Il arrive assez fréquemment que des observations soient incomplètes, c’est à dire les valeurs d’une ou plusieurs variables manquent. On parle d’observations à données manquantes. Par exemple, dans le cas d’un sondage, certaines personnes ne répondent pas à certaines questions ou alors certaines réponses sont oubliées lors de la saisie informatique. Parfois ce sont de simples problèmes liés au codage des données (par exemple, présence de caractères non interprétables par la fonction de lecture de données) qui font disparaître certaines valeurs. Si on considère le cas de mesures issues de capteurs, un des capteurs peut fonctionner de façon intermittente ou alors la transmission des mesures peut subir des perturbations ponctuelles. Quel est l’impact de l’absence de certaines données sur la construction de modèles à partir des données et sur la prise de décision avec ces modèles ?
Lorsque les observations à données manquantes font partie des observations employées pour la construction d’un modèle, une solution simple est d’ignorer ces observations incomplètes. Bien que fréquemment employée par défaut, cette solution s’avère simpliste car ses conséquences peuvent être, comme nous le verrons plus loin, non seulement une diminution des performances du modèle, mais potentiellement un fort biais de modélisation pouvant conduire à un modèle inopérant. Avant de décider d’ignorer les observations incomplètes il est donc nécessaire de mieux comprendre pourquoi des données manquent. Une solution qui s’avère souvent meilleure (du point de vue des performances du modèle décisionnel construit à partir des données) consiste à estimer (ou imputer) les données manquantes et à traiter les valeurs estimées comme des valeurs mesurées. Enfin, la solution idéale serait de corriger les erreurs responsables des données manquantes ou de compléter la collecte de données, mais cette solution n’est pas toujours accessible.
Si le modèle est déjà construit et ce sont les observations auxquelles le modèle doit être appliqué qui présentent des données manquantes, il est nécessaire d’examiner attentivement l’impact sur la décision des différentes méthodes d’estimation.
Comment caractériser l’absence de certaines données¶
Afin de mieux comprendre l’impact de différentes approches proposées pour faire face au problème des données manquantes, il est nécessaire d’examiner d’abord la nature de ce manque de données.
Considérons un tableau de \(n\) observations décrites par \(d\) variables, représenté par la matrice de données \(\mathbf{X}\) (\(n \times d\)) :
Observation
\(X_1\)
\(X_2\)
…
\(X_d\)
\(o_1\)
…
…
…
…
…
…
…
…
…
\(o_n\)
…
…
…
…
La matrice indicatrice des données manquantes (\(n \times d\) également) est \(\mathbf{M} = (m_{ij})\), avec \(m_{ij} = 1\) si la valeur \(x_{ij}\) est manquante et \(m_{ij} = 0\) sinon. Enfin, on note par \(\mathbf{X}_o\) les données observées et par \(\mathbf{X}_m\) les données manquantes.
L’analyse met en général en évidence les trois cas suivants :
Données manquant de façon complètement aléatoire (missing completely at random, MCAR). Dans ce cas, la probabilité d’absence d’une donnée (la valeur d’une variable) est identique pour toute observation (et toute variable à valeurs manquantes). En utilisant les notations définies ci-dessus, \(p(\mathbf{M} | \mathbf{X}) = p(\mathbf{M})\) (indépendance des données). Par exemple, pour les réponses à un sondage nous sommes dans cette situation (MCAR) si chaque personne interrogée décide de répondre à une question en lançant un dé et en refusant de répondre si la face 1 apparaît. Ce cas est malheureusement bien peu fréquent.
Données manquant de façon aléatoire (missing at random, MAR). Dans ce cas, la probabilité d’absence de la valeur d’une variable est indépendante de la valeur qu’aurait eu cette variable si elle n’avait pas été absente (c’est en ce sens que les données manquent « de façon aléatoire »). Mais cette probabilité dépend des valeurs prises par d’autres variables qui ont été observées. Avec les notations définies plus haut, \(p(\mathbf{M} | \mathbf{X}) = p(\mathbf{M} | \mathbf{X}_o)\). Par exemple, nous sommes dans cette situation (MAR) lorsqu’un participant a plus de chances de ne pas répondre à la question 2 s’il a donné une certaine réponse (bien enregistrée, non manquante) à la question 1. Un autre exemple : la note d’un candidat à un examen de rattrapage sera manquante si le candidat a obtenu une note de passage (connue) à l’examen principal.
Données manquant de façon non aléatoire (missing not at random, MNAR). Dans ce cas, la probabilité d’absence de la valeur d’une variable dépend de variables qui n’ont pas été observées. Par exemple, nous sommes dans cette situation (MNAR) si l’absence de réponse à une question dépend de la catégorie socioprofessionnelle de la personne interrogée et le sondage n’inclut aucune question sur la catégorie socioprofessionnelle (ou d’autres variables permettant de la prédire). Nous sommes encore dans cette situation MNAR si l’absence de réponse à une question dépend de la valeur qu’aurait cette réponse si elle était présente : par exemple, une des réponses à une question du sondage est souvent évitée car difficile à assumer par les personnes interrogées. Avec les notations définies plus haut, le cas MNAR est caractérisé par l’absence de réduction possible de \(p(\mathbf{M} | \mathbf{X})\) (car il y a dépendance de données manquantes \(\mathbf{X}_m\)) ou par le fait que \(p(\mathbf{M} | \mathbf{X})\) ne donne pas d’indication utile (car les variables pouvant expliquer \(\mathbf{M}\) ne sont pas dans \(\mathbf{X}\)).
Il n’est pas possible de savoir, uniquement à partir des observations disponibles concernant un problème de modélisation, si des données manquent de façon aléatoire ou non (cas MAR ou cas MNAR). Pour tenter de répondre à cette question il est conseillé de chercher d’autres travaux sur le même problème de modélisation (caractérisé par les données manquantes), travaux qui peuvent informer sur le mécanisme par lequel des données manquent. Il est également envisageable d’inclure dans l’étude (par ex. dans le questionnaire) un maximum de variables qui ont le potentiel d’expliquer les données manquantes ; cela permet de rendre le cas MAR plus probable (parmi les variables observées, on en trouve qui expliquent le manque de certaines valeurs pour d’autres variables) que le cas MNAR.
Lorsque les données manquent de façon non aléatoire (cas MNAR), par la définition même de ce cas, un modèle pour le manque de données est indisponible. Ici encore, des travaux antérieurs, même qualitatifs, sur le même problème de modélisation peuvent informer sur un modèle du manque de données et il est éventuellement possible de compléter la collecte (observer de nouvelles variables, explicatives pour le manque de données) afin de passer du cas MNAR au cas MAR.
Regardons d’abord l’impact de la solution la plus simple qui consiste à ignorer les observations incomplètes (présentant des données manquantes). Nous nous intéressons ensuite à différentes méthodes qui permettent d’estimer les données manquantes afin de compléter les observations.
