Les informations concernant le déroulement de l’unité d’enseignement RCP208 « Apprentissage statistique : modélisation descriptive et introduction aux réseaux de neurones » au Cnam se trouvent dans ce préambule.
« Essentially, all models are wrong, but some are useful. »
(Box, G. E. P., and Draper, N. R. Empirical Model Building and Response Surfaces, John Wiley & Sons, New York, NY, 1987, p. 424.)
Des données en nombre toujours plus grand sont de plus en plus facilement accessibles. Que pouvons-nous en faire ? Comment bien les utiliser pour répondre à nos besoins ? Cela passe, en général, par des étapes d’analyse des données afin de mieux les comprendre et des étapes de modélisation afin de mieux les décrire et les utiliser. Les approches et méthodes à mettre en œuvre ont été développées principalement dans deux domaines qui présentent de nombreux points de rencontre, la reconnaissance des formes et la fouille de données.
La « reconnaissance des formes » (pattern recognition) a pour objectif d’identifier à quelle « catégorie » appartient une « forme » décrite par des données brutes. Par « forme » on entend ici les valeurs prises par certaines variables. Par exemple, une « forme » peut être constituée par les valeurs prises à un moment donné par les variables qui décrivent l’état clinique d’un patient, les catégories à trouver étant « présence de maladie X » et « absence de maladie X ». Une « forme » peut être aussi, par exemple, une partie d’une image, les catégories à déterminer étant « véhicule » et « non véhicule ».
La « fouille de données » (data mining) cherche à trouver, dans de grands volumes de données, des « régularités » ou des relations inconnues a priori et potentiellement utiles. Par exemple, des similarités entre les réactions en ligne d’une partie des utilisateurs d’un réseau social.
Dans ce cours nous nous intéressons à des méthodes d’analyse des données et de modélisation descriptive ou décisionnelle à partir de données. Ces méthodes sont en général employées aussi bien dans la reconnaissance des formes que dans la fouille de données. La suite naturelle de ce cours (unité d’enseignement Cnam RCP209) approfondit l’étude de la modélisation décisionnelle.
Ce cours présente les éléments de base des méthodes d’analyse de données et de modélisation à partir des données. Plus précisément, nous cherchons à vous permettre de
Examiner et comprendre les (caractéristiques des) données, notamment à travers les analyses factorielles ou la réduction non-linéaire de dimension, méthodes qui fournissent également des moyens de visualisation.
Comprendre les différents types de problèmes posés par les données et les idées sur lesquelles sont basées les solutions à ces problèmes.
Obtenir des modèles descriptifs des données par des méthodes de classification automatique, d’estimation de densités, de réduction de dimension, de sélection de variables.
Construire des modèles décisionnels (ou prédictifs) notamment par des perceptrons multi-couches ; d’autres méthodes (dont les forêts d’arbres de décision, les SVM, les réseaux de neurones profonds) sont examinées ultérieurement dans l’unité d’enseignement RCP209.
Savoir mettre œuvre des méthodes d’analyse des données, de reconnaissance des formes et de fouille de données, grâce notamment aux travaux pratiques qui emploient l’environnement logiciel http://scikit-learn.org en Python.
Le contenu détaillé de cet enseignement (RCP208), avec indication du nombre de séances de cours et TP par chapitre, est :
Introduction : exemples d’applications, nature des problèmes de modélisation, nature des difficultés posées par les données, types de variables et leur représentation. TP associés : introduction à Python et scikit-learn, éventuellement installation assistée. (2 séances)
Méthodes factorielles (analyse en composantes principales, analyse des correspondances multiples, analyse factorielle discriminante) dans le contexte plus large de l’analyse des données et de la réduction de dimension. TP associés : ACP, AFD. (2 séances)
Classification automatique : k-means (avec initialisation k-means++), DBSCAN, validation de la classification automatique. TP : k-means, DBSCAN. (2 séances)
Estimation de densités : histogrammes, noyaux de Parzen, modèles de mélanges, espérance-maximisation (EM). TP associés : noyaux de Parzen, estimation de modèles de mélanges. (2 séances)
Imputation des données manquantes : spectre des méthodes. TP associés : imputation avec Scikit-learn. (1 séance)
Sélection de variables. TP associé : sélection de variables. (1 séance)
Réseaux de neurones multi-couches : architectures, capacités d’approximation, apprentissage et régularisation, explicabilité. TP associés : réseaux de neurones multi-couches en discrimination et régression. (3 séances)
De nombreuses références, sous forme imprimée ou sur le Web, traitent les différents sujets abordés dans cet enseignement. Certaines références vous seront également indiquées dans les séances de cours et de TP. Nous avons listé ci-dessous des ouvrages qui couvrent des parties plus larges du contenu de cet enseignement.
Azencott, C.-A. Introduction au Machine Learning. Dunod, juillet 2019, 240 p.
Géron, A. Machine Learning avec Scikit-Learn : mise en œuvre et cas concrets. Dunod, novembre 2019, 320 p.
Crucianu, M., J.-P. Asselin de Beauville, R. Boné, Méthodes factorielles pour l’analyse des données : méthodes linéaires et extensions non-linéaires. Hermès, 2004, 288 p.
Saporta, G., Probabilités, analyse des données et statistique. 622 p., Éditions Technip, Paris, 2006.
Dans une démarche de modélisation à partir de données, si l’analyse et la description des données sont des étapes importantes, l’objectif final est en général la construction de modèles décisionnels. Pour mieux appréhender les problèmes posés par la modélisation décisionnelle, examinons de plus près (mais néanmoins de façon simplifiée) un exemple qu’est la détection d’objets.
Détecter un objet (ou une instance d’une catégorie d’objets, par ex. « véhicule ») dans une image consiste à signaler si l’image contient (ou non) une vue de l’objet. La localisation de l’objet permet en plus de délimiter la région de l’image correspondant à la vue de l’objet. Dans la suite nous considérons que, pour détecter et localiser un objet dans une image, l’outil de détection déplace une « fenêtre » sur l’image et indique, pour chaque position et taille de la fenêtre, si son contenu est une vue de l’objet. Il faut noter que d’autres approches existent, par ex. pour détecter des objets en mouvement dans une vidéo il suffit de considérer les régions en mouvement, faciles à trouver par un traitement de bas niveau. Ou alors, un réseau de neurones profond (ces réseaux sont étudiés dans l’UE RCP209) a la capacité à analyser directement le contenu de l’image entière.
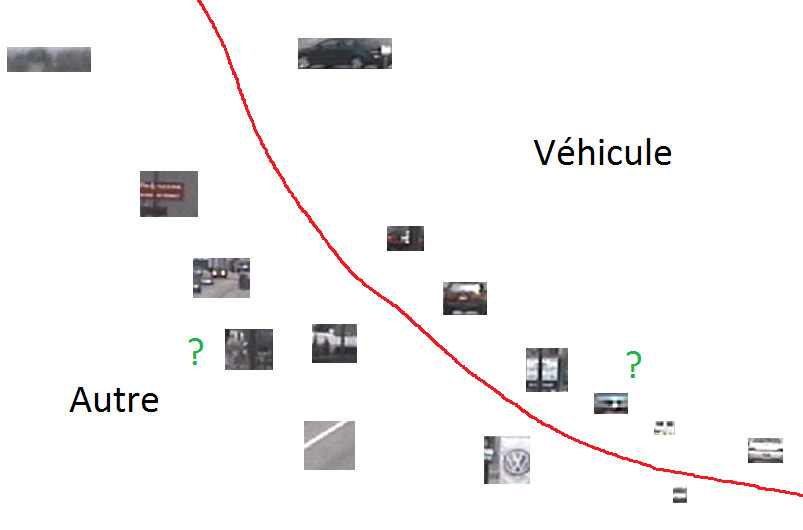
L’illustration suivante (Fig. 1) montre le résultat souhaité pour la détection (avec localisation) de véhicules et aussi de piétons dans une image issue d’une caméra de vidéosurveillance. Pour éviter de surcharger l’image, des rectangles rouges de localisation n’ont pas été dessinés pour toutes les instances de ces catégories d’objets. Nous pouvons observer que les objets appartenant à une certaine catégorie (par ex. « véhicules ») présentent une forte variabilité due à la fois aux différences intrinsèques entre les instances (marque, couleur, type, etc.) et aux différences de représentation dans l’image (taille, point de vue, illumination).
Fig. 1 Illustration de détection (avec localisation) de véhicules et de piétons¶
La seconde illustration (Fig. 2) montre un exemple de résultat obtenu pour la détection (avec localisation) de visages humains vus de face. L’orientation de chaque visage est également estimée à partir de l’image.
Fig. 2 Illustration de détection (avec localisation) de visages¶
Pour chaque position de la fenêtre de détection, le détecteur d’une certaine classe d’objets (par ex. véhicules) reçoit le contenu de la région correspondante de l’image (concrètement, une matrice de pixels) et doit décider s’il affecte cette observation à la classe recherchée ou non. Le détecteur est un modèle décisionnel obtenu à partir d’un ensemble d’observations dites d`apprentissage. Chacune de ces observations consiste en une matrice de pixels (données d’entrée) et une étiquette correspondante de classe (dans l’exemple, « véhicule » ou « non véhicule ») ; ces étiquettes sont des données de supervision. Une fois obtenu, le modèle décisionnel doit être évalué sur des données de test, qui possèdent également l’information de supervision (les étiquettes de classe correspondantes, pour savoir si et quand le modèle se trompe) mais ne font pas partie des données d’apprentissage. Si les performances de détection ainsi obtenues sont jugées satisfaisantes, le modèle décisionnel peut être employé comme détecteur sur de nouvelles observations, qui ne possèdent pas de données de supervision, afin de prendre les décisions d’affectation à une classe (dans l’exemple, à la classe « vehicule » ou à la classe « non véhicule »).
