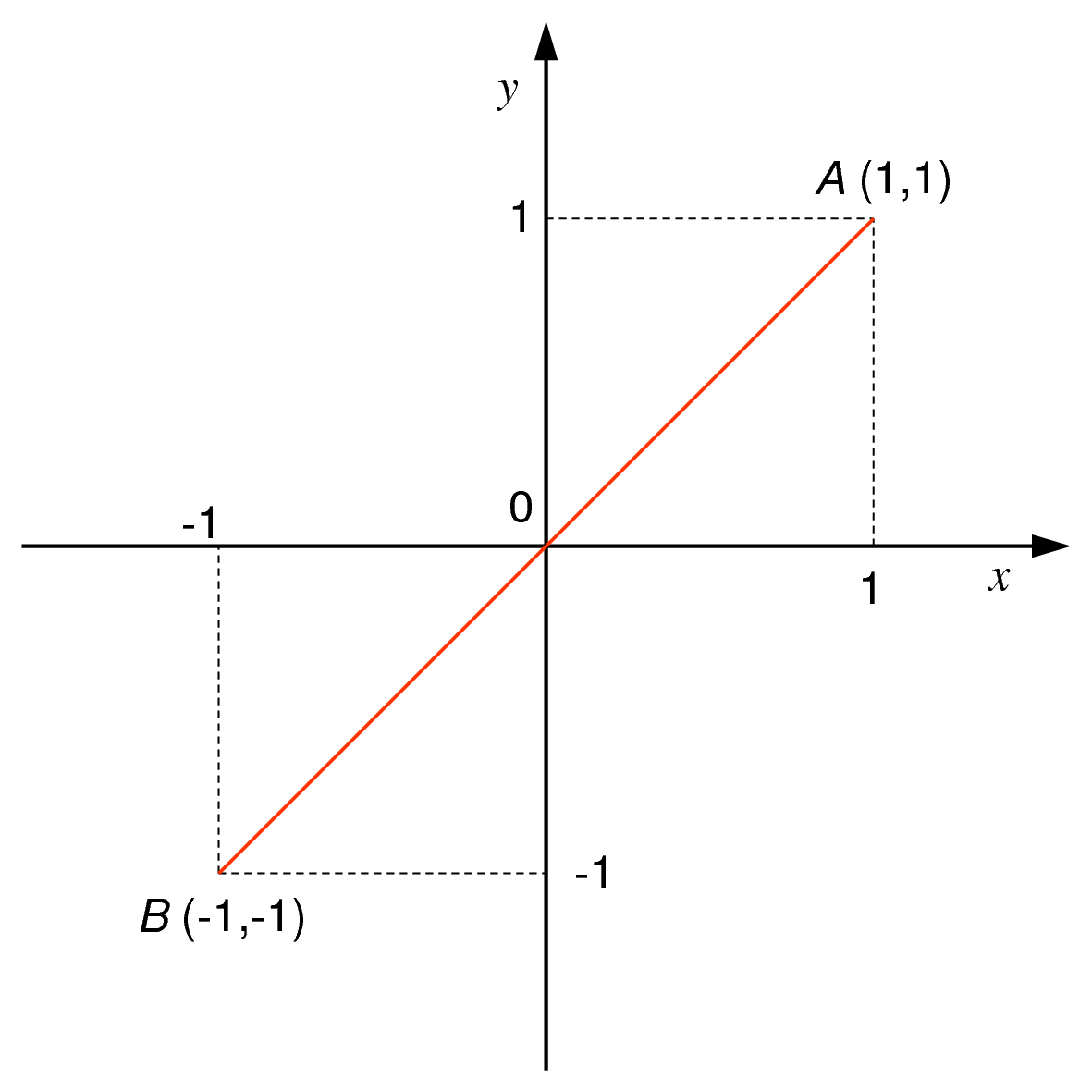Les observations à modéliser sont souvent décrites par de nombreuses variables de nature diverse. Certaines de ces variables peuvent être redondantes, c’est à dire fournir la même information prédictive (ou presque), et cela peut avoir un impact négatif sur certaines méthodes de modélisation décisionnelle. Aussi, d’autres variables n’apportent aucune information prédictive et leur prise en compte peut ainsi agir comme du « bruit » dans le processus de modélisation prédictive. Comment examiner les caractéristiques des variables et surtout les relations entre ces variables ? Les méthodes d`analyse factorielle sont des outils très pertinents dans la mise en évidence des relations entre variables et, plus généralement, dans la compréhension des données à modéliser.
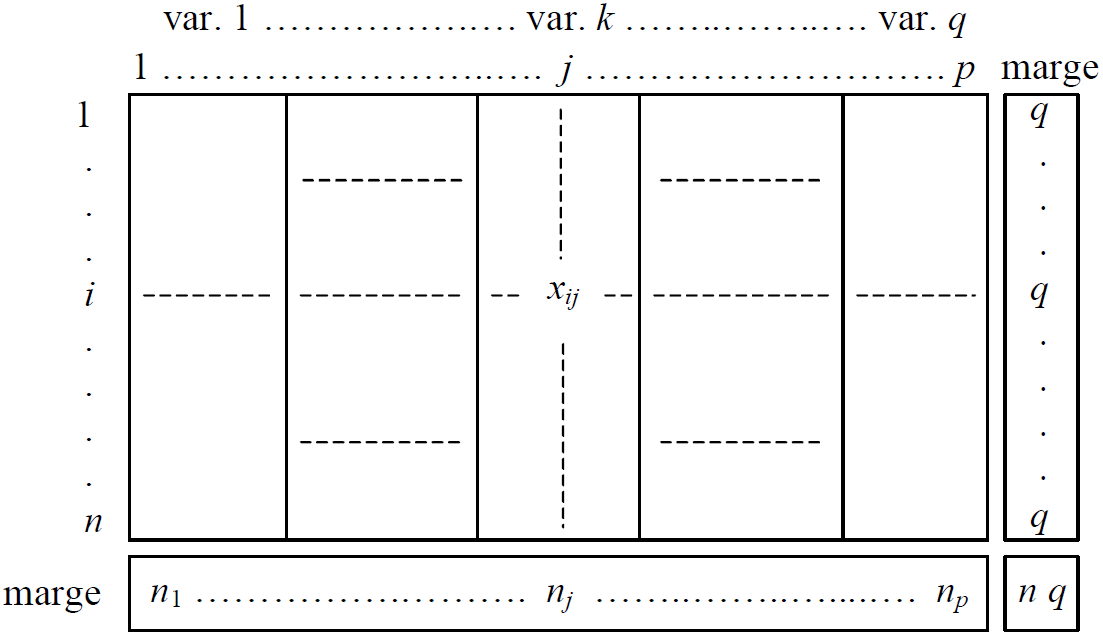
Considérons \(n\) observations décrites par \(d\) variables, représentées dans un tableau comme celui qui suit :
Observation
\(X_1\)
\(X_2\)
…
\(X_d\)
\(o_1\)
…
…
…
…
\(o_2\)
…
…
…
…
…
…
…
…
…
\(o_n\)
…
…
…
…
On parle souvent de matrice des données brutes, notée \(\mathbf{R}\).
L’objectif général des méthodes d’analyse factorielle est la recherche de facteurs permettant de résumer les données ou leurs caractéristiques. Les facteurs sont des variables dérivées des \(d\) variables initiales, en général en nombre bien plus faible \(k \ll d\).
Ces méthodes visent à réduire la dimension des données (le nombre de variables) en conservant au mieux l’information utile. Cela passe par le choix d’un sous-espace de description plus pertinent par rapport à un critère qui caractérise la méthode, comme la réduction de la redondance entre variables ou l’amélioration de la séparation entre classes d’observations.
Les méthodes d’analyse factorielle contribuent également à améliorer la lisibilité des données, en mettant en évidence des relations entre variables ou entre groupes de variables, ainsi qu’en permettant de visualiser les relations entre données ou entre variables projetées dans l’espace de faible dimension des facteurs les plus significatifs.
Dans la pratique, les méthodes d’analyse factorielles sont utilisées essentiellement dans un but d’exploration et de description des données. Une caractéristique utile importante et générale de ces méthodes (qualifiées parfois de « géométriques ») est l’absence d’hypothèses préalables concernant les données.
Nous présenterons dans ces deux séances de cours trois méthodes factorielles linéaires :
L’analyse en composantes principales (ACP), méthode à caractère exploratoire, adaptée à des observations décrites par des variables quantitatives.
L’analyse des correspondances binaires (AFCB) ou multiples (ACM), méthode à caractère exploratoire, adaptée à des observations décrites par des variables nominales (à modalités).
L’analyse factorielle discriminante (AFD), méthode à caractère exploratoire et décisionnel, adaptée à des observations décrites par des variables quantitatives et appartenant à plusieurs classes.
Les travaux pratiques associés abordent actuellement l’ACP et l’AFD. Des développements et détails complémentaires concernant ces méthodes classiques peuvent être trouvés dans des sources externes (par ex. [Sap11], [CABB04]).
Ces observations sont décrites par plusieurs variables (14 dans l’étude [1]). Parmi les questions intéressantes, permettant de mieux comprendre ces données, nous pouvons mentionner
Y a-t-il des groupes de variables redondantes ?
Y a-t-il des facteurs (caractéristiques), dérivés des variables initiales, dont la variation décrit mieux les différences entre observations ?
Examinons d’abord un cas simple, le lien entre deux variables décrivant les feuilles :
Elongation : \(1 - \frac{d_{\max}}{D}\), où \(d_{\max}\) est diamètre du plus grand cercle inscrit dans la feuille et \(D\) est le diamètre (extérieur) de la feuille.
Isoperimetric factor : rapport entre l’aire (multipliée par une constante) de la feuille et le carré du périmètre.
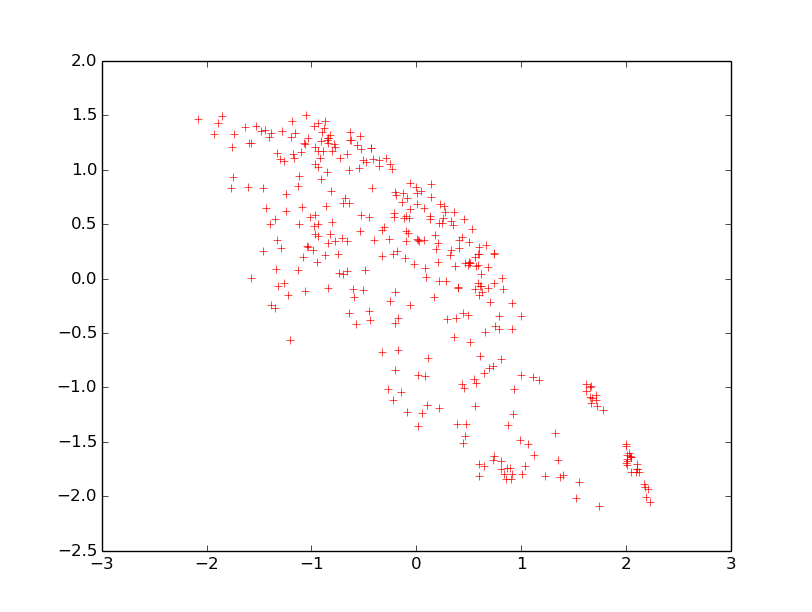
Fig. 27 présente les 340 observations dans le plan de ces 2 variables normalisées (chacune est de moyenne nulle, le centre de gravité du nuage est donc dans l’origine des axes, et d’écart-type égal à 1).
Fig. 27 Représentation des observations dans le plan des 2 variables: elongation (en abscisse) et isoperimetric factor (en ordonnée)¶
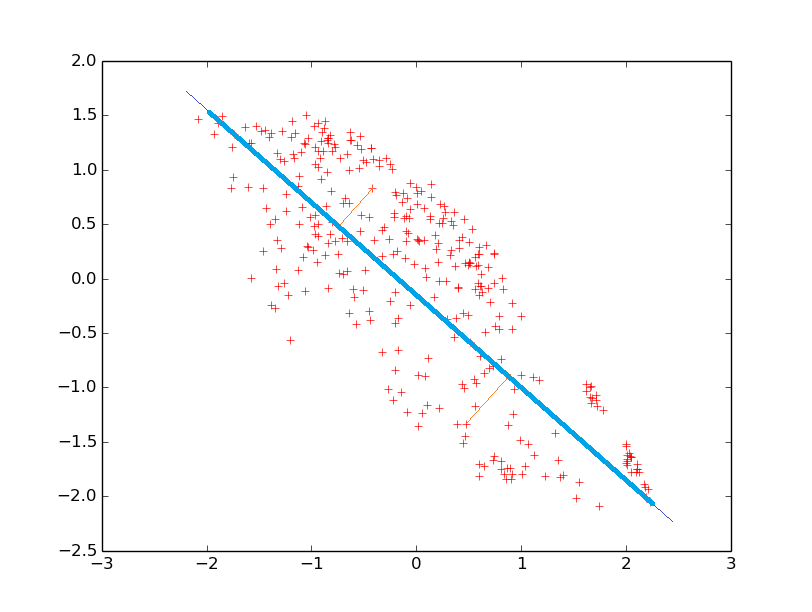
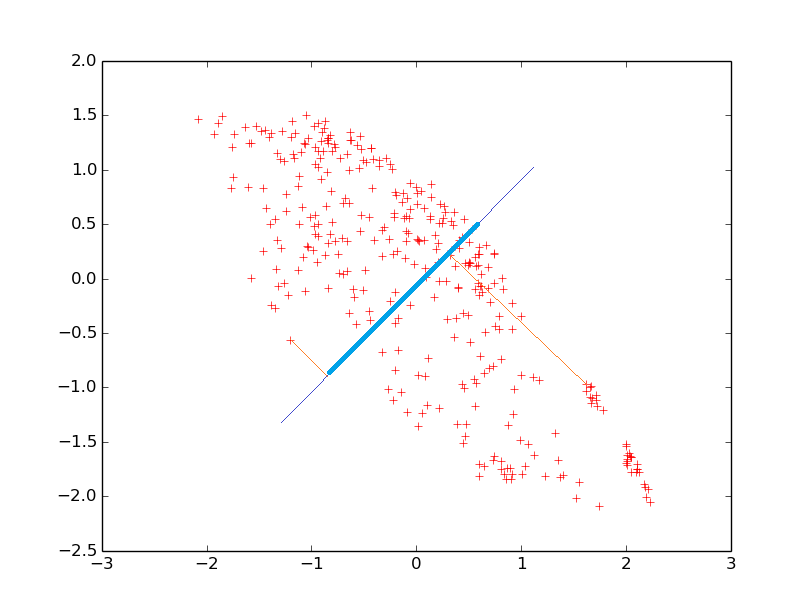
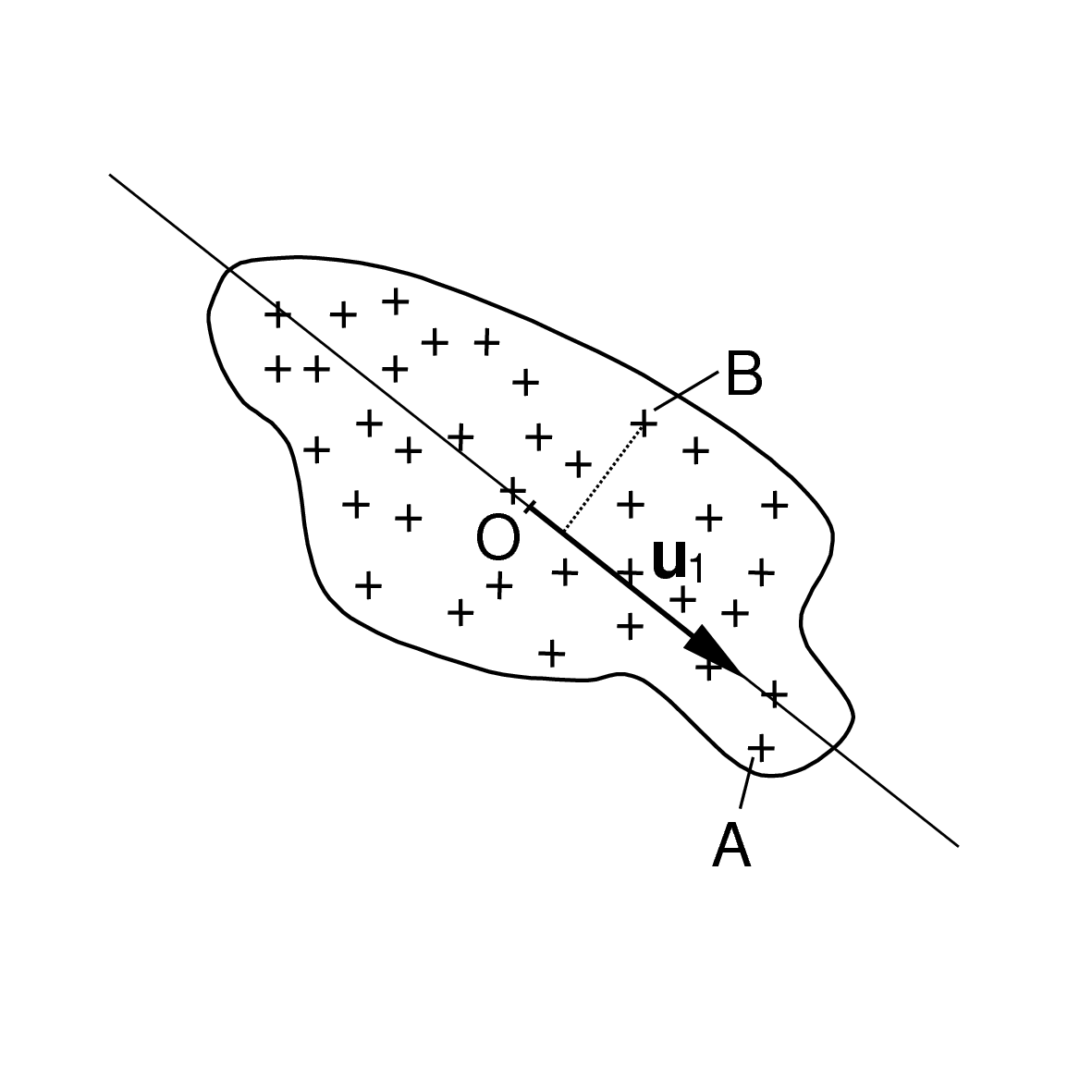
Dans quelle mesure pouvons-nous résumer par une seule variable dérivée l’information qu’apportent ces deux variables initiales ? Dans la Fig. 27 considérons une droite qui tourne autour du centre de gravité du nuage (qui est dans l’origine des axes) et les projections orthogonales des données sur cette droite. Y a-t-il une orientation pour laquelle la variance des projections sur la droite est nettement plus élevée que pour les autres orientations ? Les deux illustrations suivantes (Fig. 28) montrent deux orientations particulières de la droite :
Fig. 28 Pour quelle orientation de la droite (en bleu foncé) la variance des projections (en bleu clair) sur la droite est la plus élevée ?¶
Nous pouvons constater que l’orientation illustrée par la première figure permet de maximiser la variance des projections. La droite qui a cette orientation correspond ainsi à la composante principale de ce nuage d’observations. Il est important de noter aussi que c’est pour cette même droite que l’écart entre les données et leurs projections sur la droite est le plus faible. Les projections sur cette droite constituent ainsi la meilleure approximation unidimensionnelle du nuage bidimensionnel. Dans la mesure où les observations sont relativement proches de cette droite, la nouvelle variable que représente la droite « résume » assez bien l’information qu’apportent les variables initiales elongation et isoperimetric factor.