Suppression des observations à données manquantes¶
Lorsque certaines données manquent, une approche fréquemment employée par défaut consiste à ignorer les observations incomplètes. La construction du modèle est réalisée avec les seules observations complètes. Suivant la nature du manque de données, l’impact de l’utilisation de cette approche peut être très différent :
Dans le cas MCAR (la probabilité d’absence d’une donnée est identique pour toute observation), ignorer les observations à données manquantes équivaut à utiliser un échantillon aléatoire des observations (celles qui sont complètes). Si ce choix n’introduit pas de biais particulier dans la modélisation, il peut diminuer la qualité du modèle résultant si le nombre d’observations complètes n’est pas assez élevé. En présence de classes déséquilibrées (certaines classes d’observations sont d’effectif bien plus faible que les autres), cette réduction du nombre d’observations exploitables pour la modélisation peut avoir un impact significatif car les classes les plus rares peuvent être représentées par un nombre très insuffisant d’observations complètes (ou même disparaître).
Dans le cas MAR, ignorer les observations à données manquantes introduit un biais dans la modélisation. En effet, dans ce cas la valeur d’une variable manque lorsque d’autres variables, observées, prennent certaines (combinaisons de) valeurs. Ignorer les observations incomplètes revient à ignorer la plupart des occurrences de ces combinaisons de valeurs pour ces variables observées. Par exemple, si les participants à un sondage ne répondent pas à la question 2 lorsqu’ils ont donné la réponse A à la question 1, ignorer les observations à données manquantes implique aussi d’ignorer les réponses A à la question 1. Dans le cas MAR il peut donc être préférable de « compléter » les observations incomplètes par l’estimation (l’imputation) des données manquantes grâce à une modélisation de la dépendance entre les variables observées et la variable à valeurs manquantes.
Dans le cas MNAR, ignorer les observations à données manquantes introduit un biais dans la modélisation car cela revient à éliminer des observations de façon non aléatoire. En revanche, dans le cas MNAR, vu que l’absence de la valeur d’une variable ne dépend pas de variables observées, l’estimation (l’imputation) des données manquantes à partir des valeurs prises par les variables observées est plus difficile à justifier.
