Réduction du nombre de variables explicatives : approches¶
La réduction du nombre de variables explicatives (ou d’entrée) consiste à réduire la dimension des \(n\) observations disponibles de \(m\) (\(\mathbf{x} \in \mathbb{R}^m\)) à \(k\) (\(\mathbf{x}_r \in \mathbb{R}^k\)), avec en général \(k \ll m\). Cette réduction peut répondre à un ou plusieurs objectifs :
Réduire le volume de données à traiter, tout en conservant au mieux l’information « utile ». Pour définir un critère à optimiser il est d’abord nécessaire de définir ce qu’est « information utile ».
Améliorer le rapport signal / bruit en supprimant des variables non pertinentes, ce qui implique de définir d’abord ce qu’est une variable non pertinente.
Réduire la complexité d’un modèle décisionnel afin d’améliorer sa capacité de généralisation, sachant que le nombre de variables explicatives est une composante de cette complexité.
Simplifier la mise en production et la maintenabilité de la solution en réduisant le nombre de variables à recueillir pour les nouvelles observations.
Améliorer la « lisibilité » des données, en mettant en évidence des relations entre variables ou groupes de variables, éventuellement en permettant une visualisation utile (ce qui implique de définir ce qu’il faut mettre en évidence).
Répondre à la « malédiction de la dimension » (curse of dimensionality).
A objectifs différents correspondent, naturellement, des critères différents et donc des méthodes différentes.
Les principales approches de la réduction du nombre de variables sont la réduction de dimension (terme trop général) et la sélection de variables. Par réduction de dimension on entend ici la construction de nouvelles variables, en nombre plus réduit mais obtenues comme des combinaisons (par exemple combinaisons linéaires) de variables initiales. Cette approche permet une plus grande flexibilité que la sélection de variables, en revanche les nouvelles variables sont rarement interprétables (chacune étant une combinaison de plusieurs variables initiales). Par sélection de variables (feature selection) on entend la sélection d’un sous-ensemble de \(k\) variables parmi les \(m\) variables initiales. Les variables sélectionnées gardent ainsi leur signification initiale. En revanche, cette solution est potentiellement sous-optimale car c’est un cas particulier de la construction de nouvelles variables.
Pour la réduction de dimension, rappelons que la dépendance entre les nouvelles variables et les variables initiales peut être
Linéaire, consistant à trouver un sous-espace linéaire de dimension \(k\) qui est proche des observations dans l’espace initial \(\mathbb{R}^m\) et à projeter les observations sur ce sous-espace. De telles méthodes sont présentées dans le Chapitre 2 (méthodes factorielles : ACP, AFD, ACM). L’illustration suivante montre un sous-espace linéaire de dimension 2 (un plan) dans l’espace 3D :
Fig. 146 Sous-espace linéaire 2D dans l’espace 3D¶
Non linéaire, consistant à trouver un sous-espace non linéaire de dimension faible qui est proche des observations et à projeter ces observations sur ce sous-espace. De telles méthodes sont présentées dans le Chapitre 5 (LLE, t-SNE, UMAP). L’illustration suivante montre un sous-espace non linéaire de dimension 2 (manifold) dans l’espace 3D :
Fig. 147 Sous-espace non linéaire 2D dans l’espace 3D¶
Les méthodes de sélection de variables suivent trois approches principales (voir aussi [MBN02], [TAL14]) :
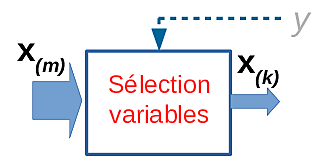
Filtrage : la sélection est réalisée suivant des critères définis sans faire appel à un modèle prédictif (ou décisionnel) ultérieur. Des critères de sélection typiques pour les méthodes de filtrage sont la minimisation de la redondance entre variables d’entrée, la maximisation de l’information mutuelle entre une variable d’entrée et la variable à prédire, ou une combinaison entre ces deux critères. L’illustration suivante montre de façon schématique une méthode de filtrage ; une éventuelle variable expliquée (\(Y\), à prédire par un modèle décisionnel ultérieur) peut intervenir dans le critère de sélection.
Fig. 148 Représentation d’une méthode de sélection suivant l’approche de filtrage.¶
Les méthodes de filtrage présentent un coût modéré car la sélection est faite en amont de la construction (l’apprentissage) de modèles prédictifs. En revanche, la coopération entre la méthode de sélection et le modèle prédictif ultérieur est sous-optimale car ce modèle n’intervient pas dans le processus de sélection.
