Les informations concernant l’organisation et le déroulement de l’unité d’enseignement RCP216 « Ingénierie de la fouille et de la visualisation de données massives » au Cnam se trouvent dans ce préambule.
Cours - Introduction¶
[Diapositives du cours : 2 par page] [Diapositives du cours : 1 par page]
La fouille de données peut être définie comme le « Processus d’extraction non triviale d’informations implicites, inconnues auparavant et potentiellement utiles (sous forme de règles, contraintes, régularités) à partir de données issues de bases de données » (Gregory Piatetsky-Shapiro). Si ce domaine est loin d’être nouveau, c’est seulement depuis quelques années que les praticiens se confrontent à de nouvelles difficultés liées à une augmentation significative du volume de données. Cette augmentation a été dans certains cas bien plus rapide que la croissance continue des capacités de calcul et de stockage des serveurs individuels, les volumes résultants étant alors incompatibles avec un traitement centralisé. On parle alors en général de « données massives » (big data).
Mais le volume n’est pas le seul défi (relativement) nouveau pour la fouille de données. Dans un rapport de 2001 le META Group (actuellement Gartner) parlait de 3V : volume, variété, vélocité. En effet, les données massives ne sont plus simplement relationnelles mais se présentent souvent dans une grande diversité (variété) de formats semi-structurés (XML, JSON) ou non structurés (par ex. textes, images, vidéo), qui nécessitent la mise au point de méthodes de fouille (ou au moins de prétraitement) adaptées. Vous pouvez regarder les dernières enquêtes en date sur le site de KDnuggets (enquêtes à prendre avec des précautions car rien ne permet d’évaluer leur représentativité). La vélocité correspond au fait que dans de nombreux cas de nouvelles données arrivent sous forme de flux et doivent être traitées en temps réel (ou dans des délais cohérents avec les flux), ce qui impose de nouvelles exigences sur la latence des opérations de fouille. Enfin, différents intervenants dans ce domaine ajoutent volontiers d’autres V : véracité, valeur, visibilité, etc. Il faut mentionner aussi une autre caractéristique à ne pas négliger, la « faible densité en information », qui limite fortement l’utilité d’un travail réalisé sur un échantillon de faible taille ou sur un nombre réduit de variables.
Les institutions et les entreprises qui possèdent des données (ou qui peuvent en récolter) concernant de près ou de loin leurs activités ne prennent conscience que très progressivement de la valeur que ces données peuvent avoir pour leurs activités. Au-delà des connaissances théoriques et pratiques concernant la collecte, la gestion et la fouille de données massives, il est très important de comprendre ce que peuvent apporter les données qu’on possède (et quelles autres données seraient potentiellement utiles). Les success stories (ou les éventuels échecs ou semi-échecs, lorsqu’ils ne sont pas passés sous silence) apportent des enseignements utiles, si on garde un regard critique pour éviter les pièges de la communication institutionnelle. Voir par exemple la note Analyse des big data. Quels usages, quels défis ?.
Sujet du cours¶
Nous nous intéresserons dans ce cours aux trois défis mentionnés, le volume, la variété et la vélocité, en insistant toutefois sur le premier. Nous verrons quelles sont les approches actuelles pour faire passer à l’échelle la fouille de données et étudierons plus longuement des opérations de fouille en environnement distribué. Nous aborderons dans ce contexte certains problèmes fréquents dans la fouille de données massives. Enfin, nous examinerons le rôle de la visualisation et de l’interaction, non seulement dans la présentation des résultats mais aussi lors des opérations de fouille de données.
Nous considérons que les connaissances statistiques de base sont déjà acquises, que vous avez déjà suivi un enseignement sur les bases de données documentaires et distribuées, et que vous connaissez déjà des méthodes de fouille de données. Dans le cadre du certificat de spécialisation Analyste de données massives, vous devez avoir suivi d’abord le cours Bases de données documentaires et distribuées (NFE204) et le cours Entreposage et fouille de données (STA211).
Contenu et objectifs de l’enseignement¶
Dans la première partie du cours (2/3 du volume horaire) nous examinerons d’abord les principales approches permettant de faire de la fouille sur de très grands volumes de données. La première consiste à réduire le volume de données à traiter (et donc aussi de calculs à faire). On retrouve ici des méthodes classiques qui travaillent sur un échantillon des données et/ou qui réduisent le nombre de variables (la dimension des données). Nous examinerons les techniques d’échantillonnage et rappellerons des méthodes d’analyse factorielle des données (analyse en composantes principales, analyse factorielle discriminante, analyse des correspondances multiples).
Dans cette première approche on trouve également des méthodes (moins populaires dans le domaine de la fouille de données) qui cherchent à réduire l”ordre de complexité des calculs à faire en évitant les calculs à faible potentiel grâce, en général, à l’utilisation de structures d’index multidimensionnels ou métriques. Nous nous intéresserons ici principalement au hachage sensible à la similarité (Locality Sensitive Hashing, LSH) et à son utilisation dans des opérations de recherche par similarité ou de jointure par similarité.