Nous avons constaté qu’il était intéressant, notamment dans le cas MAR, d’estimer les données manquantes afin de compléter les observations au départ incomplètes. Cela peut permettre de réduire le biais de modélisation (cas MAR) ou améliorer la précision du modèle résultant (cas MCAR). Après imputation, le modèle est construit à partir de toutes les observations, celles qui étaient complètes au départ et celles complétées par imputation. Nous remarquerons ici que dans certaines méthodes l’imputation et la construction de modèle se déroulent en parallèle (l’algorithme EM donne une idée de ce type d’approche).
C’est une bonne pratique de comparer le modèle obtenu après imputation des données manquantes avec celui obtenu (dans la mesure où cela est possible) par suppression des observations à données manquantes.
Les méthodes d’imputation sont nombreuses, dans la suite de ce chapitre nous examinons quelques-unes des plus simples :
Imputation par une valeur unique : valeur par défaut, moyenne, médiane.
Imputation par des valeurs caractérisant des sous-ensembles de données : groupes, classes.
Imputation à partir des \(k\) plus proches voisins.
Imputation par décomposition en valeurs singulières.
La méthode la plus simple consiste à employer, pour chaque variable à valeurs manquantes, une seule valeur comme estimation de ses valeurs manquantes. La valeur utilisée peut être
Une valeur fixe, indépendante des données (et donc la même pour toutes les variables à valeurs manquantes), par exemple la valeur 0. Cette solution est parfois employée par défaut lors de la lecture même des fichiers de données (voir par ex. la fonction numpy.genfromtxt()). Bien entendu, un choix arbitraire doit être évité. L’utilisation de la valeur 0 est concevable si la variable concernée est de moyenne nulle (voir le cas suivant).
Une valeur représentative de la distribution de la variable concernée :
Pour une variable quantitative, la moyenne des valeurs présentes (non manquantes) peut être employée. La moyenne est toutefois sensible à la présence de quelques valeurs extrêmes, le choix de la médiane est préférable.
La médiane des valeurs non manquantes a une bien meilleure robustesse que la moyenne en présence de valeurs extrêmes.
Pour une variable quantitative qui ne peut prendre qu’un nombre très limité de valeurs différentes ou pour une variable nominale (à modalités), il est possible de choisir la valeur la plus fréquente parmi les valeurs présentes.
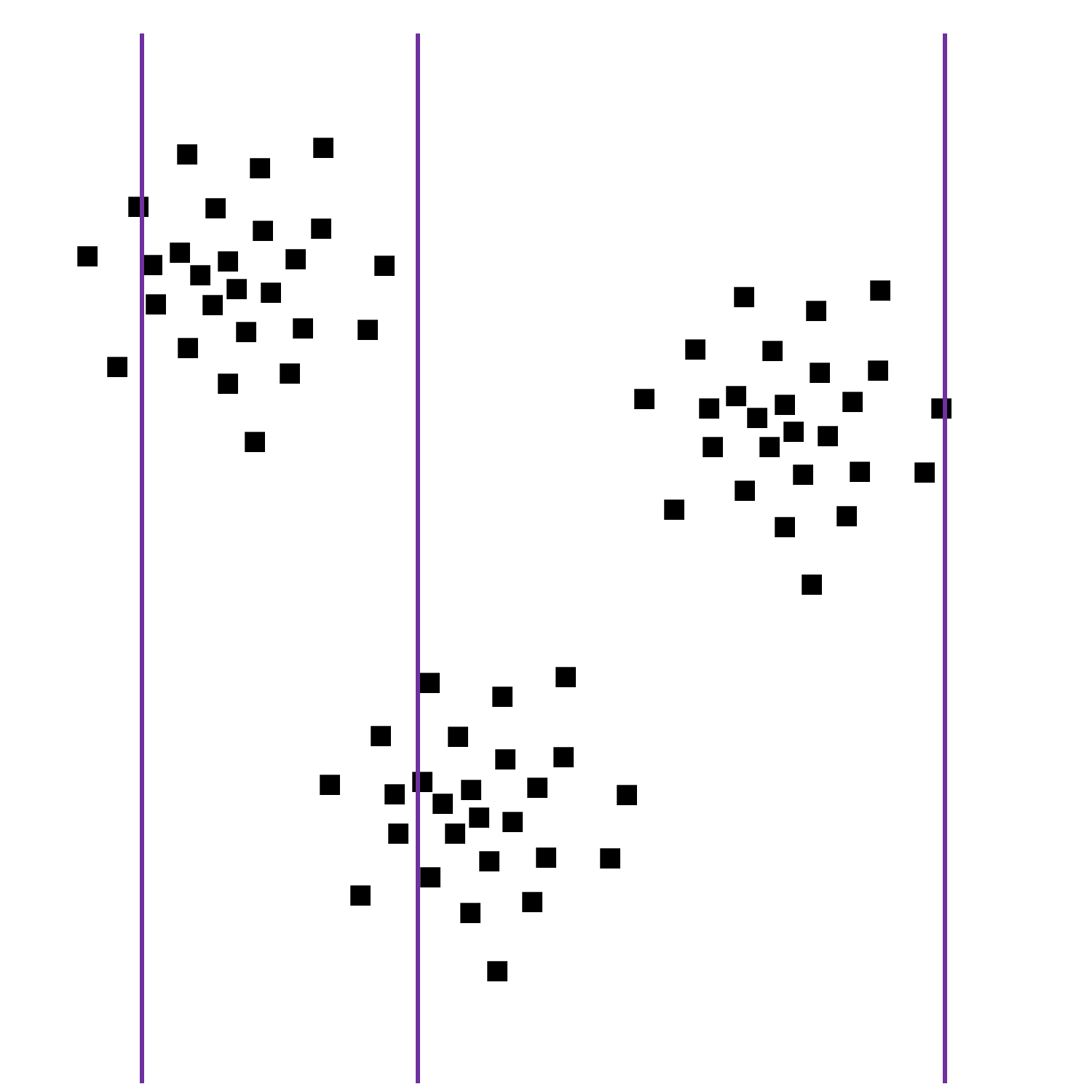
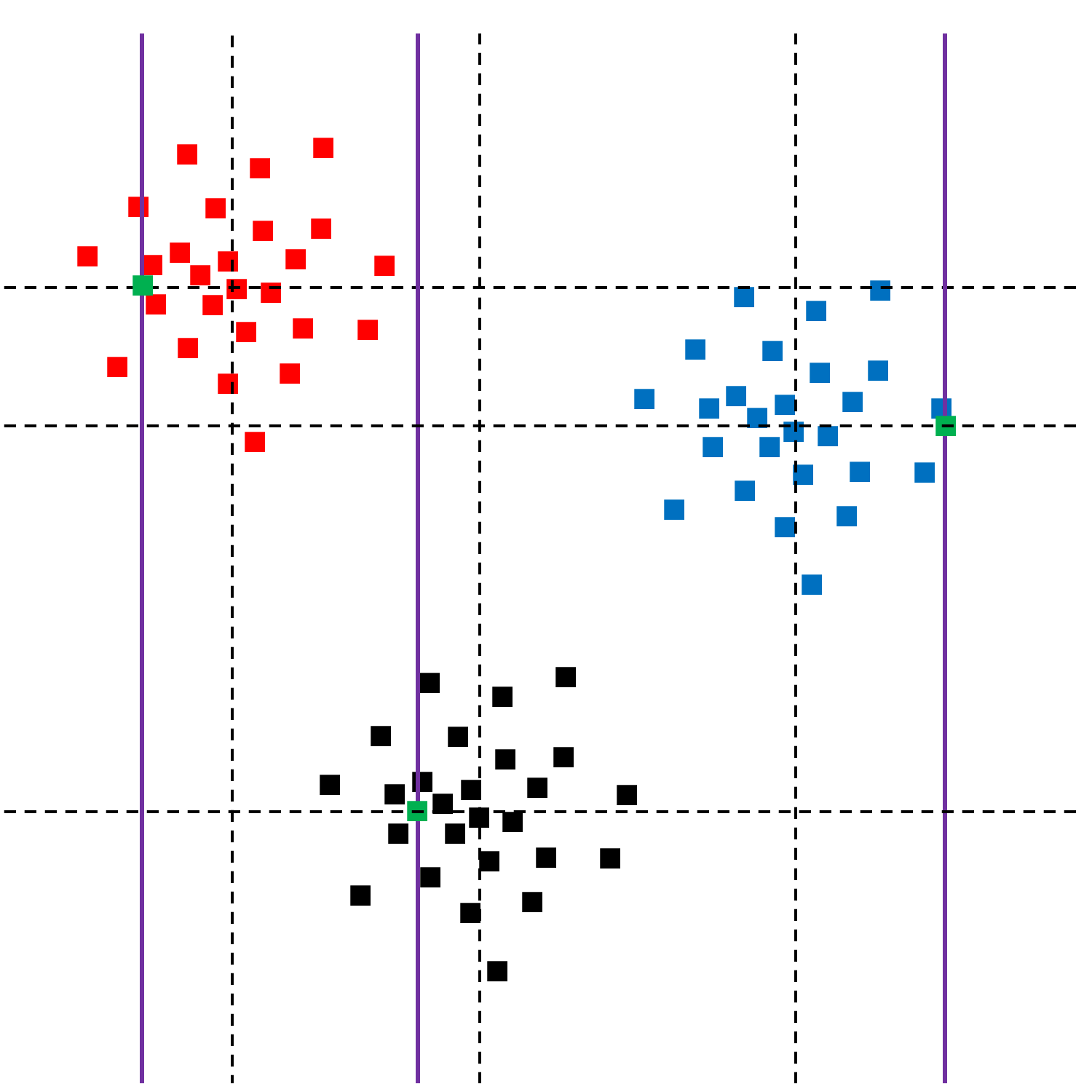
Les illustrations suivantes montrent deux ensembles d’observations bidimensionnelles (de \(\mathbb{R}^2\), variable \(X\) pour l’abscisse et \(Y\) pour l’ordonnée) qui présentent des caractéristiques différentes. Les lignes verticales correspondent aux abscisses (coordonnées horizontales, variable \(X\)) de trois observations pour lesquelles l’ordonnée (coordonnée verticale, variable \(Y\)) est manquante.