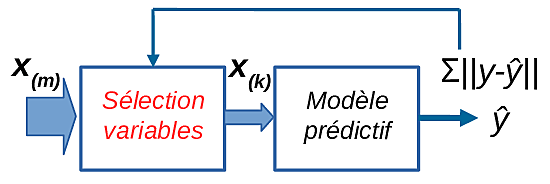
Wrapper (emballage) : la sélection est réalisée par une coopération directe avec le modèle prédictif qui emploie les variables sélectionnées. Le critère de sélection typique est la maximisation des performances du modèle prédictif ultérieur sur un ensemble d’observations de validation. Le modèle prédictif et la sélection du groupe de variables sont « emballés » ensemble, d’où le nom de cette approche. L’illustration suivante montre de façon schématique une méthode de filtrage ; le critère de sélection est la réduction de l’erreur du modèle décisionnel (\(\sum_n |y_i-\hat{y}_i|\)).
Fig. 149 Représentation d’une méthode de sélection suivant l’approche wrapper.¶
Les méthodes wrapper présentent un coût élevé car pour évaluer chaque groupe de variables candidat il faut construire (apprendre) et évaluer un modèle prédictif. En revanche, la coopération entre la méthode de sélection et le modèle prédictif ultérieur peut être considérée optimale.
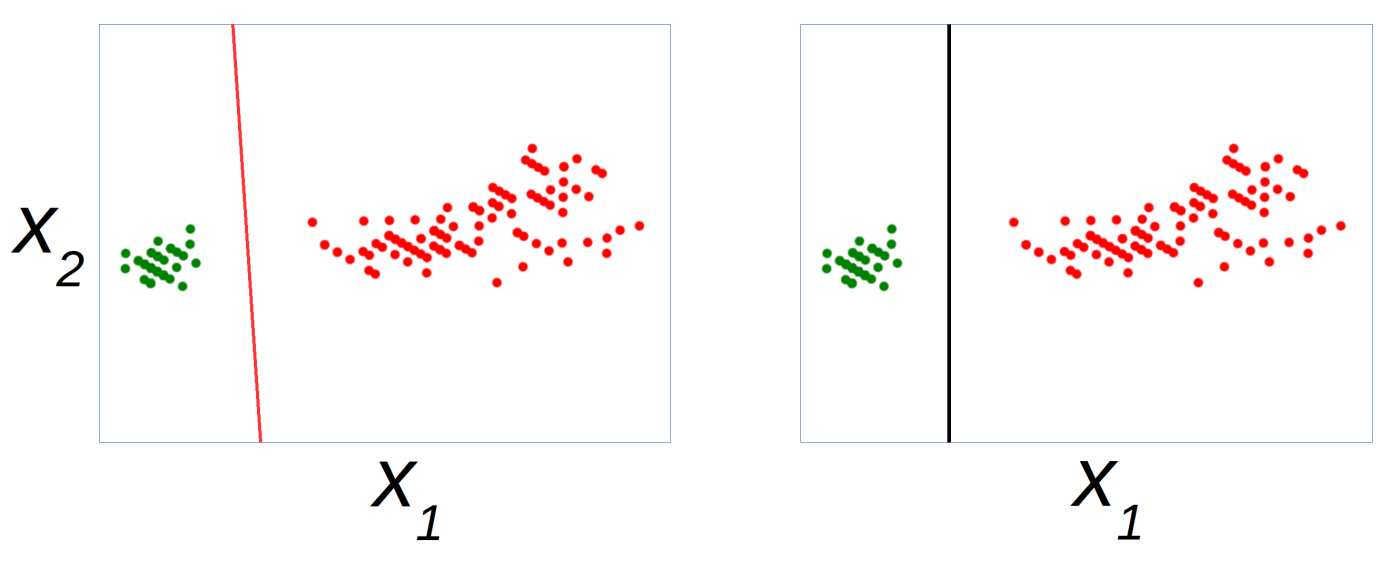
Intégration (embedding) : l’opération de sélection de variables est intégrée à la méthode de construction de modèle prédictif. Un exemple simple est la construction d’arbres de décision. Un autre exemple est l’introduction d’une régularisation \(L_1\) dans la fonction de coût du modèle prédictif. L’illustration suivante montre l’effet de la régularisation \(L_1\) dans un problème de discrimination entre deux classes avec deux variables explicatives ; une régularisation \(L_1\) suffisante permet de sélectionner une seule des deux variables.
