Les données textuelles contiennent des informations potentiellement très utiles pour la fouille. Ces données sont présentes sous des formes très diverses, allant de textes élaborés, avec une bonne conformité grammaticale, à de simples « mots-étiquettes » (tags, souvent parties de mots ou mots issus d’un lexique de groupe), en passant par des phrases incomplètes en langage SMS, présentant un lexique particulier, de nombreuses fautes d’orthographe et une syntaxe très simplifiée. Ces données sont destinées à être lues et comprises par des humains, parfois appartenant à des groupes restreints.
Si les opérations de fouille de données s’appliquent à une population de \(m\) observations, nous considérons ici que chaque observation est caractérisée par un ensemble de variables quantitatives et nominales mais aussi par un texte (ou liste de mots-clés ou de tags). L’ensemble de ces textes sera noté par \(\mathcal{T}\), avec \(card(\mathcal{T}) = m\).
Au-delà de difficultés relativement superficielles, comme la non conformité lexicale ou syntaxique, le problème principal dans la fouille de données textuelles est le « fossé sémantique », c’est à dire l’écart entre l’interprétation qu’un ordinateur peut obtenir automatiquement à partir d’un texte et la signification de ce même texte pour un humain (de la catégorie ciblée par le texte). Des difficultés de même nature se manifestent pour la fouille d’autres types de données, comme les images ou les vidéos.
Même si les méthodes d’analyse de données textuelles ne sont pas encore capables de combler ce fossé sémantique, il est néanmoins souvent possible d’extraire de façon automatique des informations utiles à partir des données textuelles. Le volume de données aide parfois ce processus d’extraction d’informations. Comme les données textuelles ne sont pas directement exploitables par les méthodes classiques de fouille de données, des traitements préalables sont nécessaires suivant l’objectif visé.
Parmi les principaux objectifs de la fouille de données textuelles, nous pouvons mentionner :
L’identification de thèmes, qui vise à regrouper des textes (ou parties de textes, ou ensembles de tags, etc.) en thèmes inconnus a priori. Cela implique en général l’utilisation de méthodes de classification automatique sur des données textuelles dont la représentation a été adaptée, par exemple par le passage à des représentations vectorielles (que nous examinerons plus loin). Il est parfois utile de trouver les occurrences de parties spécifiques des textes, comme les entités nommées, afin de les représenter séparément.
Le classement de textes, qui vise à affecter des textes (ou parties de textes, ou ensembles de tags, etc.) à des catégories (classes) prédéfinies. Cela passe en général par l’application de modèles décisionnels, obtenus par apprentissage supervisé, à des représentations vectorielles de textes (ou d’ensembles de tags). La détection d’entités nommées, à représenter séparément, peut être utile.
L’extraction d’informations, qui vise à mettre en correspondance des textes avec des « schémas » d’interprétation prédéfinis. Un schéma d’interprétation regroupe plusieurs variables qui reçoivent des valeurs à partir du texte traité. Ces variables sont ensuite utilisées pour la fouille, conjointement avec d’autres variables (quantitatives, nominales) décrivant la même population. Dans certains cas il est possible d’identifier de telles « variables » à partir d’un ensemble de textes, sans avoir à définir un ou plusieurs schémas a priori.
Rappelons ici que la fouille de textes protégés par le droit d’auteur, même en accès ouvert sur le web, est interdite (sauf accord explicite des auteurs) dans la plupart des pays européens. Le Royaume-Uni est une exception notable à cette règle.
Comme l’indiquent les dernières enquêtes en date sur le site de KDnuggets (à prendre avec des précautions car rien ne permet d’évaluer leur représentativité), la fouille de données s’intéresse beaucoup aux données textuelles. Dans ces enquêtes on trouve des données textuelles aussi bien dans le type text que dans les sources Twitter, web content, email ou social network (en partie).
Avant de regarder de plus près les opérations de traitement nécessaires, il est utile de passer en revue quelques applications afin de mieux comprendre leurs exigences pour la fouille de textes.
La gestion de la relation client regroupe plusieurs applications potentielles de la fouille de textes. Il est possible de déterminer des catégories de clients à partir des termes employés dans leurs échanges avec le service client. Une classification thématique des textes des courriels adressés au service client peut aider à rediriger les courriels mal adressés au départ. Les causes de retours négatifs fréquents peuvent être identifiées par la détection d’entités nommées dans les messages ou éventuellement la mise en correspondance avec des schémas d’interprétation. L’image d’une famille de produits peut être caractérisée par la nature des retours (au service client, sur des forums web) et les termes employés dans ces retours. La mise en correspondance avec des schémas d’interprétation peut permettre de déterminer, dans des suggestions faites au service client, des attentes majeures pour l’évolution des produits.
L’identification de tendances à partir de messages postés sur des médias sociaux. Le classement thématique de textes ou d’intitulés de messages permet d’identifier les fils de discussion d’intérêt. L’association fréquente d’entités nommées correspondant à des produits ou familles de produits ou marques et de mots (répertoriés au préalable ou non) fournit des indications sur l’appréciation des produits ou marques, sur l’impact affectif d’événements liés à des marques ou sur des caractéristiques recherchées pour ces produits.
L’identification de supports adaptés pour la publicité en ligne. Le classement thématique de textes ou d’intitulés de messages, ainsi que l’identification d’entités nommées correspondant à des produits ou familles de produits ou marques, permettent de catégoriser et donc de cibler des blogs ou des fils de discussion sur des forums.
L’identification de risques sécuritaires par la surveillance d’échanges sur des réseaux sociaux. Cela passe en général par le classement thématique de messages et de fils de discussion, avec suivi de l’évolution thématique, ainsi que par la quantification de l’impact affectif d’événements. Le classement thématique fait appel à des listes de mots ou de locutions (groupes de mots) qui évoluent en général dans le temps. La quantification de l’impact affectif d’événements nécessite un classement sur la base de locutions faisant référence à des événements, ainsi qu’une extraction de mots et locutions caractérisant ce type d’impact.
L’identification de concepts ou de liens entre concepts. Il arrive fréquemment que plusieurs communautés s’intéressent à un même concept mais avec des perspectives différentes ou des outils méthodologiques distincts. Une communauté suit rarement les travaux qui se déroulent dans une autre communauté. Pour profiter de résultats obtenus dans d’autres communautés il est nécessaire de pouvoir déterminer les concepts communs ou de trouver des liens entre les concepts. La fouille de textes cherchera dans une telle situation à « cartographier » progressivement les concepts de chaque communauté (quels sont les concepts et les liens entre ces concepts) et à associer ensuite des parties de cartes entre différentes communautés. Les concepts sont désignés par des entités nommées (pas nécessairement les mêmes entre communautés différentes), des outils de recherche d’entités nommées sont donc nécessaires. Dans une même communauté, les liens entre concepts seront issus souvent de proximités dans le texte entre les entités nommées correspondantes. Entre communautés, les liens sont établis à partir de concepts très vraisemblablement communs (entités nommées très similaires) et sont ensuite étendus à d’autres concepts grâce à leurs contextes sur les cartes intra-communautés.
La fouille de données textuelles passe par plusieurs étapes brièvement décrites dans la suite. Toutes ces étapes ne sont pas systématiquement présentes, le choix des étapes nécessaires dépend de l’objectif et du contexte de la fouille. Certaines étapes, comme la collecte de données ou le pré-traitement, font partie de tout projet de fouille de données et présentent des particularités qui dépendent de la nature des données.
La collecte des données textuelles. On trouve en général dans cette étape l’identification des sources, la récupération des contenus à partir de ces sources et l’extraction des textes à partir des contenus obtenus. Par exemple, une page web contient aussi d’autres données comme le balisage HTML, des menus, parfois des scripts Javascript, etc., qui doivent en général être séparés des données textuelles à traiter.
Le pré-traitement des données textuelles. Les données textuelles collectées peuvent présenter une certaine diversité ou d’autres caractéristiques qui entravent les opérations d’analyse, des pré-traitements sont donc souvent nécessaires. On inclut ici l’uniformisation du codage (d’autant plus importante pour des caractères à accents), l’élimination éventuelle de certains caractères spéciaux (symboles, etc., suivant l’objectif), la « traduction » éventuelle d’éléments de langage SMS, etc.
L”extraction d’entités primaires. Le texte est découpé en mots et signes de ponctuation. Des locutions (groupes de mots qui forment une même entité) nominales (« chemin de fer »), verbales (« arrondir les angles »), etc., peuvent éventuellement être extraites si elles sont présentes dans le lexique employé.