Fig. 116 Observations à valeurs manquantes (ordonnée inconnue)¶
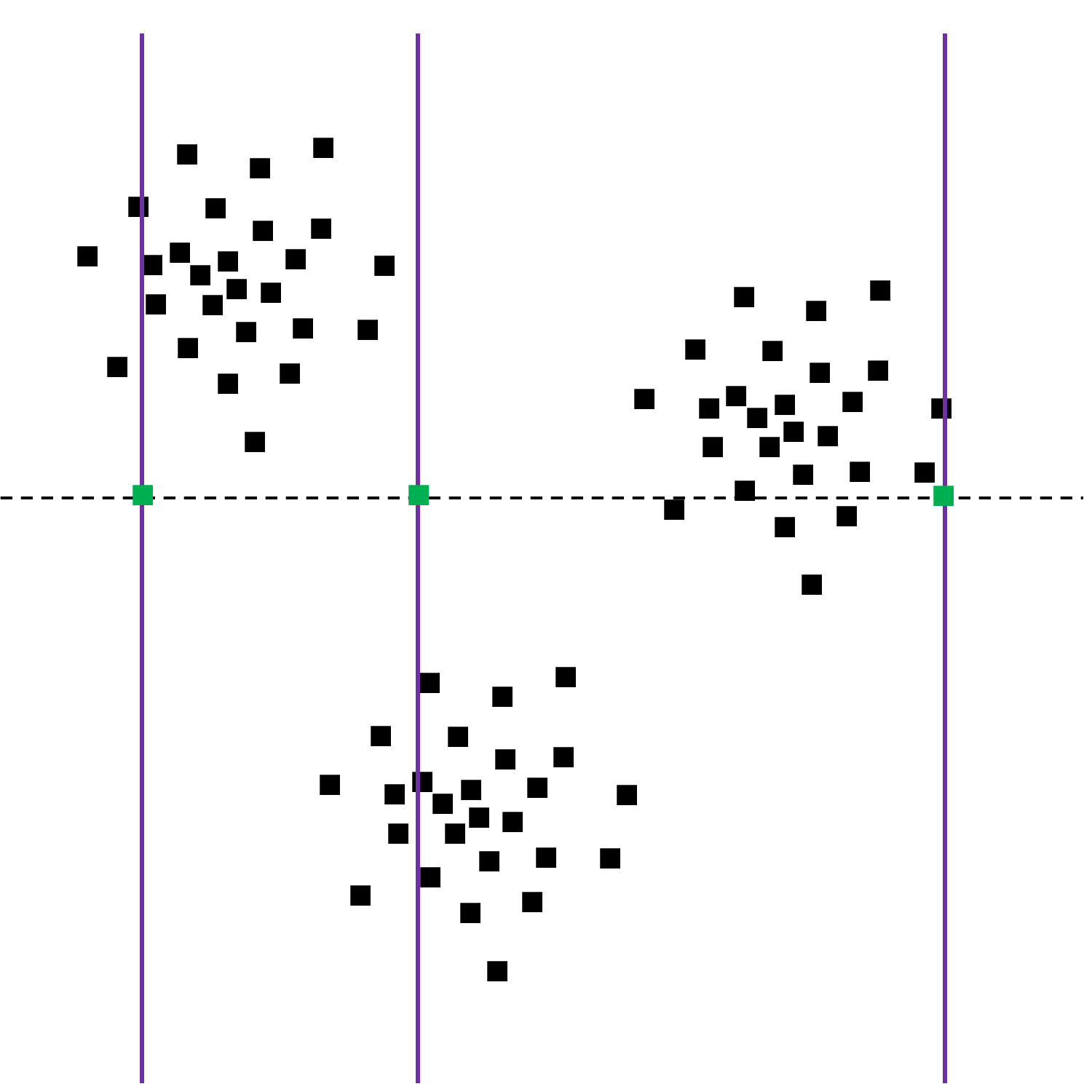
Après l’imputation par la moyenne (valeur indiquée par le trait pointillé horizontal), on peut voir où sont positionnées les observations complétées. On peut constater que ces positions ne reflètent pas bien la distribution des observations en général. En effet, l’imputation tient compte uniquement de la distribution marginale des ordonnées (variable \(Y\)) alors que la distribution jointe des abscisses et ordonnées des observations met en évidence une dépendance entre ces deux variables \(X\) et \(Y\).
Il est important de noter que l’utilisation d’une valeur unique pour imputer les valeurs manquantes d’une variable peut réduire très fortement la variance estimée pour cette variable. Cela doit être pris en considération dans l’interprétation des résultats de différentes analyses et dans la suite de la modélisation.
Imputation par une moyenne partielle : centre du groupe¶
Lorsque des regroupements « naturels » sont présents dans les données, il est possible d’utiliser les centres des groupes pour imputer les valeurs manquantes de certaines observations. Cela permet de tenir compte des distributions marginales limitées à des sous-ensembles de données, sous-ensembles qui sont pertinents par rapport à la distribution jointe des variables.
La procédure est simple :
Un algorithme de classification automatique, par ex. k-moyennes, est appliqué aux observations complètes (sans données manquantes).
Pour chaque observation à données manquantes, il faut ensuite