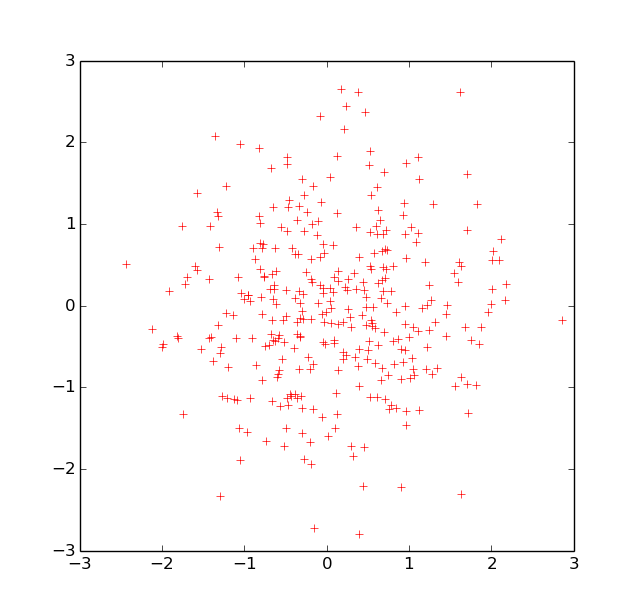
Pouvons-nous toujours résumer, même de façon imparfaite, deux variables par une seule ? Non, comme le montre l’exemple illustré dans la Fig. 29. Ici, le nuage d’observations n’a de « dispersion » plus forte dans aucune direction particulière, donc aucune direction (aucune variable unidimensionnelle dérivée des variables initiales, l’abscisse et l’ordonnée) ne peut résumer convenablement l’information apportée par les deux variables initiales.
Fig. 29 Pour un nuage d’observations de forme sphérique, aucune direction de projection ne peut être privilégiée¶
Comment trouver les composantes principales ? Avant d’examiner le cas général, l’exemple suivant présente un cas élémentaire pour lequel il est possible de suivre de près les calculs. Nous restons à deux variables initiales (l’abscisse et l’ordonnée dans le plan de l’écran) et limitons à deux le nombre d’observations, données par le tableau suivant (voir aussi la Fig. 30) :
(1)¶\[\begin{split}\begin{array}{c|c|c} & X & Y\\ \hline A & 1 & 1\\ B & -1 & -1 \end{array}\end{split}\]
Fig. 30 Exemple élémentaire : nuage de 2 observations¶
Les observations représentées comme des vecteurs colonne sont donc \(A = \left(\begin{array}{c}1\\1\end{array}\right)\) et \(B = \left(\begin{array}{c}-1\\-1\end{array}\right)\).
Nous pouvons constater que les deux variables initiales sont chacune de moyenne nulle car \(1 + (-1) = 0\). Le centre de gravité du nuage des observations est alors \(\mathbf{g} = \frac{A + B}{2}\), donc \(\mathbf{g} = \left(\begin{array}{c}0\\0\end{array}\right)\).
Les deux variables initiales présentent chacune une variance égale à 1 car \(\frac{(1 - 0)^2 + (-1 - 0)^2}{2} = 1\).
Dans la matrice des covariances empiriques, notée par \(\mathbf{S}\), les variances se trouvent sur la diagonale principale et les covariances en dehors de la diagonale principale. On parle de covariances « empiriques » car elles sont calculées à partir des observations. Ici, la covariance entre les deux seules variables initiales est \(\frac{(1 - 0)(1 - 0) + (-1 - 0)(-1 - 0)}{2} = 1\) ; sur les deux observations les variables co-varient parfaitement car elles prennent la même valeur pour chaque observation. Covariance et corrélation sont identiques dans cet exemple car les variances des deux variables sont égales à 1. La matrice des covariances empiriques est alors \(\mathbf{S} = \left(\begin{array}{c c}1&1\\1&1\end{array}\right)\).
Nous pouvons maintenant chercher la droite de projection (la variable dérivée) pour laquelle la variance des projections est la plus forte, c’est à dire le premier axe principal. On peut montrer que la variance des projections des observations sur une droite de direction définie par le vecteur colonne unitaire (de norme égale à 1) \(\mathbf{u}\) est alors \(\mathbf{u}^T \mathbf{S} \mathbf{u}\), où \(^T\) est l’opération de transposition.
L`axe principal est la direction qui correspond au vecteur \(\mathbf{u}\) pour lequel la variance des projections sur ce vecteur, \(\lambda = \mathbf{u}^T \mathbf{S} \mathbf{u}\), est maximale. Nous sommes en présence d’un problème de maximisation sous contraintes d’égalité : trouver \(\mathbf{u}\) qui maximise \(\mathbf{u}^T \mathbf{S} \mathbf{u}\) sous la contrainte \(|\mathbf{u}| = 1\) (ici \(|\cdot| = 1\) désigne la norme). La méthode des multiplicateurs de Lagrange (voir par ex. cette présentation vidéo et les transparents associés) permet de montrer que le vecteur \(\mathbf{u}\) est une solution de l’équation des valeurs et vecteurs propres \(\mathbf{S} \mathbf{u} = \lambda \mathbf{u}\), et plus précisément le vecteur propre\(\mathbf{u}\) associé à la plus grande valeur propre\(\lambda\).
Pour obtenir la solution il faut résoudre \(\det(\mathbf{S} - \lambda \mathbf{I}) = 0\) afin de déterminer \(\lambda\) et ensuite \(\mathbf{S} \mathbf{u} = \lambda \mathbf{u}\) pour déterminer \(\mathbf{u}\). Ici \(\mathbf{I}\) est la matrice identité d’ordre 2, c’est à dire la matrice \(2 \times 2\) qui a des 1 sur la diagonale principale et des 0 en dehors.
L’équation \(\det(\mathbf{S} - \lambda \mathbf{I}) = 0\) devient \((1 - \lambda)(1 - \lambda) - 1 = 0\), donc \(\lambda (\lambda - 2) = 0\), et les solutions sont \(\lambda_1 = 2\) et \(\lambda_2 = 0\), \(\lambda_1 > \lambda_2\).
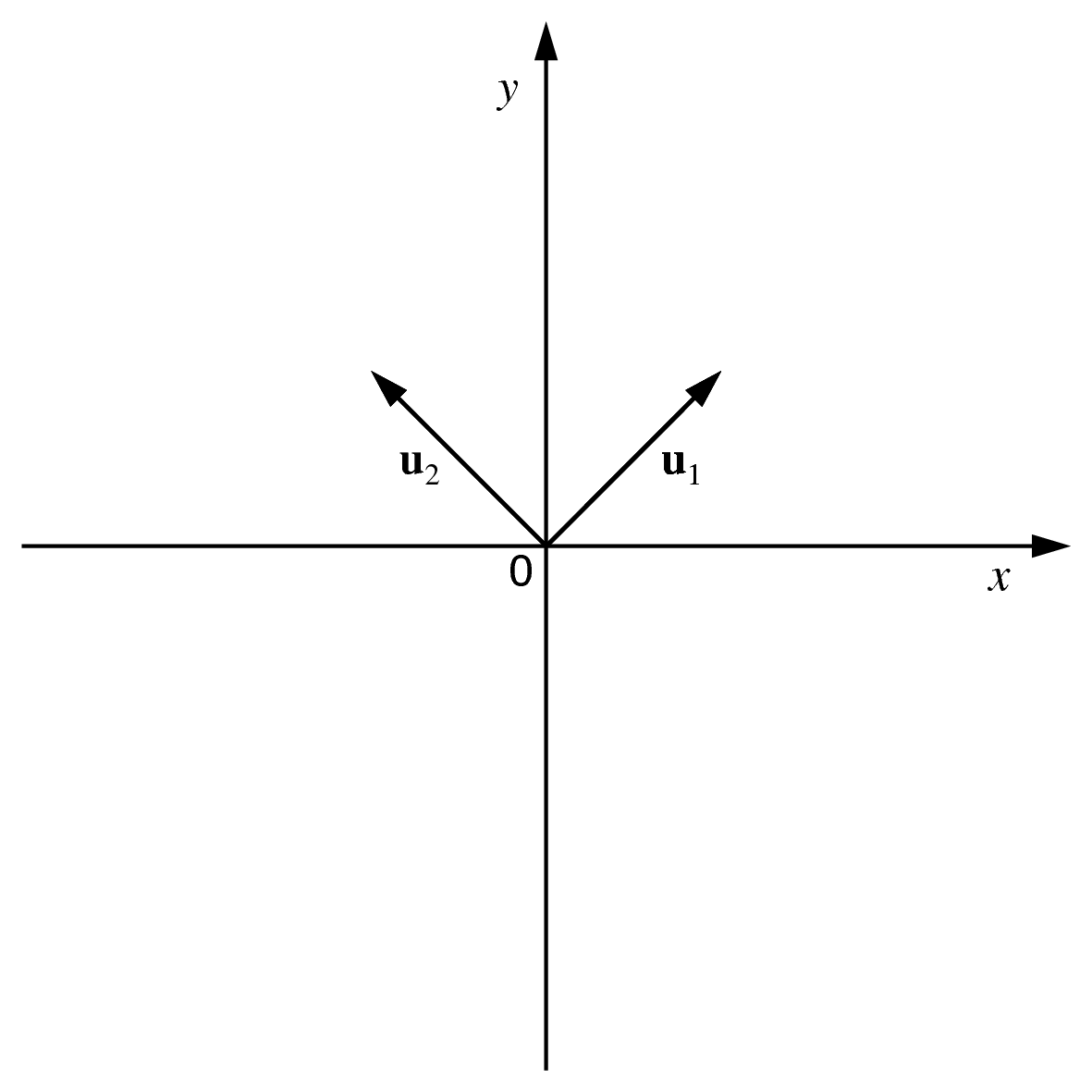
Les vecteurs propres unitaires associés sont \(\mathbf{u}_1 = \left(\begin{array}{c}\sqrt{2}/2\\\sqrt{2}/2\end{array}\right)\) pour \(\lambda_1 = 2\) et \(\mathbf{u}_2 = \left(\begin{array}{c}-\sqrt{2}/2\\\sqrt{2}/2\end{array}\right)\) pour \(\lambda_2 = 0\). Rappelons qu’un vecteur propre est défini à une constante multiplicative près, car si \(\mathbf{S} \mathbf{u} = \lambda \mathbf{u}\) alors le vecteur \(c \mathbf{u}\) satisfait également cette équation (\(c \in \mathbb{R}\) est la constante multiplicative) pour la même valeur propre que \(\mathbf{u}\). En particulier, \(- \mathbf{u}_1\) (le vecteur de sens opposé à \(\mathbf{u}_1\)) est unitaire et satisfait aussi l’équation pour la même valeur propre \(\lambda_1\).
Fig. 31 Exemple élémentaire : vecteurs propres de la matrice de covariances empiriques¶
L’axe principal est donc donné dans cet exemple élémentaire par le vecteur \(\mathbf{u}_1\). La variance des projections des observations sur \(\mathbf{u}_1\) est \(\mathbf{u}_1^T \mathbf{S} \mathbf{u}_1 = \lambda_1\).
Analyse en composantes principales : données, objectifs¶
Introduite par Hotelling en 1933 suivant des idées avancées par Pearson dès 1901, l’ACP est une méthode d’analyse exploratoire des données : à partir d’un ensemble de \(n\) observations caractérisées par \(d\) variables quantitatives initiales, on cherche à « condenser » la représentation des données en conservant au mieux leur organisation globale. Pour cela, on représente les données sur \(k\) nouvelles variables (les composantes principales, \(k < d\)) obtenues comme des combinaisons linéaires des variables initiales, en conservant le plus de variance possible.
L’ACP est principalement utilisée pour :
Condenser les données en conservant au mieux leur organisation globale.
Visualiser en faible dimension l’organisation prépondérante des données.
Interpréter les corrélations ou anti-corrélations entre multiples variables.
Interpréter les projections des prototypes de classes d’observations par rapport aux variables.
Éventuellement préparer des analyses ultérieures en éliminant les sous-espaces dans lesquels la variance des données est très faible (assimilés, parfois à tort, à des sous-espaces de bruit, sans information utile).
Nous pouvons distinguer trois variantes de l’analyse en composantes principales :
L`ACP générale, dans laquelle la recherche des directions de variance maximale est faite sans transformer les données. On travaille donc directement sur la matrice des données brutes, \(\mathbf{X} = \mathbf{R}\). Dans ce cas, interviennent dans l’analyse à la fois la position du nuage d’observations par rapport à l’origine et la forme du nuage, comme indiqué dans la Fig. 32. Cette variante est utilisée très rarement, essentiellement pour tenir compte du zéro naturel de certaines variables.
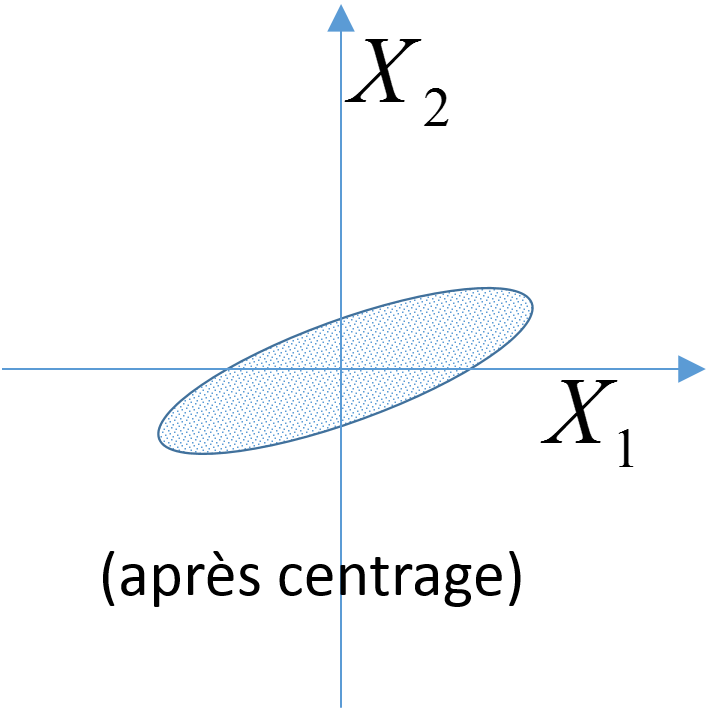
L`ACP centrée, dans laquelle les variables sont d’abord « centrées », c’est à dire la moyenne de chaque variable est soustraite pour chaque observation de la valeur de cette variable. La matrice analysée, \(\mathbf{X}\), est obtenue en transformant la matrice de données brutes \(\mathbf{R}\) pour que chaque variable (chaque colonne) soit de moyenne nulle. Cela revient à s’intéresser à la forme du nuage d’individus par rapport à son centre de gravité, voir la Fig. 33. Cette variante est utilisée lorsque les variables initiales sont directement comparables (de même nature, intervalles de variation comparables).
L`ACP normée, dans laquelle les variables sont à la fois « centrées » et « réduites ». La réduction (après centrage) consiste à diviser pour chaque observation la valeur de cette variable par son écart-type. La matrice analysée, \(\mathbf{X}\), est obtenue donc en transformant \(\mathbf{R}\) pour que chaque variable (chaque colonne) soit de moyenne nulle et d’écart-type unitaire. On s’intéresse donc à la forme du nuage d’individus après centrage et réduction des variables, voir la Fig. 34. Cette variante, la plus fréquemment rencontrée, est employée lorsque les variables quantitatives sont de nature différente (par ex. distances, poids, durées, etc.) ou présentent des intervalles de variation très différents.