Examinons de façon plus détaillée les grandes étapes de la construction d’un modèle décisionnel. Nous considérons ici le cadre particulier des problèmes de discrimination dans lesquels le modèle doit décider s’il affecte une observation à une classe spécifique (dite « d’intérêt ») ou non. La détection d’objets dans les images, par exemple, fait partie de ce cadre.
Déterminer quelles données devraient permettre de discriminer la classe d’intérêt du reste
Suivant le problème considéré, cette étape peut être plus facile ou plus difficile. Par exemple, pour détecter des véhicules dans les images il est plutôt évident qu’il faut disposer des images en question. Il est déjà moins évident de déterminer les caractéristiques que doivent avoir ces images, et notamment leur résolution (une trop faible résolution limitera les capacités de détection d’objets de faible taille ou de forte complexité visuelle) ou l’utilisation ou non de la couleur (les objets de la classe d’intérêt sont-ils caractérisés par des couleurs spécifiques ou non ?).
Prenons un autre exemple, la détection des utilisateurs qui envisagent de changer de fournisseur d’accès. Il est ici plus difficile de savoir a priori quelles variables peuvent être utiles (lesquelles présentent un bon potentiel explicatif du comportement futur des utilisateurs). Lorsque les observations sont décrites par de très nombreuses variables de nature diverse, faut-il tenter de toutes les employer pour construire le modèle décisionnel ? Comme nous le verrons plus tard, certaines variables peuvent être redondantes, c’est à dire fournir la même information prédictive (ou presque), et cela peut avoir un impact négatif sur certaines méthodes de modélisation décisionnelle. Aussi, d’autres variables n’apportent aucune information prédictive et leur prise en compte peut ainsi agir comme un « bruit » dans le processus de modélisation prédictive. Des techniques de sélection de variables ou de réduction de dimension permettent de diminuer le nombre des variables qui interviennent dans la construction du modèle. Certaines de ces techniques peuvent être appliquées en amont de la construction du modèle, d’autres y sont intégrées. De façon générale, il est utile de chercher à acquérir une bonne connaissance du problème, permettant d’exclure ou d’inclure de façon bien fondée certaines variables du/au processus de modélisation.
Récolter, examiner, nettoyer les données
Les données à partir desquelles on souhaite faire la modélisation ont souvent déjà été récoltées, parfois sans un objectif spécifique de modélisation ; elles peuvent répondre plus ou moins bien aux exigences d’une modélisation particulière. Dans d’autres cas, il est possible de maîtriser le recueil de données et avoir ainsi plus de garanties concernant leurs qualités par rapport à l’objectif de modélisation.
Lorsque les données deviennent disponibles (et, si possible, même pendant l’opération de recueil de données) il est nécessaire d’examiner ces données pour détecter les éventuels problèmes et apporter les corrections éventuellement nécessaires. Par exemple, pour la détection de véhicules, toutes les caméras envisagées fonctionnent-elles normalement ? Les enregistrements numériques sont-ils bien stockés et accessibles ? Les opérateurs qui doivent fournir l’information de supervision (délimiter, sur certaines images, les régions qui représentent des vues de véhicules) ont-ils bien compris les consignes et les appliquent-ils correctement ? La qualité des données (absence de données manquantes, informations de supervision correctes, etc.) a une importance majeure dans le processus de modélisation ultérieur.
Représenter les données de façon adéquate
La représentation de départ des données recueillies dépend en général des processus qui ont permis de produire ces données. Cette représentation n’est pas nécessairement la mieux adaptée au processus de modélisation. Il faut donc souvent passer par de nouvelles représentations, plus adéquates. Une représentation est mieux adaptée si elle permet de séparer plus facilement les observations appartenant à la classe d’intérêt des autres observations. Par exemple, séparer les parties d’image qui montrent un véhicule des parties d’images qui ne montrent pas de véhicule.
Ces représentations peuvent être conçues par un humain (le terme handcrafted est souvent utilisé dans ce cas) ou développées automatiquement (notamment par apprentissage profond). Dans l’exemple de détection de véhicules, il peut être préférable de représenter les matrices de pixels (régions d’images) par les coefficients d’une analyse en ondelettes (représentation handcrafted) ou par le vecteur d’activation d’une certaine couche d’un réseau profond.
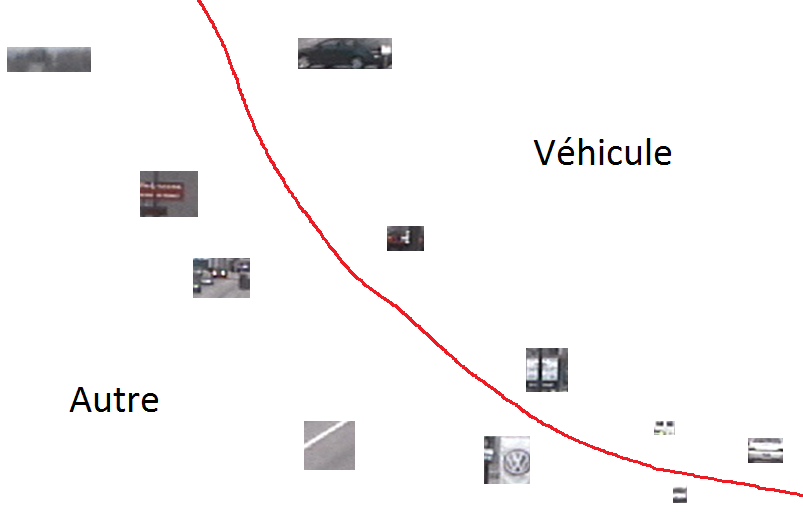
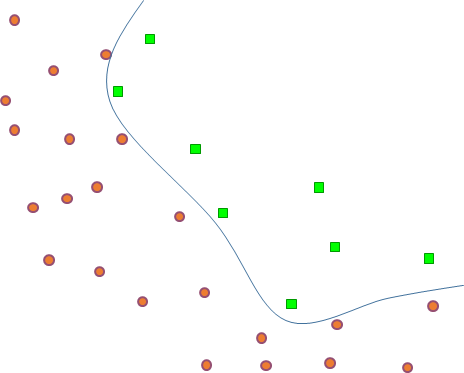
Dans la figure suivante (Fig. 3), des régions d’images montrant ou non un véhicule ont été représentées de façon simplifiée à travers les valeurs de deux variables numériques (des coordonnées dans un plan). Nous nous servirons de cette représentation simplifiée dans la suite pour expliquer les étapes suivantes de la modélisation.
Fig. 3 Détection de véhicules : trouver l’espace de représentation adéquat¶
Modéliser, à partir des données, la frontière de discrimination de la classe d’intérêt
Dans l’espace de représentation trouvé il faut maintenant déterminer un modèle capable de prendre la bonne décision pour chaque observation. Dans certains cas, cette étape n’est pas indépendante de la précédente (par exemple pour les représentations obtenues par apprentissage profond).
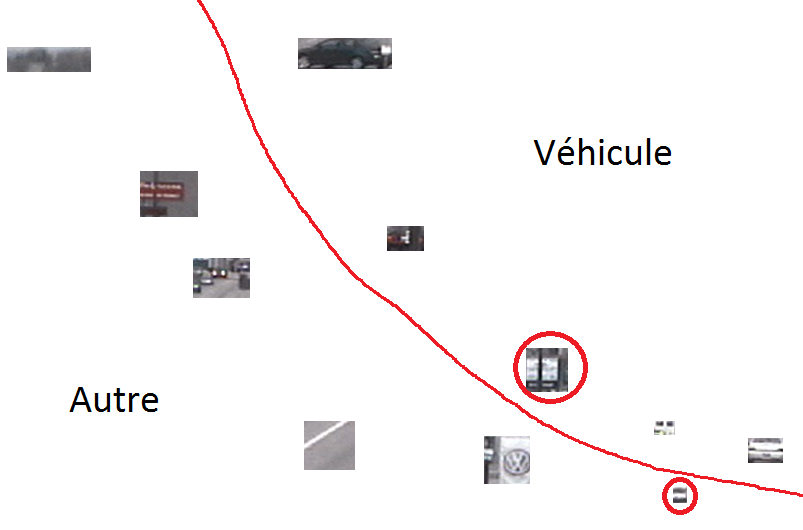
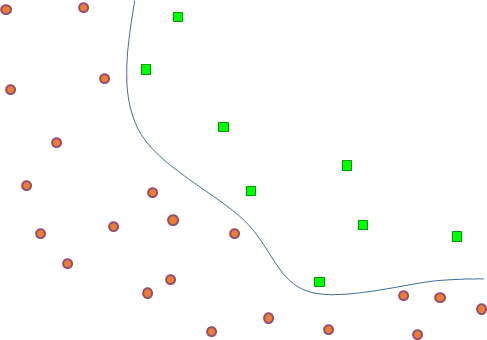
Pour séparer les observations de la classe d’intérêt des observations n’appartenant pas à la classe d’intérêt il faut construire une frontière de discrimination dans l’espace de représentation. Le modèle décisionnel est dans ce cas la frontière de discrimination. Une telle frontière est illustrée dans la figure suivante (Fig. 4) par la courbe rouge qui sépare les régions d’images qui contiennent des véhicules (en haut à droite) des autres régions d’images.
Fig. 4 Détection de véhicules : modéliser, à partir d’observations, le frontière de discrimination¶
Le modèle décisionnel est obtenu à partir de données d`apprentissage qui incluent à la fois des observations de la classe d’intérêt (exemples « positifs ») et des observations n’appartenant pas à la classe d’intérêt (exemples « négatifs »).
Pour trouver le modèle il faut d’abord choisir une ou plusieurs familles de modèles (par ex. les frontières linéaires, les frontières quadratiques, etc.). Ensuite, il est nécessaire de sélectionner une fonction d’erreur (par ex. le taux d’erreur de classement) permettant de caractériser la qualité des décisions individuelles d’un modèle. Enfin, une procédure d’optimisation est appliquée pour obtenir, dans chaque famille de modèles, le modèle qui minimise la fonction d’erreur.