Fig. 150 Effet de la régularisation \(L_1\) dans un problème de discrimination entre deux classes avec deux variables explicative : à gauche, sans régularisation, la frontière est oblique (dépend à la fois de \(X_1\) et de \(X_2\)) ; à droite, avec une régularisation \(L_1\) suffisante, la frontière est verticale (ne dépend plus de \(X_2\), seule la variable \(X_1\) est employée).¶
Les méthodes intégrées ne présentent pas de surcoût par rapport à la construction du modèle prédictif mais ne peuvent pas être utilisées avec tout type de méthode de modélisation prédictive.
Sélection de variables : méthodes d’exploration de l’espace de recherche¶
Le choix de \(k\) variables parmi \(m\) implique d’explorer un espace de recherche de \(O(C_m^k) \left(= \frac{m!}{k! (m-k)!}\right)\), qui est donc très large. Pour cette raison, une exploration exhaustive de cet espace n’est généralement pas envisageable et des explorations partielles (donc sous-optimales) sont indispensables.
Une situation favorable est celle où le critère de « pertinence » des variables est exprimable par variable initiale individuelle (donc indépendamment des autres). Par exemple, pour l’approche de filtrage, l’information mutuelle entre une variable d’entrée et la variable à prédire. Il est alors possible de calculer ce critère pour chaque variable d’entrée et ensuite sélectionner les \(k\) variables de pertinence optimale, ce qui mène à une complexité de seulement \(O(m)\).
Si le critère de « pertinence » des variables n’est exprimable que par groupe de variables initiales, par exemple la redondance pour l’approche de filtrage ou la performance globale pour l’approche wrapper, la réduction de complexité ne peut pas être aussi forte que dans le cas précédent. Une bonne réduction de la complexité peut néanmoins être obtenue grâce à des méthodes incrémentales ou décrémentales.
Méthodes incrémentales (par cooptation de variables) : on démarre avec une seule variable (par exemple choisie avec la méthode précédente où le critère de pertinence est exprimé par variable individuelle) ; à chaque itération on ajoute une variable parmi les variables explicatives initiales, plus précisément celle qui forme le meilleur ensemble avec les variables déjà sélectionnées aux itérations précédentes. La complexité résultante est de \(O(m^2)\) (la complexité exacte augmente avec le nombre de variables à ajouter).
Méthodes décrémentales (par élimination de variables) : on démarre avec la totalité des variables initiales ; à chaque itération on teste toutes les combinaisons avec une variable en moins par rapport à l’itération précédente et on choisit celle qui est optimale (on élimine donc une variable). La complexité résultante est de \(O(m^2)\) (la complexité exacte augmente avec le nombre de variables à éliminer).
L’exploration de l’espace de recherche est explicite dans l’approche de filtrage et l’approche wrapper, en revanche elle est absente (ou implicite) dans l’approche intégration.
Après avoir passé en revue les principales approches de sélection de variables et examiné les méthodes employées pour réduire l’espace de recherche, nous pouvons nous concentrer sur les critères de sélection de variables explicatives. En allant de la plus simple à la plus complexe, nous trouvons les familles suivantes de critères :
Propriétés intrinsèques d’une variable explicative (ou d’entrée). La principale propriété intrinsèque d’une variable d’intérêt ici est la variance de la variable : si la variance est très faible, la variable explique une faible part de la variance des observations et est éliminée. En apparence trop simple, ce critère peut néanmoins donner des résultats positifs dans certains cas, comme nous le verrons plus loin, ainsi que dans la séance de travaux pratiques.
Caractérisation de chaque variable explicative, prise individuellement, par rapport à la variable expliquée (ou de sortie). Le critère utilisé est de type « qualité de prédiction », caractérisée de différentes façons suivant que nous suivons une approche de filtrage ou oun approche wrapper. Sont sélectionnées individuellement les variables d’entrée qui « expliquent le mieux » la variable de sortie.
Caractérisation d’un groupe de variables d’entrée par rapport à la variable de sortie. Pour obtenir de meilleurs résultats que la caractérisation des variables explicatives individuelles par rapport à la variable de sortie, il faut se résoudre à passer aux groupes de variables d’entrée (ce qui a pour conséquence aussi une augmentation de la complexité algorithmique de la sélection). Est sélectionné le groupe qui « explique le mieux » la variable de sortie.