Nous illustrons les résultats de l’application de l’ACP sur un exemple qui concerne le sommeil des mammifères, issu de [3], où chaque observation correspond à un représentant typique d’une des 62 espèce de mammifères et est décrite par plusieurs variables. Il y a au total \(n = 62\) espèces différentes (donc 62 observations) décrites par les \(d = 10\) variables initiales pour lesquelles nous avons indiqué les noms, les moyennes et les écart-types dans le tableau suivant :
Les lignes de la matrice des données brutes \(\mathbf{R}\) décrivent les observations dans l’espace des variables initiales, les colonnes de \(\mathbf{R}\) décrivent les variables dans « l’espace » des observations. Deux analyses sont donc possibles, celle du nuage des observations et celle du nuage des variables.
L’analyse du nuage des observations. Nous nous intéressons aux lignes de la matrice de données et cherchons \(k\) nouvelles variables (linéairement indépendantes entre elles) obtenues comme des combinaisons linéaires des variables initiales (c’est à dire, un sous-espace linéaire de dimension \(k\) de l’espace initial) telles que la projection des observations sur ces variables conserve le plus de variance (ou « dispersion »).
Pour \(k = 1\), comme nous l’avons vu plus haut, l’axe principal est la direction qui correspond au vecteur \(\mathbf{u}\) pour lequel la variance des projections sur ce vecteur, \(\lambda = \mathbf{u}^T \mathbf{S} \mathbf{u}\), est maximale. Le vecteur \(\mathbf{u}\) recherché est le vecteur propre \(\mathbf{u}\) associé à la plus grande valeur propre \(\lambda\) de l’équation des valeurs et vecteurs propres \(\mathbf{S} \mathbf{u} = \lambda \mathbf{u}\).
Plus généralement, pour \(k \geq 1\) il est facile de montrer (voir par ex. [CABB04], [Sap11]) que le sous-espace de dimension \(k\) recherché est généré par les \(k\) vecteurs propres \(\mathbf{u}_{\alpha}\) associés aux \(k\) plus grandes valeurs propres \(\lambda_{\alpha}\) de la matrice \(\mathbf{X}^T \mathbf{X}\). Ces valeurs et vecteurs propres sont obtenus comme solutions de l’équation des valeurs et vecteurs propres \(\mathbf{X}^T \mathbf{X} \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{u}_{\alpha}\), \(\alpha \in \{1,\ldots,k\}\). Les vecteurs \(\mathbf{u}\) sont en général choisis de norme égale à 1 car cela facilite le calcul des projections des observations sur les axes.
Les valeurs propres non nulles sont souvent exprimées sous la forme de pourcentages d’inertie ; il suffit pour cela de diviser chaque valeur propre par la somme des valeurs propres (et de multiplier ensuite par 100).
La matrice analysée \(\mathbf{X}\) est :
Pour l’ACP générale, la matrice des données brutes \(\mathbf{X} = \mathbf{R}\).
Pour l’ACP centrée, la matrice des données centrées (de chaque variable on retire sa moyenne empirique), donc \(\mathbf{X}^T \mathbf{X}\) est la matrice des covariances empiriques.
Pour l’ACP normée, la matrice des données après centrage et réduction des variables (on divise chaque variable centrée par son écart-type), donc \(\mathbf{X}^T \mathbf{X}\) est la matrice des corrélations empiriques.
Pour l’exemple qui concerne le sommeil des mammifères, les variables de départ étant de nature diverse (poids, durées, indices), l’ACP normée (variables centrées et réduites) a été employée. Les variables initiales sont donc d’abord centrées et réduites avant l’analyse pour avoir chacune une moyenne nulle et une variance égale à 1.
La projection orthogonale d’une observation \(\mathbf{o}_i\) sur l’axe factoriel \(\alpha\) peut être obtenue facilement comme le produit scalaire entre le vecteur \(\mathbf{x}_i\) qui représente l’observation et le vecteur unitaire \(\mathbf{u}_{\alpha}\) qui définit cet axe :
Nous pouvons observer que la matrice \(\mathbf{X}^T \mathbf{X}\) est symétrique et il est possible de montrer qu’elle est également (semi-)définie positive. Toutes ses valeurs propres sont donc réelles et positives, à l’exception de celles qui sont nulles si la matrice est semi-définie. Cela implique également que les vecteurs propres associés à des valeurs propres différentes sont orthogonaux, en conséquence les axes principaux sont orthogonaux.
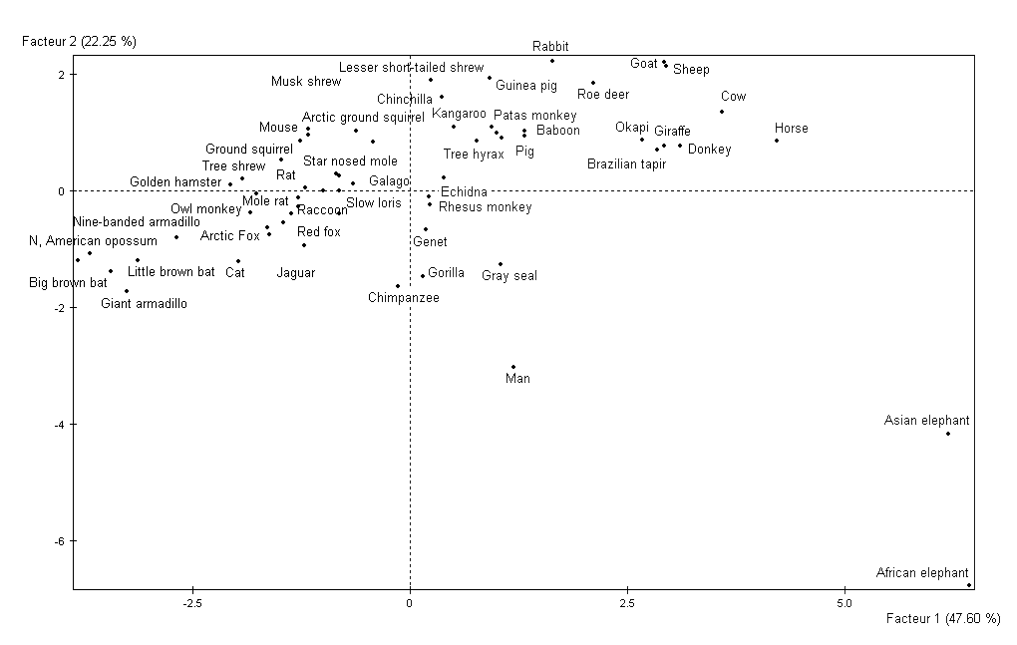
La Fig. 35 montre la projection du nuage des observations sur les deux premiers axes principaux pour l’exemple qui concerne le sommeil des mammifères. Tous les noms d’espèces ne sont pas représentés pour ne pas surcharger l’illustration.
Fig. 35 Sommeil des mammifères : projection du nuage des observations sur les deux premiers axes principaux¶
Ici \(\lambda_1 = 47,6\%\) et \(\lambda_2 = 22,25\%\). Le premier facteur (le premier axe principal) explique donc 47,6% de l’inertie totale du nuage d’observations, deux fois plus que le deuxième axe qui explique seulement 22,25%.
En examinant la Fig. 35 nous pouvons constater d’abord deux observations très atypiques, correspondant aux éléphants. Ces observations atypiques présentent d’ailleurs un fort impact sur l’analyse, comme nous le verrons dans ACP : aides à l’interprétation, et une nouvelle analyse peut éventuellement être réalisée après élimination de ces observations afin de « mieux laisser s’exprimer » les autres observations. Nous pouvons également observer que les projections d’espèces qui présentent des caractéristiques physiques et d’habitat similaires sont naturellement similaires, par ex. « chèvre » (goat) et « mouton » (sheep). Nous reviendrons à l’interprétation des projections des observations après avoir examiné la projection des variables et les relations de transitions entre analyses.
L’analyse du nuage des variables se déroule de façon symétrique. Dans ce cas nous souhaitons examiner les colonnes de la matrice de données \(\mathbf{X}\), ce qui revient à s’intéresser aux lignes de la matrice de données transposée \(\mathbf{X}^T\). Le sous-espace de dimension \(k\) recherché est généré par les \(k\) vecteurs propres \(\mathbf{v}_{\alpha}\) associés aux \(k\) plus grandes valeurs propres \(\mu_{\alpha}\) de la matrice \(\mathbf{X} \mathbf{X}^T\). Ces valeurs et vecteurs propres sont obtenus comme solutions de l’équation des valeurs et vecteurs propres \(\mathbf{X} \mathbf{X}^T \mathbf{v}_{\alpha} = \mu_{\alpha} \mathbf{v}_{\alpha}\), \(\alpha \in \{1,\ldots,k\}\). Les vecteurs \(\mathbf{v}\) sont également choisis de norme égale à 1.
La projection orthogonale d’une variable \(\mathbf{X}_j\) sur l’axe factoriel \(\alpha\) peut être obtenue facilement comme le produit scalaire entre le vecteur \(\mathbf{X}_j\) qui représente la variable (la colonne \(j\) de la matrice \(\mathbf{X}\)) et le vecteur unitaire \(\mathbf{v}_{\alpha}\) qui définit cet axe :
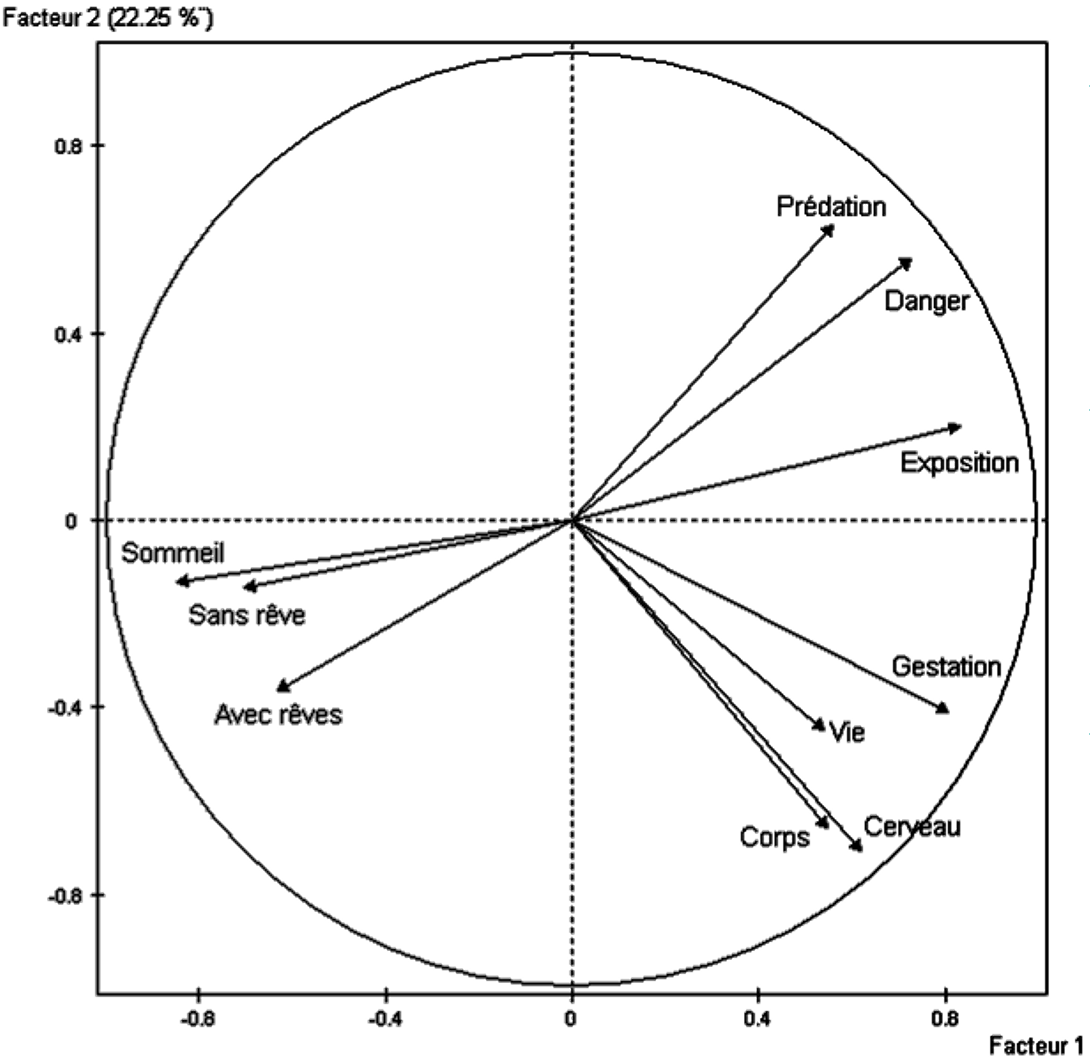
La Fig. 36 montre la projection du nuage des variables sur les deux premiers axes principaux pour l’exemple qui concerne le sommeil des mammifères. Les variables de départ étant de nature diverse (poids, durées, indices), c’est l’ACP normée qui a été employée. Les variables initiales ont donc d’abord été centrées et réduites avant l’analyse, pour avoir chacune une moyenne nulle et une variance égale à 1. Cela explique pourquoi chaque variable initiale est représentée par un vecteur de norme égale à 1, situé donc sur une hyper-sphère centrée dans l’origine. L’intersection de cette hyper-sphère avec le plan de projection illustré (défini par les deux premiers axes principaux) est donc un cercle et les vecteurs sont projetés à l’intérieur de ce cercle. Plus la projection d’une variable initiale est proche du cercle, plus cette variable est proche du plan de projection, donc bien représentée par ce plan. Les pourcentages d’inertie expliquée par chacun des deux premiers axes correspondent aussi aux valeurs propres \(\lambda_1 = 47,6\%\) et \(\lambda_2 = 22,25\%\), l’explication de ce constat est donnée plus loin dans ACP : relations entre les deux analyses.
Fig. 36 Sommeil des mammifères : projection du nuage des variables sur les deux premiers axes principaux¶
La visualisation des projections du nuage des variables sur les deux premiers axes principaux permet d’identifier trois groupes de variables initiales, avec une forte corrélation entre variables à l’intérieur de chaque groupe : le groupe « sommeil », le groupe « danger » et le groupe « corps, cerveau, vie, gestation » (CCVG). Le poids du corps, le poids du cerveau, la durée de vie et la durée de gestation sont donc assez fortement corrélées. On observe une forte opposition entre le groupe « sommeil » et le groupe « danger » (c’est à dire, anti-corrélation des variables entre ces deux groupes) ; les mammifères qui courent plus de dangers durant leur sommeil sont ceux qui dorment le moins. On observe ensuite une opposition plus faible (car seulement par rapport au premier axe principal) entre le groupe « sommeil » et le groupe CCVG, les mammifères les plus gros ne sont pas les plus gros dormeurs. Enfin, on constate une opposition encore plus faible (car seulement par rapport au deuxième axe principal) entre le groupe « danger » et le groupe CCVG, qui indique que les mammifères les plus gros courent en général moins de risques (et sont plus difficilement des proies).
L’analyse du nuage des observations et l’analyse du nuage des variables s’intéressent aux lignes et respectivement aux colonnes d’une même matrice de données, quels sont alors les liens entre ces analyses ?
Nous pouvons constater qu’en (pré-)multipliant \(\mathbf{X}^T \mathbf{X} \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{u}_{\alpha}\) par \(\mathbf{X}\) nous obtenons \(\mathbf{X} \mathbf{X}^T (\mathbf{X} \mathbf{u}_{\alpha}) = \lambda_{\alpha} (\mathbf{X} \mathbf{u}_{\alpha})\). À tout vecteur propre \(\mathbf{u}_{\alpha}\) de \(\mathbf{X}^T \mathbf{X}\) associé à une valeur propre \(\lambda_{\alpha}\) correspond donc un vecteur propre \((\mathbf{X} \mathbf{u}_{\alpha})\) de \(\mathbf{X} \mathbf{X}^T\) associé à la même valeur propre. Noter que la norme de ce vecteur n’est pas 1 mais plutôt \(\sqrt{\lambda_{\alpha}}\) (car nous pouvons écrire \(|\mathbf{X} \mathbf{u}_{\alpha}|^2 = (\mathbf{X} \mathbf{u}_{\alpha})^T (\mathbf{X} \mathbf{u}_{\alpha}) = \mathbf{u}_{\alpha}^T \mathbf{X}^T \mathbf{X} \mathbf{u}_{\alpha} = \mathbf{u}_{\alpha}^T \lambda_{\alpha} \mathbf{u}_{\alpha} = \lambda_{\alpha}\)).
Aussi, en (pré-)multipliant \(\mathbf{X} \mathbf{X}^T \mathbf{v}_{\alpha} = \mu_{\alpha} \mathbf{v}_{\alpha}\) par \(\mathbf{X}^T\) nous obtenons \(\mathbf{X}^T \mathbf{X} (\mathbf{X}^T \mathbf{v}_{\alpha}) = \mu_{\alpha} (\mathbf{X}^T \mathbf{v}_{\alpha})\). À tout vecteur propre \(\mathbf{v}_{\alpha}\) de \(\mathbf{X} \mathbf{X}^T\) associé à une valeur propre \(\mu_{\alpha}\) correspond alors un vecteur propre \((\mathbf{X}^T \mathbf{v}_{\alpha})\) de \(\mathbf{X}^T \mathbf{X}\) associé à la même valeur propre. Ce vecteur propre est aussi de norme \(\sqrt{\lambda_{\alpha}}\) et non 1.