calculer la distance au centre de chaque groupe en tenant compte uniquement des valeurs des variables renseignées pour cette observation,
déterminer le centre le plus proche de l’observation,
donner à chaque variable non renseignée la valeur de la même variable pour le centre de groupe trouvé comme étant le plus proche.
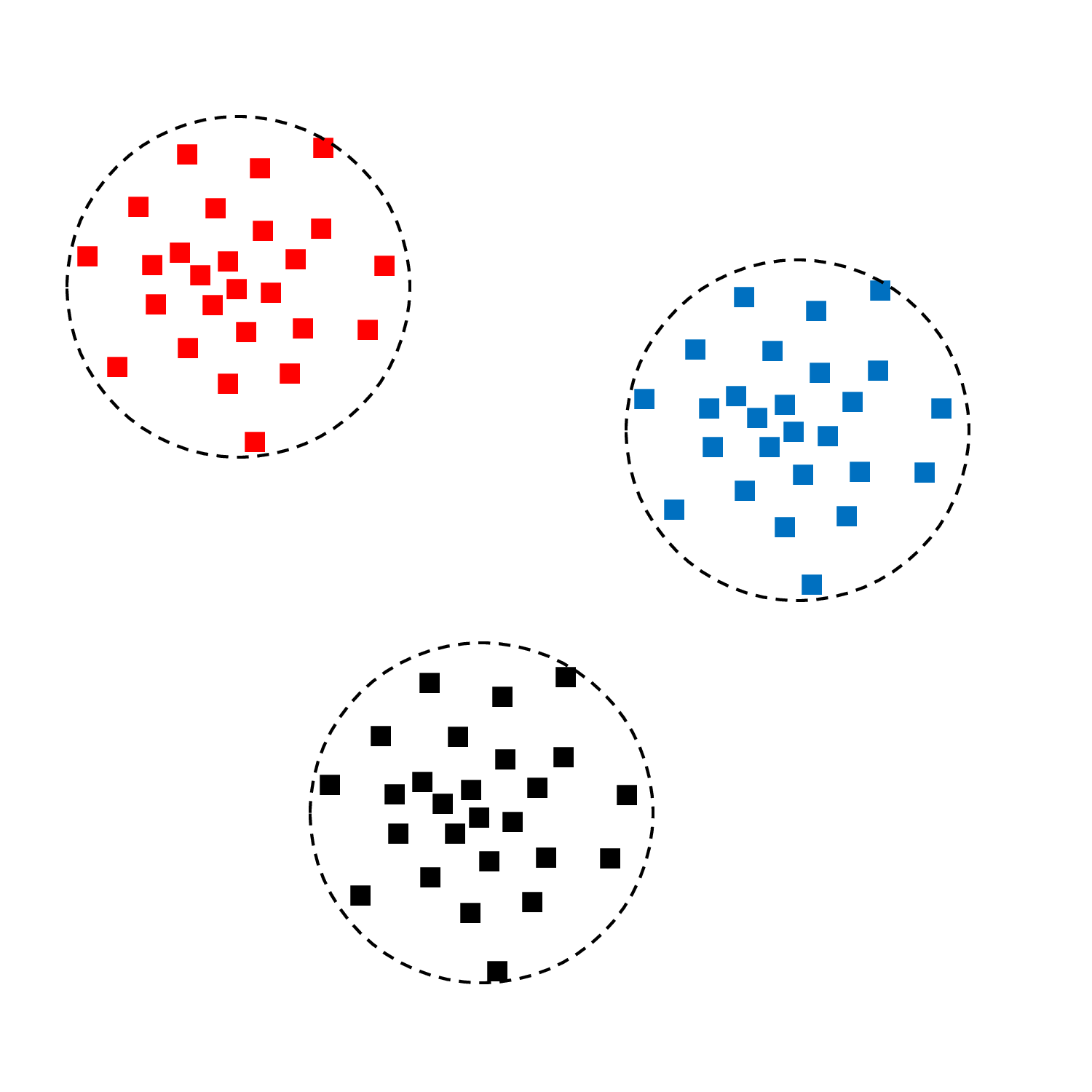
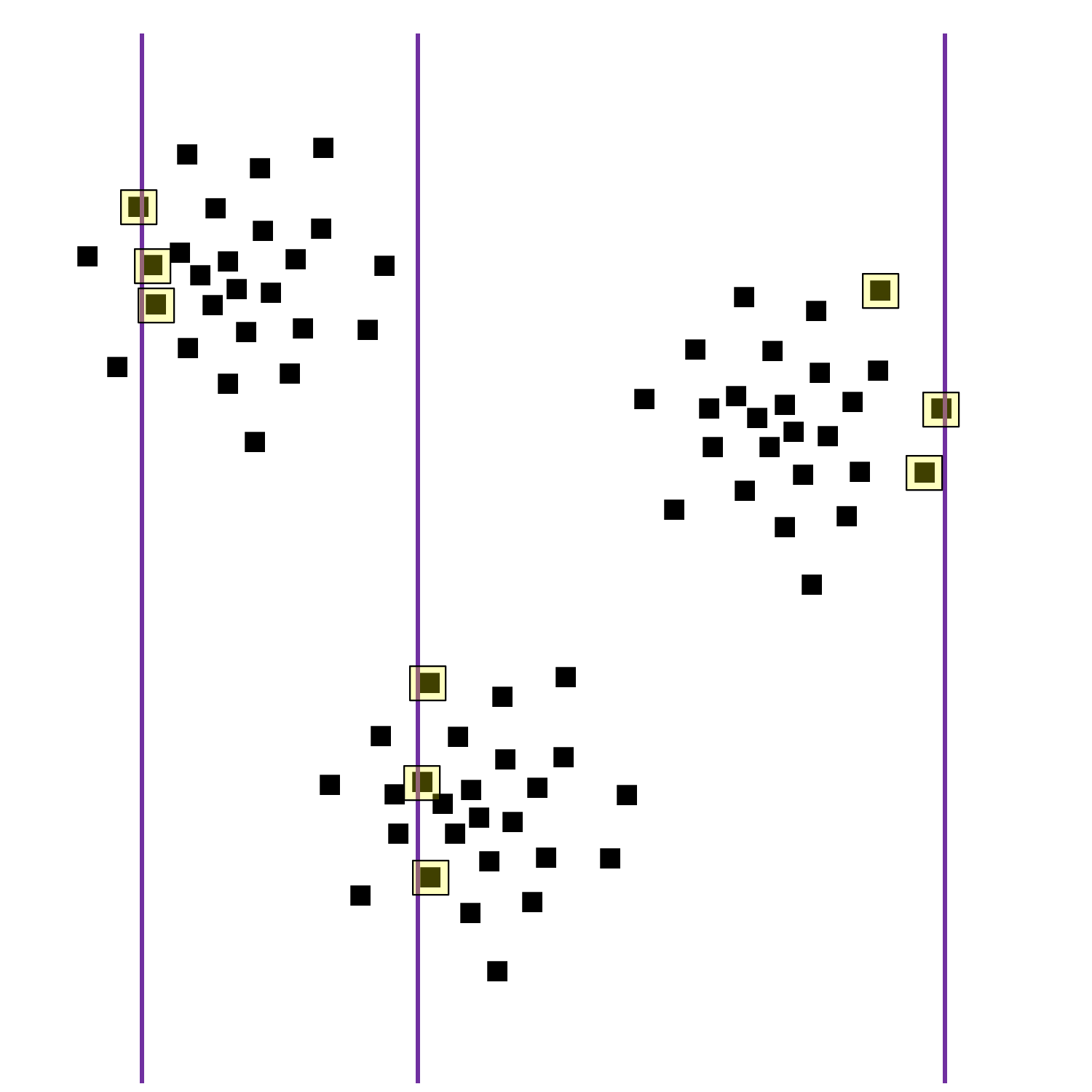
Les illustrations suivantes montrent un ensemble d’observations bidimensionnelles qui forment 3 groupes et l’application de cette procédure d’imputation sur ces observations.
Fig. 121 Groupes trouvés par classification automatique des observations complètes¶
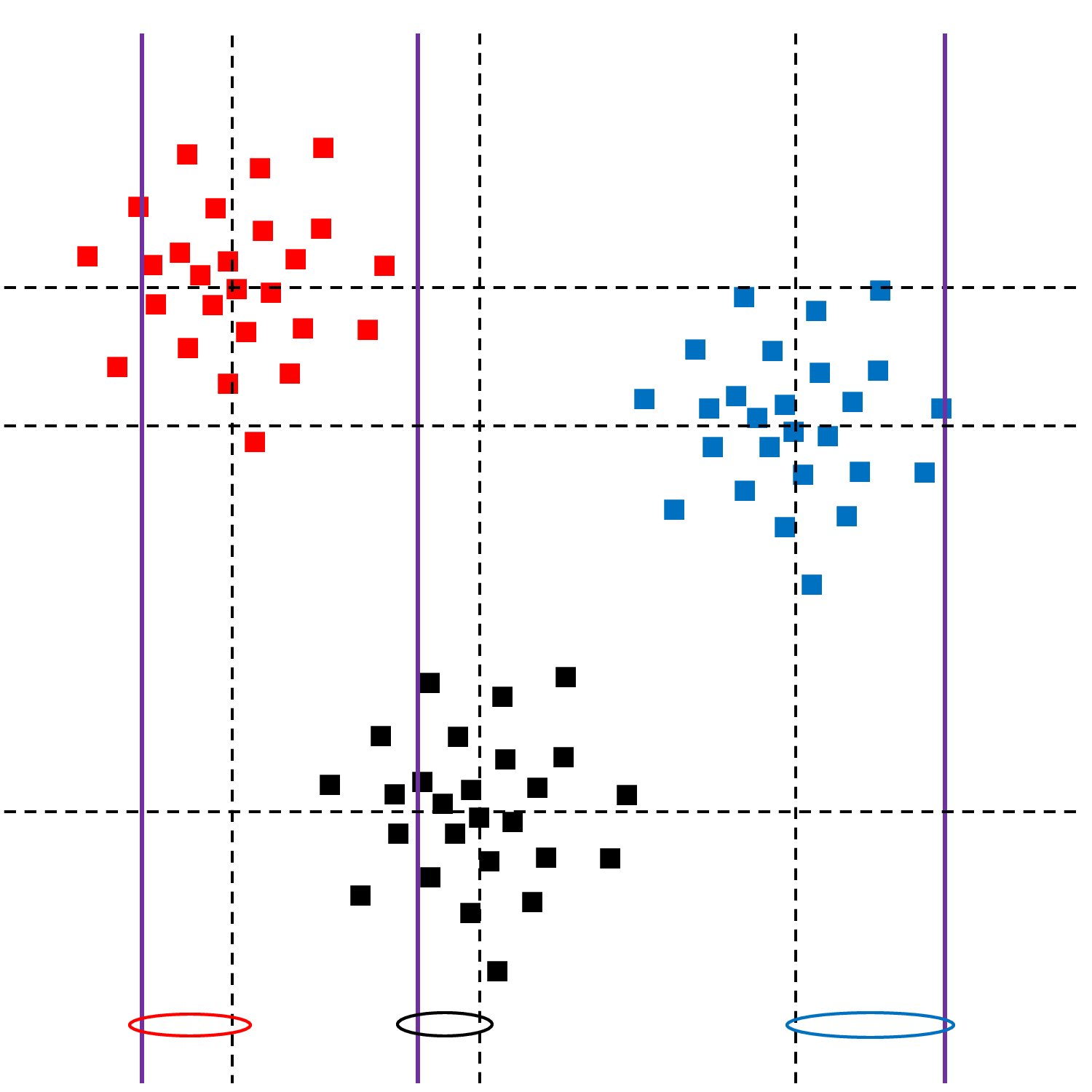
Pour chacune des trois observations à ordonnée manquante (variable \(Y\)), représentées par une ligne verticale à la position de l’abscisse (variable \(X\)), le centre de groupe le plus proche est déterminé en tenant compte uniquement des variables renseignées, ici la variable \(X\) :
Imputation par une moyenne partielle : centre de la classe¶
Lorsque les observations sont décrites également par une variable nominale importante (« classe ») il peut être utile de tenir compte de cette variable pour l’imputation. Si une observation à données manquantes appartient à une certaine classe, les observations complètes de la même classe peuvent être plus pertinentes que les autres pour estimer ces données manquantes. Concrètement, pour une observation appartenant à une classe, la valeur qui manque pour une des variables est estimée par la moyenne (ou par la médiane) des valeurs prises par cette variable sur les seules observations de la classe.