L”étiquetage grammatical ou étiquetage morpho-syntaxique (part-of-speech tagging ou POS tagging). Chaque entité primaire extraite du texte (mot, très rarement locution) est caractérisée par une catégorie (et éventuellement une sous-catégorie) lexicale comme nom, verbe, adverbe, etc., des informations concernant le genre, le nombre, la conjugaison, etc. Est parfois proposée une fonction dans la phrase, comme sujet, complément d’objet direct, etc., mais cela exige en général une analyse syntaxique.
L”extraction d’entités nommées. Les entités nommées peuvent être des noms de personnes (« Louis XIII »), de lieux (« Mont Blanc »), d’organisations (« Nations Unies »), des dates, etc., et jouent souvent un rôle important dans les opérations de fouille.
La résolution référentielle cherche à identifier l’entité, explicitement présente ailleurs dans le texte, à laquelle se réfère une partie d’une phrase ; par ex., à qui fait référence Il dans « Barack Obama est le 44ème président des États-Unis. Il est né le 4 août 1961 à Honolulu ». Cela est d’autant plus important qu’une règle stylistique souvent respectée conseille d’éviter la répétition.
L”analyse syntaxique cherche à mettre en évidence la structure hiérarchique des phrases d’un texte et joue un rôle important dans la compréhension du texte. Une analyse complète rencontre de nombreuses difficultés et n’est souvent pas indispensable par rapport à l’objectif poursuivi, une analyse partielle est ainsi le plus souvent pratiquée. On peut mentionner, par exemple, le traitement de la négation (pour permettre la distinction entre affirmation et négation) ou la « quantification » d’une variable à partir des adverbes employés (par ex. « très abouti / plus ou moins abouti / peu abouti »).
L”extraction d’informations cherche à mettre des textes en relation avec des schémas d’interprétation pré-définis et fait appel pour cela à plusieurs outils dont l’extraction d’entités nommées, l’analyse syntaxique superficielle, l’analyse pragmatique, etc.
La lemmatisation consiste à remplacer chaque mot (par ex. « pensons ») par sa forme canonique (« penser »), alors que la racinisation le remplace par sa racine (« pense », dans l’exemple). Cette étape est utile pour la classification thématique de textes (en passant ou non par des représentations vectorielles) car elle permet de traiter comme un mot unique les différentes variantes issues d’une même forme canonique ou racine. Noter que la racinisation notamment peut engendrer des confusions, par ex. « organ » est à la fois la racine de « organe » et de « organisation ».
La représentation vectorielle des textes vise à faciliter l’application aux textes de méthodes de fouille conçues pour des données vectorielles. Plusieurs techniques différentes existent, à commencer par le modèle classique de Salton [SMG86], avec différentes pondérations, en passant par l’applications de méthodes de réduction de dimension comme dans l’analyse sémantique latente (LSA, [DDL90]) et en allant jusqu’aux représentations compactes de type Word2Vec ([MCC13], [MSC13]), BERT ([DCL18]), GPT ([RNS18], [RWC19], [BMR20]).
Le développement de modèles sur la base du contenu textuel seul ou en ajoutant des variables quantitatives et nominales.
L’utilisation des modèles développés et l’évaluation des résultats.
Nous examinons maintenant les principales opérations réalisées lors des différentes étapes spécifiques à la fouille de données textuelles.
Collecte et pré-traitement des données textuelles¶
Les données textuelles potentiellement utiles dans un projet de fouille de données massives peuvent provenir de sources variées et se trouver dans des formats différents. Les opérations suivantes sont en général nécessaires :
Identification des sources. Il est parfois nécessaire de regrouper des données issues de plusieurs sources, données qui peuvent avoir des caractéristiques très différentes :
Les textes sont des séquences parfois longues de phrases structurées et sémantiquement liées entre elles, mais peuvent présenter une conformité lexicale et grammaticale variable. Même si la conformité est moyenne, la présence d’une structuration grammaticale de la séquence de mots aide le traitement de ces données.
Les mots-clés, les « mots-étiquettes » (tags, souvent parties de mots ou mots issus d’un lexique de groupe) se trouvent sous la forme de simples listes, en général courtes (2 à 5 éléments), pour chaque unité d’analyse. Dans ces listes il y a souvent beaucoup de « bruit », dû soit aux fautes de frappe, soit à la présence d’éléments non pertinents (tag spam). L’absence de structure grammaticale qui relierait les mots-clés successifs et, parfois, l’absence de lexique spécifique pour les tags, rendent difficile l’exploitation de ces données. Par ailleurs, le fait que la liste correspondant à chaque unité d’analyse soit courte a un impact négatif sur les résultats de traitements statistiques qui leur sont appliqués.
Les messages de type SMS (qui se retrouvent aussi dans des sources web et non seulement dans les échanges directs entre téléphones portables) sont très souvent constitués de mots issus d’un lexique spécifique, parfois codé, d’expressions ad hoc, sont truffés de fautes de frappe (ou de sélection) et d’émoticônes (smiley). De nombreux traitements spécifiques sont nécessaires, avec des résultats de qualité très variable.
La transcription de la parole présente dans les vidéos téléchargées sur des réseaux sociaux, dans des programmes audiovisuels ou dans des échanges téléphoniques est de plus en plus utilisée comme source de texte. Cette transcription est toutefois difficile et les résultats comportent de nombreuses erreurs de différents types. Cela explique pourquoi sur de telles données on se contente en général d’appliquer des méthodes de recherche de mots-clés (word spotting) puis éventuellement d’extraction d’informations suivant des schémas simples et basés sur les mots-clés.
Au vu de la diversité des caractéristiques des différents types de contenus textuels, il est important d’examiner (avant de démarrer le coûteux travail de collecte des données) dans quelle mesure les sources choisies sont compatibles avec l’objectif de la fouille de données. Par exemple, la résolution référentielle et l’analyse syntaxique exigent en général une assez bonne conformité grammaticale. Aussi, pour employer avec de bons résultats des représentations vectorielles il est en général nécessaire que le volume de données textuelles correspondant à chaque unité d’analyse soit suffisant.
Récupération des contenus à partir des sources. Pour chaque type de source, différents outils sont disponibles. Lorsque les données se trouvent sur des sites web, des outils simples de type wget permettent d”« aspirer » le contenu. Il faut veiller à respecter les règles de chaque site : sous-répertoires autorisés, débit des requêtes, etc. Ne pas oublier que la fouille de textes protégés par le droit d’auteur, même en accès ouvert sur le web, n’est possible qu’avec accord explicite des auteurs. Parfois, les données se trouvent déjà dans un data warehouse géré par exemple par Apache Hive, dans ce cas le langage d’interrogation associé (par ex. HiveQL) devrait permettre de délimiter le domaine des données à extraire.
Extraction des données textuelles. Les contenus récupérés peuvent contenir aussi d’autres données en plus des textes d’intérêt. Par exemple, dans une page web on trouve également le balisage HTML, des menus, parfois des scripts Javascript, etc. Ces données peuvent néanmoins intervenir dans la fouille, par ex. le balisage peut contribuer à pondérer des éléments textuels dans une analyse ultérieure (l’occurrence d’un terme dans un titre peut recevoir un « poids » supérieur à une occurrence dans le texte normal), les liens HTML peuvent servir à construire un graphe utile entre textes ou à identifier des références externes importantes, etc. Pour appliquer des traitements spécifiques aux données textuelles d’intérêt, il est néanmoins nécessaire de les séparer des autres données. Des outils configurables existent, ainsi que des librairies adaptées par ex. aux données XML dans différents langages comme Python, Scala ou Java, directement utilisables à partir de Spark.
Pré-traitements. L’objectif des pré-traitements est d’obtenir pour les données textuelles une représentation uniforme et compatible avec les outils d’analyse ultérieurs. On peut mentionner l’uniformisation du codage des caractères (d’autant plus importante lorsque des caractères accentués sont employés), l’élimination de certains caractères spéciaux (symboles, etc., suivant l’objectif), la « traduction » éventuelle d’éléments de langage SMS, etc. Des librairies adaptées en Python, Scala ou Java sont également disponibles mais une configuration adaptée aux caractéristiques des données est nécessaire.
Les opérations 3, 4 et éventuellement 2 (si les sources sont nombreuses ou alors un débit d’interrogation élevé est autorisé) sont facilement parallélisables sur une plate-forme distribuée car le même traitement doit être appliquée aux différents fragments de données.