Nous pouvons conclure que les valeurs propres non nulles de même ordre de \(\mathbf{X} \mathbf{X}^T\) et \(\mathbf{X}^T \mathbf{X}\) sont toutes égales, \(\lambda_{\alpha} = \mu_{\alpha}\). Aussi, que les relations suivantes sont valables entre vecteurs propres :
De ce constat résultent les relations de transition (ou de dualité) suivantes qui permettent de passer des projections des variables sur l’axe factoriel d’ordre \(\alpha\) aux projections des observations sur l’axe factoriel correspondant de même ordre, et réciproquement :
Ces deux relations sont importantes car elles permettant de passer des résultats d’une des analyses directement aux résultats de l’autre. En général, le nombre \(n\) d’observations est nettement supérieur au nombre \(d\) de variables initiales, il est donc préférable de traiter la matrice \(\mathbf{X}^T \mathbf{X}\), de dimension \(d \times d\), plutôt que \(\mathbf{X} \mathbf{X}^T\), de dimension \(n \times n\). Les résultats de l’autre analyse sont ensuite facilement obtenus grâce aux relations de transition.
Par ailleurs, les relations de transition rendent possible une interprétation simultanée des projections des observations et des projections des variables sur les axes factoriels de même ordre. En effet, si seules quelques observations (quelques valeurs de \(i\)) présentent des valeurs très élevées (\(x_{ij}\)) pour une variable (\(j\)), alors de (7) nous obtenons que la projection de cette variable (\(\phi_{\alpha j}\)) sur un axe est, à un facteur multiplicatif près (\(\frac{1}{\sqrt{\lambda_{\alpha}}}\)), la moyenne pondérée des projections sur l’axe de même ordre (\(\psi_{\alpha i}\)) de ces observations. Dans l’exemple du sommeil des mammifères, nous pouvons ainsi constater que les éléphants présentent des valeurs comparativement très élevées pour les variables du groupe CCVG.
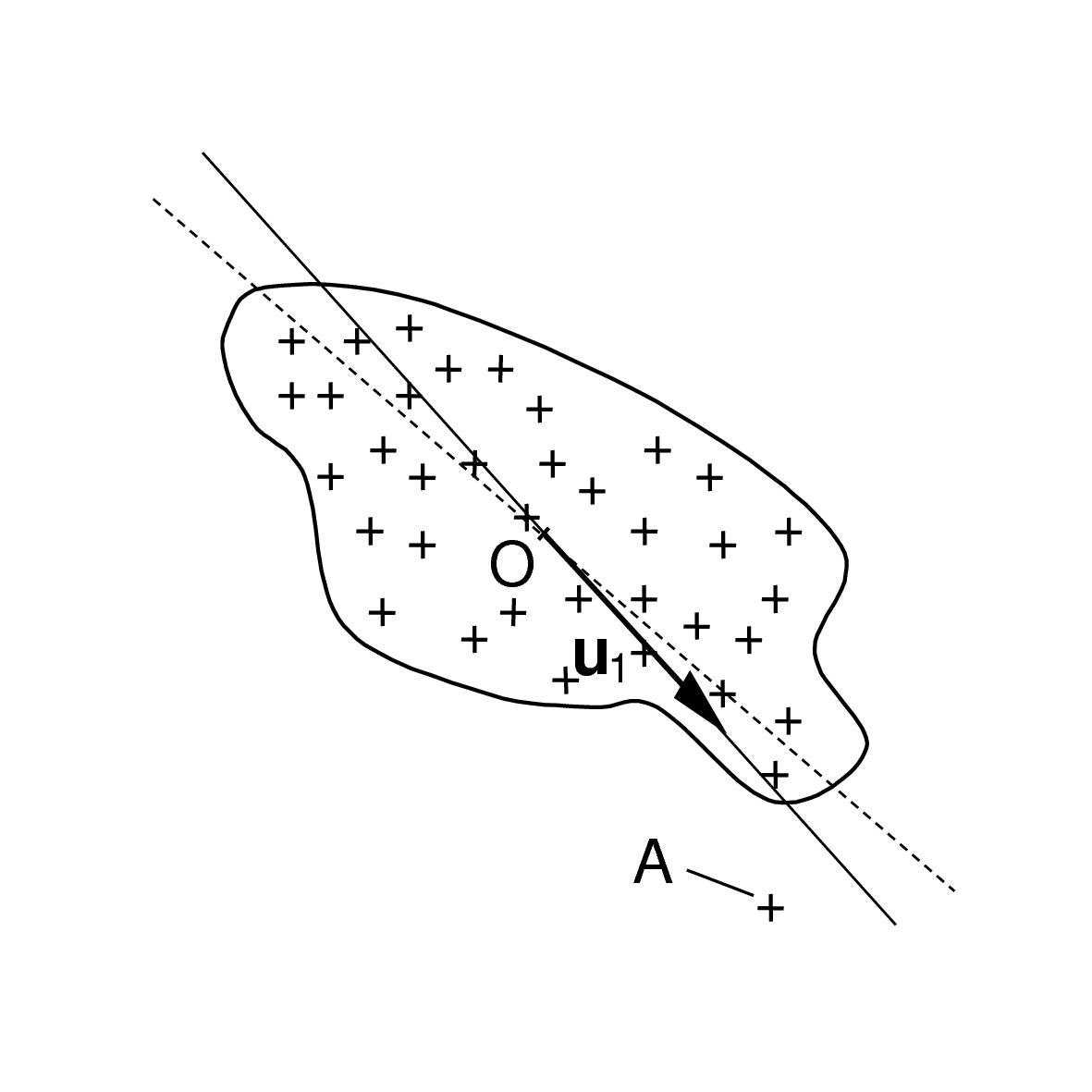
Un des objectifs de l’ACP est d’aider à une meilleure compréhension des données à travers les possibilités d’interprétation des relations (corrélations ou anti-corrélations) entre multiples variables, des positionnement relatifs de certaines observations ou classes d’observations par rapport aux variables, etc. Les aides à l’interprétation permettent de savoir jusqu’où aller dans l’interprétation, en identifiant les observations et variables mal représentées par leurs projections sur les axes et les éventuelles observations dont l’impact sur l’analyse est excessif.
La qualité de représentation d’une observation (ou d’une variable) par un axe factoriel est évaluée à travers l’apport de l’axe factoriel dans l’explication de l’inertie de l’observation (ou de la variable). Cette mesure est parfois plus connue sous le nom de contribution relative (ou cosinus carré) d’un axe dans l’explication de l’inertie d’une observation (ou d’une variable). La contribution relative de l’axe \(\alpha\) dans l’explication de l’inertie de l’observation \(i\) a l’expression suivante :
La contribution relative est le rapport entre le carré de la projection de l’observation (ou de la variable) sur l’axe (c’est à dire l’inertie de la projection) et le carré de la norme du vecteur qui représente l’observation (ou la variable) dans l’espace de départ (c’est à dire l’inertie totale de l’observation ou de la variable).
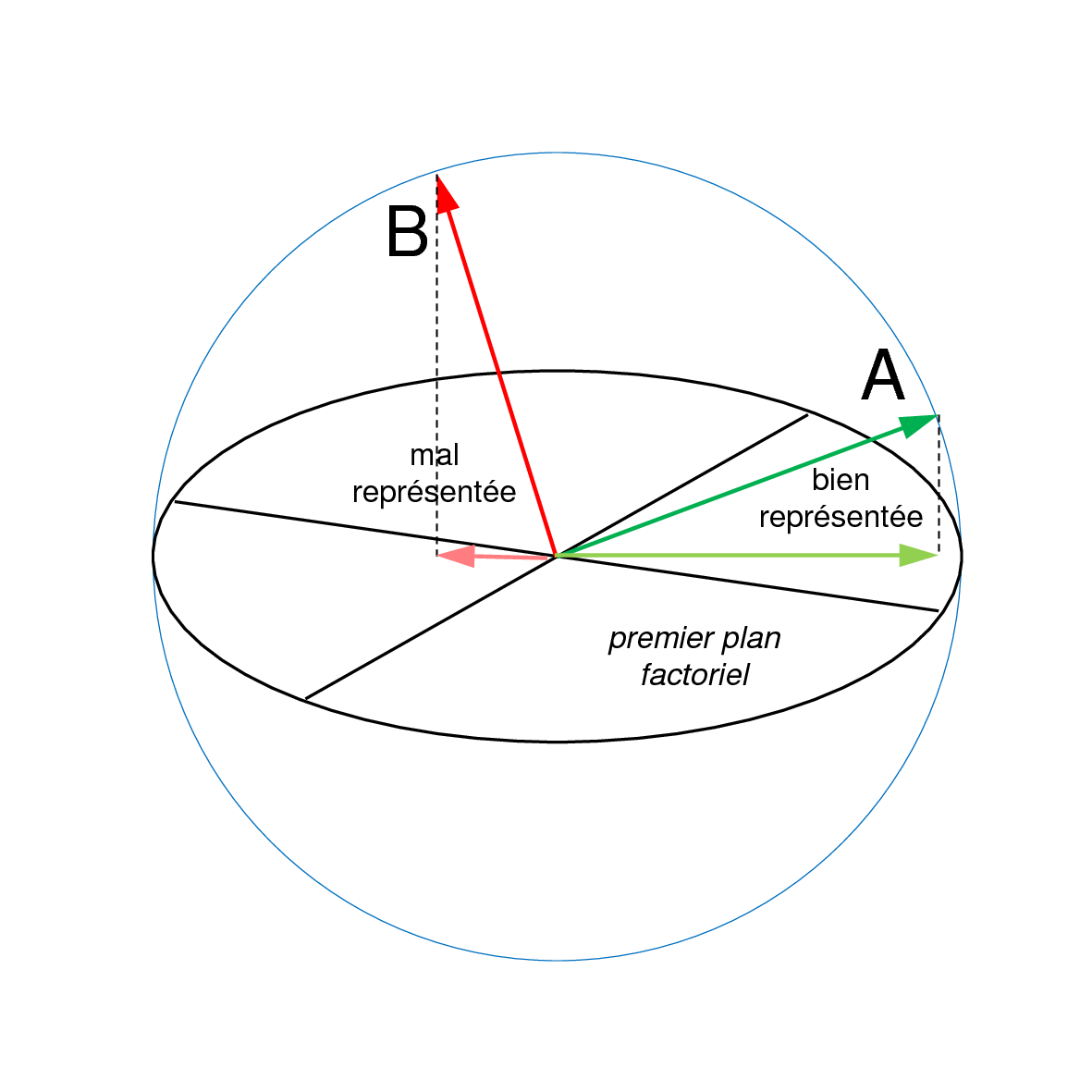
Dans l’exemple ci-dessous (Fig. 37), l’axe factoriel représenté explique la majeure partie de l’inertie de l’observation A mais une faible part de l’inertie de l’observation B. Il est donc pertinent d’interpréter la position de la projection de A sur cet axe, mais il n’est pas pertinent d’interpréter la projection de B sur l’axe.
Fig. 37 Contribution relative d’un axe dans l’explication de l’inertie d’une observation : A est bien mieux représentée par l’axe illustré que B¶
Dans l’exemple ci-dessous (Fig. 38), le plan factoriel (défini par deux axes factoriels) représenté explique la majeure partie de l’inertie de la variable A mais une faible part de l’inertie de la variable B. Il est donc pertinent d’interpréter la position de la projection de A sur ce plan, mais il n’est pas pertinent d’interpréter la projection de B sur le même plan. Lorsque l’analyse est normée (c’est le cas Fig. 38), tous les vecteurs représentant des variables ont une même norme de 1 et sont donc situés sur une sphère centrée dans l’origine. L’intersection entre cette sphère et un plan factoriel est un cercle (centré dans l’origine). Les variables dont la projection est proche du cercle sont bien représentées par ce plan factoriel, les variables dont la projection est plus proche du centre sont mal représentées par ce plan.
Fig. 38 Contribution relative d’un axe dans l’explication de l’inertie d’une variable¶
Pour que les résultats soient interprétables, il est également important que les contributions des différentes observations (ou variables initiales) à l’analyse soient relativement équilibrées. Dans un cas concret, y a-t-il des observations (ou variables) dont l’impact sur les résultats de l’analyse, c’est à dire sur l’orientation des axes factoriels, soit démesuré ? Cet impact est mesuré par la contribution absolue (ou simplement contribution) d’une observation (ou d’une variable) à la variance expliquée par un axe factoriel. La contribution d’une observation à la variance expliquée par un axe factoriel est le rapport entre le carré de la projection de l’observation sur l’axe et la variance totale expliquée par cet axe, c’est à dire la valeur propre correspondant à l’axe :
La contribution d’une variable à la variance expliquée par un axe factoriel est le rapport entre le carré de la projection de la variable sur l’axe et la variance totale expliquée par cet axe (la valeur propre correspondante) :
La Fig. 39 montre une observation très excentrée, notée par A, qui aura inévitablement un impact très fort sur l’orientation de l’axe factoriel illustré. En examinant la Fig. 35 nous pouvons constater visuellement que les éléphants devraient avoir un impact très fort sur l’orientation des axes présentés (cela est confirmé par le calcul de leurs contributions absolues à l’orientation des 2 premiers axes). Dans de telles situations, il peut être préférable de retirer l’observation ou les observations dont l’impact est excessif et de refaire l’analyse. Les observations retirées seront ensuite projetées comme des observations supplémentaires (voir ACP : observations et variables supplémentaires) sur les axes ainsi obtenus.
Fig. 39 Contribution absolue d’une observation à la variance expliquée par un axe factoriel : l’observation A, très excentrée, « tire » l’axe factoriel vers elle¶
Dans la section ACP : solution nous avons proposé quelques interprétations obtenues à partir des projections du nuage des observations sur les deux premiers axes principaux et ensuite des projections du nuage des variables sur les axes de même ordre. Ces interprétations doivent être validées à partir des valeurs obtenues pour les aides à l’interprétation correspondantes. Les observations ou variables dont la projection a été interprétée sont-elles bien représentées par ces axes ? C’est le cas dans cet exemple (bien que nous n’ayons pas fourni les valeurs des contributions relatives pour les observations). Y a-t-il des observations (ou des variables) dont l’impact sur l’analyse est excessif ? Oui, les éléphants, comme le suggère Fig. 35.
Les objectifs de l’interprétation des résultats d’une analyse en composantes principales sont :
Révéler quelles variables (ou groupes de variables) sont corrélées et quelles variables (ou groupes de variables) s’opposent.
Si les individus ne sont pas anonymes, identifier des relations entre eux.
Mettre en évidence des regroupements d’individus et les caractériser à partir des variables.
Nous pouvons maintenant lister quelques règles générales d’interprétation des résultats d’une ACP, règles que nous avons suivies dans la section ACP : solution :
Associer une interprétation à chaque axe factoriel à partir des corrélations et des oppositions entre variables initiales. Dans l’exemple du sommeil de mammifères, le premier axe peut être considéré comme étant associé à l’opposition entre espèces dont les individus dorment beaucoup et espèces dont les individus sont soumis à des dangers.
Le regroupement de projections des individus sur les plans factoriels s’interprète en termes de similitudes de comportement par rapport aux variables. Dans l’exemple du sommeil des mammifères, nous pouvons ainsi constater que les éléphants présentent des valeurs comparativement très élevées pour les variables du groupe CCVG.
Éviter d’interpréter les projections sur un axe factoriel des individus mal représentés par l’axe (contributions relatives faibles de cet axe par rapport à ces individus).
Retirer, pour une nouvelle analyse, les individus ayant des contributions absolues excessives à l’orientation de certains axes. Dans l’exemple du sommeil de mammifères, retirer les deux observations correspondant aux éléphants.