La réduction de volume peut éventuellement permettre de faire le travail de fouille de données sur des plateformes matérielles standard, peu coûteuses. Lorsque cette première approche s’avère insuffisante ou ne peut pas être appliquée en raison de la « faible densité en information », la seconde approche, qui consiste à employer des plateformes parallèles, s’impose. Afin de maximiser le rapport entre la capacité de traitement et les coûts d’exploitation, la solution préférée aujourd’hui est d’utiliser des systèmes composés d’un nombre élevé d’ordinateurs standard, bon marché. Pour faciliter la mise en œuvre des méthodes de fouille de données sur ce type de plateforme, ainsi que pour maximiser la disponibilité malgré les pannes inhérentes d’ordinateurs individuels, un mécanisme d’exécution simple et relativement générique a été proposé, MapReduce. Les auditeurs ayant suivi le cours Bases de données documentaires et distribuées (NFE204) connaissent déjà ce mécanisme. Nous verrons comment écrire certains algorithmes de fouille de données en utilisant les primitives de MapReduce.
Dans la suite du cours nous nous focaliserons sur les particularités des opérations de fouille dans un contexte de données massives. Nous examinerons d’abord les méthodes employées dans les systèmes de recommandation, de plus en plus utilisés dans le marketing et surtout dans la vente en ligne. Nous regarderons ensuite la mise en œuvre de la classification automatique lorsque les volumes de données à traiter sont importants. Dans le développement et l’application de modèles décisionnels sur des données massives nous considérerons le cas des machines à vecteurs de support (Support Vector Machines, SVM) linéaires qui ne sont pas abordées dans le cours Entreposage et fouille de données (STA211). Des informations intéressantes se trouvent souvent dans des données textuelles (messages, tweets, avis, blogs, etc.) et dans des réseaux sociaux, la fouille de textes et la fouille de réseaux sociaux sont donc des sujets très importants. Nous passerons en revue les objectifs de fouille possibles et les opérations associées. La vélocité étant une des caractéristiques clés des données massives, nous examinerons des opérations spécifiques au traitement de données qui arrivent en flux et doivent être traitées en temps réel.
La fin du cours est une présentation synthétique mais concrète du domaine de la visualisation de données. La visualisation est importante à la fois pour faire comprendre les résultats et pour guider de façon interactive les opérations de fouille de données massives. Seront exposées à la fois des questions plus théoriques indispensables concernant notamment la perception humaine et des techniques de représentation et d’interaction, avec leurs spécificités et domaines d’intérêt. La visualisation de graphes recevra plus d’attention.
Les travaux pratiques (TP) sont une mise en œuvre directe de notions et méthodes vues en cours. Les TP emploient le framework open source Spark et le langage de programmation Python (les TP précédents, utilisant le langage Scala, restent accessibles à travers des liens). Une connaissance préalable du langage Python n’est toutefois pas nécessaire, certaines notions indispensables seront vues lors des TP. Il est également possible d’utiliser les librairies de Spark à partir de Java et de Scala si un de ces langages vous est plus familier. Enfin, SparkR et sparklyr permettent d’utiliser une partie des fonctionnalités de Spark à partir de code écrit en R.
Lors des séances de travaux pratiques, après une introduction à Spark et à Python, vous apprendrez à manipuler des données numériques, à utiliser l’échantillonnage, à faire une analyse en composantes principales et une classification automatique, à travailler sur des données textuelles et sur des flux de données, à mettre au point un modèle décisionnel (SVM linéaire), ainsi qu’à faire des opérations de fouille sur des graphes (issus éventuellement de réseaux sociaux). Vous apprendrez également à bien concevoir des visualisations de différents types de données.
Les objectifs de cet enseignement sont :
pour la fouille de données massives, vous faire comprendre les approches de passage à l’échelle, vous familiariser avec un logiciel permettant l’exécution distribuée efficace de méthodes de fouille de données, vous transmettre des méthodes de résolution de problèmes courants de la fouille de données et vous faire appliquer ces méthodes sur des données réelles ;
pour la visualisation, vous faire comprendre les principes et les enjeux, vous transmettre des techniques usuelles ainsi que leurs utilisations et vous familiariser avec la programmation de ces techniques.
Après avoir suivi cet enseignement, les auditeurs doivent avoir la capacité à mettre œuvre, sur des données massives, des techniques de fouille de données et de visualisation interactive.
Quelques références bibliographiques¶
De nombreuses références, sur supports classiques ou électroniques, traitent les différents sujets abordés dans cet enseignement. Vous aurez des références spécifiques dans les différentes séances de cours ou de TP. Nous avons listé ci-dessous quelques références qui couvrent des parties plus larges du contenu de cet enseignement.
