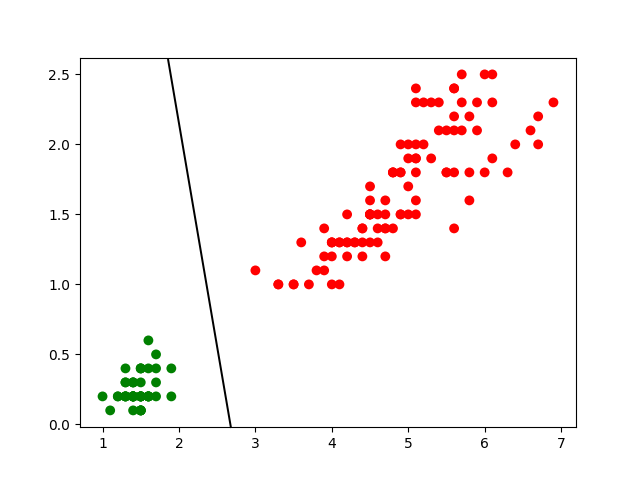
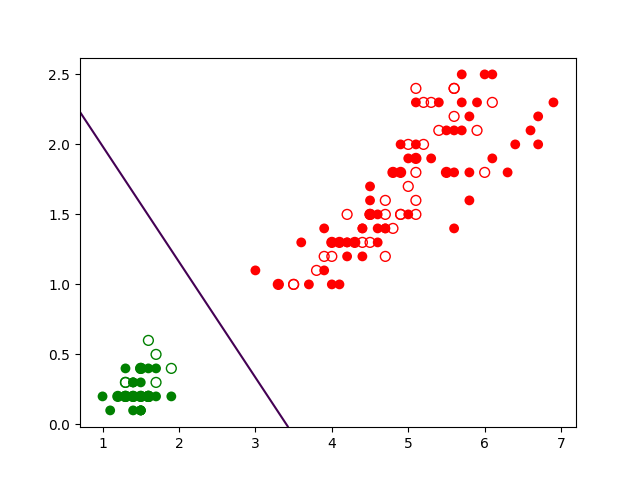
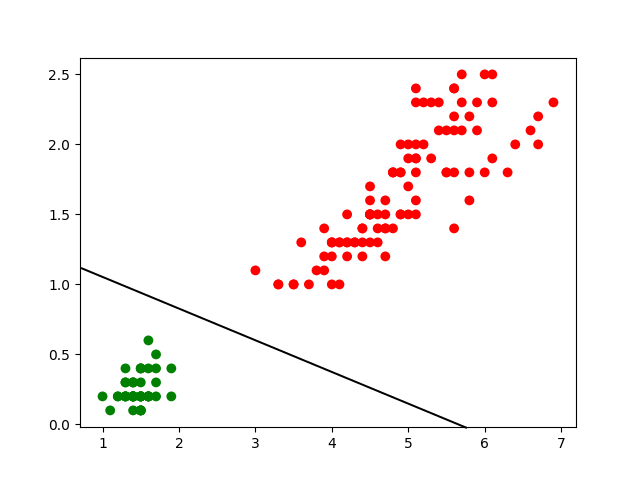
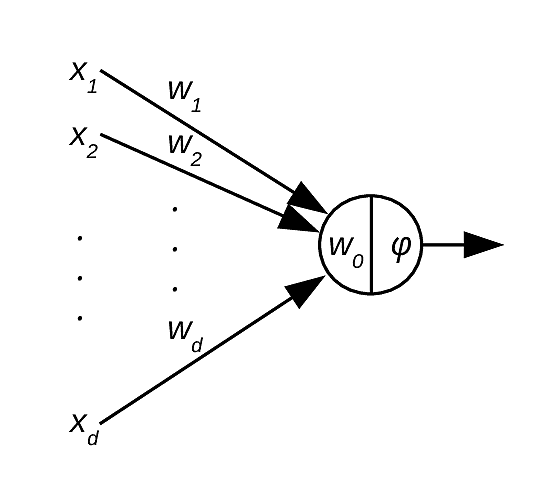
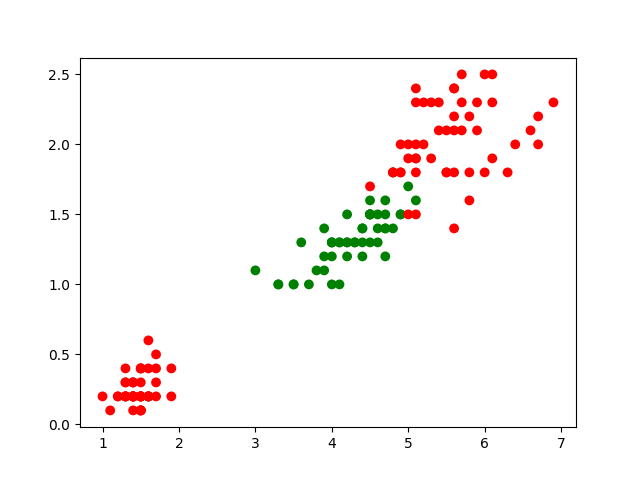
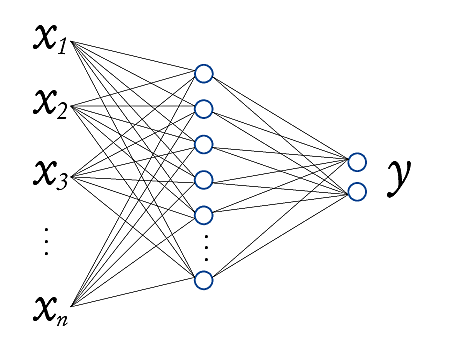