Le choix du nombre \(k\) de composantes principales (ou d’axes) à retenir dépend de l’objectif de l’analyse :
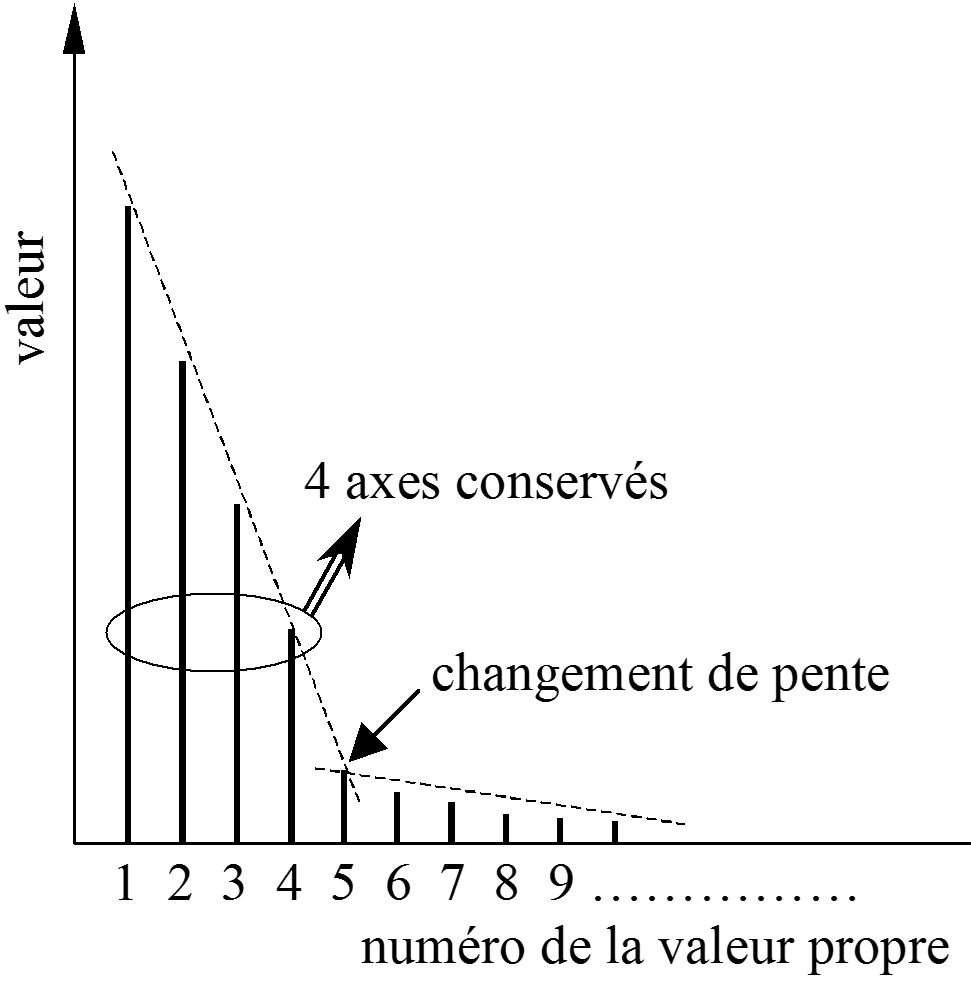
Pour une analyse descriptive avec visualisation, il faut déterminer à partir de quel ordre les différences entre les pourcentages d’inertie expliquée ne sont plus significatives. Un test statistique d’égalité entre valeurs propres successives peut être envisagé si la distribution des données est proche d’une distribution normale multidimensionnelle. Une méthode heuristique est souvent utilisée, voir la Fig. 40 : on construit le graphique des valeurs propres triées par ordre décroissant et on conserve les valeurs propres (et les composantes principales associées) qui précèdent le premier « coude ». En effet, lorsque les différences entre valeurs propres successives deviennent faibles, les axes principaux correspondants ne sont plus significatifs car ils deviennent très instables par rapport au choix de l’échantillon analysé. Nous avions déjà remarqué à l’aide de la Fig. 29 que lorsque le nuage d’observations n’a de « dispersion » plus forte dans aucune direction particulière, aucune direction ne peut être privilégiée pour le « résumer ».
Fig. 40 Choix du nombre d’axes en ACP : lorsque les différences entre valeurs propres successives deviennent faibles, les axes principaux correspondants ne sont plus significatifs¶
Pour la compression des données on impose en général la conservation d’une qualité d’approximation des données initiales, mesurée par le taux d’inertie expliquée (par ex. 85%). Sont choisis autant d’axes que nécessaire pour que la somme des valeurs propres correspondantes dépasse le taux d’inertie visé.
Si l’ACP est employée comme prétraitement avant application de méthodes décisionnelles, on utilise souvent un simple critère de bon conditionnement de la matrice des covariances empiriques (ou corrélations empiriques pour une analyse normée). Attention, ce choix peut s’avérer nocif lorsque les directions qui présentent la plus faible variance sont des directions prédictives (par exemple, dans un problème de classement, des directions discriminantes ou qui aident à séparer les classes), comme nous le verrons plus loin (Fig. 55). Il est également possible de considérer le nombre d’axes comme un paramètre supplémentaire de la méthode décisionnelle et d’employer ensuite une technique de sélection de modèle décisionnel.
Après avoir appliqué l’ACP sur les observations disponibles, décrites par les variables initiales, et obtenu les axes factoriels (axes principaux ici), il est envisageable de projeter sur les mêmes axes de nouvelles données. Il est ainsi possible de projeter de nouvelles observations, décrites par les mêmes variables initiales, sur les axes obtenus lors de l’analyse du nuage des observations. Il est également possible de projeter de nouvelles variables, décrivant les mêmes observations, sur les axes obtenus lors de l’analyse du nuage des variables. Attention à ne pas oublier de traiter convenablement ces données supplémentaires avant projection. Pour une nouvelle observation il faut retirer la moyenne de chaque variable des valeurs observées (pour une ACP centrée) et diviser chaque résultat ainsi obtenu par l’écart-type de la variable respective (pour une ACP normée). Pour une nouvelle variable, il faut retirer sa moyenne de toutes les valeurs mesurées (pour une ACP centrée), calculer son écart-type et diviser les résultats du « centrage » par cet écart-type (pour une ACP normée).
Les projections de ces observations (ou variables) supplémentaires peuvent participer aux interprétations à condition que la qualité de représentation de ces observations (ou variables) sur les axes de projection soit bonne. Il est donc nécessaire de calculer les contributions relatives (8) (ou (9)) correspondantes.
Quelles peuvent être ces observations supplémentaires (aussi appelées illustratives) ?
Observations faites dans des conditions différentes ou nouvelles observations. Par exemple, lorsque des observations présentent une qualité incertaine, il peut être préférable de ne pas les inclure dans l’analyse mais de les considérer plutôt comme observations supplémentaires. Aussi, lorsque les mêmes « individus » sont observés à nouveau, il est possible d’examiner leur évolution entre mesures successives en traitant ces mesures ultérieures comme des observations supplémentaires.
Observations atypiques, éliminées de l’analyse en raison de leurs contributions absolues excessives. Les observations très atypiques (éloignées du nuage des autres observations) ont en général un fort impact sur l’analyse ; l’orientation des axes factoriels reflète ainsi en trop grande partie l’atypicité de ces observations plutôt que les caractéristiques plus larges du nuage d’observations. Il est alors préférable d’exclure ces observations atypiques de l’analyse et de les projeter sur les axes factoriels (obtenus sans ces observations) comme des observations supplémentaires.
Le centre de gravité d’un groupe d’observations défini sur des critères spécifiques au problème peut être projeté sur les axes factoriels de l’analyse du nuage des observations afin d’interpréter sa position par rapport aux projections d’autres observations ou par rapport aux variables (interprétation simultanée). Un cas typique est celui où le groupe est composé des observations qui possèdent une modalité particulière pour une variable nominale (non prise en compte par l’ACP). Par exemple, dans le cas du sommeil des mammifères, il est possible de définir un groupe « mammifères domestiques » et regarder où se projette le centre de gravité de ce groupe. Il est pertinent d’interpréter la projection de ce centre de gravité sur un axe factoriel si les observations qui composent le groupe sont bien représentées par cet axe et leurs projections sur l’axe sont relativement bien regroupées. Cela s’exprime par l’inégalité \(v_{\alpha k} > 1,96\), où \(n_k\) est le nombre d’observations qui font partie du groupe (ou qui possèdent la modalité \(k\) d’une variable nominale) et
Les variables supplémentaires (ou illustratives) peuvent être :
De nouvelles variables quantitatives décrivant les mêmes observations. Ces variables peuvent être projetées sur les axes factoriels de l’analyse du nuage des variables, après centrage pour une ACP centrée et centrage suivi de réduction pour une ACP normée.
Des variables nominales (à modalités). De telles variables ne sont pas prises en compte par l’ACP mais peuvent contribuer à l’interprétation. Par exemple, il est possible de voir si les axes principaux contribuent ou non à séparer les groupes d’observations qui possèdent des modalités différentes pour la variable nominale. Pour prendre en compte une variable nominale comme variable supplémentaire, il faut déterminer pour chaque modalité le centre de gravité des observations qui la possèdent et projeter ce centre de gravité comme une observation supplémentaire sur les axes de l’analyse du nuage des observations. Pour que ces projections soient interprétables, la condition (12) doit être vérifiée.
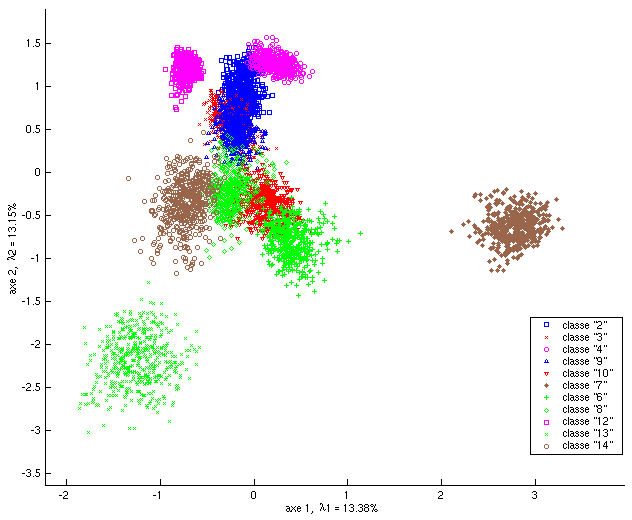
Il est utile d’examiner un nouvel exemple, dans lequel les observations correspondent à des descripteurs visuels de pixels extraits d’images de textures [2]. Il y a 11 classes de (micro-)textures et 500 pixels sont issus de chaque classe, donc le nombre total d’observations est \(n = 5500\). Les observations peuvent être considérées ici comme étant « anonymes » car les pixels individuels n’ont pas de signification particulière. Chaque pixel est décrit par 40 variables qui sont les moments statistiques modifiés d’ordre 4, déterminés pour 4 orientations différentes \(0^{\circ}, 45^{\circ}, 90^{\circ}, 135^{\circ}\), tenant compte des relations avec les voisins d’ordres 1 et 2. Il y a donc \(d = 40\) variables initiales.
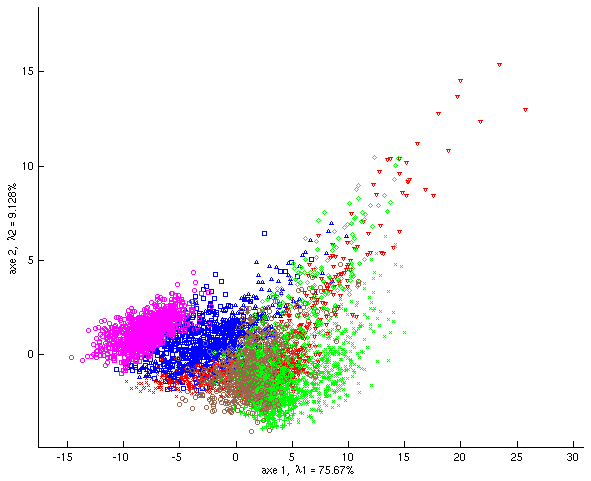
La Fig. 41 montre les projections du nuage des observations sur les deux premiers axes principaux. Les 5500 observations initiales de dimension 40 sont projetées sur les deux premiers axes (\(k = 2\)). En plus des 40 variables quantitatives initiales, chaque pixel est caractérisé par la classe de texture à laquelle il appartient, mais l’ACP ne tient pas compte de cette variable nominale. Cette classe a néanmoins été représentée dans la Fig. 41 par une couleur et une forme spécifique du point de projection afin de nous permettre de voir dans quelle mesure les directions de variances maximales (les deux premiers axes principaux dans cette projection bidimensionnelle) permettent de séparer les classes.
Fig. 41 Textures : projections du nuage des observations sur les deux premiers axes principaux¶
Nous observons que le premier axe factoriel explique plus de 75% de l’inertie, alors que le deuxième axe explique seulement 9% de l’inertie. Dans les projections sur le premier plan factoriel on constate l’opposition entre un grand nuage dense composé de pixels appartenant à différentes classes et un nuage bien plus petit composé de pixels assez atypiques issus de quelques classes. La variable nominale (qui n’intervient pas dans l’ACP) n’est pas directement liée à cette opposition, le premier axe ne sépare pas les observations issues des différentes classes de textures.
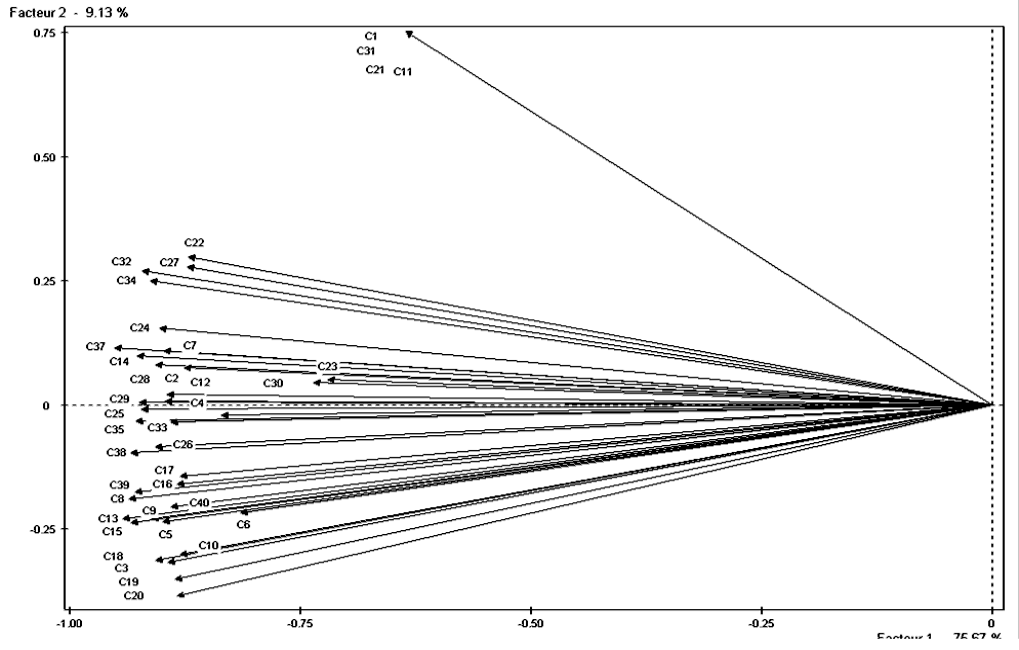
La Fig. 42 montre un détail de la projection du nuage des variables sur les deux premiers axes principaux. Nous observons d’abord que pour quatre variables les projections sur ce plan factoriel sont identiques. Un examen plus attentif des données indique que ces variables sont en fait identiques.
D’ailleurs, la matrice \(\mathbf{X}^T \mathbf{X}\) a parmi ses valeurs propres la valeur 0 de multiplicité égale à 4. Attention, cela ne signifie pas, en général, que dans les variables initiales il y a quatre variables identiques mais seulement qu’il y a quatre variables qui sont des combinaisons linéaires d’autres variables.
Nous observons également que toutes les variables sont assez bien corrélées, ce qui explique pourquoi le premier axe domine à ce point en termes d’inertie expliquée (75%). Cette forte corrélation entre toutes les variables porte le nom d”« effet taille » et indique la présence d’une variable « cachée » (le premier axe principal) qui « explique » assez bien les variables. Le nom « effet taille » provient d’études réalisées sur les mesures physiques d’individus, mesures qui sont naturellement corrélées à la « taille » de l’individu.
Fig. 42 Textures : projections du nuage des variables sur les deux premiers axes principaux (détail)¶
Un exemple : notes élevées ou faibles à deux matières¶
Considérons les notes obtenues par les 32 élèves d’une classe à deux matières, les mathématiques et la littérature. Au lieu de nous intéresser directement aux notes exactes, nous les classerons en deux catégories, notes élevées et notes faibles. Le tableau de contingences suivant présente les effectifs correspondant à chacune des quatre combinaisons possibles :
Nous avons ainsi défini deux variables nominales, la « note » en littérature et la « note » en mathématiques. Chacune de ces variables possède deux modalités différentes, « élevée » et « faible ». Chaque élève possède une (et une seule) modalité pour chacune de ces variables. A partir du contenu du tableau de contingences, pouvons-nous dire s’il y a un lien entre les deux variables nominales ? Pour que la réponse soit positive, il faudrait que la proportion d’élèves avec une note faible en littérature ne soit pas la même parmi les élèves avec une note élevée en mathématiques et pour la classe entière.
Dans le cas présent, la réponse est négative car cette proportion est la même, \(\frac{6}{24} = \frac{8}{32}\).
Et si les effectifs étaient plutôt ceux du tableau suivant ?
Dans ce cas la réponse est positive car \(\frac{10}{24} > \frac{12}{32}\). Et nous pouvons difficilement en dire plus car nous n’avons que deux variables, chacune avec deux modalités.
Il est donc assez facile de caractériser le lien entre deux variables nominales qui possèdent chacune deux modalités. Comment procéder dans un cas plus général ?