L’analyse d’un texte démarre en général par une étape d’extraction d’entités « primaires », employées ensuite pour construire des structures plus complexes ou des représentations vectorielles. Le texte est découpé en lemmes et signes de ponctuation grâce à un outil de segmentation (tokenizer) qui utilise des règles dépendantes de la langue et un lexique. Le lexique contient l’ensemble des lemmes (unités autonomes) d’une langue et/ou d’un domaine particulier (par ex. la biochimie), ainsi que des informations additionnelles, morphologiques (formes possibles, avec racine et suffixes, préfixes) ou parfois syntaxiques. Un lexique peut souvent être enrichi par des lemmes spécifiques
Un lemme peut être constitué d’un ou plusieurs mots. Parmi les lemmes qui comportent plusieurs mots on peut distinguer les mots composés (par ex. « chauve-souris ») et les locutions (groupes de mots qui forment une même entité). On trouve des locutions nominales (« chemin de fer »), verbales (« arrondir les angles »), etc. Si les mots composés sont en général présents dans les lexiques, la situation est plus nuancée pour les locutions. Par ailleurs, la détection de locutions exige parfois une analyse plus approfondie et non seulement une recherche dans un lexique. Par exemple « arrondir les angles » est vraisemblablement une locution dans un texte qui traite de négociations mais n’est probablement pas une locution dans des instructions de débavurage.
Il faut noter ici que l’association des lemmes extraits à des concepts, nécessaire pour l’interprétation des textes, est un problème difficile et incomplètement résolu. Si les cas d”homonymie (un même lemme peut être associé à plusieurs concepts différents, par ex. le lemme « avocat ») ne sont pas si fréquents, une certaine ambiguïté d’interprétation est souvent présente. Les concepts et leurs relations (par ex. sorte_de, partie_de) sont décrits dans des ontologies (générales ou spécifiques à un domaine), qui incluent aussi des informations sur l’expression des concepts par différents lemmes dans une langue particulière. Dans le cadre d’un traitement automatique dont l’objectif est la fouille de données, l’identification des concepts associés aux lemmes extraits sera en général réalisée pour un nombre limité de concepts d’intérêt majeur par rapport au problème.
Lors de l’étape d’étiquetage grammatical ou morpho-syntaxique, chaque lemme extrait est caractérisé par une catégorie lexicale (nom, verbe, adverbe, etc.) et, lorsque cela est pertinent, des informations concernant le genre, le nombre, le mode, le temps, etc. Cette opération n’est pas triviale car de nombreux lemmes peuvent appartenir à plusieurs catégories lexicales. Par exemple, « bien » peut être aussi bien un adverbe (« c’est bien fait »), un nom (« le bien et le mal »), un adjectif (« des gens bien ») ou une interjection (« Bien ! »). Une analyse du contexte est nécessaire pour enlever cette ambiguïté. Cette analyse est souvent superficielle, basée sur sur le voisinage local du lemme dans la phrase. Des erreurs d’étiquetage sont possibles, surtout lorsque le voisinage des lemmes est atypique, en raison par exemple d’une faible conformité grammaticale du texte.
Un exemple d’outil efficace et facile d’emploi est TreeTagger (voir http://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/). L’étiquetage est fait grâce à des règles qui peuvent être fournies directement ou apprises à partir d’exemples.
Considérons une partie du premier paragraphe du chapitre introductif de ce cours, voici les résultats fournis par TreeTagger :
NOM, VER, ADV et ADJ signifient respectivement nom, verbe, adverbe et adjectif, DET:ART signifie « article » , PRP signifie « préposition », PUN signifie « ponctuation » et SENT indique la fin de la phrase. Observons que pour chaque lemme TreeTagger fournit sa forme canonique (« pouvoir » pour « peut », « le » pour « la »).
Extraction d’entités nommées et résolution référentielle¶
Une entité nommée est un élément du langage qui fait référence à une entité unique du domaine du discours. Les entités nommées peuvent être de différents types : noms de personnes (« Barack Obama Jr. »), de lieux (« Mont Blanc »), d’organisations (« Mouvement international de la Croix-Rouge et du Croissant-Rouge »), de produits (« iPhone 6s », « Galaxy S6 »), dates (« 5 mai 1789 », « 18 brumaire 1799 »), etc. L’extraction des entités nommées est très utiles dans la fouille de données textuelles car ces entités donnent des indications fortes sur le contenu d’un texte.
Les premières approches d’extraction étaient basées sur l’utilisation de règles définies explicitement et impliquaient donc une étape préparatoire laborieuse. Les approches plus récentes font appel à des méthodes d’apprentissage à partir d’un corpus annoté, avec éventuellement la prise en compte d’un nombre limité de règles explicitement définies. Les règles d’extraction doivent prendre en compte le contexte en raison de difficultés liées à la polysémie (par ex. l’entité « Washington » fait référence à la ville, à l’état ou à la personne) ou à la métonymie (par ex. « l’Elysée » fait référence à la présidence de la République Française ou simplement au palais).
On peut considérer que les meilleurs outils permettent l’extraction correcte de 90 à 95% des entités nommées génériques et s’approchent ainsi des performances d’un humain. Si les entités sont spécifiques à un domaine, un travail important est néanmoins nécessaire pour définir des règles adéquates ou annoter un corpus suffisant.
La résolution référentielle (correspondant globalement à entity linking) cherche à résoudre les problèmes de coréférence, c’est à dire à identifier l’entité, explicitement présente ailleurs dans le texte, à laquelle se réfère une partie d’une phrase. Par exemple, à qui fait référence le pronom Il dans « Barack Obama est le 44ème président des États-Unis. Il est né le 4 août 1961 à Honolulu ». Cela est d’autant plus important qu’une règle stylistique souvent respectée dans les textes rédigés conseille d’éviter la répétition. L’emploi de plusieurs mots ou groupes de mots différents pour désigner une même entité est aussi un problème de coréférence, comme dans « Google […]. La société de Mountain View […] » (le siège de Google est à Mountain View et Google est la société la plus connue ayant son siège à Mountain View).
Plusieurs types de méthodes contribuent au traitement de la coréférence car tous les problèmes ne sont pas de même nature. Si la résolution pronominale (exemple avec Il ci-dessus) fait plutôt appel à l’analyse syntaxique, pour relier entre elles les différentes façons de désigner une même entité il est en général nécessaire de disposer d’une base de données et éventuellement de quelques règles spécifiques. La qualité des résultats dépend fortement de la complétude de la base de données.
L’analyse syntaxique cherche à mettre en évidence la structure hiérarchique des phrases d’un texte et joue un rôle important dans la compréhension du texte. Bien entendu, l’analyse syntaxique n’a de sens que si les données textuelles sont sous forme de phrases et non simplement de mots-clés. Aussi, la bonne conformité grammaticale est critique pour ce type d’analyse. Une analyse complète doit produire un ensemble d’arbres syntaxiques décrivant chaque phrase du texte et permettant ultérieurement son « interprétation ».
Dans la pratique, l’analyse syntaxique rencontre de nombreuses difficulté même sur des textes qui présentent une assez bonne conformité grammaticale. Parmi les causes de ces difficultés nous pouvons mentionner la présence de mots hors lexique, de structures non répertoriées par la grammaire, ainsi que de diverses formes d’ambiguïté. La conséquence de ces difficultés est en général la présence d’un nombre élevé d’arbres d’analyse pour chaque phrase, qui mènent à une multitude d’interprétations entre lesquelles un choix automatique est souvent impossible. Les travaux actuels visent des méthodes d’analyse « robuste », qui proposent une analyse pour chaque élément avec peu d’analyses alternatives.
Heureusement, une analyse syntaxique complète n’est en général pas indispensable par rapport à l’objectif de fouille de texte. Il est possible de pratiquer une analyse « de surface » qui ne met pas en évidence la structure complète des phrases et ne cherche pas à enlever toute ambiguïté, mais se contente d’extraire des parties (chunks) comme les groupes nominaux et les groupes verbaux, ainsi que des relations simples entre eux. Parfois c’est une analyse partielle qui est employée, analyse qui se concentre sur des fragments spécifiques importants qui présentent des constructions simples et avec peu de variabilité. On peut mentionner, par exemple, le traitement de la négation (pour permettre la distinction entre affirmation et négation) ou la « quantification » d’une variable à partir des adverbes employés (par ex. « très abouti / plus ou moins abouti / peu abouti »). L’analyse peut aussi être limitée au voisinage de certains lemmes jugés importants pour l’interprétation, comme des entités nommées.