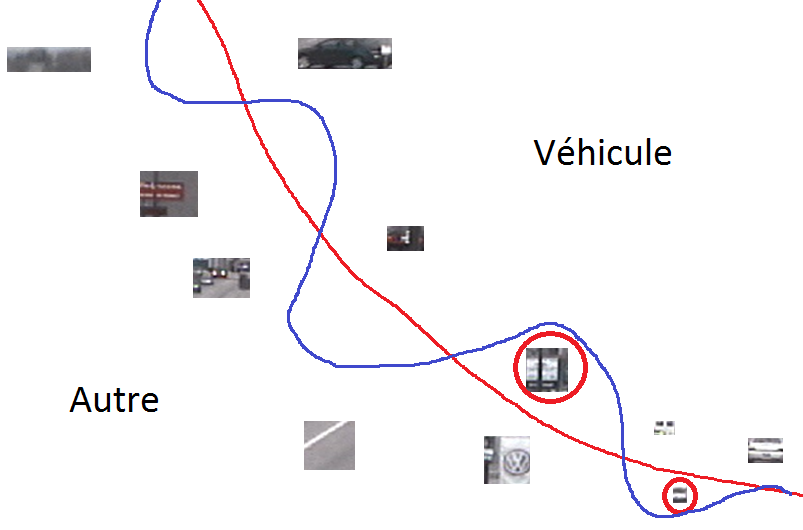
Suivant la famille de modèles choisie, il est possible que l’optimisation des paramètres n’arrive pas à réduire l’erreur sur les données d’apprentissage (erreur d’apprentissage) en-dessous d’une valeur strictement positive. Pour un problème de discrimination cela signifie que certaines données d’apprentissage restent mal classées par le modèle (de la famille) qui minimise la fonction d’erreur. La figure suivante (Fig. 5) montre un cas où la famille choisie contient des frontières lisses et le modèle (la frontière) final(e) ne classe pas correctement deux des données d’apprentissage.
Fig. 5 Détection de véhicules : erreurs du modèle (frontière de discrimination) sur les données d’apprentissage¶
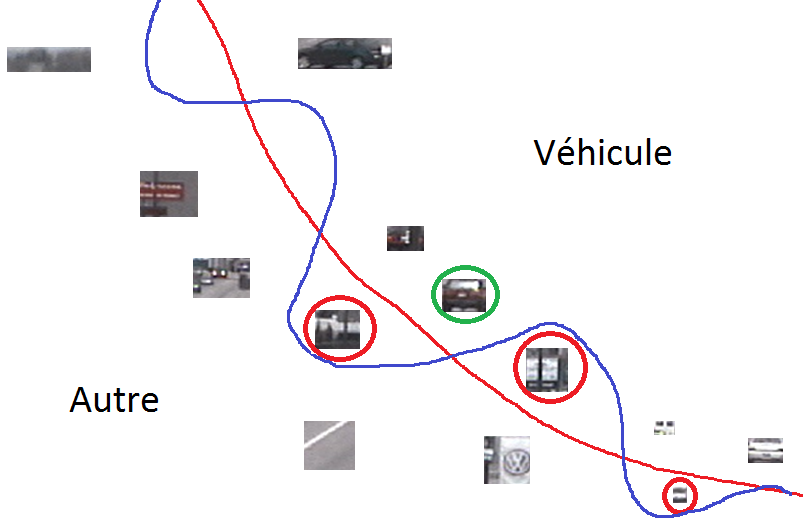
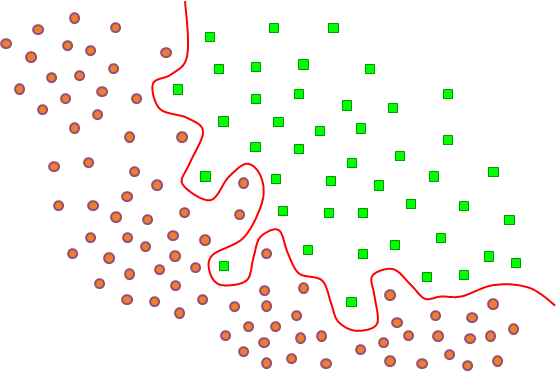
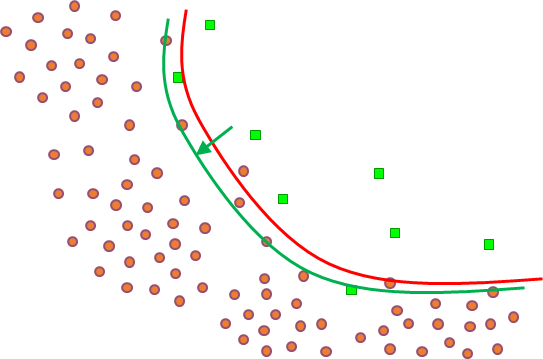
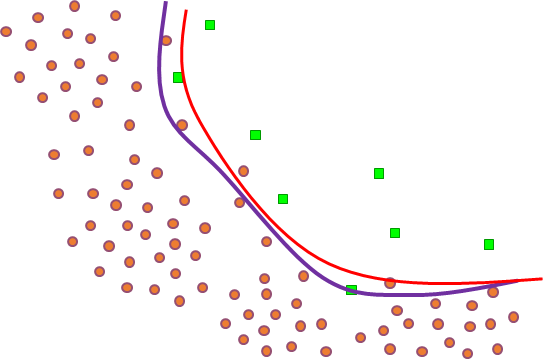
En choisissant une autre famille de modèles, plus « large », il est en général possible de trouver un modèle pour lequel l’erreur d’apprentissage est encore plus faible, voire nulle. Par exemple, en considérant des frontières moins lisses (qui peuvent avoir des « ondulations » de plus forte amplitude) il est possible d’obtenir la frontière représentée en bleu dans la figure suivante (Fig. 6), qui classe correctement toutes les données d’apprentissage (l’erreur d’apprentissage est nulle).
Fig. 6 Détection de véhicules : un modèle plus complexe permet de réduire encore l’erreur d’aprentissage¶
Faut-il préférer la première frontière (le premier modèle), moins complexe mais qui fait plus d’erreurs sur les données d’apprentissage, ou la seconde frontière (le second modèle), plus complexe mais qui fait moins (ou pas) d’erreurs d’apprentissage ? En général, ce ne sont pas les performances sur les données d’apprentissage qui permettent de répondre à cette question. En effet, estimer les performances futures d’un modèle à partir des performances obtenues sur les données d’apprentissage donnerait un résultat trop optimiste, car c’est précisément sur ces données que le modèle a été choisi par la procédure d’optimisation. Vous verrez dans RCP209 que l’existence de bornes de généralisation peut éventuellement permettre d’estimer les performances sur de nouvelles données à partir des performances sur les données d’apprentissage.
Pour que le résultat de l’évaluation soit plus représentatif des performances futures, il est nécessaire de faire cette évaluation sur d’autres données, qui n’ont pas été utilisées pour l’apprentissage. Les données employées pour choisir parmi plusieurs modèles, chacun obtenu par apprentissage et appartenant à une famille différente de modèles, sont souvent appelées données de validation.
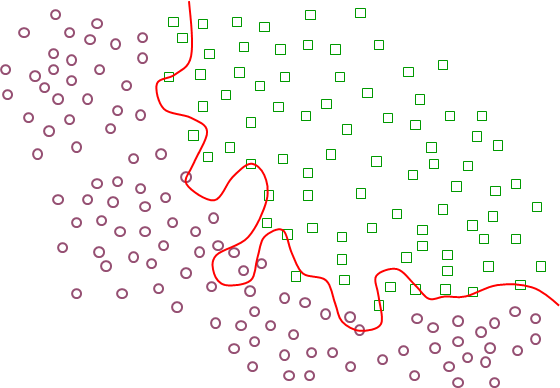
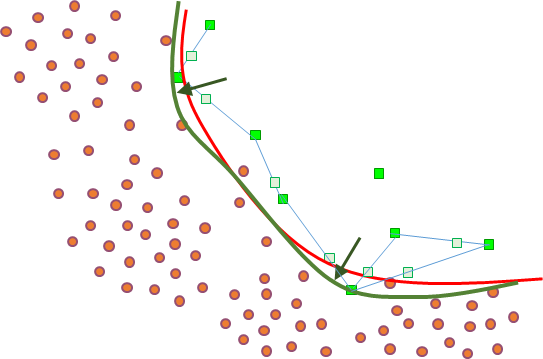
Dans l’exemple considéré, supposons que nous avons deux données de validation, illustrées par les nouvelles imagettes de la figure suivante (Fig. 7, comparer à la Fig. 6 qui montrait uniquement les données d’apprentissage).
Fig. 7 Détection de véhicules : erreurs des modèles sur les données de validation¶
Nous pouvons constater que dans cet exemple le modèle « simple » prend la bonne décision d’affectation pour chacune de ces données (affecte une à la classe « véhicule » et l’autre à la classe « autre » ou « non véhicule ») alors que le modèle « complexe » se trompe pour une des données (affecte la donnée qui ne représente pas un véhicule à la classe « véhicule »). Suivant les performances sur ces données de validation, il faudrait dans cet exemple privilégier le modèle le plus simple par rapport au modèle le plus complexe. Bien entendu, le nombre de données de validation devrait être bien plus élevé, suffisant pour que la comparaison soit fiable.
Une fois retenu un modèle par rapport à un autre (dans l’exemple, le modèle « simple » au détriment du modèle « complexe »), comment estimer ses performances futures ? Il est nécessaire d’employer pour cela des données de test, qui ne font partie ni des données d’apprentissage ni de celles de validation, car les données d’apprentissage comme celles de validation ont déjà servi à obtenir (apprendre, respectivement sélectionner) ce modèle. Ces données de test (comme les données d’apprentissage ou de validation, d’ailleurs) doivent être représentatives des données pour lesquelles le modèle devra prendre des décisions lors de son utilisation à venir.