Sur la fouille de données massives :
J. Leskovec, A. Rajaraman, J. Ullman. Mining of Massive Datasets. Cambridge University Press.
Karau, H., A. Konwinski, P. Wendell et M. Zaharia. Learning Spark - Lightning-Fast Big Data Analysis. O’Reilly, 2015.
Ryza, S., U. Laserson, S. Owen and J. Wills. Advanced Analytics with Spark - Patterns for Learning from Data at Scale. O’Reilly, 2015.
Sur la visualisation de données et l’interaction :
Fry, B. Visualizing Data. O’Reilly. 2008.
Spence, R. Information Visualization: Design for Interaction. Prentice Hall. 2007.
Passage à l’échelle de la fouille de données¶
Dans le cadre de ce cours, par « passage à l’échelle » (scalability) nous entendrons la capacité à faire face à une augmentation forte du volume de données à traiter. Il faut remarquer que la notion de « passage à l’échelle » est plus large et, même dans un contexte de fouille de données massives, peut concerner d’autres aspects : capacité d’une méthode de fouille à traiter des données décrites par un très grand nombre de variables, capacité d’un outil à gérer ou à traiter des données malgré leur hétérogénéité, etc.
La première approche pour le passage à l’échelle consiste à réduire fortement le volume de calculs à faire. Une première méthode est la réduction (forte) du volume de données, en travaillant sur un échantillon et/ou sur un nombre bien plus faible de variables. Si les données disponibles présentent une « faible densité en information » alors cette méthode ne produira pas de résultats satisfaisants : si l’échantillon est trop petit, les « régularités » recherchées par la méthode de fouille ne se manifesteront pas suffisamment pour être détectables ; si le nombre de variables est trop faible, les « régularités » trouvées seront incomplètes et les capacités prédictives insuffisantes.
Une seconde famille de méthodes suivant cette approche de réduction travaille sur toutes les données (et toutes les variables) mais en exploitant leurs caractéristiques de similarité afin de diminuer l’ordre de complexité des calculs à faire. En effet, les modèles décisionnels sont souvent « locaux » : la décision pour une nouvelle donnée dépend exclusivement ou principalement des données étiquetées proches. Grâce à la construction préalable d’index il est parfois possible de réduire ainsi l’ordre de complexité des calculs à faire, par exemple \(O(N) \rightarrow O(\log(N))\) ou \(O(cst.)\), \(O(N^2) \rightarrow O(N\log(N))\), \(N\) étant le nombre total de données. Ces méthodes peuvent être exactes (fournir les mêmes résultats qu’un calcul exhaustif) ou, plus souvent, approximatives. En revanche, ces méthodes deviennent peu efficaces (réduction insuffisante de la complexité et même augmentation du coût) lorsque le nombre de variables décrivant les données est élevé. Bien entendu, il est possible de combiner réduction du volume de données (par ex. réduction du nombre de variables) et réduction de l’ordre de complexité des calculs.
La seconde approche pour le passage à l’échelle consiste à employer des plateformes de calcul parallèle. Pendant longtemps, les calculs parallèles étaient effectués sur des architectures parallèles dédiées. Non seulement ces architectures étaient très coûteuses à réaliser (et à concevoir), mais elles présentaient en général des points névralgiques et des « goulots d’étranglement », surtout au niveau des échanges entre les unités de calcul et le stockage de masse. Ces architectures sont aujourd’hui encore employées dans des secteurs très spécifiques.
De ces architectures ont également été dérivées des architectures mono-puce adaptées au calcul matriciel, employées au départ principalement pour les cartes graphiques mais qui connaissent une rapide évolution avec le développement relativement récent de l’apprentissage profond (deep learning). Des processeurs matriciels ont également été mis au point plus spécifiquement avec cet objectif.
Afin de maximiser le rapport entre la capacité de traitement et les coûts d’utilisation, la solution souvent préférée à partir des années 2010 consistait à distribuer données et calculs sur un nombre élevé d’ordinateurs standardisés, bon marché, chacun avec son propre stockage de masse, reliés par un réseau local haut débit standard pour former un cluster. La latence associée au transfert de données entre différents ordinateurs, ou entre ordinateurs et un stockage externe, incite à conserver les données sur les unités de stockage des ordinateurs individuels. Les données à traiter étant en général bien plus volumineuses que les programmes à exécuter, il est préférable alors de laisser le plus longtemps possible les données sur les unités de stockage locales des ordinateurs individuels et de transmettre à ces ordinateurs les différents programmes à exécuter sur les mêmes données. Les traitements à appliquer aux données seront ainsi partitionnés en tâches à exécuter par chaque ordinateur sur les données locales. En faisant travailler ensemble des ressources distribuées, cette approche de parallélisation peut être appliquée à une gamme d’algorithmes bien plus large que les calculs matriciels. Par ailleurs, le calcul distribué présente des capacités de passage à l’échelle supérieures aux processeurs graphiques et autres processeurs vectoriels existants. Enfin, des processeurs matriciels peuvent être ajoutés aux ordinateurs du cluster afin de faciliter l’intégration efficace de l’apprentissage profond dans des algorithmes plus larges.