L’extraction d’informations à partir de textes est un des principaux objectifs de la fouille de textes. Cette étape vise à mettre en correspondance des textes avec des « schémas » d’interprétation prédéfinis qui ont un rapport direct avec l’application de fouille. Un schéma d’interprétation (ou patron sémantique) regroupe plusieurs variables qui ont un rapport direct avec l’application de fouille, par exemple :
[Fait: ?]{[Où: ?][Quand: ?][Qui: ?][Nature: ?]…}
Ces variables reçoivent des valeurs à partir de l’analyse du texte traité qui sera ainsi décrit à travers un ou plusieurs schémas. Les variables des schémas sont ensuite utilisées pour la fouille, conjointement avec d’autres variables (quantitatives, nominales) décrivant la même population.
Considérons par exemple le texte « Tôt le 25 avril 1974, au Portugal, des capitaines en rupture avec le système de Salazar se révoltent et prennent le pouvoir ». L’analyse de ce texte doit permettre de donner les valeurs suivantes au schéma défini ci-dessus :
[Fait: événement politique]{[Où: Portugal][Quand: 25/04/1974][Qui: forces armées][Nature: prise de pouvoir]…}
Si on considère un autre schéma, mieux adapté à la représentation du contenu d’interventions sur des médias sociaux, par ex.
alors le texte « J’ai été terriblement déçu par ce roman. Je trouvais l’écriture fade et le style pseudo-éthérique très agaçant », devrait permettre d’obtenir
L’extraction d’informations demande en général de définir le lexique et les entités nommées d’intérêt, les schémas d’interprétation pertinents et des règles d’inférence spécifiques (permettant d’identifier dans le texte les valeurs à affecter aux différentes variables du schéma). Cela implique en général un travail spécifique conséquent.
Suivant la complexité des schémas et la nature des textes traités, différentes opérations peuvent être nécessaires pour identifier le(s) schéma(s) adapté(s) à un texte est extraire de ce texte les valeurs des variables correspondantes : l’étiquetage grammatical, l’extraction d’entités nommées, la résolution référentielle, l’analyse syntaxique locale, des règles d’inférence issues d’une ontologie ou définies spécifiquement, des règles pragmatiques (par ex. concernant la mise en forme du texte), etc.
Dans des textes et parfois dans des listes de mots-clés, un même lemme du lexique peut prendre des formes variables. Par exemple, en français la forme d’un verbe varie suivant le mode, le temps, la personne et le nombre. Ces différences, nécessaires pour certaines opérations comme l’étiquetage grammatical et l’analyse syntaxique, peuvent nuire à d’autres opérations. Par exemple, pour la classification thématique de textes (en passant ou non par des représentations vectorielles) il est préférable de traiter comme un lemme unique les différentes variantes issues d’une même forme canonique (par ex. « penser » plutôt que « pensons », « pense », « penserons »). Cela permet d’ignorer une partie de la variance (stylistique, pragmatique, etc.) pour se concentrer sur le fond thématique. Également, diverses ressources linguistiques comme les ontologies contiennent des règles dans lesquelles seules les formes canoniques sont présentes ; leur utilisation nécessite donc une étape préalable de mise sous forme canonique.
Deux opérations différentes peuvent être employées pour réduire cette variabilité de formes. La lemmatisation consiste à remplacer chaque mot (par ex. « pensons ») par sa forme canonique (« penser »). La racinisation consiste à remplacer chaque mot (par ex. « pensons ») par sa racine (« pense »). Notons que la racine n’est pas nécessairement un mot de la langue, par ex. la racine de « cheval » et de « chevaux » est « cheva ». La lemmatisation fait appel à l’analyse lexicale avec étiquetage grammatical. La racinisation emploie plutôt des règles simples de construction des mots dans une langue spécifique.
La racinisation engendre assez souvent des confusions entre lemmes différents qui ont une même racine, par ex. « organ » est aussi bien la racine de « organe » que de « organisation ». L’élimination du préfixe peut également avoir un impact négatif sur les étapes de traitement ultérieures, par ex. « mange » est aussi bien la racine de « mangeable » que de « immangeable ». Ces confusions étant plus fréquentes en français, la lemmatisation est en général préférée pour le français alors qu’en anglais la racinisation est souvent employée.
L’analyse et la fouille de données font souvent appel à des méthodes qui travaillent sur des représentations vectorielles des données. Pour appliquer de telles méthodes à des données textuelles (ou à des données qui combinent textes, variables quantitatives et variables nominales), il est nécessaire de pouvoir représenter des textes (ou des ensembles de mots-clés ou de tags) sous une forme vectorielle. Le modèle vectoriel de texte de Salton [SMG86] a été employé (avec diverses variations et améliorations) pour la recherche d’informations et la classification thématique de textes durant de nombreuses années. Plus récemment, la disponibilité de corpus très vastes de textes a permis le développement de méthodes nouvelles, comme l’analyse sémantique explicite (ESA[GM07]), Word2Vec [MCC13], BERT [DCL18] ou GPT [BMR20].
Pour construire la représentation vectorielle classique de textes ([SMG86]), plusieurs étapes préalables sont en général nécessaires : l’extraction d’entités primaires, l’étiquetage grammatical, la lemmatisation (ou la racinisation, qui permet d’éviter l’étape d’étiquetage grammatical) et la suppression des « mots à ignorer » (stop words). Cette dernière étape vise à éliminer du texte les mots très fréquents mais peu discriminants car nécessairement présents dans tous les textes : prépositions, conjonctions, articles, verbes auxiliaires, etc. Des dictionnaires plus ou moins larges de tels mots sont disponibles pour chaque langue. Si l’identification de locutions ou d’entités nommées (et résolution référentielle) est nécessaire par rapport à l’objectif de l’analyse, alors ces étapes doivent être réalisées avant la suppression des stop words. Après ces opérations, un texte devient une succession de lemmes, éventuellement locutions et entités nommées, qui seront toutes appelées « termes » dans la suite.
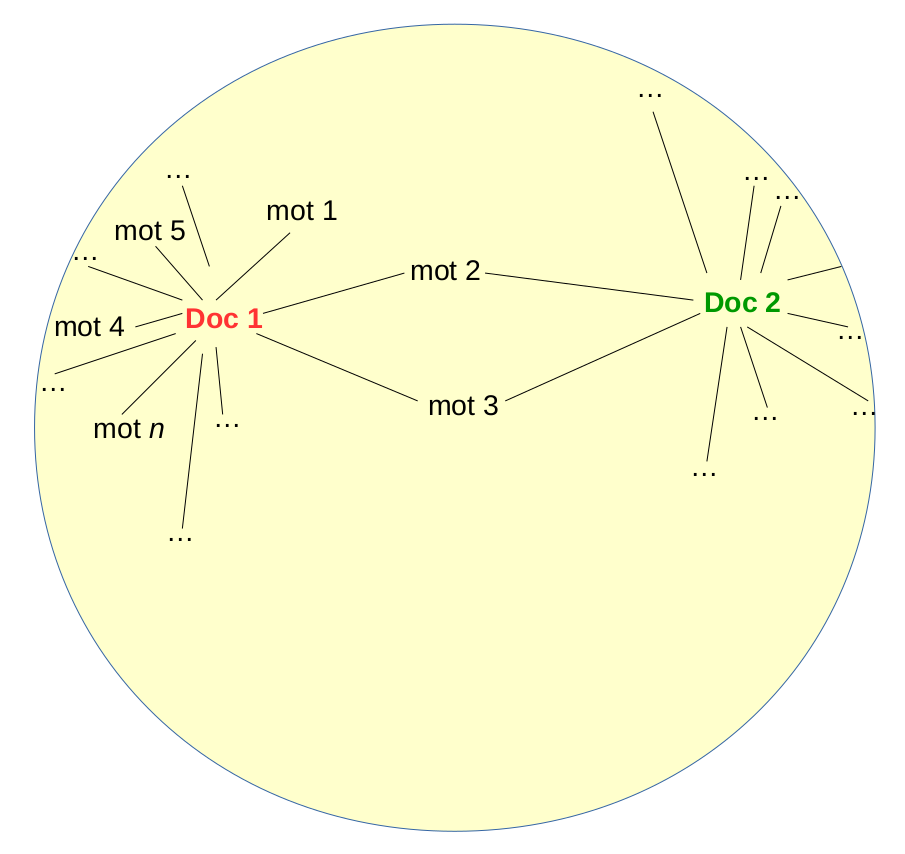
Considérons l’ensemble \(\mathcal{T}\) de documents (textes ou de listes de mots-clés ou de tags), chaque texte étant associé à une observation de la population à analyser. La méthode de base de représentation vectorielle de textes, proposée dans [SMG86], consiste à répertorier la totalité des termes présents dans \(\mathcal{T}\) (nous noterons leur nombre par \(n\)), après lemmatisation et suppression des stop words, et à affecter une dimension (un axe) de l’espace vectoriel à chaque terme. Chaque texte est alors représenté par un vecteur : la composante associée à un terme est 0 si le terme est absent du texte et différent de 0 (plusieurs techniques de pondération peuvent être employées ici) si le terme est présent dans le texte. Ce vecteur est en général de très grande dimension, car le nombre de termes différents qui apparaissent dans un grand ensemble de textes \(\mathcal{T}\) est très élevé. Un tel vecteur est aussi le plus souvent très creux, car chaque texte ne contient qu’une faible part des termes de \(\mathcal{T}\). La figure suivante illustre ce type de représentation vectorielle de texte (de dimension 10…4, par ex. 100004) :
Fig. 61 Exemple de représentation vectorielle de texte¶
Plus un texte est court, plus le vecteur associé sera en général creux et donc sa norme euclidienne faible. Pour utiliser la distance euclidienne il est donc nécessaire de normaliser les vecteurs associés aux différents textes de \(\mathcal{T}\). Une solution souvent préférée est d’employer plutôt la distance cosinus.