Décider avec le modèle obtenu
L’objectif de la construction d’un modèle décisionnel est de prendre des décisions sur de nouvelles observations. Dans notre exemple, décider, pour une région d’une nouvelle image, si elle contient ou non un « véhicule » (la classe d’objets d’intérêt).
Fig. 8 Détection de véhicules : avec le modèle, decider sur de nouvelles observations¶
Pour cela, une fois le modèle décisionnel choisi et ses performances futures estimées à travers les performances sur des données de test, il est appliqué aux nouvelles observations (pour lesquelles l’information de supervision est absente) afin de prendre les décisions les concernant.
Une première remarque ici est que l’hypothèse de représentativité des données d’apprentissage, validation et test est rarement vraie en pratique, car les distributions des données sont en général non stationnaires (évoluent dans le temps, plus ou moins lentement). Il est alors nécessaire de surveiller l’évolution des performances d’un modèle décisionnel lors de son utilisation et, lorsque ces performances se dégradent, de refaire la modélisation. Afin de surveiller les performances il faut tester le modèle régulièrement sur de nouvelles observations pour lesquelles les informations de supervision (la bonne classe d’appartenance, par exemple) sont disponibles.
Une seconde remarque est que la construction d’un modèle (décisionnel) n’est pas indispensable à la prise de décision. La décision sur la base des \(k\) plus proches voisins, par exemple, est une méthode relativement populaire qui consiste à prendre comme décision pour une nouvelle observation le résultat du vote des \(k\) observations (avec information de supervision) les plus proches de l’observation nouvelle. Dans l’exemple de la détection de véhicules, si les \(k\) plus proches voisins d’une nouvelle observation sont majoritairement dans la classe « véhicule » alors l’observation sera affectée à cette même classe.
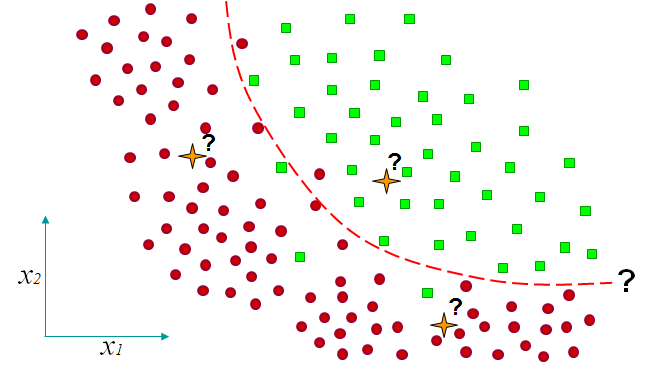
En général, les observations à partir desquelles un modèle est construit ou celles sur lesquelles le modèle doit proposer des décisions sont décrites par plusieurs variables de différents types (que nous examinerons plus tard). Pour la suite de notre présentation dans ce cours introductif nous considérons que les observation sont décrites seulement par deux variables quantitatives, \(X_1\) et \(X_2\), qui prennent des valeurs réelles (\(\in \mathbb{R}\)). Chaque observation \(i\) est ainsi définie par les valeurs de ces deux variables, \((x_{i1}, x_{i2})\), et peut ainsi être représentée par un point du plan. La figure suivante (Fig. 9) montre un ensemble de telles observations bidimensionnelles (les points dessinés dans le plan), qui possèdent en plus une information de supervision de type classe d’appartenance. La classe d’intérêt est représentée par la couleur verte et l’autre classe par la couleur rouge.
Il est important de noter que les valeurs prises par les variables pour une observation peuvent être affectées d’aléa (par ex. de bruit de mesure) qui font que les valeurs enregistrées, les seules auxquelles nous avons accès, ne sont pas tout à fait les « vraies ». Aussi, certaines observations d’une classe peuvent être assez ambiguës pour passer, éventuellement pour un observateur humain qui fournit l’information de supervision, pour des observations de l’autre classe. Enfin, l’information disponible dans les variables observées peut ne pas suffire pour décider si certaines observations font partie d’une classe ou de l’autre. Les nuages d’observations des deux classes peuvent ainsi se « mélanger » partiellement.
Fig. 9 Simplification de l’exemple : problème de classement, chaque observation est décrite par les valeurs de 2 variables numériques¶
Nous sommes en présence d’un problème de classement (ou de discrimination) à deux classes : le modèle décisionnel doit affecter les observations soit à la classe d’intérêt, soit à l’autre classe. Nous avons également représenté un modèle décisionnel qui prend ici la forme d’une frontière de discrimination (en orange) dans le plan des observations, ainsi que trois observations (croix oranges) sans information de supervision (la classe est inconnue) qu’un modèle doit affecter à une des classes.
Après ces précisions, nous pouvons revenir à la construction et à l’évaluation des performances de modèles décisionnels.
Un modèle est obtenu à partir de données d`apprentissage, pour lesquelles l’information de supervision (ici, la classe d’appartenance) est connue. Les performances du modèle sur les observations d’apprentissage sont en général exprimées par l`erreur d’apprentissage (ou risque empirique), facile à mesurer car les données sont disponibles ainsi que l’information de supervision associée (la classe d’appartenance de chaque observation d’apprentissage est connue).
La figure suivante (Fig. 10) montre un ensemble d’observations avec information de supervision et un modèle qui a été obtenu sur ces observations considérées comme données d’apprentissage. Ce modèle ne fait aucune erreur de classement sur ces données : aucune de ces observations n’est du « mauvais » côté de la frontière de discrimination (ou de l’autre côté que la majorité des observations de la même classe).
Fig. 10 Modèle décisionnel (ici, frontière de discrimination entre deux classes) obtenu sur des données d’apprentissage¶
Le but final d’une modélisation décisionnelle est d’utiliser le modèle obtenu pour prendre des décisions concernant les futures observations qui ne possèdent pas d’information de supervision. Pour un problème de classement, ce sont des décisions d’affectation de chaque observation à une des classes. Les performances d’un modèle sur ces données futures (performances de généralisation) sont habituellement exprimées par l`erreur de généralisation (ou risque espéré) qui ne peut pas être mesurée car ces observations sont inconnues au départ et, lorsqu’elles arrivent, l’information de supervision est absente.
Si elle ne peut pas être mesurée, l’erreur de généralisation peut en revanche être estimée. L’estimation est en général obtenue à partir de l’erreur sur des données de test, qui possèdent l’information de supervision mais ne sont pas utilisées pour l’apprentissage. Les données de test (comme les données d’apprentissage) sont supposées issues de la même distribution que les données futures sur lesquelles le modèle doit prendre des décisions. Cela conditionne leur représentativité des données futures, donc la qualité du modèle et la qualité de l’estimation obtenue pour les performances de généralisation.
La figure suivante (Fig. 11) présente un ensemble d’observations (avec information de supervision) qui a une intersection vide avec l’ensemble de données d’apprentissage (figure précédente). L’erreur de test que fait le modèle sur ces observations peut être mesurée et constitue une estimation de l’erreur de généralisation du modèle. Le modèle représenté fait quelques erreurs de classement sur ces observations : certaines observations sont du « mauvais » côté de la frontière de discrimination. L’erreur de généralisation estimée est donc non nulle.
Fig. 11 Application du modèle décisionnel sur des données de test¶
Sous certaines conditions (que vous étudierez un peu plus dans RCP209), il est également possible d’obtenir une borne supérieure sur l’écart entre l’erreur de généralisation (qui ne peut être mesurée) et l’erreur d’apprentissage (qui peut être mesurée). Cela permet donc, en principe, de calculer une borne supérieure sur l’erreur de généralisation à partir de l’erreur d’apprentissage mesurée.
L’objectif de la modélisation décisionnelle est d’obtenir le modèle qui présente la meilleure généralisation, c’est à dire la plus faible erreur de généralisation. Comment procéder si seule l’erreur d’apprentissage est directement accessible ? Quel est le rapport entre l’erreur de généralisation et l’erreur d’apprentissage ?
En règle générale, pour obtenir un modèle il faut commencer par choisir une famille de modèles et ensuite chercher les paramètres du modèle (au sein de cette famille) qui optimisent un critère pertinent.
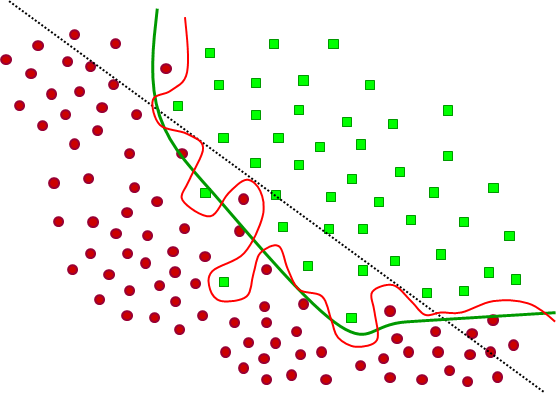
Considérons trois familles de modèles, plus précisément ici trois familles de courbes pour la frontière de discrimination : la famille des droites (dans le plan), une famille de courbes très lisses et une famille de courbes potentiellement très « ondulées ». A l’intérieur de chacune de ces familles, un modèle est obtenu par une recherche des valeurs de paramètres (par ex., pour la droite la pente et l’abscisse correspondant à l’ordonnée 0) qui minimisent l’erreur d’apprentissage, seul critère dépendant des données et directement accessible. Les trois modèles résultants sont illustrés dans la figure suivante (Fig. 12) ; la droite en trait noir pointillé, le modèle lisse en trait vert et le modèle « ondulé » en trait rouge.