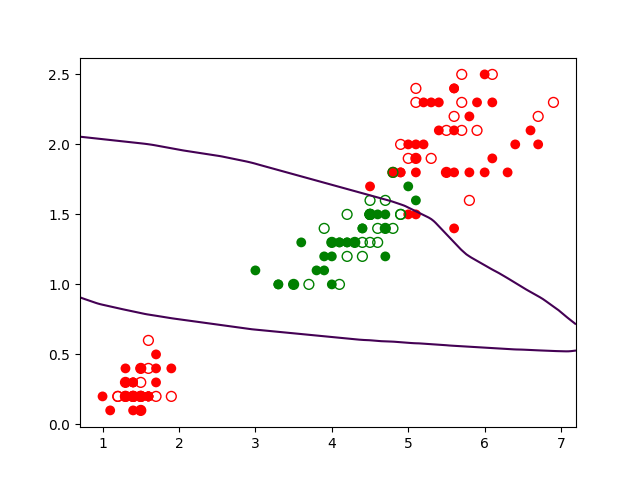
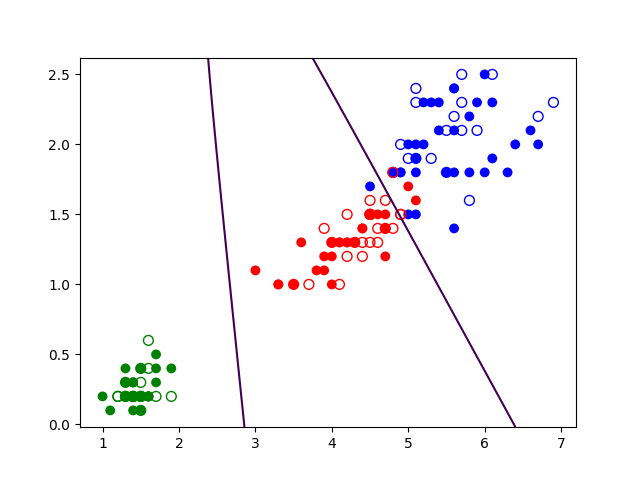
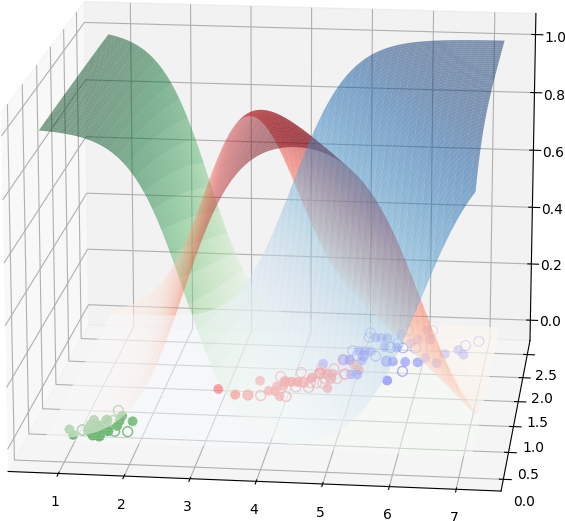
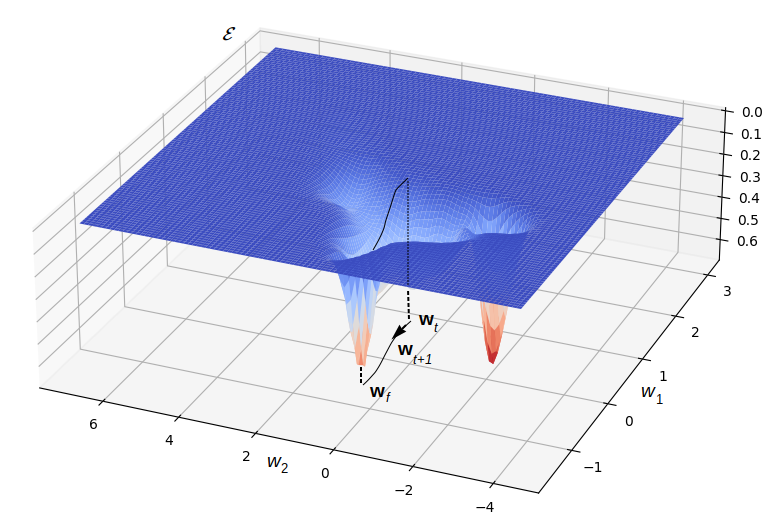
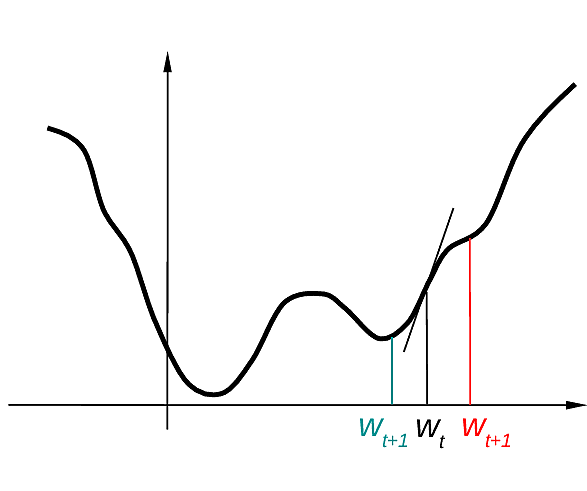