Cette représentation vectorielle de base a connu de nombreuses évolutions, parmi lesquelles nous pouvons mentionner l’utilisation de pondérations de type TF-IDF (term frequency x inverse document frequency), la sélection de mots (par ex. en utilisant le test du \(\chi^2\)), la réduction de dimension par « analyse sémantique latente » (LSA[DDL90]), etc.
Dans la comparaison des vecteurs qui représentent des textes, les différents termes n’ont pas tous la même importance. D’abord, un terme qui apparaît dans une majeure partie des documents textuels de \(\mathcal{T}\) contribue moins aux distinctions entre textes qu’un autre terme qui est présent dans un faible nombre de textes. Ensuite, un terme qui a de multiples occurrences dans un même texte est plus significatif pour ce texte qu’un autre terme qui n’y figure qu’une seule fois. Ces deux critères sont les plus fréquemment employés pour obtenir des pondérations des termes et peuvent être exprimés de différentes façons. Les pondérations des termes sont systématiquement employées pour la recherche d’informations, mais on les retrouve également dans la classification thématique de textes.
Le premier critère se traduit en général par la pondération de chaque terme par un coefficient inversement proportionnel au nombre de documents (de l’ensemble \(\mathcal{T}\)) dans lesquels il apparaît. En anglais on parle de inverse document frequency (IDF). L’expression fréquemment utilisée pour ce coefficient est \(idf_i = \log\left(\frac{m}{m_i}\right)\), \(m\) étant le nombre total de documents de \(\mathcal{T}\) et \(m_i\) le nombre de documents contenant le terme \(i\). Le logarithme permet ici d’éviter une sur-pondération des termes très rares. D’ailleurs, les termes dont le nombre d’occurrences dans la collection de documents est inférieur à un seuil sont en général exclus dès le départ (sans calcul de leur \(idf\)). De nombreuses variations existent pour cette composante IDF. Nous noterons que la pondération IDF dépend de l”ensemble des documents.
Le second critère mène à une pondération proportionnelle au nombre nombre d’occurrences du terme dans le document. En anglais on parle de term frequency (TF). L’expression employée en général est \(tf_{ij} = \frac{n_{ij}}{\|d_j\|}\), \(n_{ij}\) étant le nombre d’occurrences du terme \(i\) dans le document \(j\) et \(\|d_j\|\) la longueur du document \(d_j\). Nous remarquerons que la pondération TF dépend uniquement du document \(j\).
En tenant compte de ces deux critères, la pondération du terme \(i\) dans le document \(j\) est \(tf_{ij} \cdot idf_i\). Si le terme \(i\) est absent du document, alors la composante correspondante du vecteur qui représente le document \(j\) est 0. Si le terme \(i\) est présent, la composante qui lui correspond est \(tf_{ij} \cdot idf_i\).
Nous remarquerons que d’autres considérations peuvent intervenir dans le calcul de la pondération, par ex. surpondération des entités nommées par rapport aux lemmes simples, surpondération des occurrences dans des titres (éventuellement suivant le niveau du titre), etc.
Enfin, d’autres méthodes de pondération peuvent donner de meilleurs résultats que TF-IDF, voir par exemple BM25 dans [RZ09].
L’ensemble de documents textuels \(\mathcal{T}\) peut être représenté par une matrice documents-termes\(\mathbf{M}\) dans laquelle chacune des \(m\) lignes correspond à un document et chacune des \(n\) colonnes à un terme, avec des pondérations de type TF-IDF.
Dans cette représentation, aussi bien les lignes que les colonnes sont très creuses, un document contenant une faible part de l’ensemble total des termes et un terme étant en général présent dans peu de documents. Toute similarité entre documents est expliquée par la présence de nombreux termes communs entre les documents, toute similarité entre termes est expliquée par leur présence commune dans un grand nombre de documents. La « lisibilité » de ces similarités est limitée par les grands nombres de termes et respectivement de documents. Aussi, cette représentation présente également d’autres problèmes liés aux termes employés. Par exemple, deux synonymes (termes différents mais ayant une même signification, comme « voiture » et « automobile ») sont associés à deux dimensions (ou composantes) différentes des vecteurs qui représentent les documents ; si deux documents emploient chacun un de ces termes, la comparaison de leurs vecteurs ne mettra en évidence aucune similarité due à la signification commune des synonymes. Un autre exemple : un terme rare, qui correspond à une particularité stylistique de l’écriture et a peu de rapports avec la signification des documents, aura un poids IDF (et donc TF-IDF) élevé alors que pour la comparaison des documents (ou leur classification thématique) il peut être considéré comme du « bruit ». L’utilisation dans quelques documents d’un terme avec un sens alors que dans de nombreux autres documents le même terme est employé avec un autre sens (cas d’homonymie) produit également du « bruit ».
L’analyse (ou indexation) sémantique latente (Latent Semantic Analysis, LSA [DDL90]) a été proposée comme une réponse à ces insuffisances de la représentation vectorielle classique. La LSA cherche à identifier des « concepts latents » (un tel concept correspond à des corrélations entre les occurrences de plusieurs termes, non à un concept bien identifié dans une ontologie) pour représenter les documents d’une collection. Par exemple, des synonymes comme « voiture » et « automobile » seront corrélés avec un même ensemble d’autres termes liés à l’univers automobile, c’est ce concept qui sera identifié par la LSA et caractérisera les documents, mettant ainsi en évidence un lien que des termes différents comme « voiture » et « automobile » ne permettaient pas de voir directement.
Un autre exemple, concernant plutôt l’homonymie : dans l’ensemble \(\mathcal{T}\) on peut avoir de multiples documents qui contiennent les termes « juge », « prévenu », « procès », « avocat », « audience », « peine », et d’autres qui contiennent « four », « citron », « avocat », « assiette », « couteau », « mayonnaise ». Dans le premier cas, les corrélations indiqueront le concept (au sens de la LSA) « justice » alors que dans le second le concept « cuisine ». Dans la plupart des cas, le contenu d’un document sera caractérisé par la présence de certains concepts (issus d’un ensemble relativement réduit de concepts). Un terme sera également caractérisé par sa contribution à un nombre réduit de tels concepts. Aussi, le « bruit » dû à l’emploi d’un même terme « avocat » dans les deux contextes avec deux sens différents pourra être supprimé (ou réduit) car l’impact des corrélations multiples signalées sera dominant. Les concepts correspondant à des corrélations entre de multiples termes ne sont pas nommés, d’ailleurs ils ne sont pas toujours facilement interprétables par un humain (contrairement aux deux cas mentionnés ci-dessus).