L’emploi d’un nombre (très) élevé d’ordinateurs standard augmente, naturellement, la probabilité de panne d’au moins un des ordinateurs participant à un traitement. Comment faire en sorte que la panne qui se produira de façon inévitable sur un (ou plusieurs) ordinateur(s) n’engendre pas une perte de données ? Un mécanisme de réplication permet de stocker chaque donnée sur plusieurs ordinateurs afin de réduire le risque de perte malgré des pannes individuelles. Comment éviter, en cas de panne sur un (ou plusieurs) ordinateur(s), l’interruption des calculs en cours dans le système distribué, avec obligation de reprise depuis le début (ou le dernier point de validation) ? En partitionnant les calculs en « grains » traçables et suffisamment fins pour qu’en cas de panne les grains abandonnés puissent être efficacement réaffectés aux ordinateurs encore actifs.
MapReduce et la fouille de données¶
Bien entendu, il ne faut pas laisser au programmeur applicatif le soin de mettre en œuvre les mécanismes de réplication, ni de gérer la traçabilité des grains et leur réaffectation. Ces tâches sont de la responsabilité du framework utilisé. Le programmeur applicatif a néanmoins le rôle important (et parfois difficile) de reformuler les algorithmes qu’il souhaite mettre en œuvre sur la plateforme distribuée suivant le mécanisme d’exécution implémenté par le framework. Un mécanisme d’exécution très populaire, présent dans plusieurs frameworks (dont le framework open source Hadoop), est MapReduce. Nous l’examinerons très brièvement ici et vous êtes incités à (re)voir les explications particulièrement bien illustrées de MapReduce, premiers pas (dans l’unité d’enseignement NFE204 du Cnam).
MapReduce propose de décomposer l’ensemble des opérations à réaliser en deux types de tâches élémentaires et uniformes, les Map et les Reduce. Chaque donnée passe d’abord par une tâche Map et ensuite, transformée par celle-ci, éventuellement par une tâche Reduce. En revanche, aucun ordre d’exécution particulier n’est attendu entre différentes tâches Map ou entre différentes tâches Reduce. Une ou plusieurs tâches Map et/ou Reduce peuvent être facilement assignées à chaque nœud de calcul. Par nœud de calcul nous entendons ici soit un ordinateur individuel, soit un cœur d’une unité centrale multi-cœur (dans ce dernier cas, la mémoire vive et le stockage de masse de l’ordinateur sont partagés entre les cœurs).
Le fonctionnement général de MapReduce est le suivant (voir aussi la figure MapReduce : exécution d’un programme) :
L’ensemble de données à traiter est découpé en fragments (chunks).
Chaque tâche Map est assignée à un nœud de calcul qui reçoit un ou plusieurs fragments que la tâche Map transforme en une séquence de paires [clé, valeur].
Chaque tâche Reduce est associée à une ou plusieurs clés et est assignée à un nœud de calcul.
Les paires (clé, valeur) produites par les Map sont groupées par clés et stockées sur les nœuds de calcul qui exécuteront les tâches Reduce respectives (étape shuffle).
Chaque tâche Reduce combine, pour chaque clé qui lui est associée, les valeurs des paires [clé, valeur] avec cette clé ; les résultats sont stockés et constituent le résultat du traitement.
Le programmeur écrit les fonctions Map et Reduce, le framework se charge de tout le reste.