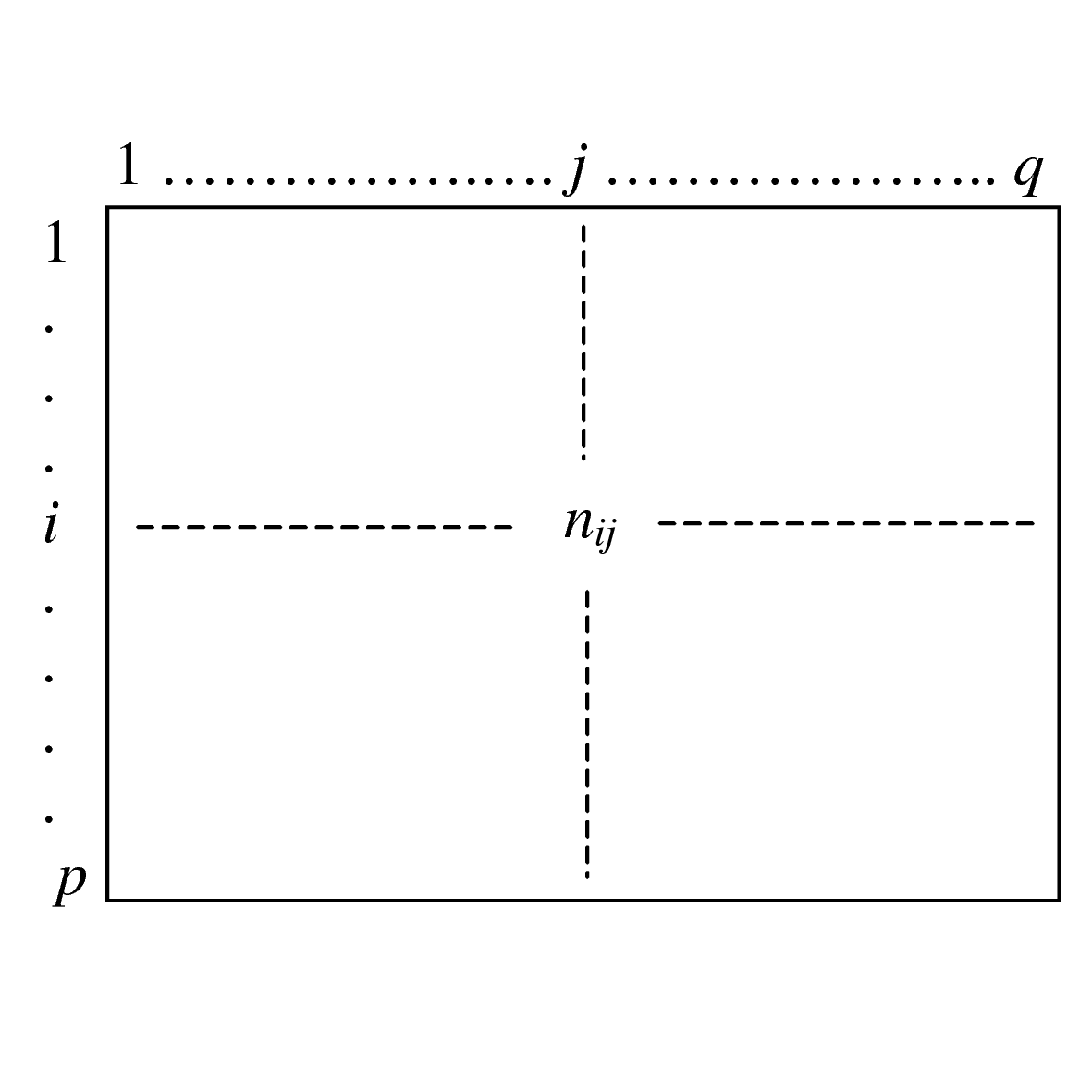
Considérons maintenant deux variables nominales, avec \(p\) et respectivement \(q\) modalités. Les effectifs correspondant aux différentes combinaisons possibles entre les modalités des deux variables sont représentés dans un tableau de contingences :
Fig. 43 Tableau de contingences entre deux variables nominales¶
Comment résumer les liens entre les modalités des deux variables ? Quels sont les liens dominants ? Nous avons vu que l’analyse en composantes principales (ACP) permettait de résumer les liens entre des variables quantitatives. Il est ainsi envisageable de se servir d’un appareil mathématique similaire pour caractériser le nuage des lignes (modalités de la première variable nominale) et le nuage des colonnes (modalités de la seconde variable nominale) d’un tableau de contingences. Il est toutefois nécessaire de faire quelques adaptations pour tenir compte de la nature des données et des relations que nous cherchons à mettre en évidence.
Considérons un deuxième exemple pour illustrer la suite de cette présentation. Les données sont issues d’une enquête réalisée au Québec aux débuts de l’Internet grand public, [4]. Nous nous intéressons à deux des variables nominales retenues, l’ancienneté dans l’utilisation d’Internet et le nombre moyen d’heures de connexion par mois. Ces variables ont été discrétisées à partir principalement de connaissances spécifiques au problème. Ainsi, à partir de chaque variable quantitative a été obtenue une variable nominale dont chaque modalité correspond à un intervalle de valeurs de la variable quantitative. Les modalités des deux variables nominales résultantes et les effectifs des différentes combinaisons de modalités sont indiqués dans le tableau suivant.
< 3 mois
3-6 mois
6-12 mois
1-2 ans
2-3 ans
> 3 ans
total
< 2 h
71
76
160
208
65
23
603
2-5 h
197
204
542
798
359
148
2248
5-10 h
251
234
491
762
427
229
2394
10-20 h
172
164
421
565
399
227
1948
> 20 h
79
98
239
397
272
241
1326
total
770
776
1853
2730
1522
868
8519
Analyse factorielle des correspondances binaires (AFCB)¶
L’analyse factorielle des correspondances binaires (AFCB, [Ben73]) a pour objectif de mettre en évidence les relations dominantes entre les modalités de deux variables nominales. Les données sont disponibles au départ sous la forme d’un tableau de contingences, comme celui de l’exemple concernant l’utilisation d’Internet au Québec. Pouvons-nous appliquer une analyse sur le modèle de l’ACP directement sur les données d’un tel tableau ? En examinant le tableau ci-dessus, après avoir calculé les sommes par lignes et par colonnes, nous pouvons constater que certaines modalités sont bien plus fréquentes que d’autres. Faut-il ignorer ces différences et donner à toutes les modalités le même poids dans l’analyse (comme on le fait pour les observations et pour les variables dans une ACP) ou alors privilégier les modalités les plus fréquentes par rapport aux moins fréquentes ? Également, dans le calcul des distances dans l’espace des lignes, une composante correspondant à une colonne plus fréquente (par ex. « 1-2 ans ») doit-elle avoir plus de poids qu’une composante correspondant à une colonne moins fréquente (par ex. « < 3 mois ») ? Les choix faits dans l’AFCB se reflètent dans les étapes de traitement présentées dans la suite.
La première étape, très simple, consiste à passer d’un tableau de contingences à un tableau des fréquences relatives (voir aussi Fig. 44) :
où \(n_{ij}\) est le nombre d’individus qui possèdent la modalité \(i\) pour la première variable et \(j\) pour la seconde, et \(n\) est l’effectif global (le nombre total d’individus). Les marges correspondantes sont
Le tableau des fréquences relatives est obtenu en divisant les éléments du tableau de contingences par une constante (l’effectif global \(n\)), les marges des lignes et des colonnes du tableau des fréquences relatives reflètent donc les différences de fréquence entre modalités.
La seconde étape consiste à construire les profils-lignes (et les profils-colonnes), en divisant chaque ligne (respectivement chaque colonne) par sa marge. Nous obtenons ainsi des profils-lignes (respectivement profils-colonnes) de même norme \(L_1\) égale à 1.
AFCB : analyse des profils-lignes et des profils-colonnes¶
Les modalités étant représentées par les profils (profils-lignes pour la première variable, profils-colonnes pour la seconde), les fréquences relatives des modalités (\(f_{i.}\) pour la ligne \(i\), \(f_{.j}\) pour la colonne \(j\)) n’ont pas d’impact sur les calculs de distance entre chaque profil et le centre de gravité des profils. En revanche, la pondération d’un profil dans l’analyse est proportionnelle à la fréquence relative de la modalité dont il est issu : \(f_{i.}\) pour le profil-ligne \(i\), respectivement \(f_{.j}\) pour le profil-colonne \(j\). L’importance accordée à un profil issu d’une modalité plus fréquente est ainsi supérieure à l’importance accordée à un profil issu d’une modalité moins fréquente. Cette pondération intervient :
Dans le calcul du centre de gravité des profils, par ex. pour les profils-lignes le centre de gravité \(g_L\) a comme composantes \(g_{Lj} = \sum_{i=1}^p f_{i.}\frac{f_{ij}}{f_{i.}} = \sum_{i=1}^p f_{ij} = f_{.j}\), pour \(1 \leq i \leq p\).
Dans le calcul de l’inertie par rapport au centre du nuage (voir [CABB04], [Sap11]).
L’utilisation de la distance euclidienne classique dans l’espace des profils aurait pour conséquence la sur-pondération, dans les calculs de distance, des composantes correspondant aux modalités les plus fréquentes de l’autre variable. Par exemple, dans le calcul des distances dans l’espace des lignes, une composante correspondant à une colonne plus fréquente (par ex. « 1-2 ans ») aurait bien plus de poids qu’une composante correspondant à une colonne moins fréquente (par ex. « < 3 mois »). Afin de réduire cette sur-pondération, c’est la distance du \(\chi^2\) qui a été proposée ([Ben73]) plutôt que la distance euclidienne classique. Ainsi, entre les profils-lignes \(\mathbf{i},\mathbf{l}\), la distance du \(\chi^2\) est
La distance du \(\chi^2\) présente une propriété intéressante, l`équivalence distributionnelle : si deux colonnes proportionnelles sont cumulées en une seule (fusion de deux modalités), les distances entre les profils-lignes (et celles entre les autres profils-colonnes) ne changent pas. En conséquence, il n’est pas nécessaire de refaire l’analyse après la fusion.
Afin d’obtenir les mêmes résultats d’analyse avec la distance euclidienne, il est nécessaire de redéfinir les profils :
le profil de la ligne \(i\) : \(\frac{1}{f_{i.}} \left[\frac{f_{i1}}{\sqrt{f_{.1}}} \ldots \frac{f_{ij}}{\sqrt{f_{.j}}} \ldots \frac{f_{iq}}{\sqrt{f_{.q}}}\right]\),
le profil de la colonne \(j\) : \(\frac{1}{f_{.j}} \left[\frac{f_{1j}}{\sqrt{f_{1.}}} \ldots \frac{f_{ij}}{\sqrt{f_{i.}}} \ldots \frac{f_{pj}}{\sqrt{f_{.p}}}\right]\).
Avec ces modifications des profils et la prise en compte des pondérations (voir ci-dessus), l’analyse des profils-lignes et des profils-colonnes se déroule comme l’analyse du nuage des observations et respectivement du nuage des variables dans l’ACP centrée. Les axes factoriels recherchés sont ceux qui maximisent la variance des projections des profils. Il est possible de montrer que les valeurs propres non nulles issues de l’analyse du nuage des profils-lignes sont identiques aux valeurs-propres non nulles issues de l’analyse du nuage des profils-colonnes. Des développements mathématiques plus complets peuvent être trouvés dans [CABB04], [Sap11].
Le choix du nombre d’axes pour l’AFCB peut être fait comme pour l’ACP, sachant que l’objectif principal de l’AFCB est l`interprétation à partir des projections sur les axes factoriels. Le critère du « coude » peut ainsi être employé pour choisir le nombre d’axes factoriels (voir la Fig. 40).
Supposons que \(\psi_{\alpha i}\) est la coordonnée du profil-ligne \(i\) sur l’axe factoriel d’ordre \(\alpha\) et \(\phi_{\alpha j}\) la coordonnée du profil-colonne \(j\) sur l’axe factoriel d’ordre \(\alpha\). Comme pour l’ACP, nous obtenons les relations de transition suivantes entre les résultats des deux analyses qui concernent les profils-lignes et respectivement les profils-colonnes :
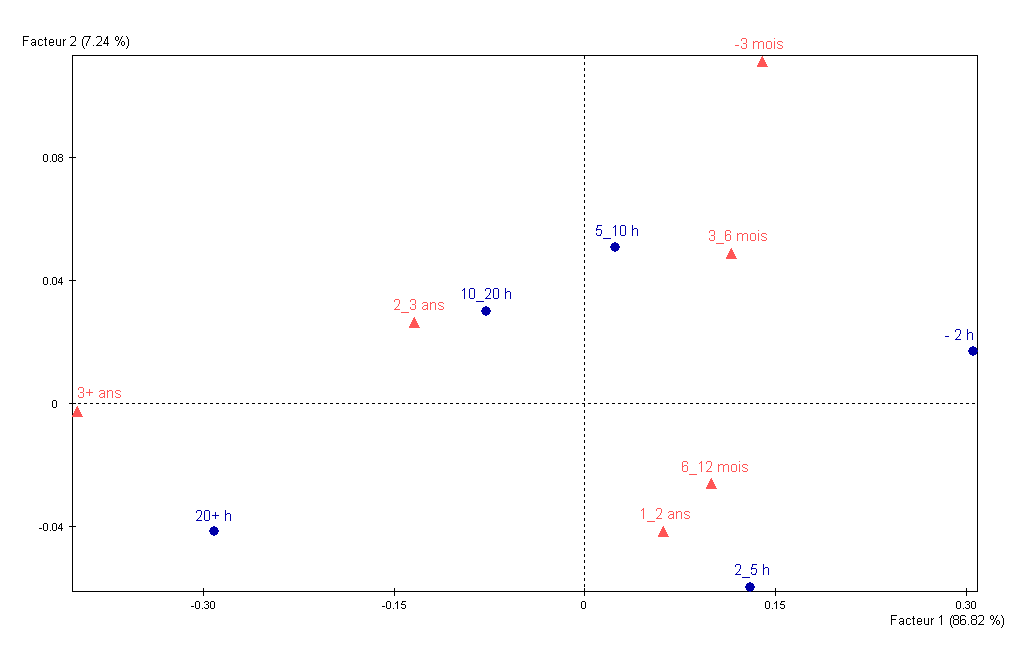
Ces relations de transition rendent possible l’interprétation à partir d’une représentation simultanée, c’est à dire des projections des profils-lignes et des profils-colonnes sur les axes factoriels de mêmes ordres. Les résultats obtenus pour les deux variables issues de l’enquête sur l’utilisation d’Internet sont montrés dans la Fig. 45.
Fig. 45 Utilisation d’Internet : projection des modalités sur les deux premiers axes factoriels¶
Nous pouvons d’abord observer que le premier axe factoriel représente bien plus d’inertie que le deuxième (\(87\% \gg 7\%\)), l’interprétation la plus importante sera donc faite à partir des projections sur le premier axe.
Les aides à l’interprétation sont définies comme pour l’ACP : la qualité de représentation des profils (contributions relatives des axes factoriels), l’influence de chaque profil (contributions absolues des modalités à l’orientation des axes factoriels).
A partir de la Fig. 45 nous pouvons constater un lien assez fort entre la durée de connexion et l’ancienneté, sauf pour une ancienneté inférieure à 6 mois. En effet, l’évolution de « moins de 3 mois » à « 3-6 mois » et ensuite « 6-12 mois » se fait le long du deuxième axe, alors que l’évolution du temps de connexion se fait plutôt le long du premier axe. Nous pouvons également constater des proximités assez fortes entre les projections des modalités « 10-20 h » de la première variable et « 2-3 ans » de la seconde variable. Cette proximité indique qu’une part importante des individus qui se connectent 10 à 20 heures par semaine utilisent Internet depuis 2 à 3 ans (et réciproquement). Les projections des modalités « 2-5 h » et « 1-2 ans » sont également assez proches, ainsi que « 2-5 h » et « 6-12 mois ». Les liens entre les autres modalités des deux variables sont plus faibles.
Il est important de noter que si les variables nominales étaient indépendantes alors toutes les projections des modalités sur les axes factoriels seraient confondues. Comme les variables sont rarement parfaitement indépendantes sur un ensemble d’observations, l’analyse peut produire des axes et les projections des modalités sur ces axes peuvent sembler distinctes (et éloignées, suivant l’échelle de la figure) même lorsque les variables sont presque indépendantes. Il est donc utile d’appliquer avant analyse un test du \(\chi^2\) d’indépendance entre les variables afin de savoir s’il est pertinent d’appliquer l’AFCB.
Bien souvent, les observations sont décrites par plus de deux variables nominales. L’analyse des correspondances peut être étendue à l’analyse simultanée des relations entre plus de deux variables nominales, on parle dans ce cas d’analyse des correspondances multiples ou ACM. L’objectif général de l’ACM est de mettre en évidence les relations dominantes entre modalités des variables nominales initiales.
Considérons \(n\) observations caractérisées par \(q > 2\) variables nominales, représentées par un tableau disjonctif complet (TDC, voir la Fig. 46). On suppose, ici encore, que chaque observation possède exactement une modalité pour chaque variable. L’ACM peut être appliquée à partir d’un TDC pour mettre en évidence des relations entre modalités des différentes variables ou éventuellement des relations entre observations et modalités.
Il est également possible d’appliquer l’ACM à partir d’un tableau de Burt qui est la concaténation des tables de contingences par paires de variables nominales. L’emploi du TDC permet d’analyser à la fois le nuage des observations et le nuage des modalités des variables, alors que le tableau de Burt permet d’étudier seulement le nuage des modalités car les observations individuelles n’y sont pas décelables.
L’ACM est traditionnellement employée dans le traitement d’enquêtes basées sur des questions fermées à choix multiples, afin de mettre en évidence des relations entre modalités ou éventuellement entre observations et modalités. Pour cela, \(k\) nouvelles variables quantitatives sont construites à partir des \(q\) variables nominales initiales, en conservant un maximum de variance. L’ACM peut également servir à résumer un grand nombre (\(q\)) de variables nominales par un faible nombre (\(k \ll q\)) de variables quantitatives. Lorsque le nombre d’observations est assez faible pour que les observations individuelles ne se perdent pas dans la masse, l’ACM permet aussi de mettre en évidence des relations intéressantes entre observations et variables. Il est enfin possible d’inclure des variables quantitatives dans l’analyse, après leur transformation en variables nominales (voir ACM : inclusion de variables quantitatives).