L’imputation par le centre du groupe et l’imputation à partir des \(k\) plus proches voisins (voir plus loin) peuvent être vues comme des cas particuliers de cette approche, dans lesquels la « classe » n’est pas issue d’une variable nominale observée mais de la similarité entre observations. Pour l’imputation par le centre du groupe, une classe correspond à un groupe résultant de la classification automatique des observations complètes (sans données manquantes). Pour l’imputation à partir des \(k\) plus proches voisins, une « classe » est définie ad hoc pour chaque observation à données manquantes et inclut les \(k\) plus proches voisins de cette observation (déterminés en tenant compte uniquement des variables renseignées).
Nous remarquerons enfin que les moyennes employées pour l’imputation sont en général des moyennes non pondérées. Il est toutefois possible d’utiliser, dans le calcul de ces moyennes, des pondérations inversement proportionnelles aux distances entre l’observation à données manquantes et les observations de la même « classe ». Cela revient à considérer que les observations complètes les plus proches sont plus « représentatives » que les autres.
Imputation à partir des \(k\) plus proches voisins¶
L’utilisation de l’imputation par les centres de groupes peut donner des résultats intéressants mais reste conditionnée par le respect de l’hypothèse de présence de groupes dans les données. Pour une observation à donnée(s) manquante(s), considérer que les observations complètes les plus proches sont plus « représentatives » que les autres constitue une hypothèse moins restrictive. Bien entendu, cette proximité doit être déterminée à partir de calculs de distance limités aux seules variables renseignées pour l’observation à données manquantes.
La procédure est alors :
Pour chaque observation à données manquantes,
trouver ses \(k\) plus proches voisins (observations complètes) en tenant compte, dans les calculs de distances, uniquement des valeurs des variables renseignées pour cette observation,
donner comme valeur, à chaque variable non renseignée, la moyenne des valeurs que prend la même variable pour ces \(k\) voisins.
Les illustrations suivantes montrent les deux mêmes ensembles d’observations bidimensionnelles (de \(\mathbb{R}^2\)) et l’application de cette procédure d’imputation avec \(k=3\) sur ces observations.
Pour chacune des trois observations à ordonnée manquante (variable \(Y\)), représentées par une ligne verticale à la position de l’abscisse (variable \(X\)), les 3 plus proches voisins déterminés en tenant compte uniquement des variables renseignées, ici la variable \(X\), sont :
Fig. 125 Détermination des \(k\) plus proches voisins à partir des variables renseignées¶
Fig. 126 Imputation à partir des \(k\) plus proches voisins¶
Fig. 127 Observations qui forment un nuage allongé¶
Pour chacune des trois observations à ordonnée manquante, représentées par une ligne verticale à la position de l’abscisse, les 3 plus proches voisins déterminés en tenant compte uniquement des variables renseignées sont :
Fig. 128 Détermination des \(k\) plus proches voisins à partir des variables renseignées¶
Fig. 129 Imputation à partir des \(k\) plus proches voisins¶
Les résultats obtenus dans ces deux exemples, sur des ensembles d’observations à caractéristiques différentes, reflètent mieux la distribution jointe des deux variables \(X\) et \(Y\).
Imputation par décomposition en valeurs singulières¶
Cette méthode est intéressante dans les cas où une décomposition en valeurs singulières (SVD) avec une réduction de rang fournit une bonne approximation des observations (complètes), c’est à dire lorsque les observations décrites par \(d\) variables quantitatives se situent à proximité d’un sous-espace linéaire de dimension \(k\) bien plus faible que \(d\). Dans ce cas, une estimation pour la donnée manquante d’une observation est obtenue à l’intersection entre le sous-espace qui est une bonne approximation des observations complètes et le sous-espace obtenu en fixant les valeurs des variables connues pour l’observation à données manquantes.