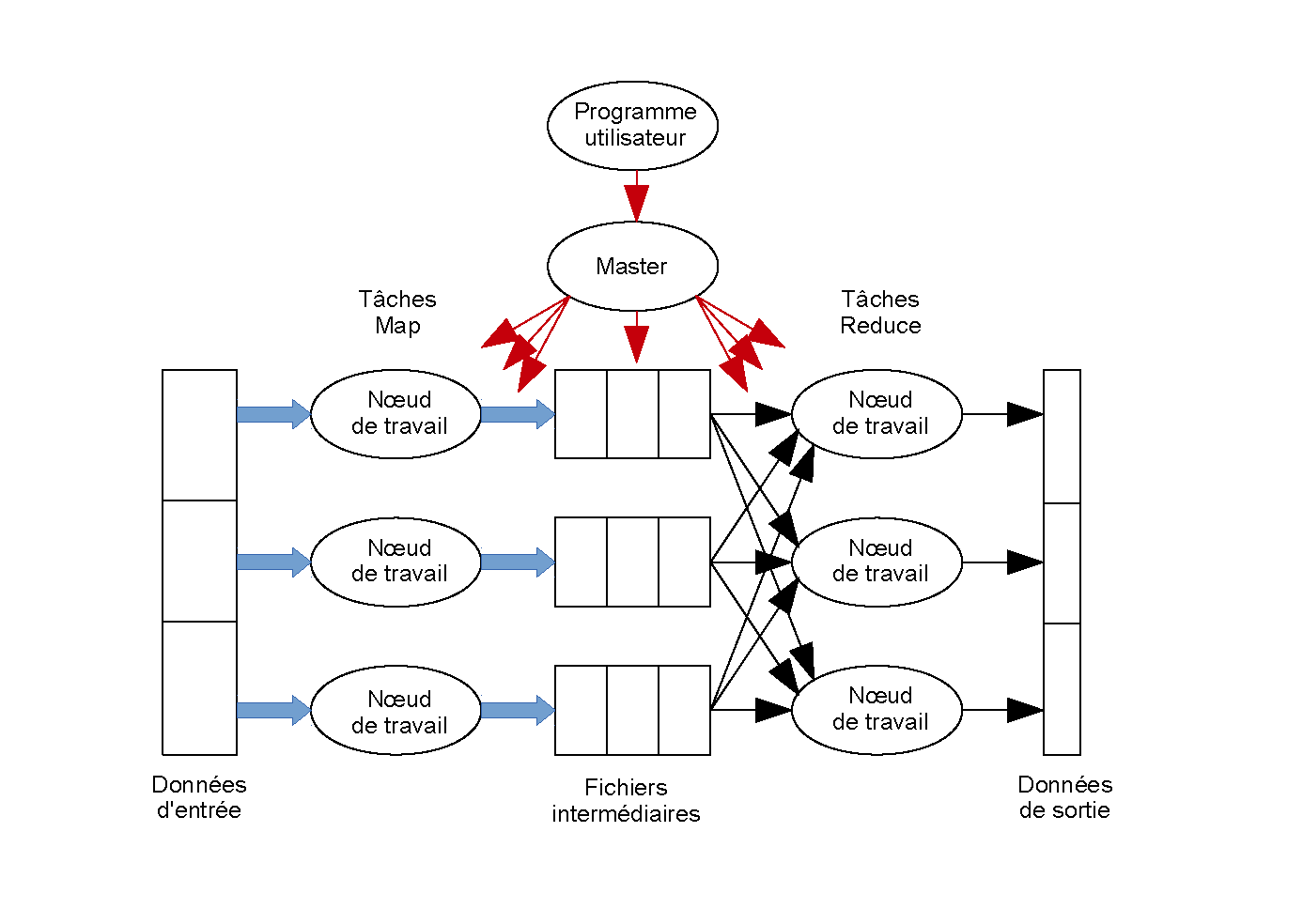
Fig. 1 MapReduce : exécution d’un programme¶
On peut se demander si un mécanisme aussi simple est adapté à une classe suffisamment large d’algorithmes. Pour mieux illustrer l’écriture d’un algorithme en utilisant le modèle d’exécution MapReduce nous considérerons deux exemples classiques. Nous en verrons d’autres plus tard dans ce cours. Le premier exemple classique concerne le comptage du nombre d’occurrences de chaque mot dans une (grande) collection de documents textuels.
Chaque tâche Map est affectée à un nœud de calcul qui travaillera sur son fragment local de données (constitué d’un ou plusieurs documents textuels). Dans le cadre de la tâche Map, chaque nœud de calcul génère une paire [mot, 1] pour chaque occurrence d’un mot dans son fragment local. Les paires [mot, 1] sont ensuite groupées par mots et stockées (étape shuffle). Enfin, chaque tâche Reduce reçoit les paires correspondant à un mot, fait l’addition des valeurs qui lui sont associées dans toutes ces paires et stocke les résultats. Ce processus est également décrit dans l’algorithme suivant :
On considère, pour simplicité, que chaque document constitue un fragment.
Chaque tâche Map est assignée à un nœud de calcul qui reçoit un fragment, le découpe en mots et, pour chaque occurrence d’un mot, génère une paire [mot, 1] (la clé est ici le mot lui même, la valeur est égale à 1).
Chaque tâche Reduce est associée à une ou plusieurs clés (mots) et est assignée à un nœud de calcul.
Les paires [mot, 1] produites par les Map sont groupées par mots et stockées sur les nœuds de calcul qui exécuteront les tâches Reduce respectives (étape shuffle).
Chaque tâche Reduce reçoit les paires [mot, 1] correspondant à un mot, fait l’addition des valeurs 1 associées au mot et stocke le résultat.