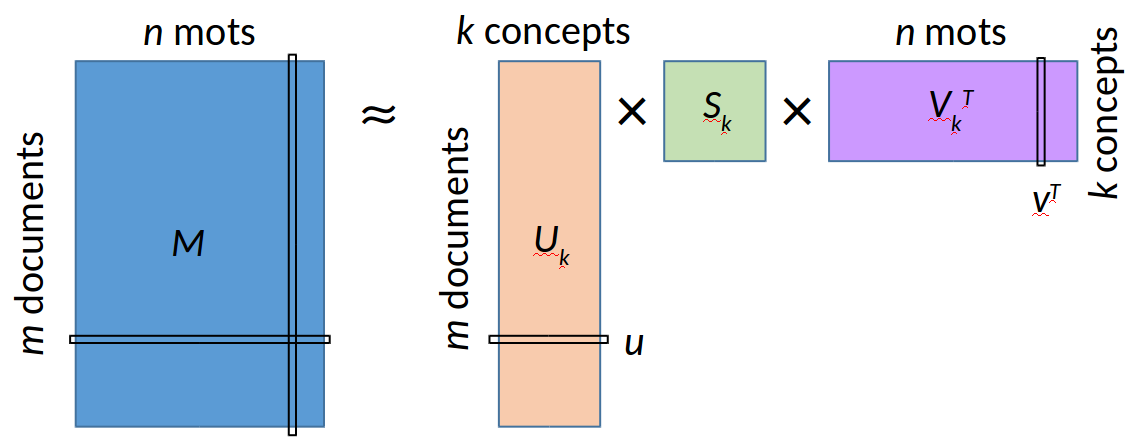
L’analyse sémantique latente consiste à appliquer une décomposition en valeurs singulières (Singular Value Decomposition, SVD) à la matrice documents-termes, suivie par une réduction de rang, pour obtenir une approximation de faible rang (avec un faible nombre de « concepts ») de cette matrice. Plus précisément, la matrice documents-termes sera décomposée de la façon suivante :
avec \(\mathbf{U}\) et \(\mathbf{V}\) des matrices orthogonales (une matrice est orthogonale si par le produit avec sa transposée on obtient la matrice identité) et \(\mathbf{S}\) une matrice diagonale.
La décomposition en valeurs singulières est liée à l’analyse en composantes principales : en calculant \(\mathbf{M} \mathbf{M}^T\) et \(\mathbf{M}^T \mathbf{M}\) on constate que \(\mathbf{S}\) (\(n \times n\)) contient sur sa diagonale principale les racines carrées des valeurs propres de \(\mathbf{M} \mathbf{M}^T\) (ou de \(\mathbf{M}^T \mathbf{M}\), les valeurs propres non nulles des deux matrices étant les mêmes), \(\mathbf{U}\) (\(m \times n\)) a pour colonnes les vecteurs propres de \(\mathbf{M} \mathbf{M}^T\) et \(\mathbf{V}\) (\(n \times n\)) a pour colonnes les vecteurs propres de \(\mathbf{M}^T \mathbf{M}\). Nous avons supposé ici que \(m \geq n\) et que le rang de \(\mathbf{M}\) était \(n\).
Si on conserve uniquement les \(k\) plus grandes valeurs propres (\(k < m, k < n\)) et les vecteurs propres associés, alors on obtient la meilleure approximation de rang \(k\) de \(\mathbf{M}\) (de même dimension \(m \times n\) que \(\mathbf{M}\)) :
Les valeurs sur la diagonale principale de \(\mathbf{S}_k\) indiquent l”« importance » de chacun des \(k\) « concepts latents » (ou facteurs) identifiés. Pour chacun des \(m\) documents, la ligne correspondante de \(\mathbf{U}_k\) permet de voir quels concepts y sont présents et avec quels poids. Pour chacun des \(k\) concepts, la colonne associée de \(\mathbf{V}\) (la ligne associée de \(\mathbf{V}^T\)) indique quels termes forment le concept (et avec quelles pondérations).
Fig. 63 Décomposition matricielle pour l’analyse sémantique latente¶
En général, les développements concernant LSA sont présentés à partir de la matrice termes-documents, qui est la transposée de la matrice documents-termes traitée ici. Lorsque LSA a été proposée, le nombre de documents était le plus souvent inférieur au nombre de termes. Pour des données massives, le nombre de documents est en général bien supérieur au nombre de termes et l’utilisation dans Spark d’une RowMatrix pour contenir ces données impose d’employer la matrice documents-termes.
Cette idée de la recherche d’un nombre réduit de concepts latents qui s’expriment à travers des ensembles de termes et sont présents (à des degrés divers) dans des documents textuels a été développée ultérieurement dans l’analyse sémantique latente probabiliste (Probabilistic Latent Semantic Analysis, PLSA [Hof99]) et ensuite dans l’allocation de Dirichlet latente (Latent Dirichlet Allocation, LDA [BNJ03]) ; cette dernière est implémentée dans Spark.
Les relations entre termes et entre documents issues (directement, ou après LSA, PLSA, LDA, etc.) de la matrice \(\mathbf{M}\) représentant un ensemble de documents \(\mathcal{T}\) sont très dépendantes des particularités de \(\mathcal{T}\). Cela engendre des biais de modélisation, présents même pour des ensembles \(\mathcal{T}\) de grande cardinalité (données massives). Pour s’affranchir de ces biais, l’analyse sémantique explicite (Explicit Semantic Analysis, ESA [GM07]) considère un corpus très grand, pouvant faire référence (Wikipedia) pour construire une matrice documents-termes. Cela permet d’obtenir des représentations générales et très riches des termes, indépendantes d’ensembles spécifiques (et souvent beaucoup plus petits) de documents applicatifs. Fin 2017, Wikipedia comportait près de 2 millions d’articles en français.
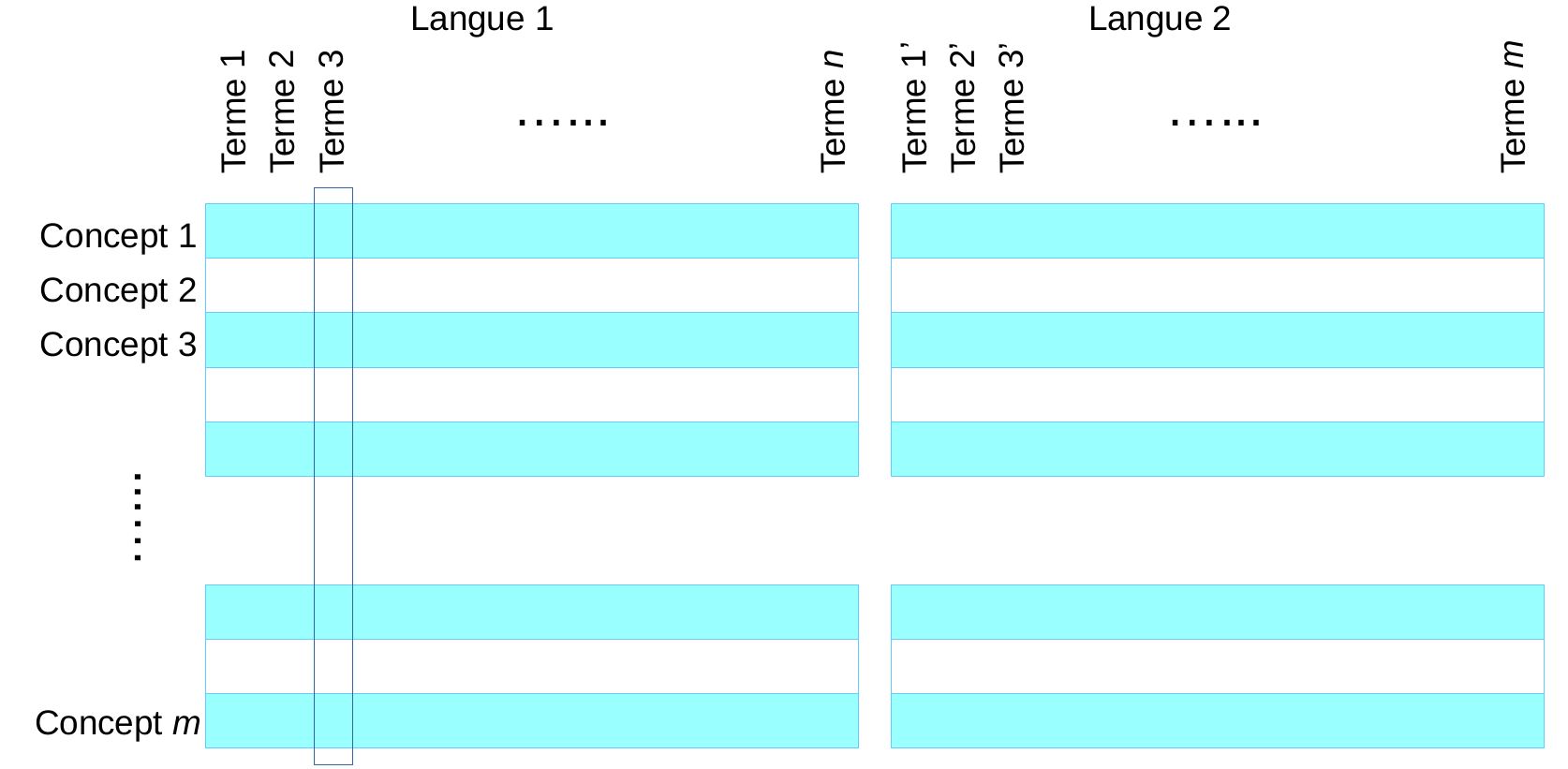
Avec ESA, chaque terme est représenté par un vecteur dont la dimension est donnée par le nombre de pages (ou de « concepts ») Wikipedia. Chaque composante du vecteur correspond à une page Wikipedia. Si le terme y est absent, la valeur est 0. Si le terme y est présent, la valeur est égale à sa pondération TF-IDF. Tout autre document est représenté par le centre de gravité de l’ensemble des termes qu’il contient ; le calcul du centre de gravité tient compte des pondérations TF-IDF par rapport au document.