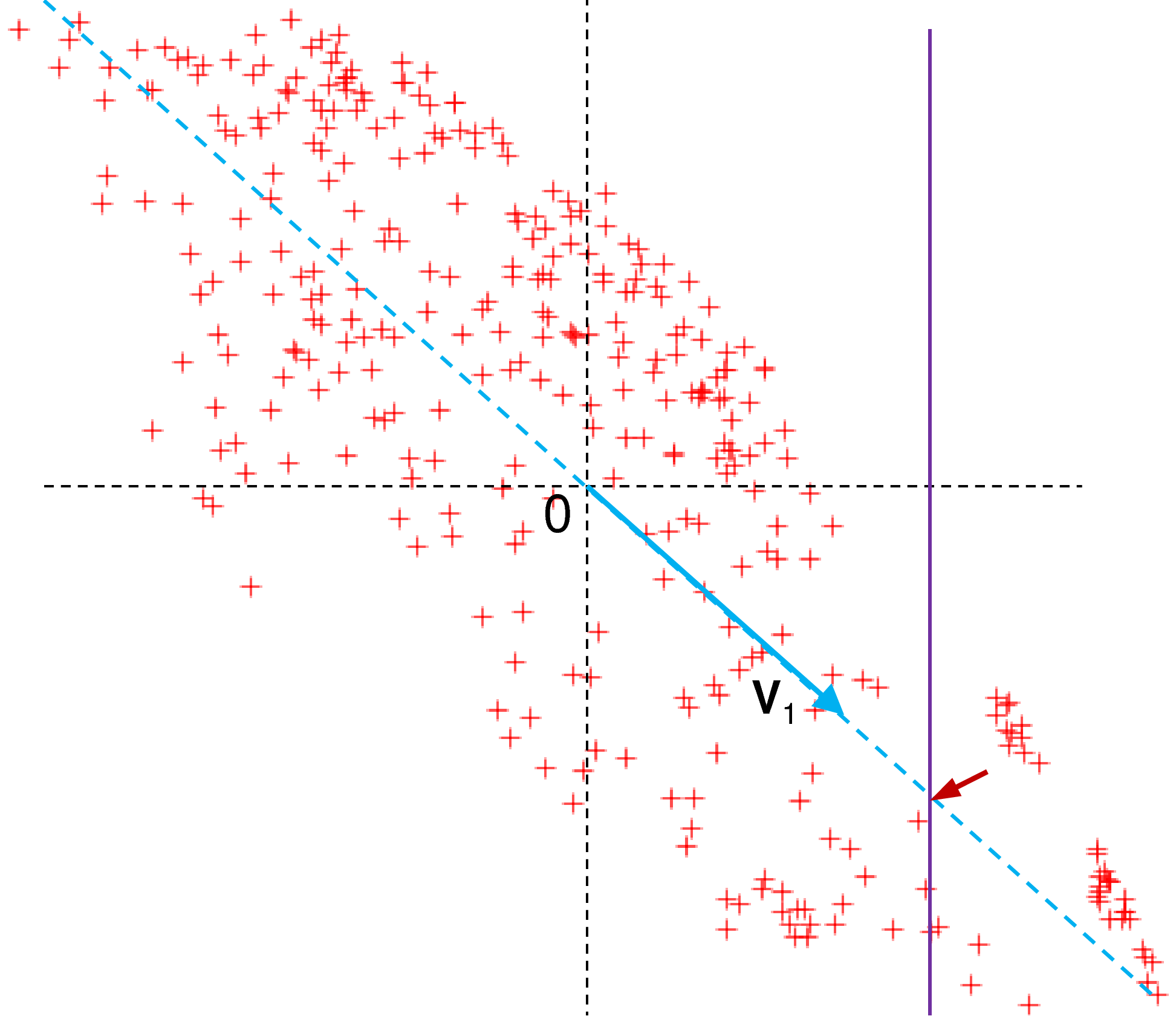
Cette situation est illustrée dans la figure suivante. Les points rouges correspondent à des observations complètes bidimensionnelles (de \(\mathbb{R}^2\), \(d=2\)). Le trait vertical de couleur indigo correspond au sous-espace (ici unidimensionnel) obtenu en fixant la valeur de la variable connue (ici l’abscisse, variable \(X\)) pour une observation à donnée manquante (valeur de l’ordonnée, variable \(Y\)). Enfin, la ligne oblique en pointillés, de couleur bleue, correspond au sous-espace linéaire qui est une bonne approximation unidimensionnelle (\(k = 1 < d\)) du nuage des observations complètes. Une flèche rouge indique l’intersection entre les deux sous-espaces.
Fig. 130 Nuage d’observations bidimensionnelles et droite qui produit sa meilleure approximation unidimensionnelle¶
Pour préciser la méthode, considérons \(\mathbf{X}\) la matrice \(n \times d\) de données (chaque observation correspond à une ligne, chaque variable quantitative à une colonne), \(\mathbf{X}^c\) sa restriction aux observations (lignes) sans données manquantes (\(\mathbf{X}^c\) est donc \(n' \times d\) avec \(n' < n\)) et \(\mathbf{X}^m\) la restriction aux lignes comportant des données manquantes.
Pour rappel, la décomposition en valeurs singulières, de rang réduit \(k < d\), appliquée à \(\mathbf{X}^c\) peut s’écrire
\(\mathbf{U}_k\) (matrice \(n' \times k\)) a pour colonnes les vecteurs propres de \(\mathbf{X}^c (\mathbf{X}^c)^T\) correspondant aux \(k\) plus grandes valeurs propres,
\(\mathbf{D}_k\) (matrice \(k \times k\)) est diagonale avec sur la diagonale les racines carrées des \(k\) valeurs propres de \(\mathbf{X}^c (\mathbf{X}^c)^T\) en ordre décroissant,
\(\mathbf{V}_k\) (matrice \(d \times k\)) a pour colonnes les vecteurs propres de \((\mathbf{X}^c)^T \mathbf{X}^c\) correspondant aux \(k\) plus grandes valeurs propres.
On peut montrer que \(\mathbf{X}_k^c\) est la meilleure approximation de rang \(k\) de \(\mathbf{X}^c\) au sens des moindres carrés, c’est à dire \(\mathbf{X}_k^c = \arg\min_{\mathbf{A}\textrm{ de rang }k} \|\mathbf{X}^c - \mathbf{A}\|^2\)).
La méthode d’imputation par décomposition en valeurs singulières est (voir [HTS99]) :
Appliquer la décomposition en valeurs singulières de rang \(k < d\) à \(\mathbf{X}^c\) pour obtenir \(\mathbf{X}_k^c = \mathbf{U}_k \mathbf{D}_k \mathbf{V}_k^T\).
Pour chaque observation \(\mathbf{x}^m\) (vecteur colonne à \(d\) éléments, qui est le transposé d’une ligne de \(\mathbf{X}^m\)) à données manquantes,
Déterminer \(\mathbf{V}_k^*\), la matrice réduite obtenue de \(\mathbf{V}_k\) en éliminant les lignes d’indices correspondant aux données manquantes de \(\mathbf{x}^m\), et \(\mathbf{V}_k^{(*)}\), ce qui reste de \(\mathbf{V}_k\) une fois \(\mathbf{V}_k^*\) extrait. Si \(a\) valeurs manquent dans \(\mathbf{x}^m\) alors \(\mathbf{V}_k^*\) est \((d-a) \times k\) et \(\mathbf{V}_k^{(*)}\) est \(a \times k\).
Déterminer \(\mathbf{x}^{m*}\), le vecteur réduit obtenu de \(\mathbf{x}^m\) en éliminant les données manquantes, et \(\mathbf{x}^{m(*)}\), la partie de \(\mathbf{x}^m\) correspondant aux données manquantes. \(\mathbf{x}^{m*}\) possède \((d-a)\) composantes et \(\mathbf{x}^{m(*)}\) possède \(a\) composantes.
Estimer \(\mathbf{x}^{m(*)}\) par \(\hat{\mathbf{x}}^{m(*)} = \mathbf{V}_k^{(*)}\left((\mathbf{V}_k^*)^T \mathbf{V}_k^*\right)^{-1} (\mathbf{V}_k^*)^T \mathbf{x}^{m*}\).
Dans l’exemple illustré plus haut \(k = 1\), donc \(\mathbf{V}_k\) est ici une matrice \(2 \times 1\), on obtient par décomposition en valeurs singulières \(\mathbf{v}_1 = \left(\begin{array}{r}0,77\\-0,63\end{array}\right)\). Soit l’observation \(\mathbf{x}^m = \left(\begin{array}{c}1,5\\ ?\end{array}\right)\) (l’ordonnée manque) illustrée plus haut par la ligne verticale de couleur indigo. On obtient alors par imputation \(\hat{\mathbf{x}}^{m(*)} = -1,23\), correspondant à l’ordonnée du point où le trait vertical intersecte le support du vecteur \(\mathbf{v}_1\) (point indiqué par la flèche rouge dans la figure précédente).