Remarque : l’addition étant associative et commutative, il est possible de transférer dans les Map une partie des calculs des Reduce ; ainsi, une tâche Map peut en plus additionner le nombre d’occurrences de chaque mot dans le fragment qu’elle reçoit et générer plutôt des paires (mot, nombre d’occurrences du mot dans le fragment). Cela permet de minimiser les échanges de données car, au lieu de produire autant de paires [mot, 1] qu’il y a d’occurrences de ce mot dans le fragment, chaque tâche Map ne produira qu’une seule paire (mot, nombre d’occurrences du mot dans le fragment).
On observe ainsi qu’une bonne connaissance de la nature des calculs à faire permet d’améliorer l’efficacité de l’exécution de l’algorithme. Bien entendu, cela n’est pas toujours aussi facile que dans l’exemple précédent.
Le second exemple concerne la multiplication (grande) matrice x vecteur : \(\mathbf{y} = \mathbf{M} \times \mathbf{x}\) (ou \(y_i = \sum_{j=1}^n m_{ij} x_j\)).
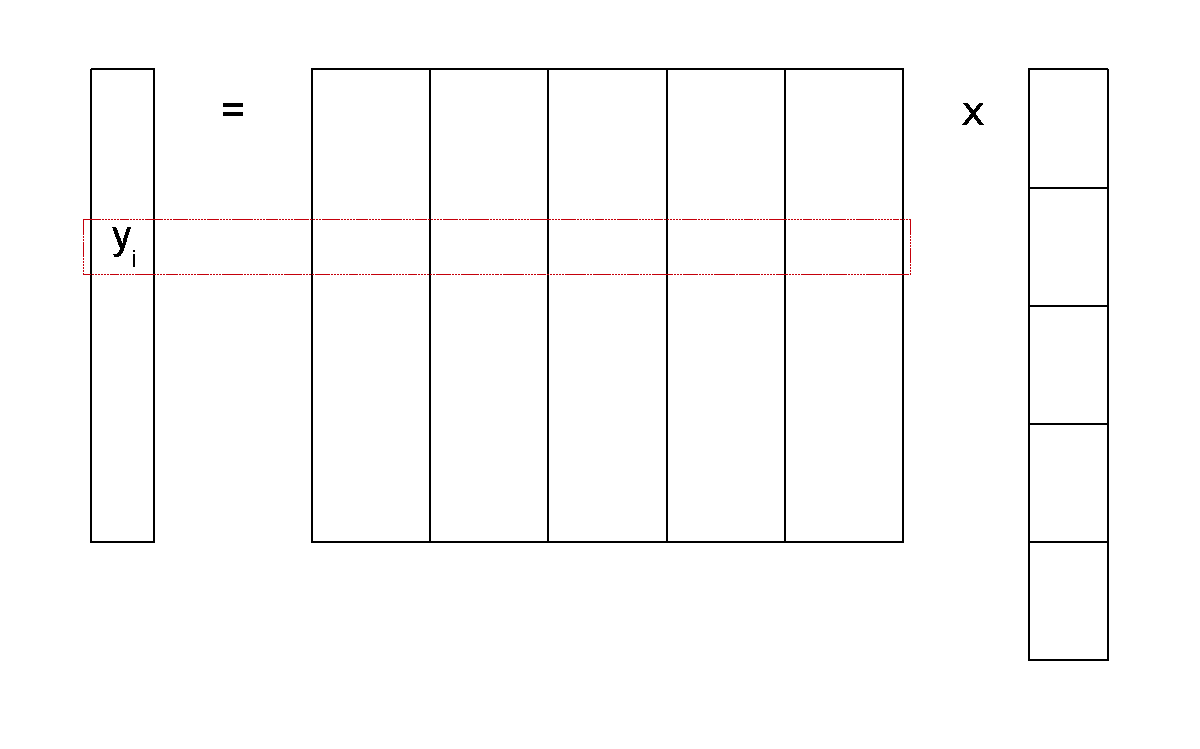
Fig. 2 Multiplication matrice x vecteur¶
La (très grande) matrice \(\mathbf{M}\) est découpée en fragments qui sont des groupes de colonnes ; un fragment doit tenir dans la mémoire d’un nœud de calcul. Le vecteur \(\mathbf{x}\) est aussi découpé en groupes de lignes de façon correspondante.
Chaque tâche Map est assignée à un nœud de calcul qui reçoit un fragment de la matrice \(\mathbf{M}\) et le fragment correspondant de \(\mathbf{x}\) ; pour chaque élément \(m_{ij}\) de son fragment, calcule \(m_{ij} x_j\) et génère \((i, m_{ij} x_j)\).
Chaque tâche Reduce est associée à une ou plusieurs valeurs de \(i\) et est assignée à un nœud de calcul.
Les paires \((i, m_{ij} x_j)\) sont groupées par \(i\) et stockées sur les nœuds de calcul qui doivent exécuter les tâches Reduce respectives (étape shuffle).