Fig. 64 Un document est représenté par le centre de gravité des vecteurs représentant ses lemmes¶
Contrairement aux résultats de LSA (ou de PLSA, ou de LDA), où les « concepts latents » sont en nombre relativement faible et ne sont pas toujours interprétables par un humain, avec ESA les dimensions des vecteurs sont interprétables car chaque dimension correspond à un concept précis (une page) de Wikipedia.
Nous remarquerons qu’un corpus multi-langues comme Wikipedia, ou de nombreux concepts (surtout les plus importants) ont des pages dans plusieurs langues, permet de définir des représentations de documents indépendantes de la langue car exprimées comme des vecteurs dans l’espace de ces concepts ; on parle de Cross-language ESA.
Il est important de noter que Wikipedia comporte également des biais (certains domaines sont plus présents que d’autres, certains mots sont préférés à d’autres, etc.) et évolue constamment (le nombre de concepts augmente, mais les pages existantes changent également). Aussi, le nombre de concepts décrits et le niveau de détail varient beaucoup d’une langue à une autre. Cela a un impact sur les représentations issues de l’analyse sémantique explicite.
Les représentations vectorielles précédentes sont basées sur la description d’un texte par l’ensemble des termes (le plus souvent mots individuels) qu’il contient. Dans un tel « sac de mots » (bag of words) toute information liée au contexte des mots est ignorée. Or, le contexte d’un mot dans une phrase caractérise assez bien le mot à la fois sur l’aspect syntaxique et sur l’aspect sémantique. Il est alors utile d’exploiter le contexte pour construire des représentations vectorielles plus « raffinées ».
C’est ce que propose la représentation Word2Vec (voir [MCC13], [MSC13]), sur la base de ressources textuelles très volumineuses. Avec le modèle Skip-gram [MCC13], l’objectif est de trouver des représentations permettant de prédire le mieux possible le contexte des mots. Plus précisément, étant donnée une séquence de mots \(w_1, w_2, \ldots, w_T\), on cherche à maximiser
\(V\) étant le nombre de mots du vocabulaire, \(u_{w_i}\) la représentation « de sortie » de \(w_i\) et \(v_{w_j}\) la représentation « d’entrée » de \(w_j\). Une reformulation du problème permet de remplacer softmax et réduire ainsi le coût des calculs (voir [MSC13]).
Avec cette représentation, les mots se regroupent par similarité de contexte qui reflète à la fois une similarité syntaxique et une similarité sémantique. Aussi, on constate une forme d’additivité, par exemple la représentation la plus proche du résultat du calcul \(v_{Madrid} - v_{Spain} + v_{France}\) est \(v_{Paris}\).
Contrairement aux représentations de base pondérées (TF-IDF) ou ESA, les représentations Word2Vec sont d’assez faible dimension (par ex. 300) et denses. Il est possible de développer de telles représentations non seulement pour des mots individuels mais également pour des locutions, des entités nommées et plus généralement pour des phrases courtes.
Word2Vec et les extensions sont utilisées avec de bons résultats pour résoudre des problèmes très divers : désambiguïsation, traduction de textes, classification de textes, illustration de textes, etc. Sur https://code.google.com/archive/p/word2vec/ sont mises en libre accès des représentations Word2Vec pour de grands nombres de mots et d’entités nommées.
De nombreuses nouvelles méthodes de représentation ont été développées ces dernières années. Les plus récentes exploitent l’apprentissage de réseaux de neurones profonds à partir de très grandes bases de textes. On peut distinguer les méthodes qui développent une représentation unique pour chaque mot (en faisant une « synthèse » de ses différents contextes possibles, comme Word2vec, GloVe ou FastText), de celles qui produisent une représentation de chaque mot dans son contexte particulier dans la phrase (comme ELMo, BERT ou GPT-x).
Il faut également noter que la plupart des méthodes récentes traitent plutôt des séquences fréquentes de caractères, ce qui leur permet de représenter aussi des mots « hors vocabulaire » (pour lesquels aucune représentation n’a été préalablement apprise) en combinant des représentations de parties de ces mots. Ces méthodes font ainsi l’hypothèse que différentes parties d’un mot (notamment celles correspondant à des séquences plus fréquentes dans la langue) contribuent à la signification du mot. Les résultats obtenus appuyent cette hypothèse.
Méthodes qui construisent, comme Word2Vec, une représentation unique pour chaque mot (plongement lexical ou word embedding), quel que soit son contexte et son sens dans une phrase (liste non exhaustive) :
GloVe[PSM14] exploite directement la matrice (très creuse) de cooccurrences des mots dans des fenêtres de contexte. L’objectif est de rapprocher le produit scalaire des vecteurs représentant des mots (embeddings) du logarithme de leur probabilité de cooccurrence. Comme Word2Vec, GloVepermet d’obtenir des word embeddings seulement pour les mots rencontrés dans les textes du corpus traité (c’est à dire les mots du vocabulaire).
FastText[BGJ17] vise justement à résoudre le problème des mots hors vocabulaire. La méthode est similaire à Word2vec, sauf que l’unité de base est le n-gramme de caractères plutôt que le mot. En conséquence, même si un mot est inconnu (aucun code n’a donc été préalablement appris pour ce mot), il est quand même constitué d’une séquence de caractères ; avec FastText ces sous-séquences possèdent des représentations vectorielles (par ex. pour le mot vecteur les trigrammes sont {vec,ect,cte,teu,eur}), il est donc possible d’obtenir une représentation pour le mot en combinant les représentations de ces sous-séquences.
Méthodes qui construisent une représentation différente pour chaque mot dans chaque contexte (modèles de langage; liste non exhaustive) :
ELMo (Embedding from Language Models) [PNI18] prend en entrée des embeddings de caractères successifs, suit une couche convolutionnelle (qui traitera donc des n-grammes de caractères) et 2 couches de highway network, qui produisent des représentations intermédiaires traitées par plusieurs niveaux de LSTM (réseaux de neurones récurrents) vers la gauche et vers la droite, les représentations étant concaténées à chaque niveau. Les représentations de mots résultantes sont obtenues comme des combinaisons linéaires des entrées et des représentations issues des différents niveaux de LSTM. L’unité de base étant le caractère, ELMo permet donc de représenter des mots hors vocabulaire. Il est important de noter que la représentation ELMo d’un mot dépend de son contexte dans la phrase traitée ; dans une autre phrase le même mot a une représentation différente. Cela permet, entre autres, de différencier les sens des synonymes.
BERT (Bidirectional Encoder Representations from Transformers) [DCL18] emploie des réseaux de neurones de type transformer[VSP17]. L’apprentissage est réalisé d’abord sur la prédiction de mots masqués et sur la prédiction de suite (une phrase suit ou non la phrase courante). L’apprentissage peut ensuite se poursuivre par un apprentissage supervisé sur différentes tâches cibles comme le classement de phrases, la réponse aux questions, l’étiquetage de phrase, la coréférence, etc. Les mots hors vocabulaire sont traités et les représentations sont contextualisées (comme pour ELMo). Des adaptations ont été proposées pour la langue française, comme CamemBERT ou FlauBERT.
GPT[RNS18], GPT-2[RWC19], GPT-3[BMR20], etc. emploient également des transformers. Les mots hors vocabulaire sont traités et les représentations sont contextualisées. L’apprentissage est réalisé sur la prédiction du mot suivant et sur plusieurs tâches supervisées. GPT-3 est appris sur une version filtrée (de l’ordre de 570 GB) de la très grande base CommonCrawl, ce qui permet d’obtenir des modèles avec jusqu’à \(175\cdot10^9\) paramètres. GPT-3 a un grand potentiel de mauvais usage (voir [BMR20]), ce qui fait que GPT-3 175 n’est pas open source mais accessible seulement à travers une API, sur acceptation.