Un exemple permet d’illustrer notre propos. Considérons celui issu de [CABB04] (basé sur des données de l’enquête [5]) pour clarifier la nature des résultats obtenus par ACM. L’enquête « Les étudiants et la ville » [5] dont sont issues les données inclut, entre autres, les questions suivantes :
Habitez-vous : seul(e), en colocation, en couple, avec les parents.
Quel type d’habitation occupez-vous : cité U, studio, appartement, chambre chez l’habitant, autre.
Si vous vivez en dehors du foyer familial, depuis combien de temps : moins d’1 an, de 1 à 3 ans, plus de 3 ans, non applicable (NA, pour ceux qui habitent avec leur famille).
A quelle distance de l’université vivez-vous : moins d’1 km, de 1 à 5 km, plus de 5 km.
Quelle est la surface habitable de votre logement : moins de 10 \(m^2\), de 10 \(m^2\) à 20 \(m^2\), de 20 \(m^2\) à 30 \(m^2\), plus de 30 \(m^2\).
Nous pouvons observer que trois des cinq variables sont issues de variables quantitatives discrétisées avant la réalisation du sondage. Vu le nombre total élevé de modalités (20), nous ne représentons pas ici le contenu du TDC ou du tableau de Burt.
Pour réaliser l’ACM on cherche, comme pour l’ACP, le sous-espace de dimension \(k\) qui résume le mieux la variance (on parle parfois de « dispersion ») du nuage analysé. Comme dans le cas de l’AFCB, on pondère pour l’ACM également chaque modalité (représentée par une colonne du TDC) par sa fréquence relative. Des développements plus détaillés peuvent être trouvés par ex. dans [CABB04], [Sap11].
L’objectif principal de l’ACM étant l’interprétation à partir des projections des modalités (et, parfois, des observations en faisant appel à la représentation simultanée) sur les axes factoriels, le nombre d’axes à retenir est choisi en utilisant le critère du « coude ».
L’interprétation des résultats d’une ACM est faite à partir des proximités et des oppositions entre projections de modalités de variables différentes ou d’une même variable. Deux modalités de variables différentes sont similaires (leurs projections sont proches) si ces modalités concernent les mêmes populations d’observations, c’est à dire la plupart des observations qui possèdent une de ces modalités possèdent également l’autre. Deux modalités d’une même variable sont par définition mutuellement exclusives. Elles peuvent néanmoins apparaître comme « similaires » (leurs projections sur les axes factoriels retenus sont proches) si leurs populations sont similaires par rapport aux autres variables nominales, c’est à dire possèdent en général les mêmes modalités pour les autres variables.
Il est important de noter que le centre de gravité des modalités d’une même variable se confond avec le centre de gravité du nuage de toutes les modalités. Aussi, plus une modalité est rare, plus elle est éloignée du centre de gravité.
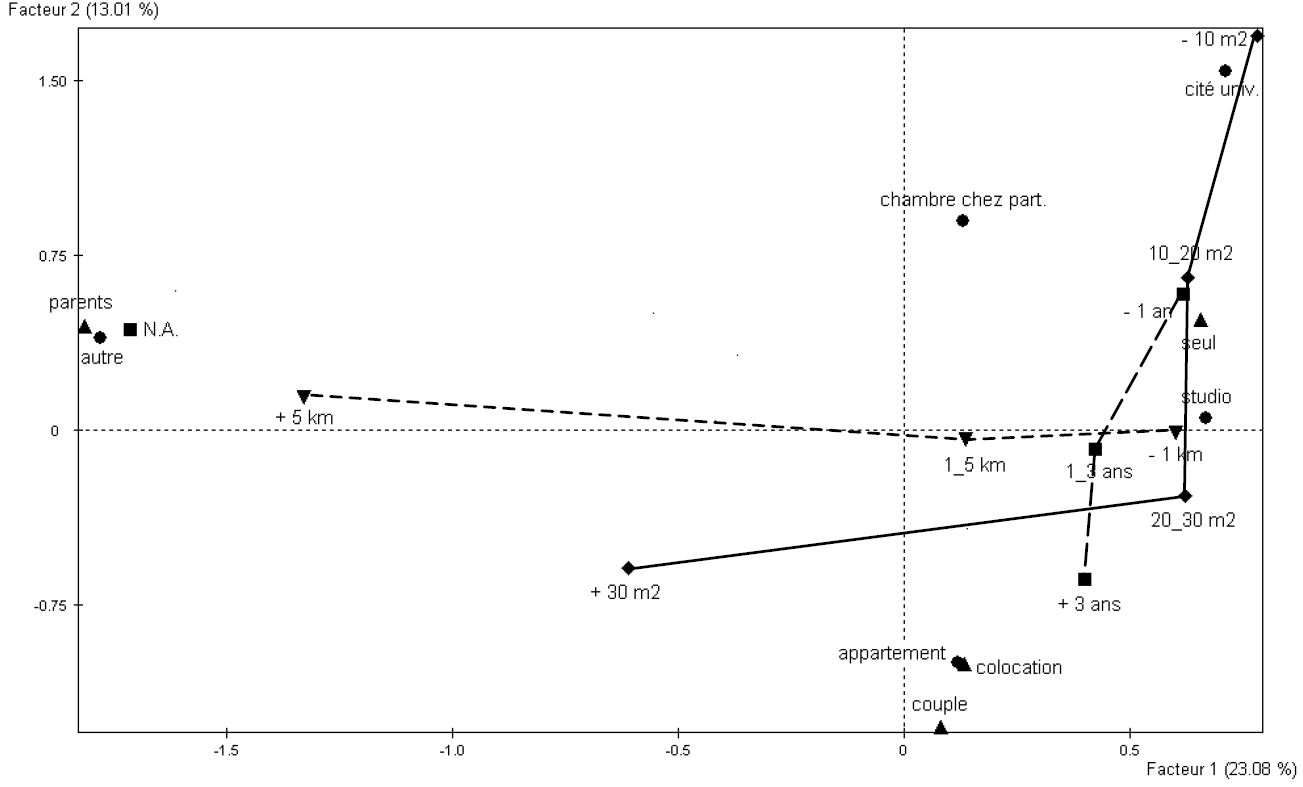
La Fig. 47 présente les projections sur les deux premiers axes factoriels des modalités des cinq variables que nous avons retenues de l’enquête « Les étudiants et la ville » [5].
Fig. 47 Les étudiants et la ville [5] : projections des modalités sur les deux premiers axes factoriels¶
Sur cet exemple nous pouvons constater des similarités fortes entre les modalités « parents » (variable « Habitez-vous »), « NA » (variable « depuis combien de temps ») et « autre » (variable « type d’habitation »), ainsi que des oppositions fortes entre « seul » et « parents » (même variable « Habitez-vous »), ou entre « +5 km » et « -1 km » (variable « distance »).
Pour améliorer la lisibilité et faciliter l’interprétation, les modalités « successives » des variables nominales ordinales (issues ici de la discrétisation préalable de variables quantitatives) ont été reliées entre elles par des traits. Cette discrétisation et l’emploi de l’ACM permettent de mettre en évidence des relations non linéaires entre intervalles de variation de variables quantitatives initiales. Dans l’exemple considéré ici, nous pouvons constater que la variable « distance » est corrélée (le long du premier axe factoriel) à la variable « surface habitable » sur une partie seulement du domaine de variation de celle-ci, alors que sur l’autre partie de son domaine de variation la variable « surface habitable » est plutôt corrélée à la variable « depuis combien de temps » (le long du deuxième axe factoriel). De telles relations ne peuvent pas être mises en évidence par une analyse linéaire directe (par ex. avec une ACP) des variables quantitatives de départ.
Afin d’inclure une variable quantitative dans l’ACM, le domaine de variation de la variable est découpé en intervalles et chaque intervalle est assimilé à une modalité de variable nominale. Cela permet de trouver des relations entre modalités de variables nominales (ou qualitatives) et intervalles de valeurs prises par des variables quantitatives. Cela donne aussi la possibilité de mettre en évidence des relations non linéaires entre (intervalles de) valeurs prises par des variables quantitatives, comme nous l’avons vu dans l’interprétation de la Fig. 47.
Le découpage en intervalles du domaine de variation d’une variable quantitative peut être réalisé à partir de différents critères :
Sur la base de connaissances a priori concernant les intervalles « pertinents ». Par exemple, les étudiants changent rarement de logement pendant l’année scolaire. Aussi, dans une ville de taille moyenne, une chambre en cité universitaire a en général une superficie de moins de moins de 10 \(m^2\), une chambre chez l’habitant une superficie de 12-15 \(m^2\) et un appartement en collocation 25-30 \(m^2\).
Lorsque le découpage est fait en amont du recueil de données à travers par ex. un questionnaire, il faut tenir compte du fait que les répondants ne peuvent pas fournir une réponse exacte (par ex. pour répondre à la question « à quelle distance de la fac vivez-vous »). Il est nécessaire de discrétiser de façon suffisamment grossière le domaine de variation pour que le choix par le répondant d’un intervalle soit fiable.
A partir de l’histogramme des valeurs, comme dans la Fig. 48. Pour un découpage robuste, les frontières entre intervalles sont choisies dans les creux de l’histogramme. Cela permet d’améliorer la stabilité du découpage (et donc des résultats de l’ACM) par rapport aux erreurs de mesure (ou d’appréciation) de la variable quantitative avant discrétisation. Chaque intervalle ainsi obtenu est une modalité de la nouvelle variable ordinale ; les valeurs numériques étant ordonnées, les intervalles le sont donc aussi et donc la variable nominale résultante est une variable ordinale.
Fig. 48 Découpage en intervalles du domaine de variation d’une variable quantitative à partir de l’histogramme des valeurs¶
L’AFD est une méthode d’analyse de données multidimensionnelles qui présente à la fois une composante descriptive et une composante décisionnelle. On considère \(n\) observations caractérisées par \(d\) variables quantitatives initiales (matrice de données \(\mathbf{X}\)) et une variable nominale de « classe » \(Y \in \{1,\ldots,q\}\) (le nombre de classes est donc \(q\)). Lors de l’étape descriptive on cherche à identifier \(k\) « facteurs discriminants » (\(k < d\), \(k < q\) !) qui permettent de différencier au mieux les classes ; ces facteurs discriminants sont des combinaisons linéaires des variables initiales. Lors de l’étape décisionnelle on construit un modèle de discrimination (ou de classement) permettant de décider à quelle classe affecter une nouvelle observation à partir des valeurs prises par les variables quantitatives (donc implicitement par les facteurs discriminants).
Les principales utilisations de l’AFD sont :
Descriptive : condenser la représentation des données en conservant au mieux la séparation entre les classes.
Décisionnelle : classer de nouvelles observations à partir du sous-espace linéaire qui optimise la séparation.
Nous nous intéresserons ici principalement à la composante descriptive. Plus d’explications sur l’AFD (à la fois sur les aspects descriptifs et décisionnels) peuvent être trouvées par ex. dans [CABB04], [Sap11].
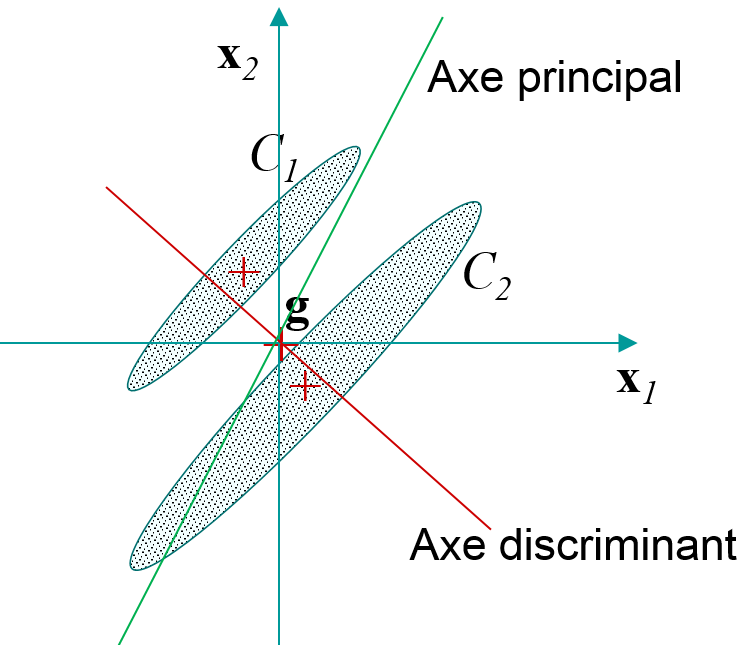
Il est utile de clarifier tout de suite la différence entre l’ACP et l’AFD. La Fig. 49 montre un exemple simple de deux classes \(C_1\) et \(C_2\) de forme allongée dans le plan. Les observations (représentées par les points à l’intérieur de chaque ellipse) sont décrites par deux variables quantitatives (les coordonnées dans le plan) et appartiennent à l’une ou l’autre des deux classes. L’ACP ignore l’information de classe (la variable nominale) et cherche le sous-espace (unidimensionnel ici) qui maximise la variance des projections sur le premier axe factoriel (l’axe principal). L’AFD tient compte de l’information de classe et cherche le sous-espace (unidimensionnel ici aussi) qui maximise la séparation entre les classes, c’est à dire la séparation entre les projections sur le premier axe factoriel (l’axe discriminant) des observations appartenant aux deux classes.
Fig. 49 Axe discriminant et axe principal pour un exemple simple¶
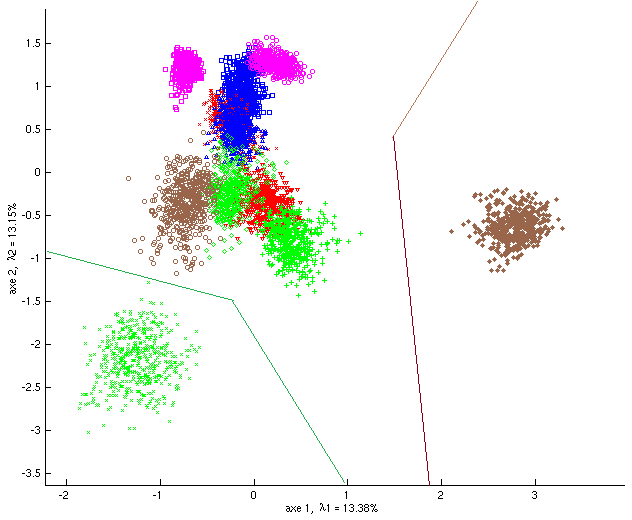
Revenons à l’exemple des données « textures » (voir Exemple : données « textures ») issues de [2], dans lequel \(n = 5500\) observations (pixels, dans ce cas) sont décrites par \(d = 40\) variables quantitatives initiales plus une variable nominale « classe » qui possède 11 modalités (il y a 11 classes de pixels), et appliquons l’ACP et l’AFD. La Fig. 50 montre la projection des observations sur les 2 premiers axes principaux et la Fig. 51 la projection des observations sur les 2 premiers axes discriminants.
Fig. 50 Exemple « textures » : projection des observations sur les 2 premiers axes principaux (ACP)¶
Fig. 51 Exemple « textures » : projection des observations sur les 2 premiers axes discriminants (AFD)¶
En comparant les résultats des deux projections on constate que la séparation entre les classes est naturellement bien meilleure avec l’AFD. On voit aussi que cette séparation entre les 11 classes n’est pas parfaite entre les projections sur le premier plan discriminant ; la séparation est en revanche presque parfaite dans l’espace tridimensionnel défini par les trois premières composantes discriminantes (non représenté ici).
Pour trouver le sous-espace de dimension \(k\) le plus discriminant on cherche à séparer au mieux les centres de gravité des classes, tout en tenant compte de la forme des classes.
Afin de comprendre de quelle façon l’AFD procède il est nécessaire de s’intéresser aux calculs des covariances entre les variables initiales, selon qu’on considère les données dans leur totalité ou séparées en classes :
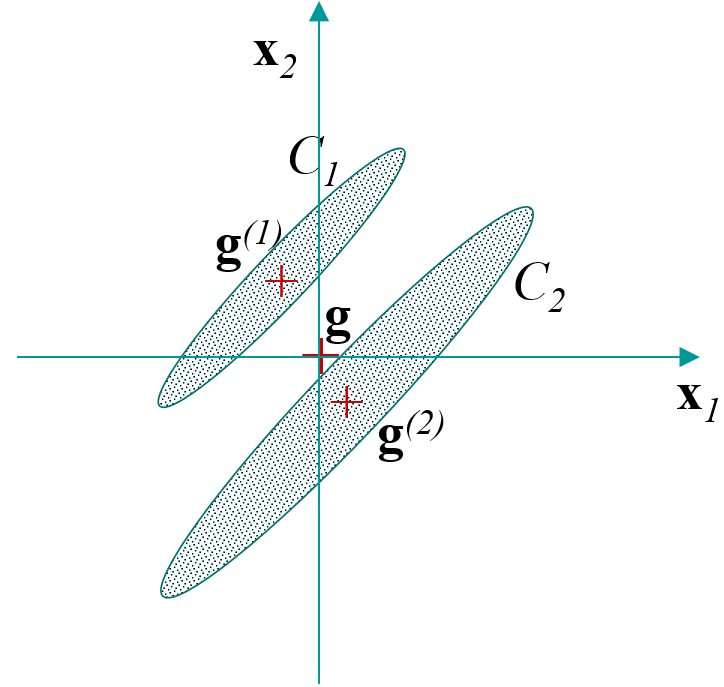
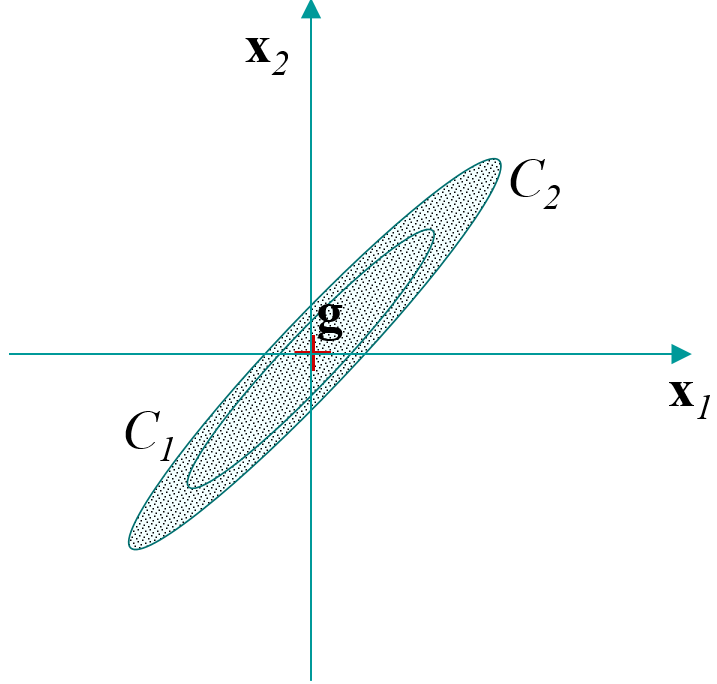
Covariances totales : calculées sur les observations de départ, centrées (le centre de gravité du nuage des observations coïncide avec l’origine des axes, voir la Fig. 52). Résulte la matrice \(\mathbf{S}\) des covariances totales, la même que celle employée pour l’analyse du nuage des observations dans l’ACP centrée.