Caractérisation d’un groupe de variables d’entrée entre elles et par rapport à la variable de sortie. Ces critères combinent la qualité de prédiction de la variable expliquée et la réduction de la redondance entre variables explicatives sélectionnées ; est ainsi choisi le groupe qui présente le meilleur compromis entre ces deux aspects.
La variance est une propriété intrinsèque d’une variable, qui ne s’intéresse pas à la relation à une autre variable (d’entrée ou de sortie). Avec \(n\) observations de la variable \(X\), la moyenne et la variance de l’échantillon sont respectivement :
L’idée de ce critère de variance est de considérer que les variables de variance trop faible expliquent trop peu de la variance des observations et peuvent être éliminées. Nous avons déjà rencontré ce type de critère dans la réduction de dimension, plus précisément pour l’analyse en composantes principales (ACP) où les axes associés aux valeurs propres les plus faibles de la matrice des covariances empiriques sont éliminées ; pour l’ACP ces axes correspondent à des variables calculées à partir des variables initiales.
Il est important de noter que la variance dépend de l’unité de mesure : par exemple, à partir d’un même échantillon de longueurs on obtient une variance bien plus grande si les valeurs sont exprimées en mm plutôt qu’en mètres. Pour éviter l’arbitraire dans la comparaison des « dispersions » de variables différentes mieux vaut utiliser le coefficient de variation qui est le rapport entre l’écart-type et la moyenne (considérée non nulle) de l’échantillon, \(\frac{\text{écart-type}}{\text{moyenne}}\).
Mais une variable (très) discriminante peut être de faible variance (ou de faible coefficient de variation), comme nous l’avons déjà vu pour l’analyse discriminante. Eliminer cette variable sur la base de ce critère de variance peut être nocif pour la suite de la modélisation.
L’idée de ce critère est d’examiner la relation entre chaque variable explicative \(X\) et la variable expliquée \(Y\). Sont sélectionnées les variables d’entrée qui « expliquent » le mieux (ou prédisent le mieux) la variable de sortie.
Différents critères de qualité prédictive individuelle ou « pertinence » peuvent être employés, par exemple :
Corrélation linéaire (variables quantitatives) : \(r = \frac{\textrm{Cov}(X,Y)}{\sigma(X) \sigma(Y)} \in [-1, 1]\) (\(\textrm{Cov}\) étant la covariance, \(\sigma\) l’écart-type).
Test du \(\chi^2\) d’indépendance (variables qualitatives ou variables quantitatives discrètes ; il peut être utile de revoir Analyse des correspondances binaires) :
Considérons \(X\) et \(Y\) variables discrètes, prenant chacune un nombre fini de valeurs ;
Nous avons \(N\) observations au total : pour \(n_{ij}\) observations \(X\) prend sa \(i\)-ème valeur et \(Y\) sa \(j\)-ème valeur, on note \(n_{i\_}=\sum_j n_{ij}\), \(n_{\_j}=\sum_i n_{ij}\), \(e_{ij} = \frac{n_{i\_} n_{\_j}}{N}\) ;
Pour chaque variable \(X\) calculons \(t_X = \sum_{i,j} \frac{(n_{ij} - e_{ij})^2}{e_{ij}}\), qui est l’écart entre la distribution conjointe de \(X,Y\) et la distribution correspondant à l’indépendance ;
Nous n’appliquons pas le test statistique d’indépendance mais nous trions plutôt les variables \(X\) en ordre décroissant de leurs valeurs \(t_X\), ensuite nous éliminons les variables \(X\) pour lesquelles ces valeurs sont trop faibles.
Information mutuelle entre \(X\) et \(Y\), qui mesure ce qu’apporte la connaissance de \(X\) à la connaissance de \(Y\) :
Pour \(X\) et \(Y\) discrètes : \(I(X;Y) = \sum_{x,y} P(x,y) \log\frac{P(x,y)}{P(x) P(y)}\).
Pour \(X\) et \(Y\) continues : \(I(X;Y) = \int_{\mathbb{R}}\int_{\mathbb{R}} p(x,y) \log \frac{p(x,y)}{p(x) p(y)} dx dy\).