Fig. 12 Modèles alternatifs obtenus sur les données d’apprentissage¶
Sur ces données d’apprentissage, seule la famille de courbes potentiellement très « ondulées » permet de trouver un modèle dont l’erreur d’apprentissage est 0. Dans la famille des modèles très lisses est obtenue une frontière qui présente une erreur d’apprentissage faible mais non nulle. Dans la famille des droites, la meilleure droite ne sépare que de façon médiocre (erreur de classement élevée) les observations d’apprentissage des deux classes ; on parle en général de sous-apprentissage dans une telle situation.
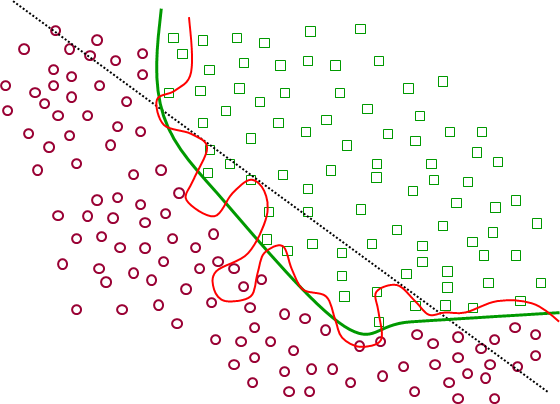
Quelles sont les performances de ces modèles sur les observations de test et donc les estimations respectives de leurs erreurs de généralisation ? La figure suivante (Fig. 13) montre la qualité de discrimination de chacun des trois modèles sur ces données de test.
Fig. 13 Performances des différents modèles sur les données de test¶
On constate dans cet exemple que la droite présente une erreur de test élevée (mais proche de son erreur d’apprentissage), la frontière lisse une erreur de test pratiquement nulle et la frontière « ondulée » une erreur de test un peu plus élevée. Le modèle qui a la plus faible erreur d’apprentissage n’est pas celui qui présente l’erreur de test la plus faible. On parle dans une telle situation de sur-apprentissage (ou d`« apprentissage par cœur »).
Dans quelle mesure ce constat est général ? Dans une famille de modèles trop « simples » (comme les droites ici) il est fréquent de ne trouver aucun modèle capable de bien séparer les données de classes différentes. Cela est aussi vrai sur les données d’apprentissage que sur les données de test. Dans une famille de modèles suffisamment « complexes » (comme les courbes potentiellement très « ondulées » ici) il est fréquent de trouver un modèle (comme la courbe rouge ici) capable de bien séparer les données qui ont été employées pour le trouver (les données d’apprentissage). Ce modèle peut être excessivement ajusté aux particularités des observations d’apprentissage et présenter ainsi une erreur de test (donc sur des données autres que celles d’apprentissage, bien qu’issues de la même distribution) bien plus élevée. Afin de trouver dans cette famille de modèles « complexes » un modèle qui généralise mieux il faudrait disposer de beaucoup plus de données d’apprentissage, pour mieux contraindre la variabilité des modèles de cette famille.
Considérons maintenant la possibilité, mentionnée plus haut, de trouver une borne supérieure pour l’erreur de généralisation à partir de l’erreur d’apprentissage grâce à une « borne de généralisation ». Cela signifie que l’erreur généralisation est inférieure ou égale à la somme entre l’erreur d’apprentissage et la borne de généralisation. En règle générale, la borne de généralisation augmente lorsque la « complexité » (ou la « capacité ») de la famille de modèles augmente et le nombre de données d’apprentissage diminue. Dans l’exemple considéré, pour la famille des droites la borne est faible (par ex. 5%) mais l’erreur d’apprentissage est élevée (par ex. 20%), la somme des deux est donc élevée (25%) et ne permet pas de borner de façon intéressante l’erreur de généralisation. Pour les modèles lisses, la borne est à peine plus élevée (par ex. 7%) et l’erreur d’apprentissage du modèle trouvé faible (par ex. 3%), la somme est donc assez faible (10%) pour fournir une borne de généralisation intéressante. Enfin, pour la famille des courbes très « ondulées » la borne est élevée (par ex. 25%) et donc, malgré une erreur d’apprentissage très faible (0% ici), la somme des deux ne fournit pas de borne supérieure intéressante pour l’erreur de généralisation. Il faudrait disposer de beaucoup plus de données d’apprentissage pour faire baisser suffisamment la borne de généralisation pour la famille des courbes très « ondulées » et obtenir des garanties de généralisation intéressantes pour cette famille.
La maîtrise de la complexité des modèles est donc très importante dans la modélisation décisionnelle. Des méthodes de contrôle de la complexité sont présentées dans le chapitre sur les réseaux de neurones et ce sujet est examiné de façon plus générale dans l’introduction de l’UE RCP209.
La réalité des données que nous pouvons avoir à traiter pour arriver à un modèle décisionnel peut être assez éloignée de l’exemple idéalisé présenté ci-dessus. Nous examinons brièvement dans la suite quelques-unes des caractéristiques des données qui posent des difficultés particulières à la modélisation :
Données inadaptées
Données non représentatives
Données aberrantes
Données manquantes
Classes déséquilibrées
Dimension très élevée des données
Pour obtenir un modèle décisionnel utile, savoir surmonter ces difficultés est au moins aussi important que maîtriser les outils de modélisation.
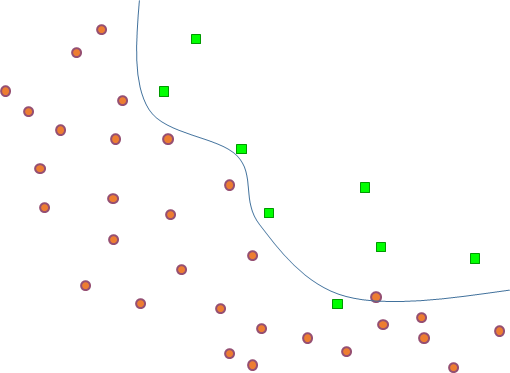
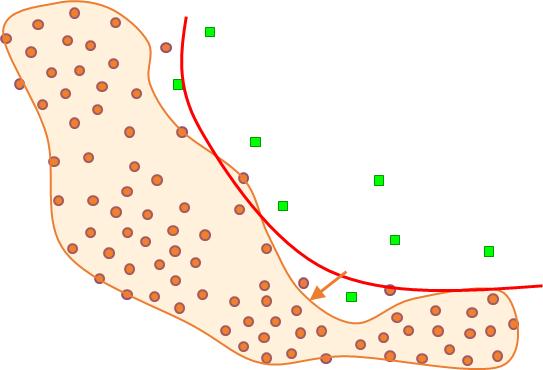
Lorsque les données à partir desquelles la modélisation décisionnelle doit être faite ont déjà été récoltées, nous pouvons parfois nous retrouver avec des données inadaptées à l’objectif visé. Prenons un exemple simple, illustré dans la figure suivante (Fig. 14). Supposons que pour obtenir un modèle de classement en deux classes nous disposons des données bidimensionnelles (des points) de la figure, où la couleur de chaque point indique sa classe d’appartenance. Que pouvons-nous espérer obtenir avec ces données ? Il est, bien entendu, possible de choisir une famille suffisamment « complexe » de modèles (dans cet exemple, de courbes suffisamment « ondulées ») pour bien séparer les points verts des points rouges. Mais un tel modèle a de fortes chances de généraliser très mal, pour les raisons que nous avons discutées plus haut. Imaginons que nous mettons de côté 10% de ces données, choisies aléatoirement, apprenons sur les 90% de données restantes et ensuite appliquons ce modèle aux données mises de côté. Il est vraisemblable que la frontière très complexe (le modèle) trouvée par apprentissage se trompe souvent (peut-être une fois sur deux) sur ces données de test. Avec une erreur de généralisation estimée à 50% pour un problème de classement en deux classes, le modèle ainsi obtenu est inutile.
Fig. 14 Données inadaptées à une modélisation décisionnelle (ici, recherche de modèle de classement)¶
Il est possible de conclure alors que l’information utile, permettant de séparer les deux classes avec un modèle appartenant à une famille raisonnablement « simple », est absente des variables disponibles ; ces variables ne sont pas assez « explicatives » pour notre problème. Pour avancer il est alors indispensable de refaire la collecte des données après avoir mieux analysé le problème afin de choisir de « meilleures » variables (avec un pouvoir explicatif supérieur pour le problème de classement visé).
Bien entendu, les situations rencontrées en pratique sont rarement aussi caricaturales. Les variables peuvent avoir un (très) faible pouvoir explicatif et être suffisamment nombreuses pour que la visualisation directe de paires ou triplets de variables ne donne pas d’indication facile à interpréter. Il peut donc être plus difficile d’arriver à la conclusion que les variables disponibles sont insuffisantes par rapport au but recherché. Des méthodes d’analyse de données, étudiées plus loin dans ce cours, ainsi que l’application successive de modèles appartenant à des familles de complexité croissante, peuvent nous y aider.
2. Données non (ou très partiellement) représentatives¶
Une difficulté assez fréquemment rencontrée est l’insuffisante représentativité des données collectées pour obtenir le modèle par rapport aux observations futures, pour lesquelles le modèle devra prendre des décisions. Cela est la conséquence d’une incohérence (partielle) entre la collecte de données et les objectifs de modélisation. Parfois, cette incohérence est due à une évolution des objectifs par rapport au moment où les critères de collecte de données ont été définis. Dans d’autres cas, ces critères ne tiennent pas compte de particularités du phénomène à modéliser.