Covariances inter-classes : calculées en considérant que les seules observations sont les centres de gravité des \(q\) classes (voir la Fig. 53). Résulte la matrice \(\mathbf{E}\) des covariances inter-classes.
Covariances intra-classes : calculées sur les observations de départ, après avoir centré chaque classe (voir la Fig. 54). Résulte la matrice \(\mathbf{D}\) des covariances intra-classes.
Ces matrices de covariances sont liées par la relation de Huygens \(\mathbf{S} = \mathbf{E} + \mathbf{D}\).
Afin de mieux séparer les centres de gravité des classes, il est possible d’appliquer une ACP sur le nuage des centres de gravité des classes. Cela reviendrait à chercher les vecteurs propres associés aux plus grandes valeurs propres de \(\mathbf{E}\), c’est à dire à résoudre l’équation de valeurs et vecteurs propres \(\mathbf{E} \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{u}_{\alpha}\). Mais cette solution ne tiendrait pas compte de la forme du nuage (ou des classes), qui doit avoir un impact sur le choix du sous-espace discriminant comme nous pouvons facilement le constater en examinant la Fig. 52 dans laquelle on tournerait les ellipses qui représentent les classes.
Comme nous l’avons vu plus haut pour l’ACP, la variance des projections des observations sur le vecteur \(\mathbf{u}\) est \(\mathbf{u}^T \mathbf{S} \mathbf{u}\). De la même façon, la variance des projections des centres de gravité des classes sur ce même vecteur \(\mathbf{u}\) est \(\mathbf{u}^T \mathbf{E} \mathbf{u}\). L’analyse factorielle discriminante (AFD) cherche comme premier axe discriminant le vecteur \(\mathbf{u}\) qui maximise le rapport \(\lambda = \frac{\mathbf{u}^T \mathbf{E} \mathbf{u}}{\mathbf{u}^T \mathbf{S} \mathbf{u}}\) (et non simplement \(\mathbf{u}^T \mathbf{E} \mathbf{u}\)).
Pour \(k \geq 1\), on peut montrer (voir par ex. [CABB04], [Sap11]) que le sous-espace discriminant recherché est généré par les \(k\) vecteurs propres \(\mathbf{u}_{\alpha}\) associés aux \(k\) plus grandes valeurs propres \(\lambda_{\alpha}\) de l`équation de valeurs et vecteurs propres généralisée
Il est possible de résoudre (20) plutôt que (18) si le rang de \(\mathbf{D}\) n’est pas inférieur à celui de \(\mathbf{S}\). Nous remarquerons que le rang de \(\mathbf{D}\) ne peut pas être supérieur à celui de \(\mathbf{S}\), voir la solution du premier exercice.
Il est important de remarquer que la matrice \(\mathbf{S}^{-1} \mathbf{E}\) n’est pas symétrique en général, bien que les matrices \(\mathbf{S}^{-1}\) et \(\mathbf{E}\) soient symétriques. En conséquence, comme vecteurs propres associés à des valeurs propres différentes, les axes factoriels discriminants ne sont pas orthogonaux. Cela doit être pris en compte lors de la représentation graphique des projections des observations sur les axes factoriels.
Pour une meilleure compréhension de l’AFD il est également utile de remarquer que si la matrice des covariances totales est la matrice identité (variances identiques et covariances nulles), \(\mathbf{S} = \mathbf{I}_d\), alors (18) devient simplement \(\mathbf{E} \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{u}_{\alpha}\), ce qui signifie que les axes discriminants recherchés sont les axes principaux de l’analyse en composantes principales du nuage des centres de gravité des classes.
Lorsque la matrice \(\mathbf{S}\) n’est pas inversible (est singulière), une approche fréquente est de réduire la dimension des observations avec une ACP, pour que dans l’espace réduit la nouvelle matrice des covariances empiriques \(\mathbf{S}'\) soit inversible (ou de rang complet), pour ensuite résoudre \({\mathbf{S}'}^{-1} \mathbf{E}' \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{u}_{\alpha}\) dans cet espace réduit.
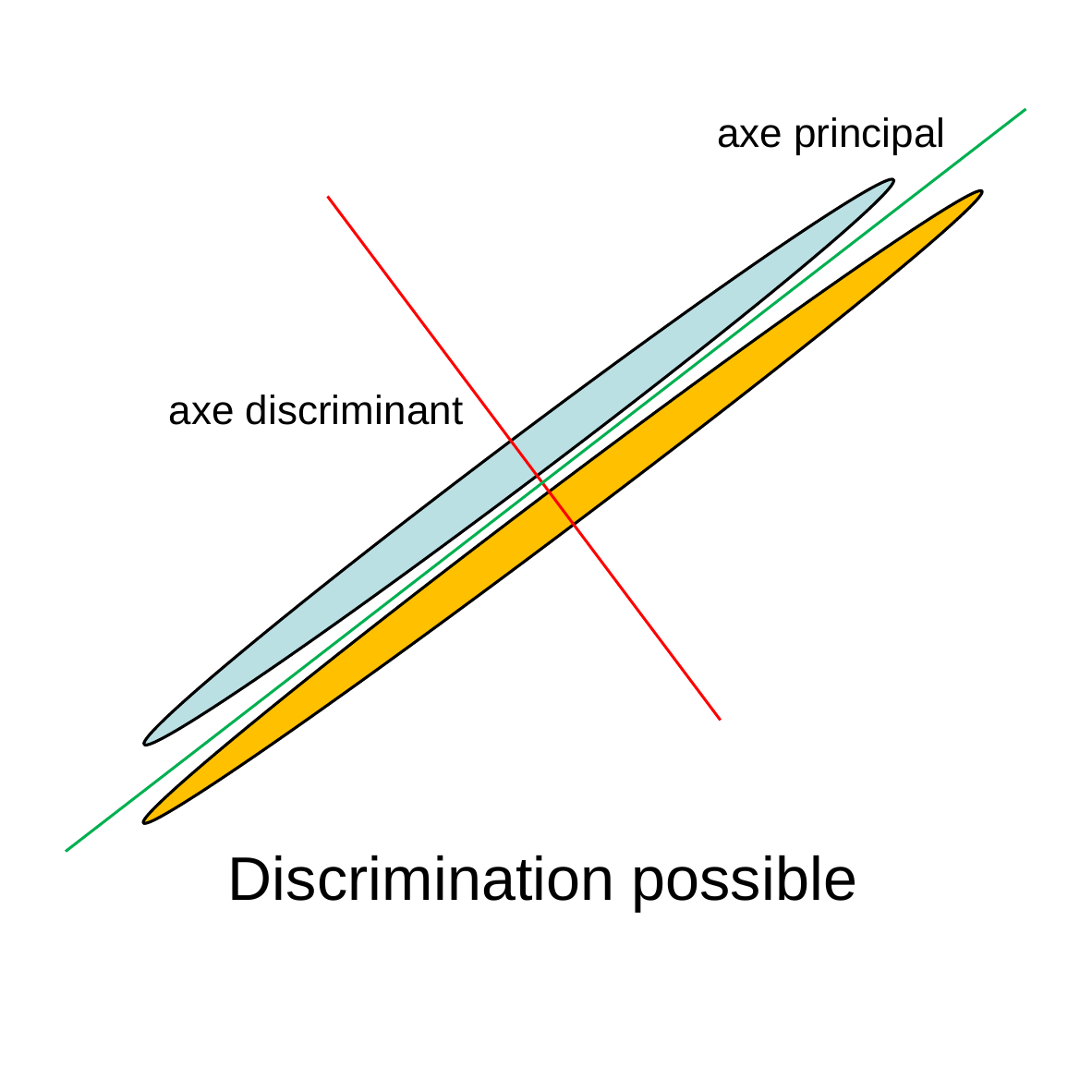
Lorsque la matrice \(\mathbf{S}\) est inversible mais mal conditionnée, c’est à dire \(\frac{\|\lambda_{\max}\|}{\|\lambda_{\min}\|} > \theta\) (la borne \(\theta\) dépend de la précision de représentation et de l’algorithme d’inversion employé), \(\lambda_{\min} > 0\), lors de son inversion l’imprécision est amplifiée de façon excessive. Une première solution est de réduire la dimension avec une ACP pour rendre dans l’espace réduit \(\mathbf{S}'\) bien conditionnée (et non seulement inversible). Malheureusement, il y a dans ce cas un risque important d’élimination de variables discriminantes, comme l’indiquent les Fig. 55 et Fig. 56.
Fig. 55 Dans l’espace de départ, la discrimination entre les deux classes est possible mais la matrice \(\mathbf{S}\) est assez mal conditionnée¶
Fig. 56 Après projection sur l’axe principal, la discrimination entre les deux classes devient impossible¶
Il faudrait préférer dans ce cas une approche de régularisation, par exemple remplacer \(\mathbf{S}\) par \(\mathbf{S} + r \mathbf{I}_m\) (où \(\mathbf{I}_m\) est la matrice identité d’ordre \(m\)). La constante de régularisation \(r > 0\) doit être assez grande pour que la matrice \(\mathbf{S} + r \mathbf{I}_m\) soit bien conditionnée (\(\frac{\|\lambda_{\max}\| + r}{\|\lambda_{\min}\| + r} < \theta\)), mais pas trop grande, pour éviter de dénaturer la solution.
Il est important de noter que pour l’AFD le nombre \(k\) d’axes factoriels (ou facteurs discriminants) est au maximum égal à \(q - 1\), \(q\) étant le nombre de classes. En effet, avec \(q\) classes, le rang de la matrice des covariances inter-classes \(\mathbf{E}\) ne peut être supérieur à \(q-1\) car les « observations » qui permettent de calculer \(\mathbf{E}\) sont les centres de gravité des classes. Or, \(q\) points (les centres de gravité des \(q\) classes) définissent un sous-espace linéaire de dimension \(q-1\) (par exemple, 2 points non confondus définissent une droite, 3 points non colinéaires définissent un plan, etc.). En conséquence, l’équation \(\mathbf{E} \mathbf{u}_{\alpha} = \lambda_{\alpha} \mathbf{S} \mathbf{u}_{\alpha}\) ne peut avoir plus de \(q-1\) valeurs propres non nulles. Par exemple, pour un problème à 2 classes on ne peut trouver qu’un seul axe discriminant (\(k = 1\)), quel que soit le nombre \(d\) de variables quantitatives décrivant les observations.
Si le nombre de classes est suffisamment élevé pour permettre à \(k\) d’être élevé, le choix du nombre de composantes discriminantes à retenir (valeur de \(k\)) peut être réalisé par différentes méthodes.
Lorsqu’il est possible de considérer que les classes sont issues de lois normales multidimensionnelles, différents tests statistiques peuvent être employés et sont proposés par certains logiciels :
Test de Rao : test d’égalité à 0 de la \(i\)-ème valeur propre.
Test du lambda de Wilks : test de l’apport des axes factoriels au-delà du \(i\)-ème.
Test incrémental : test de l’apport du \(i+1\)-ème axe factoriel.
Si l’AFD est employée comme un prétraitement avant application de méthodes décisionnelles, il est également possible de considérer le nombre d’axes (de facteurs discriminants) comme un paramètre supplémentaire de la méthode décisionnelle et de se servir ensuite d’une technique de sélection de modèle décisionnel pour choisir le nombre d’axes. La méthode de l’échantillon-test, par exemple, consiste à
Extraire par tirages aléatoires un échantillon-test (un sous-ensemble d’observations) à partir des \(n\) observations disponibles.
Répéter, pour différentes valeurs du nombre d’axes : (i) appliquer l’AFD sur les données restantes, (ii) développer le modèle décisionnel sur ces mêmes données, (iii) évaluer le modèle décisionnel sur l’échantillon-test.
Choisir les paramètres (dont nombre d’axes de l’AFD) qui donnent le meilleur résultat sur l’échantillon-test.
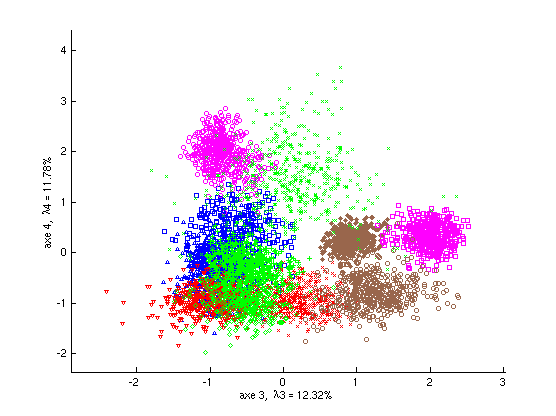
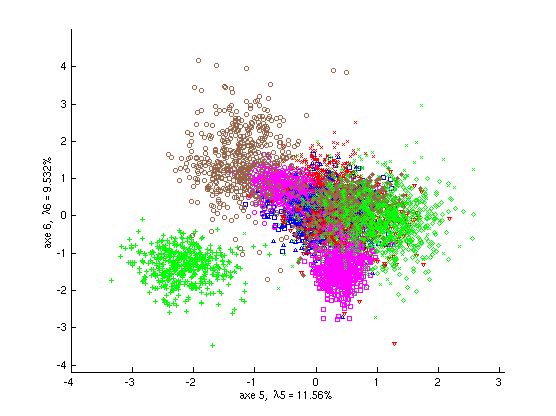
La capacité de discrimination des axes factoriels successifs diminue progressivement, comme le montrent la Fig. 57 (projections sur les axes 3 et 4) et la Fig. 58 (projections sur les axes 5 et 6) pour les données « textures » (à comparer avec les projections sur les axes 1 et 2, Fig. 51).
Fig. 57 Exemple « textures » : projection des observations sur les axes discriminants 3 et 4¶
Fig. 58 Exemple « textures » : projection des observations sur les axes discriminants 5 et 6¶
L’AFD n’est pas seulement une méthode d’analyse des données mais peut servir aussi à la construction de modèles décisionnels. Un modèle décisionnel doit permettre de classer une nouvelle observation dans une des \(q\) classes sur la base des valeurs des variables explicatives (les \(d\) variables quantitatives initiales) pour cette observation.
Nous présentons ici seulement une ébauche de cette étape décisionnelle, des détails peuvent être trouvés par ex. dans [CABB04], [Sap11].
Le modèle décisionnel consiste en une règle d’affectation d’une nouvelle observation à une des classes. Ici, on affecte l’observation à la classe la plus proche. Pour déterminer la distance entre une observation et chacune des classes il est nécessaire d’appliquer d’abord l’étape descriptive de l’AFD, permettant de trouver le sous-espace discriminant, et ensuite de projeter à la fois les observations initiales (pour lesquelles la classe d’appartenance est connue) et les nouvelles observations (pour lesquelles la classe d’appartenance est inconnue) sur ce sous-espace discriminant.
La distance entre une nouvelle observation et une classe est calculée comme la distance entre l’observation et le centre de gravité de la classe (dans le sous-espace discriminant). Deux choix différents sont couramment employés pour la métrique (la mesure de distance) :
Une même métrique par rapport à toutes les classes, donnée par la matrice \(\mathbf{S}'^{-1}\) (matrice des covariances empiriques calculée à partir des projections des observations initiales dans le sous-espace discriminant). En résultent des frontières linéaires entre les classes considérées deux à deux. Les frontières finales sont ainsi linéaires par morceaux, comme dans l’exemple donné dans la Fig. 59.
Une métrique spécifique à chaque classe (donnée en général par l’inverse de la matrice de covariance intra-classe de la classe). Dans ce cas on obtient plutôt des frontières quadratiques entre les classes considérées deux à deux (frontières finales quadratiques par morceaux).
Fig. 59 Exemple des textures : frontières de discrimination pour deux des classes dans le plan des deux premiers axes discriminants¶
Crucianu, M., J.-P. Asselin de Beauville, et R. Boné. Méthodes d’analyse factorielle des données : méthodes linéaires et non linéaires. Hermès, Paris, 2004.