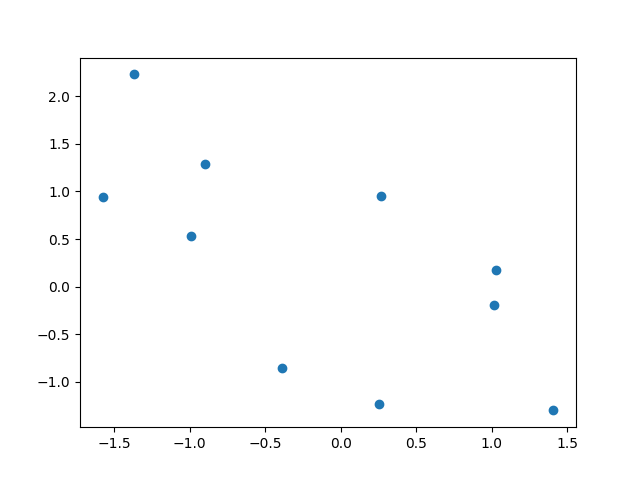
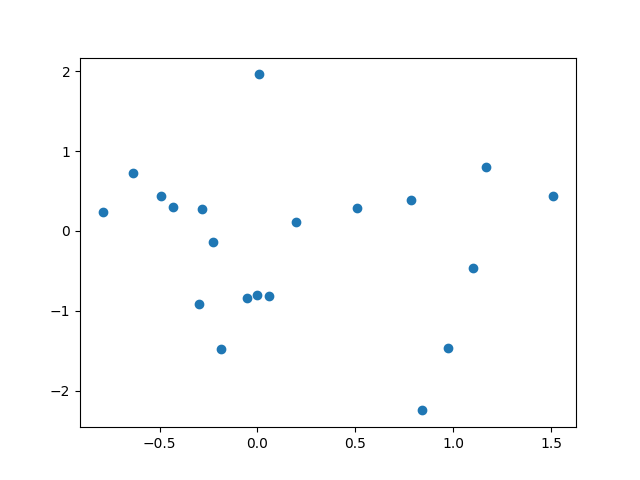
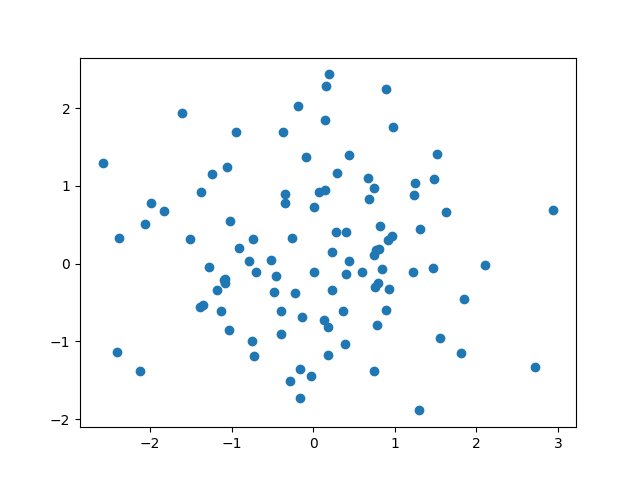
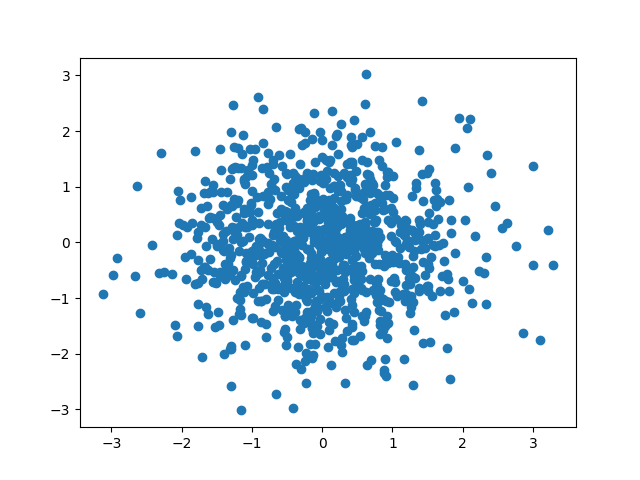
Comme le montre la figure suivante, l’information mutuelle permet de mieux caractériser les relations de dépendance entre deux variables que la corrélation linéaire.