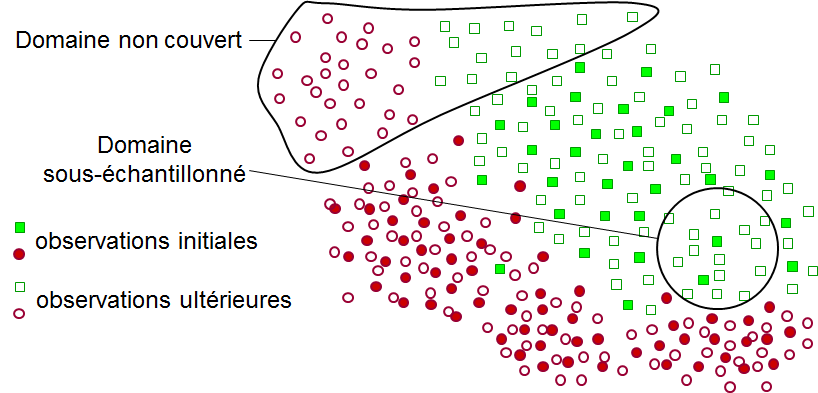
La figure suivante (Fig. 15) illustre cette difficulté pour des données bidimensionnelles dans un problème de classement en deux classes. Les points « pleins » représentent des observations collectées pour la construction du modèle, alors que les points « creux » correspondent aux observations ultérieures, que le modèle doit affecter à une des classes. Nous pouvons voir, sur cette figure, deux situations :
Données sous-représentées (domaine sous-échantillonné) : quelques données sont bien présentes pour la construction du modèle, mais leur nombre est très insuffisant. Si nous revenons à l’exemple illustratif de la détection de véhicules, cela peut arriver, par ex., lorsque la collecte des données a été faite uniquement le dimanche, quand la circulation des camions est interdite (donc les images de camions sont fortement sous-représentées), alors que le modèle doit être utilisé tous les jours de la semaine.
Domaines non couverts : dans des régions assez larges où des observations ultérieures sont présentes il n’y aucune observation dans l’étape de construction du modèle. Par exemple, pour la détection de véhicules, la collecte des données a été réalisée uniquement en ville mais le modèle est utilisé partout, y compris à la campagne (où on trouve des engins agricoles et éventuellement des animaux d’élevage, pratiquement jamais présents en ville).
Fig. 15 Données d’apprentissage non (ou peu) représentatives des données de test¶
L’insuffisance de la représentativité des données collectées peut difficilement être « devinée » pendant la collecte, en revanche il est nécessaire de pouvoir la détecter lors de l’utilisation du modèle. La détection peut être faite, dans une certaine mesure, en examinant les distances entre les observations nouvelles, sur lesquelles le modèle doit prendre des décisions, et les observations utilisées pour construire le modèle. Si ces distances sont souvent élevées, alors la représentativité est insuffisante. L’estimation de densité des observations peut également permettre d’identifier des régions où les données de test sont relativement nombreuses alors que les données d’apprentissage sont absentes.
Lorsque des insuffisances de représentativité ont été détectées, il est nécessaire de compléter la collecte des données afin d’améliorer leur représentativité et ensuite de refaire la modélisation. En attendant, il est préférable de restreindre le modèle aux régions « bien couvertes » par des observations utilisées dans la construction du modèle. Cela peut être fait à travers le rejet de non représentativité qui consiste à refuser de décider pour des observations trop éloignées du domaine couvert par les données d’apprentissage (ce sujet est brièvement abordé dans RCP209).
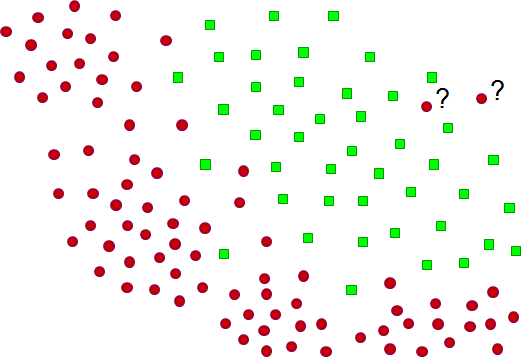
Une autre difficulté relativement fréquente est la présence, dans l’ensemble de données à employer pour la modélisation, de données (observations) éloignées de toutes les autres ou seulement de celles de leur classe. On parle en général de « données aberrantes », mais ce terme peut avoir des significations relativement différentes. La figure suivante (Fig. 16) montre deux observations (les points rouges avec points d’interrogation proches) éloignées de celles de leur classe mais proches des observations de l’autre classe (en vert). De telles données posent une difficulté de principe : faut-il les traiter comme des erreurs de mesure (ou d’enregistrement) et les exclure de la modélisation (ou chercher à les corriger) ou alors comme un phénomène significatif, à modéliser ?
L’approche la plus fréquemment rencontrée est l’exclusion des données aberrantes de la modélisation. Cette exclusion peut être implicite, grâce à l’emploi de méthodes de modélisation robustes basées sur des distributions à décroissance lente dont les paramètres sont moins sensibles aux données éloignées (la décroissance de la densité étant lente, la valeur de la densité peut rester sensiblement supérieure à 0 même pour les données éloignées). L’exclusion peut aussi être explicite, grâce à une détection des données aberrantes. Cette détection des données aberrantes peut être faites par des tests statistiques spécifiques (test de Chauvenet, test de Thompson modifié, etc.), par l’utilisation de la distance aux \(k\) plus proches voisins ou par une modélisation explicite du support de la distribution des données (les observations atypiques se trouveront exclues du support et ainsi étiquetées comme aberrantes).
L’exclusion des données aberrantes peut malheureusement avoir des conséquences négatives sur la modélisation. D’abord, l’apparition de données aberrantes peut être liée aux valeurs de certaines variables. Par exemple, un appareil de mesure fait des erreurs de mesure plus fortes dans des conditions extrêmes de température, humidité, pression, etc. Exclure les observations associées peut engendrer un biais de modélisation. Ensuite, si le nombre de données aberrantes est relativement élevé, leur exclusion peut avoir des conséquences négatives par la réduction du nombre d’observations. Il est donc très utile d’examiner de plus près les données aberrantes afin de comprendre leur apparition.
Une analyse plus approfondie peut montrer, par exemple, que des données aberrantes correspondent à des erreurs de codage dans la représentation numérique. C’est notamment le cas lorsque les données proviennent de sources multiples, qui emploient des codages différents (par ex. ISO/CEI 8859-1 vs UTF8), ou lorsque certaines valeurs numériques emploient le point pour séparer les décimales alors que d’autres emploient la virgule. Ou alors, que certaines observations ont été mal étiquetées (par un expert ou par un opérateur humain) lors de la préparation des données. Par exemple, un des opérateurs a considéré qu’un attelage n’était pas un véhicule. Le cas illustré dans la figure précédente peut être de cette nature. Dans de telles situations il est possible de corriger les données qui peuvent ainsi rentrer dans la normalité.
L’analyse peut également montrer que les données aberrantes sont la manifestation d’un phénomène significatif, qui doit être pris en compte dans la modélisation. Par exemple, que les observations considérées comme aberrantes dans la figure précédente représentent des individus atypiques mais néanmoins authentiques appartenant bien à la « classe des rouges », et qu’il est donc nécessaire de tenir compte du fait que cette classe présente plusieurs modes bien séparés.
Une difficulté de modélisation fréquente est due au fait que des observations sont incomplètes, c’est à dire les valeurs d’une ou plusieurs variables manquent. On parle alors d’observations à données manquantes. Par exemple, dans le cas d’un sondage, certaines personnes ne répondent pas à certaines questions. Si on considère le cas de mesures issues de capteurs, un des capteurs peut fonctionner de façon intermittente ou alors la transmission des mesures peut subir des perturbations ponctuelles.
Lorsque les observations employées pour la construction d’un modèle comportent des données manquantes, une première approche est de supprimer les observations qui présentent des valeurs manquantes pour certaines variables, ou de supprimer les variables qui présentent une proportion élevée de valeurs manquantes. Bien que fréquemment employée par défaut, cette approche s’avère simpliste car ses conséquences peuvent être non seulement une diminution des performances du modèle (par réduction du nombre de données d’apprentissage), mais aussi un fort biais de modélisation pouvant conduire à un modèle inopérant. Avant de décider d’ignorer les observations incomplètes il est donc nécessaire de comprendre pourquoi des données manquent. Une autre approche, qui s’avère souvent meilleure, consiste à estimer (ou imputer) les données manquantes et à traiter les valeurs estimées comme des valeurs mesurées. Enfin, la solution idéale serait de corriger les erreurs responsables des données manquantes ou de compléter la collecte de données, mais cette solution est rarement accessible.
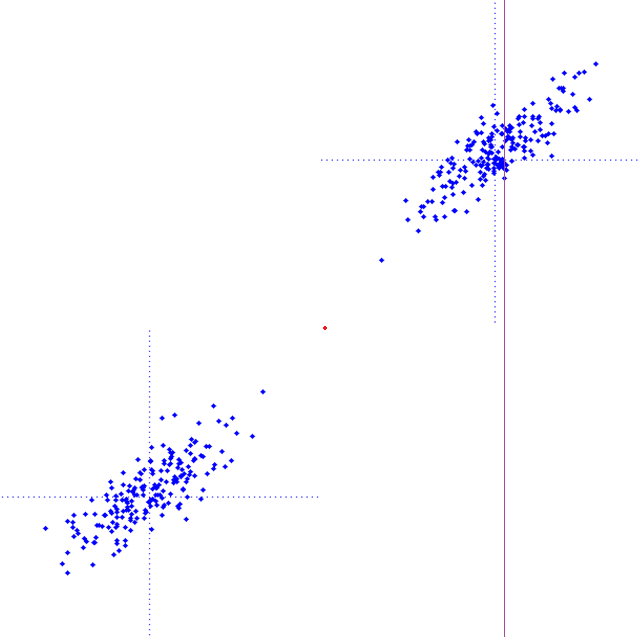
La figure suivante (Fig. 17) montre un ensemble d’observations bidimensionnelles (les points bleus). Le long trait vertical illustre une observation incomplète, pour laquelle seule l’abscisse (la coordonnée horizontale, donc la position du trait vertical) est connue et l’ordonnée (la coordonnée verticale) manque. Quelle valeur employer comme estimation de la coordonnée verticale manquante ?