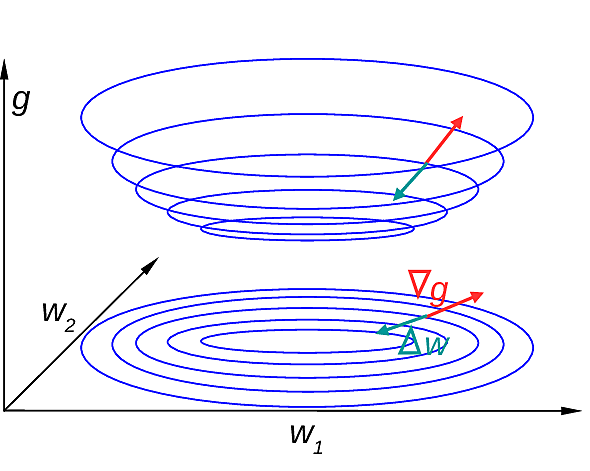
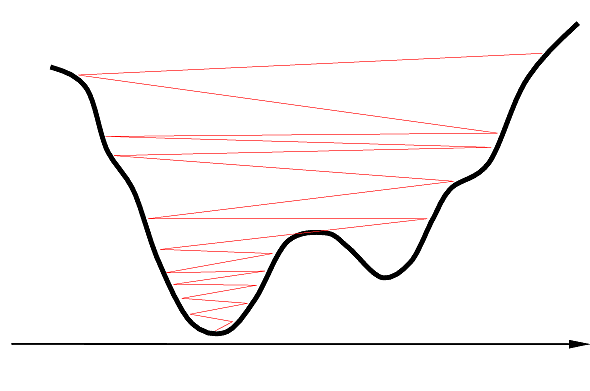
![Coût à minimiser - cas réel (illustration issue de [Ulm21]_)](_images/Visualized-loss-surfaces-of-two-deep-neural-networks-The-altitude-of-the-surfaces.png)