Fig. 151 Relations entre deux variables sur un ensemble d’observations. Les relations sont bien représentées (en haut) ou mal représentées (en bas) par la correlation linéaire (illustration issue de [VMK18]). La valeur de la corrélation linéaire est pour chaque cas en haut à gauche et la valeur de l’information mutuelle en haut à droite (en italiques).¶
Quel que soit le critère exact choisi, nous sélectionnons soit les \(k\) variables d’entrée qui sont individuellement les plus pertinentes par rapport à ce critère, ou celles dont la pertinence est supérieure à un seuil, ou à la moyenne, ou nous sélectionnons les \(k\) premiers déciles, etc.
Une insuffisance importante de cette approche de sélection de \(k \ll m\) variables parmi \(m\) est que les \(k\) variables sont individuellement les plus « explicatives » mais souvent redondantes, c’est à dire que certaines apportent approximativement la même information que d’autres concernant la variable expliquée. Des variables individuellement moins « explicatives » mais plus complémentaires aux autres (moins redondantes) ne sont pas sélectionnées, il y a donc un potentiel d’amélioration qui incite à considérer les critères suivants.
Les \(k\) variables choisies par la méthode de sélection sont ultérieurement employées ensemble pour prédire la variable expliquée. Chaque variable apporte sa contribution au sein du groupe de variables, cette contribution n’est pas nécessairement bien représentée par la contribution individuelle de cette variable considérée comme seule variable explicative. Sélectionner les groupes de variables explicatives donne souvent de meilleurs résultats (meilleures performances avec moins de variables) que la sélection sur la base de la qualité prédictive individuelle.
En règle générale on évite de comparer deux groupes quelconques de variables car l’espace de recherche serait trop large. On préfère comparer un groupe au même groupe avec une variable en plus (procédure incrémentale) ou avec une variable en moins (procédure décrémentale).
Le critère employé pour caractériser la capacité prédictive d’un groupe de variables explicatives dépend de l’approche employée.
Dans une approche wrapper :
avec chaque groupe de variables candidat on développe un modèle décisionnel,
on choisit le groupe pour lequel la performance du modèle décisionnel est meilleure.
Filtrage : extension au groupe de critères de qualité prédictive individuelle
pour la corrélation, on calcule la valeur moyenne entre variables du groupe des corrélations linéaires des variables individuelles du groupe avec la variable de sortie ;
pour l’information mutuelle, on calcule la valeur moyenne entre variables du groupe des informations mutuelles avec la variable de sortie, ou on emploie directement l’extension à plusieurs variables de l’information mutuelle :
(\(X^{(m)}\) étant un ensemble de \(m\) variables d’entrée).
Qualité prédictive de groupe et réduction de la redondance¶
Lorsqu’on emploie en pratique les méthodes proposées pour l’extension à un groupe de variables de critères de qualité prédictive individuelle, suivant l’approche de filtrage, on constate que :
Moyenner des corrélations, ou des informations mutuelles entre variables deux à deux, fait perdre en sélectivité et mène à de faibles écarts de qualité prédictive entre groupes de variables, avec pour conséquence la sélection d’un nombre élevé de variables (surtout avec une procédure décrémentale), entre lesquelles il y a de la redondance (des variables explicatives différentes apportent approximativement la même information concernant la variable expliquée).
Le calcul de l’information mutuelle est peu fiable quand il y a beaucoup de variables explicatives car le nombre d’observations est insuffisant. On peut constater ce problème même sur un exemple simple unidimensionnel. En effet, générons des données à partir de deux variables indépendantes (par construction) \(X\) et \(Y\), chacune suivant une loi normale, faisons varier la taille de l’échantillon et estimons l’information mutuelle entre \(X\) et \(Y\) à partir de cet échantillon :
\(n\):
10
20
100
1000
\(I(X;Y)\):
0.07
0.025
0.0135
0.002
On observe qu’un échantillon faible fait augmenter artificiellement l’information mutuelle, des variables non pertinentes semblent alors pertinentes et sont ainsi sélectionnées, ce qui mène à la sélection d’un nombre excessif de variables entre lesquelles il y a de la redondance. Pour que l’information mutuelle soit estimée de façon fiable, la taille de l’échantillon devrait croître exponentiellement avec le nombre de variables, ce qui très rarement le cas sur des données réelles.