Fig. 17 Observation (indiquée par une ligne verticale) dont la coordonnée verticale est manquante¶
De nombreuses méthodes existent pour l’imputation des données manquantes, par exemple :
Estimation de la valeur manquante par la moyenne (ou par la médiane) des valeurs de la variable sur toutes les observations pour lesquelles ces valeurs sont connues.
Estimation de la valeur manquante par la moyenne de la variable pour les données de la même classe (lorsque des étiquettes de classe sont disponibles) ou du même groupe (en l’absence d’étiquettes de classe) issu d’une classification automatique des observations complètes.
Estimation, lors d’itérations successives, à la fois d’un modèle des données et des données manquantes (par ex., algorithmes de type espérance-maximisation).
Un bon traitement des données manquantes exige une analyse plus attentive du problème et une bonne compréhension des différentes méthodes d’estimation (imputation). Nous y consacrons une séance de cours et une séance de TP.
Il arrive assez souvent, pour des problèmes de classement, qu’une des classes soit bien moins fréquente que l’autre (ou les autres). Par exemple, parmi les transactions par carte bancaire, une infime minorité sont « frauduleuses », alors que la très grande majorité sont « normales ». Cela est le cas à la fois pour les observations à partir desquelles le modèle est construit que pour les observations ultérieures, sur lesquelles le modèle doit (aider à) prendre des décisions.
Un déséquilibre fort engendre des difficultés significatives de modélisation. En effet, la « masse » des données de la classe majoritaire peut « pousser » la frontière de discrimination loin dans la classe minoritaire. Par ailleurs, si la classe minoritaire représente un faible pourcentage (par ex. 5%) des observations, alors un modèle qui affecte toute observation à la classe majoritaire ne fait qu’un faible pourcentage (5%) d’erreurs de classement ; or, de toute évidence, ce modèle n’a aucune utilité.
De multiples approches, de nature parfois très différente, ont été explorées pour faire face aux difficultés engendrées par le déséquilibre entre les classes. Dans la suite nous mentionnons quelques-unes de ces approches.
Privilégier des méthodes de modélisation qui sont moins sensibles que d’autres au déséquilibre entre les classes. Par exemple, les machines à vecteurs support (SVM) cherchent à maximiser la marge entre la frontière de discrimination et les données de chacune des classes. En conséquence, seules comptent les données les plus proches de la frontière, ce qui permet de réduire l’impact du déséquilibre entre les classes. Mais cela ne répond pas au problème de mesure de l’erreur faite par le modèle.
En modifiant la façon de mesurer la performance d’un modèle il est possible de mieux prendre en compte le déséquilibre entre les effectifs des classes. L’indice \(\kappa\)(Kappa) est employé pour comparer les performances d’un modèle aux performances attendues du modèle, à partir de la matrice de confusion, en tenant compte du déséquilibre. Plus précisément, l’accord observé entre les prédictions du modèle et les bonnes prédictions est comparé à l’accord entre des prédictions aléatoires respectant les mêmes proportions entre les classes et les bonnes prédictions. On peut également se focaliser sur les performances obtenues sur la classe minoritaire, en utilisant comme mesure de performance le rappel obtenu pour la classe minoritaire, c’est à dire la proportion d’éléments de la classe minoritare affectés par le modèle à cette classe. Noter toutefois que le rappel de la classe minoritaire ne doit pas être employé seul, car il ne dit rien de ce qui se passe avec la classe majoritaire : que le modèle affecte à la classe minoritaire toutes les observations (y compris celles de la classe majoritaire) ou uniquement celles de la classe minoritaire, une même valeur de 1 est obtenue pour ce rappel.
Il est possible de conserver une mesure de performances habituelle mais d’employer des pénalités asymétriques, plus élevées pour les erreurs faites sur la classe minoritaire que pour celles faites sur la classe majoritaire. Cela a pour conséquence un déplacement de la frontière de décision vers la classe majoritaire, comme illustré dans la figure suivante (Fig. 19). Noter que cette asymétrie est introduite simplement pour tenter de compenser le déséquilibre des effectifs et n’indique pas nécessairement que les erreurs faites sur la classe minoritaires sont plus « graves » que les autres.
Fig. 19 Déplacement de la frontière de décision grâce aux pénalités asymétriques¶
Plusieurs méthodes de modélisation emploient un ensemble de modèles plutôt qu’un seul modèle, chaque modèle de l’ensemble étant construit sur un échantillon des observations (voir par ex. les forêts aléatoires). Cette approche a été adaptée au cas des classes déséquilibrées en considérant, pour chaque modèle, des taux d’échantillonnage très différents (élevé pour la classe minoritaire et faible pour la classe majoritaire), permettant d’équilibrer les effectifs des classes dans l’échantillon. Les trois figures suivantes montrent trois modèles obtenus sur des échantillons (plus équilibrés que les classes complètes), la quatrième figure (Fig. 20) indique le résultat de l’utilisation de l’ensemble (frontière indigo) plutôt que d’un seul modèle (frontière rouge) obtenu sur la totalité des données.
Fig. 20 Déplacement de la frontière de décision obtenu en moyennant les modèles de l’ensemble¶
Afin d’équilibrer les effectifs des classes il est également envisageable de générer des observations synthétiques pour la classe minoritaire. Différentes méthodes (par ex. Synthetic Minority Over-sampling TEchnique, SMOTE, voir [CBH02]) permettent de générer de telles observations comme des combinaisons linéaires entre de vraies observations appartenant à la classe minoritaire. Ce procédé est illustré dans la figure suivante (Fig. 21). Il faut noter que de telles méthodes font des hypothèses fortes sur les classes (par ex., hypothèse de convexité), hypothèses qui peuvent s’avérer erronées.
Fig. 21 Génération d’observations synthétiques pour la classe minoritaire avec SMOTE et conséquence sur le déplacement de la frontière de décision¶
Une approche bien explorée consiste à reformuler le problème de classement initial comme un problème de détection d’observations aberrantes (les observations de la classe minoritaire). La figure suivante (Fig. 22) montre le résultat d’une telle reformulation. La frontière rouge correspond au modèle obtenu sur la totalité des données (effectifs déséquilibrés), suivant la formulation de départ d’un problème de classement en deux classes. Le domaine orange correspond au support déterminé pour la distribution des observations de la classe majoritaire, dans le cadre de la reformulation du problème comme une détection de « nouveauté » (ou d’observations aberrantes). Toute observation qui est à l’extérieur de la frontière orange est ainsi affectée à la classe minoritaire.
Fig. 22 Reformulation du problème comme une détection d’observations aberrantes et conséquence sur le déplacement de la frontière de décision¶
Les observations sont de dimension \(d\) si elles sont caractérisées par \(d\) variables unidimensionnelles. Dans certains cas, la dimension est élevée et cela engendre un certain nombre de difficultés regroupées sous le nom de « malédiction de la dimension » (ou « fléau de la dimension », curse of dimensionality). Ces difficultés peuvent être majeures et concernent aussi bien des aspects fondamentaux de la modélisation à partir de données que le coût des algorithmes qui mettent en œuvre la modélisation. Nous résumons ici quelques-unes de ces difficultés :
A nombre de données fixé, la densité diminue exponentiellement avec l’augmentation de la dimension \(d\). Les données deviennent « rares » ou « isolées » dans l’espace. Il n’est plus possible d’estimer la densité de façon fiable et différents tests statistiques deviennent inexploitables. Le nombre de données devrait augmenter de façon exponentielle avec la dimension pour conserver les capacités de modélisation.
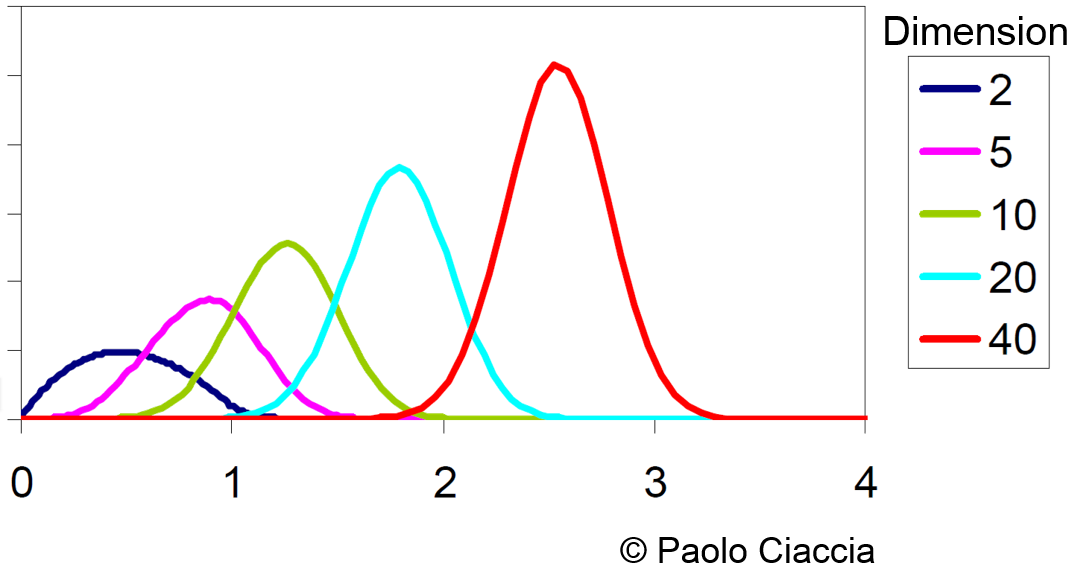
La variance de la distribution des distances entre données diminue avec l’augmentation de la dimension (voir la figure suivante, Fig. 23). Cette difficulté, qui est une des manifestations de la « concentration des mesures », peut rendre inexploitable la décision sur la base des k plus proches voisins car la représentativité de ces voisins pour une donnée devient comparable à la représentativité des autres données. Aussi, il devient difficile de trouver des regroupements dans les données (les données à l’intérieur d’un groupe ne sont pas tellement plus proches entre elles que des données d’autres groupes), donc l’intérêt de la classification automatique diminue.