Certaines applications doivent employer des représentations vectorielles de textes. Les méthodes existantes peuvent être classée en général en
Méthodes exploitant les représentations vectorielles des mots individuels (indépendantes ou dépendantes du contexte) :
La représentation vectorielle d’un texte est le centre de gravité des vecteurs représentant ses mots, en général en supprimant les stop words et parfois en pondérant les mots (par ex. pondérations TF-IDF)
Sent2Vec[PGJ17] suit l’approche Word2Vec et propose une extension du contexte d’un mot à une phrase entière (ou à un paragraphe court). Le vecteur qui représente une phrase est ensuite obtenu comme le centre de gravité des vecteurs représentant les mots individuels et les n-grammes de la phrase.
InferSent[CKS17] emploie des réseaux de neurones de type LSTM bidirectionnels. L’apprentissage est réalisé sur la base Stanford NLI, sur un problème de discrimination entre entailment (suite logique), contradiction et neutral (non liée) pour la phrase suivante à partir de la phrase courante.
Universal Sentence Encoder (USE) [CYK18] avec deux variantes : (i) Deep Averaging Network (réseau de neurones à 4 couches) qui prend en entrée les embeddings des mots et des bi-grammes de la phrase, ou (ii) Transformer encoder (6 niveaux de réseaux de neurones transformers) qui prend en entrée les embeddings des mots. La variante (ii) permet d’obtenir les meilleurs résultats mais présente un coût plus élevé d’encodage (la complexité est quadratique dans la longueur de la phrase).
Sentence-BERT (SBERT, voir aussi https://www.sbert.net/) [RG19] utilise deux réseaux BERT siamois (qui partagent les mêmes poinds des connexions) pré-entraînés et fait un apprentissage avec tois tâches supervisées (suivant les bases d’apprentissage employées, donc suivant l’information de supervision disponible) : discrimination pour la phrase suivante (entre entailment / contradiction / neutral), régression de la similarité cosinus entre phrases, similarité triplet (pour chaque phrase cible A, une phrase B est plus similaire à A que la phrase C). L’apprentissage des réseaux BERT pré-entraînés étant un fine-tuning, le coût d’apprentissage est limité (par rapport à l’apprentissage complet de réseaux BERT) et cela permet aussi d’ajouter des tâches supplémentaires mieux adaptés au problème visé.
Méthodes issues du modèle vectoriel de texte : rappelons que dans cette approche, chaque lemme présent dans la base définit une variable (1 colonne de la matrice documents-mots) et qu’il n’y a aucun lien entre deux variables (colonnes) même si les lemmes sont liés (par ex. synonymes). Bien que tous les vecteurs soient creux, les textes longs sont mieux représentés que les textes courts qui n’ont pas assez de lemmes.
Le modèle vectoriel avec pondérations TF-IDF donne (grâce aux pondérations) des représentations plus fidèles que le modèle vectoriel de base mais ignore toujours les liens entre mots différents. Le modèle vectoriel de base est une représentation simpliste qui n’est plus utilisée telle quelle.
L’analyse sémantique latente permet d’obtenir une réduction du « bruit » en considérant un nombre limité de thèmes (ou topics) et prend en compte des similarités entre mots (par ex. synonymes) à travers leurs corrélations avec d’autres mots, qui contribuent à l’identification des thèmes.
L’analyse sémantique explicite permet d’obtenir les représentations sur un grand corpus générique de textes, en réduisant ainsi les biais de modélisation, et offre la possibilité de comparer des documents multi-langues (pour les langues qui sont bien représentées dans le corpus générique qui a servi à construire la représentation). On peut remarquer que l’analyse sémantique explicite est aussi basée sur des embeddings de mots et fait donc également partie de la première famille de méthodes (voir ci-dessus).
Nous pouvons alors considérer que, pour un texte court ou un petit ensemble de mots clés (< 10-15 termes)
le centre de gravité des vecteurs représentant les mots constitue une solution facile, dans ce cas il faut préférer les représentations non-contextuelles comme GloVe (vocabulaire prédéfini, donc fixe) ou FastText (si des termes hors vocabulaire sont attendus). Pour calculer le centre de gravité, on supprime en général les stop words car ils font perdre de la discrimination et on peut pondérer les vecteurs représentant les mots restants (par ex. avec TF-IDF).
USE ou SBERT sont des solutions plus complexes à mettre en œuvre et un peu plus coûteuses mais plus performantes, si elles sont disponibles pour la langue cible.
les représentation issues du modèle vectoriel de texte sont à éviter car trop pauvres, à l’exception de l’analyse sémantique explicite, surtout pour des documents multi-langue.
Pour des textes plus longs
le centre de gravité des vecteurs représentant les mots devient peu spécifique car le nombre de mots est élevé, donc peu discriminant. Cette approche doit donc être évitée.
USE et SBERT sont actuellement les méthodes de choix pour des textes de longueur moyenne (de l’ordre d’un paragraphe).
les représentation issues du modèle vectoriel de texte (surtout LSA et ESA), plus faciles à mettre en œuvre, peuvent donner des résultats satisfaisants pour des textes plus longs.
De nombreuses ressources libres ou partiellement libres sont disponibles pour différentes étapes spécifiques à la fouille de données textuelles.
Une suite récente, bien intégrée à Spark ML est SparkNLP. Cette suite inclut la segmentation (tokenizer), l’étiquetage (tagger), la lemmatisation, la correction orthographique, l’extraction d’entités nommées, l’analyse des sentiments, ainsi que de nombreux outils de construction de représentations vectorielles de mots et de textes. Cette suite est employée dans nos séances de travaux pratiques : TP analyse de textes, TP discrimination de textes.
Une suite populaire, écrite en Python (et Cython pour une meilleure efficacité) et d’utilisation réputée simple, est spaCy (voir aussi ce tutoriel). Cette suite propose la segmentation (tokenizer), l’étiquetage (tagger), la lemmatisation, l’extraction d’entités nommées, le entity linking (identification des références à des entités nommées), ainsi que différents outils de construction de représentations.
Une autre suite, écrite en java, est Stanford CoreNLP. Les outils proposés concernent principalement l’anglais, l’espagnol et le chinois. Sont ainsi disponibles la segmentation (tokenizer), l’étiquetage (tagger), la lemmatisation, l’analyse syntaxique, l’extraction d’entités nommées, le traitement des coréférences, etc.
Opérations liées à la fouille de textes dans Spark¶
Spark propose plusieurs outils intégrés pour différentes opérations : construction et manipulation de représentations vectorielles avec pondérations TF-IDF (HashingTF,IDF), sélection de mots par test du \(\chi^2\) (ChiSqSelector), l’allocation de Dirichlet latente (LDA,DistributedLDAModel), les représentations vectorielles Word2Vec (Word2Vec,Word2VecModel).
Bojanowski, P., E. Grave, A. Joulin, and T. Mikolov. Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5 :135–146, 2017.
Brown, T. B., B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners, 2020.
Cer, D., Y. Yang, S.-y. Kong, N. Hua, N. Limtiaco, R. St. John, N. Constant, M. Guajardo-Cespedes, S. Yuan, C. Tar, B. Strope, and R. Kurzweil. Universal sentence encoder for English. In Proc. 2018 Conf. Empirical Methods in Natural Language Processing: System Demonstrations, pp 169–174, Brussels, Belgium, Nov. 2018. Association for Computational Linguistics.
Conneau, A., D. Kiela, H. Schwenk, L. Barrault, and A. Bordes. Supervised learning of universal sentence representations from natural language inference data. CoRR, abs/1705.02364, 2017.
Gabrilovich, E. and S. Markovitch. Computing semantic relatedness using wikipedia-based explicit semantic analysis. In Proceedings of the 20th International Joint Conference on Artifical Intelligence, IJCAI’07, pages 1606–1611, San Francisco, CA, USA, 2007. Morgan Kaufmann Publishers Inc.
Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’99, pages 50–57, New York, NY, USA, 1999. ACM.
[KLS15]
Klein, B., G. Lev, G. Sadeh, and L. Wolf. Associating neural word embeddings with deep image representations using fisher vectors. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, pages 4437–4446, 2015.
Mikolov, T., I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, eds, Advances in Neural Information Processing Systems 26, pages 3111–3119. Curran Associates, Inc., 2013.
Peters, M. E., M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer. Deep contextualized word representations. In Proc. of NAACL, 2018.
Pennington, J., R. Socher, and C. D. Manning. Glove: Global vectors for word representation. In Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, 2014.