Une solution est apportée en combinant la qualité de prédiction de la variable expliquée et la réduction de la redondance entre variables explicatives sélectionnées. Un exemple de méthode de sélection qui suit ce principe est minimum Redundancy and Maximum Relevance (mRMR, [PLD05]), dont les objectifs précis sont :
Augmenter la qualité prédictive mesurée par l’information mutuelle entre les variables explicatives sélectionnées et la variable de sortie, \(D = \frac{1}{m} \sum_i I(X_i;Y)\),
Tout en réduisant la redondance des variables sélectionnées, mesurée par l’information mutuelle moyenne entre ces variables, \(R = \frac{1}{m^2} \sum_{i,j} I(X_i;X_j)\).
L’algorithme mRMR fait une sélection incrémentale en maximisant un des critères suivants :
Mutual information difference (MID): \(\max_i(D-R)\), ou
Mutual information quotient (MIQ): \(\max_i\frac{D}{R}\).
Nous remarquerons que le choix d’une sélection incrémentale est important pour que les moyennes employées pour \(D\) et \(N\) restent discriminantes.
Dans [PLD05] est montré que mRMR est équivalent à l’utilisation de l’information mutuelle multi-dimensionnelle (59) sans l’inconvénient du calcul peu fiable sur un petit échantillon multidimensionnel.
D’autres méthodes proposées suivent le même principe, comme MIMR (Maximum Information and Minimum Redundancy[LSM12]) ou MRMR (Maximum Relevance and Minimum Redundancy[ZAW19].
Quels critères de sélection pour quelles approches¶
L’approche de filtrage peut faire appel à tous les critères de sélection explicites mentionnés :
Propriétés intrinsèques d’une variable (d’entrée) et plus spécifiquement le coefficient de variation.
Caractérisation de chaque variable d’entrée par rapport à la variable de sortie, en utilisant par exemple la corrélation ou l’information mutuelle.
Caractérisation d’un groupe de variables d’entrée par rapport à la variable de sortie, en utilisant par exemple l’information mutuelle multi-dimensionnelle (59).
Caractérisation d’un groupe de variables d’entrée entre elles et par rapport à la variable de sortie, en utilisant par exemple mRMR.
Dans l’approche wrapper l’évaluation d’un groupe de variables est faite uniquement à travers les performances de validation du modèle prédictif qui emploie ce groupe de variables. Cette approche n’utilise pas les propriétés intrinsèques d’une variable d’entrée, évalue des groupes de variables d’entrée (et non une variable d’entrée seule, ce serait peu pertinent car un modèle prédictif construit avec une seule variable d’entrée est en général peu performant) par rapport à la variable de sortie, et ne traite pas explicitement la redondance entre des variables d’entrée (cette redondance est maîtrisée à travers le contrôle de la complexité du modèle prédictif).
Dans l’approche d’intégration de la sélection de variables à la méthode de construction de modèle prédictif, certaines méthodes (par ex. pour les arbres de décision) font appel à des critères explicites concernant des variables individuelles, d’autres (par ex. la régularisation \(L_1\)) passent par des mécanismes implicites.
La sélection de variables peut présenter des intérêts multiples comme la réduction du bruit, l’amélioration de la généralisation, l’amélioration de la lisibilité, la simplification de la mise en production, etc.
L’approche de filtrage est moins coûteuse mais potentiellement moins performante que l’approche wrapper.
Une sélection de variables est intégrée à certaines méthodes de modélisation prédictive (à découvrir dans RCP209).
Combiner l’optimisation de la qualité prédictive et la réduction de la redondance dans une approche de filtrage peut constituer un bon compromis entre coût et performance.
Li, C., V. P. Singh, and A. K. Mishra. Entropy theory-based criterion for hydrometric network evaluation and design: Maximum information minimum redundancy2. Water Resources Research, 48(5), 2012.
Molina, L., L. Belanche, and A. Nebot. Feature selection algorithms: a survey and experimental evaluation. In 2002 IEEE International Conference on Data Mining, 2002. Proceedings, pages 306–313, 2002.
Peng, H., F. Long, and C. Ding. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell., 27(8) :1226–1238, Aug. 2005.
Tang, J., S. Alelyani, and H. Liu. Feature selection for classification: A review. In Data Classification: Algorithms and Applications, pages 37–64. 2014.
Vu, T., A. Mishra, and G. Kumar. Information entropy suggests stronger nonlinear associations between hydro-meteorological variables and enso. Entropy, 20 :38, 01 2018.


![Relations entre deux variables: bien représentées (en haut) ou mal représentées (en bas) par la corrélation linéaire (illustration issue de [VMK18]_)](_images/The-comparison-between-linear-correlation-coefficient-LCC-and-nonlinear-correlation.png)