Chaque tâche Reduce reçoit les paires correspondant une valeur de la clé \(i\), fait l’addition des valeurs qui lui sont associées et stocke les résultats.


Bien qu’intéressant car il permet de tirer profit du framework open source Hadoop, le mécanisme d’exécution MapReduce est aussi assez contraignant. D’abord, même si la définition des Map et Reduce est assez générique, le niveau d’abstraction reste assez bas ; les algorithmes rencontrés dans la fouille de données sont souvent itératifs, le programmeur d’un tel algorithme doit définir les opérations des Map et Reduce dans le cadre d’une même itération, mais aussi relier entre elles les itérations successives. Ensuite, le mécanisme de reprise sur panne de MapReduce impose le stockage des résultats des Reduce, or pour un algorithme itératif ces résultats ne sont qu”intermédiaires : l’itération suivante doit prendre ces résultats comme données d’entrée. Ce stockage des résultats intermédiaires engendre un ralentissement très significatif des algorithmes.
La comparaison des débits entre les différents niveaux de la hiérarchie de stockage, voir la figure suivante, montre bien que la sauvegarde des résultats intermédiaires, à chaque itération, sur un stockage de masse (disques classiques ou SSD) ralentit inévitablement et significativement le déroulement des algorithmes itératifs par rapport à un maintien des résultats intermédiaires en mémoire.
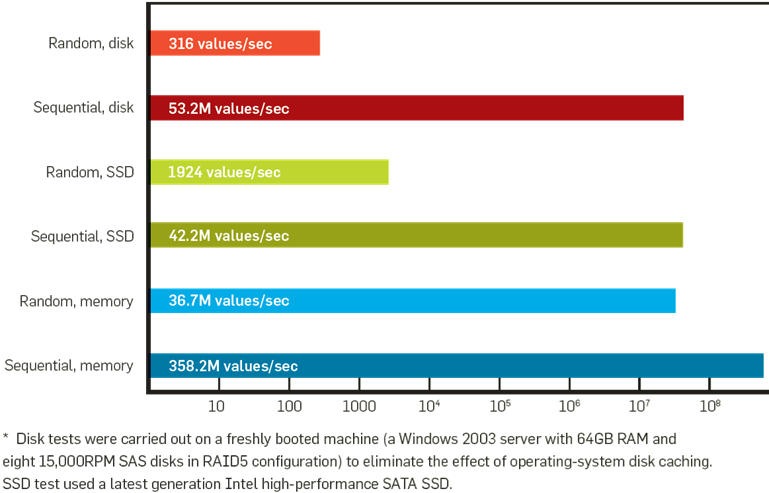
Fig. 3 Hiérarchie de stockage (issue de Communications of the ACM 2009 (8): 36-44)¶
Spark et la fouille de données¶
La solution de Spark (https://spark.apache.org) est de conserver les résultats intermédiaires dans la mémoire vive des nœuds de calcul et de garder l’historique des opérations ayant permis d’obtenir ces données. En cas de panne, l’historique permet de recalculer les données perdues (car stockées dans la mémoire vive d’un nœud de calcul tombé en panne) à partir des dernières données encore disponibles. L’impact de cette évolution sur les algorithmes itératifs est très significatif, une accélération de 10 fois par rapport au mécanisme MapReduce de départ peut être observée. A la base de ce fonctionnement on trouve les Resilient Distributed Dataset (RDD) qui sont des collections de données partitionnées en fragments (ou partitions, chunks) distribués sur les nœuds de calcul et conservés (autant que possible) en mémoire. Vous êtes incités à (re)voir aussi les explications de la séance Traitement de données massives avec Apache Spark de l’unité d’enseignement NFE204 du Cnam, ainsi que cette séance de travaux pratiques de notre cours.
Il faut noter que la représentation des données a évolué dans l’API plus récente de Spark vers les Dataset/DataFrame. Un Dataset est une collection distribuée de données fortement typées et représentées en format binaire, alors que les données d’un RDD sont représentées par des JavaObjects. Par ailleurs, un Dataset est le résultat de l’application d’un plan d’exécution issu d’un optimiseur, alors qu’un RDD est obtenu en suivant telles quelles les opérations programmées. Un DataFrame est un Dataset organisé en colonnes nommées et est similaire de ce point de vue aux tables d’une base de données relationnelle. Une explication assez détailée de l’évolution du format de stockage employé par Spark et des raisons qui justifient cette évolution peut être trouvée dans Apache Spark - Deep Dive into Storage Formats.
Notre choix d’utiliser Spark pour les travaux pratiques de cet enseignement est justifié par l’efficacité de la solution proposée, la gestion globalement implicite du parallélisme, les fonctionnalités actuelles (mais aussi les perspectives de développement) et l’existence de librairies qui couvrent non seulement la fouille de données mais aussi le traitement des graphes et des flux de données, donc la totalité des sujets abordés dans la première partie du cours. Enfin, Spark est toujours un projet très actif de la fondation Apache.