Fig. 23 Concentration des mesures pour des données qui suivent une distribution uniforme¶
Le nombre de variables considérées est une composante de la « complexité » des modèles. Avec un nombre excessif de variables, le risque de sur-apprentissage augmente ; il est possible de trouver « explicatives » (sur les données d’apprentissage) des variables qui n’ont aucune bonne raison d’être explicatives. Afin de réduire ce risque il faudrait disposer d’un nombre beaucoup plus élevé d’observations d’apprentissage.
Le coût des algorithmes d’analyse, de modélisation ou de décision avec un modèle, souvent proportionnel à \(d^2\) ou \(d^3\), peut devenir excessif.
Nous pouvons néanmoins mentionner que la dimension des données peut souvent être réduite par différentes méthodes, voir par ex. le chapitre sur les méthodes factorielles. Enfin, la distribution des données a une grande importance dans la gravité de la malédiction de la dimension : plus la distribution des données est non uniforme, plus élevée est la dimension à partir de laquelle les capacités de modélisation sont affectées de façon sensible.
Les données à modéliser sont des ensembles d’observations, chaque observation (parfois appelée individu ou entité) regroupant les valeurs que prennent simultanément les variables (ou attributs, traits) qui interviennent dans le problème. Dans l’exemple de la détection de véhicules, une observation est une (partie d`) image et les variables correspondent soit directement aux pixels individuels, soit aux caractéristiques dérivées si la modélisation est faite à partir de telles caractéristiques plutôt que directement à partir des pixels. Dans l’exemple du diagnostic médical, une observation est constituée par les valeurs prises à un moment donné par les variables qui décrivent l’état clinique d’un patient.
Les ensembles d’observations sont en général représentés par des tableaux de données, chaque ligne correspondant à une observation et chaque colonne (ou groupe de colonnes, pour une variable nominale) à une variable :
Observation
\(X_1\)
\(X_2\)
…
\(X_d\)
\(e_1\)
…
…
…
…
\(e_2\)
…
…
…
…
…
…
…
…
…
\(e_n\)
…
…
…
…
Le type d’une variable est défini par la nature des valeurs que peut prendre la variable. Plusieurs distinctions sont nécessaires. D’abord, celle entre les variables quantitatives et les variables qualitatives.
Variables quantitatives (parfois appelées « numériques »). Une distinction supplémentaire peut être faite entre variables continues, dont les valeurs sont des nombres réels (\(\in \mathbb{R}\), par ex. pour des mesures physiques, etc. ; noter que la représentation de ces valeurs a toujours une précision finie), et variables discrètes, dont les valeurs sont des entiers en général positifs (\(\in \mathbb{N}\), par ex. pour la population, le nombre d’avis, etc.).
Variables qualitatives (aussi appelées « catégorielles »). On distingue ici les variables ordinales des variables nominales. Les valeurs que peut prendre une variable qualitative portent le nom de « modalités ». Pour une variable ordinale, une relation d’ordre total est présente entre ses modalités. Nous pouvons trouver ici, par exemple, le classement (1er, 2ème, 3ème, etc.) ou l’échelle de Lickert (Pas du tout d’accord / Pas d’accord / Ni en désaccord ni d’accord / D’accord / Tout à fait d’accord). Dans le cas d’une variable nominale, les modalités (les différentes valeurs possibles) ne sont pas comparables, elles peuvent seulement être identiques ou différentes. Comme exemples citons la catégorie socio-professionnelle, les noms des pays européens, les noms des villes françaises, etc.
Une autre distinction nécessaire est entre variables non structurées et variables structurées. Une variable est considérée structurée lorsque ses valeurs possèdent pour la plupart une structure interne. Par exemple, une phrase possède une structure grammaticale (arbre syntaxique) qui est en général importante pour le traitement de la phrase. Une variable qui prend comme valeurs les structures grammaticales des réponses à une question ouverte d’un sondage est ainsi une variable structurée.
On parle parfois de valeurs-ensembles pour une variable lorsque chaque valeur possible de la variable est un sous-ensemble d’un très grand ensemble fixé. Par exemple, si on considère l’ensemble des mots d’une langue, un texte écrit en cette langue peut être vu comme un ensemble de mots, donc un sous-ensemble spécifique des mots de la langue.
Au-delà de la nature des valeurs prises individuellement, les liens entre les valeurs prises par une même variable dans des observations différentes a son importance dans la modélisation. Si les observations différentes sont considérées en général indépendantes, parfois elles présentent des dépendances. Par exemple, les mesures successives du débit d’une rivière à un endroit donné ne peuvent pas être considérées indépendantes. Aussi, des mesures simultanées et spatialement proches du taux de particules dans l’atmosphère sont naturellement liées entre elles. La mise en évidence de ces dépendances temporelles et/ou spatiales fait le plus souvent partie de l’objectif de la modélisation.
Si la représentation des valeurs prises par les variables quantitatives ne pose pas de problème particulier, la représentation des valeurs des variables qualitatives n’est pas aussi directe. En effet, certaines méthodes de modélisation peuvent employer directement une représentation symbolique de ces valeurs mais d’autres exigent des représentations numériques.
Considérons d’abord une variable ordinale de type échelle de Lickert. Peut-on envisager de représenter ses différentes valeurs par des nombres respectant la même relation d’ordre, comme dans le tableau suivant ?
Pas du tout d’accord
1
Pas d’accord
2
Ni en désaccord ni d’accord
3
D’accord
4
Tout à fait d’accord
5
Cette représentation, qui emploie une variable numérique pour représenter directement la variable ordinale, introduit des distances identiques entre les modalités successives alors que seule la relation d’ordre est associée à la signification de la variable. Pas d’accord est-elle à égale distance de Pas du tout d’accord et de Ni en désaccord ni d’accord ? Dans certains cas, cette représentation peut néanmoins donner de bons résultats. Une représentation souvent préférée consiste à associer à cette variable ordinale autant de variables numériques binaires qu’il y a de modalités différentes et utiliser le codage binaire suivant :
Pas du tout d’accord
0 0 0 0 1
Pas d’accord
0 0 0 1 1
Ni en désaccord ni d’accord
0 0 1 1 1
D’accord
0 1 1 1 1
Tout à fait d’accord
1 1 1 1 1
Cette représentation conserve la relation d’ordre entre modalités, tout en évitant d’imposer une contrainte trop forte sur la représentation des modalités successives, vu qu’une modalité suivante est associée au passage d’une nouvelle variable binaire à 1. Le désavantage de cette représentation est l’augmentation de la dimension des observations.
Pour une variable nominale, sa représentation directe par une variable quantitative suivant un codage ordinal, comme dans le tableau suivant, est fortement déconseillée.
Enseignant
1
Médecin
2
Technicien
3
…
…
En effet, une telle représentation introduit un ordre entre modalités, ordre qui est absent de la signification de la variable. Par exemple, une prédiction qui est dans l’incertitude entre Enseignant et Technicien sera assimilée à Médecin. La représentation préférée pour une variable nominale utilise un codage disjonctif (ou one-hot). Cela consiste à employer autant de variables numériques binaires qu’il y a de modalités différentes pour la variable nominale et faire en sorte que chaque variable binaire prenne la valeur 1 pour une seule des modalités, comme dans le tableau suivant :
Enseignant
1 0 0 …0 0 0
Médecin
0 1 0 …0 0 0
Technicien
0 0 1 …0 0 0
…
…
Cette représentation permet de séparer les différentes modalités mais présente également le désavantage d’une augmentation de la dimension des observations.
Pour les variables qui prennent comme valeurs des sous-ensembles d’un ensemble fixé (« valeurs-ensembles »), la solution usuelle consiste à représenter chaque sous-ensemble (une valeur de la variable) par sa fonction caractéristique. Par exemple, en considérant le vocabulaire des \(10^4\) mots les plus courants de la langue française comme ensemble total, il faut employer \(10^4\) variables binaires, chacune associée à l’un des \(10^4\) mots et indiquant sa présence ou absence. Un texte quelconque (utilisant seulement des mots de ce vocabulaire) est alors représenté par un vecteur binaire de longueur \(10^4\) où chaque bit à 1 indique que le mot correspondant est présent dans le texte. Par exemple, le texte « reconnaissance des formes » serait représenté par un vecteur binaire de longueur \(10^4\) avec seulement trois bits à 1, ceux correspondant aux trois mots « des », « formes », « reconnaissance » (nous avons supposé que les mots du vocabulaire étaient triés par ordre alphabétique), et les autres bits à 0. Cette représentation est illustrée par un vecteur-colonne dans la figure suivante. Une telle représentation est de grande dimension mais très creuse (grande majorité de 0, car chaque texte contient un petit sous-ensemble des \(10^4\) mots). Une lemmatisation permet de réduire la dimension car toutes les formes fléchies d’un mot sont remplacées par sa forme générique (le lemme).
0
a
0
…
1
des
…
…
0
…
1
formes
…
…
0
…
1
reconnaissance
…
…
0
…
Pour les variables à valeurs structurées il est nécessaire de bien comprendre cette structure afin de trouver de bonnes techniques de représentation. Il faut remarquer que les méthodes à noyaux (par ex. les SVM) permettent d’employer des noyaux spécifiques (par ex. noyaux pour arbres, noyaux pour séquences, etc.), que l’on peut voir comme des mesures de similarité entre données, pour travailler directement avec les représentations d’origine des valeurs structurées, sans exiger un recodage par une ou plusieurs variables quantitatives.
En règle générale, pour éviter de biaiser un processus de modélisation à partir de données, la représentation des variables doit être en accord avec la nature des caractéristiques auxquelles ces variables correspondent.
Modélisation : critères de choix, approche générale¶
Nitesh V. Chawla, Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. SMOTE: synthetic minority over-sampling technique. J. Artif. Int. Res. 16, 1 (juin 2002), 321-357.