Parmi les librairies existantes de Spark, dans le cadre des travaux pratiques nous nous servirons de :
MLlib : analyse des données, fouille de données, apprentissage statistique ;
Spark Streaming : traitement de flux de données (par ex. Twitter, ZeroMQ, Kinesis, sockets TCP) ;
GraphX : calculs sur les graphes (data-parallel et graph-parallel) ; remplace Pregel.
Spark permet d’exécuter des programmes en Scala, en Java et en Python. Un programme Spark tourne dans une machine virtuelle Java. Le code Scala peut appeler de façon native des librairies écrites en Java (et inversement), ce qui n’est pas le cas avec Python. Depuis la version 1.5, il est possible d’exécuter du code R en bénéficiant de la plateforme Spark (avec SparkR ou sparklyr, mais le spectre des méthodes accessibles est moins large que pour les langages Scala, Java et Python).
Examinons maintenant brièvement le déploiement de Spark (voir aussi https://spark.apache.org/docs/latest/cluster-overview.html). La figure suivante présente le déploiement sur un cluster d’ordinateurs (ensemble d’ordinateurs interconnectés et gérés de façon unifiée).
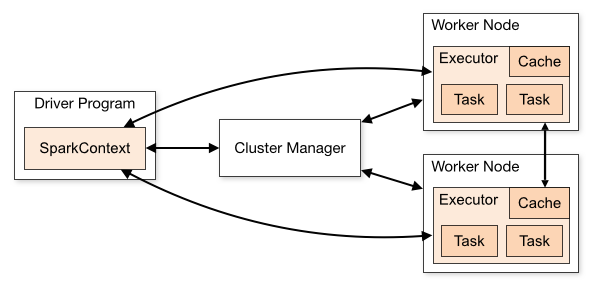
Fig. 4 Déploiement sur cluster (figure issue de la documentation de Spark)¶
Le programme driver contrôle la logique de l’application et distribue les tâches aux nœuds de calcul (worker nodes). En raison des communications nécessaires entre le driver et les workers, le driver devrait tourner sur un nœud du cluster.
Le gestionnaire de cluster (cluster manager) veille à la bonne gestion des ressources du cluster. Comme gestionnaire de cluster, Spark propose le sien (mode autonome ou standalone, pas d’intégration avec d’autres opérations), mais permet d’utiliser Apache Mesos (intégration possible avec d’autres opérations basées sur MapReduce), Hadoop YARN (intégration possible avec d’autres opérations basées sur MapReduce ou non-MapReduce) ou Kubernetes (gestion d’applications dans des conteneurs).
Plusieurs applications Spark différentes exécutées sur les mêmes nœuds de calcul sont complètement isolées entre elles car chacune tourne dans une machine virtuelle Java (JVM) spécifique et est donc isolée des autres. Ces applications peuvent communiquer entre elles uniquement à travers des fichiers.
Autres plate-formes d’exécution parallèle : Dask et Ray¶
Pour finir, quelques mots concernant deux autres plate-forme d’exécution parallèles populaires parmi les utilisateurs du langage Python : Dask et Ray.
Dask est une solution Python native développée à partir de 2014, qui a pour principal objectif la parallélisation facile de programmes qui emploient les API Python courantes comme NumPy et Pandas. Le support GPU est assuré via RAPIDS cuDF et CuPy. Dask inclut un scheduler pour le déploiement.
Ray est développé (en C++) depuis 2017 avec comme objectif la parallélisation d’algorithmes en Python et utilisée, entre autres, par OpenAI. Ray propose une API Python générique ainsi que des bibliothèques spécifiques pour l’apprentissage statistique (supervisé, par renforcement). Trois primitives importantes dans Ray sont Task (fonction, stateless), Actor (instance, stateful) et Object (donnée). Ray propose un modèle de parallélisme plus général que Spark et inclut un scheduler évolué. En revanche, le support des opérations relationnelles est limité dans Ray.
Le choix entre ces plate-formes n’est pas simple, d’autant plus qu’on peut aussi envisager des solutions de type Spark on Ray, Ray on Spark, Dask on Ray. Il est nécessaire de tenir compte de l’échelle des données, de la nature exacte des tâches à réaliser, de la facilité de prise en main souhaitée et éventuellement du support attendu. On peut considérer que pour le moment Spark et Ray sont mieux adaptés que Dask aux données massives, avec Spark préféré pour la préparation des données et à l’application d’un modèle, et Ray pour le développement du modèle. Pour une comparaison plus détaillée voir par exemple cette discussion. Il est important de noter que ce domaine est en évolution rapide.