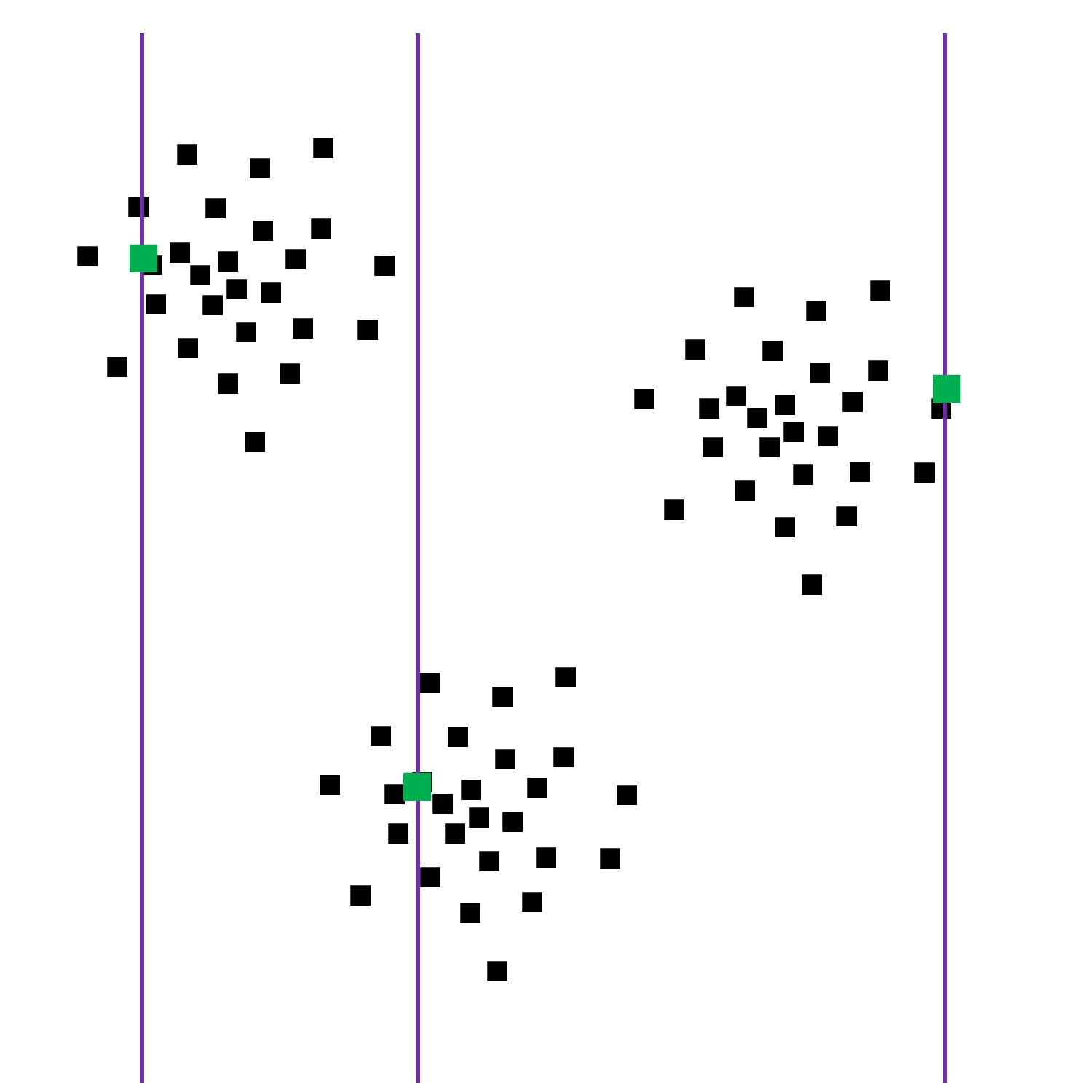
Avec les mêmes observations complètes, la figure suivante montre les valeurs imputées par cette méthode pour trois observations dont l’ordonnée (variable \(Y\)) est absente. Les observations ainsi complétées sont marquées par des points verts :
La valeur du rang réduit \(k\) a un impact important sur le résultat de l’estimation. Une solution pour choisir \(k\) consiste à s’inspirer du choix du nombre de composantes en Analyses en Composantes Principales (ACP) et à imposer une borne supérieure (par ex. de 5%) sur la réduction totale d’inertie obtenue par SVD.
Une autre solution pour choisir \(k\), plus générale car applicable aussi à d’autres paramètres correspondant à d’autres méthodes d’imputation (par ex. au nombre de voisins pour l’imputation à partir des \(k\) plus proches voisins) à condition d’avoir un nombre suffisant d’observations complètes, est d’appliquer la procédure suivante :
Étant donnée la matrice des observations complètes \(\mathbf{X}^c\), générer aléatoirement des matrices indicatrices des données manquantes en retirant à chaque fois les valeurs prises par certaines variables pour certaines observations (par ex. \(\{\mathbf{M}_1, \mathbf{M}_2, \ldots, \mathbf{M}_m\}\)).
Pour différentes valeurs du paramètre (par ex. \(k \in \{k_1, k_2, \ldots, k_p\}\)), imputer ces données manquantes (pour toutes les matrices indicatrices générées) suivant la méthode décrite ci-dessus. Calculer à chaque fois l’erreur quadratique moyenne (moyenne sur les matrices indicatrices générées et, pour chaque matrice, sur les observations à données manquantes) d’estimation de ces données manquantes (\(\{err(k_1), err(k_2), \ldots, err(k_p)\}\)). L’erreur est calculée à chaque fois entre l’estimation (imputation) correspondante et la vraie valeur, connue mais retirée des données dans la première étape.
Choisir la valeur du paramètre \(k\) pour laquelle l’erreur moyenne d’estimation est la plus faible (\(k^*=\arg\min_{1 \leq i \leq p}\{err(k_i)\}\)).
Parmi les différentes approches existantes nous pouvons mentionner également :
Les approches itératives qui alternent à chaque itération deux étapes, comme l’algorithme EM :
grâce aux estimations actuelles des données manquantes, amélioration du modèle permettant d’imputer les données manquantes,
grâce au nouveau modèle d’imputation, amélioration des estimations des données manquantes.
Cette approche est mise en œuvre avec diverses méthodes d’estimation par régression des valeurs manquantes : décomposition en valeurs singulières (SVD, voir [HTS99]), régression linéaire (voir [HTS99]), arbres de régression, forêts aléatoires (MissForest, voir [SB12]), etc.
L’imputation multiple, qui consiste à imputer (estimer) plusieurs fois les données manquantes, à réaliser ensuite l’analyse de (ou la construction de modèle décisionnel à partir de) chaque ensemble de données complétées, puis à intégrer les résultats de ces différentes analyses (ou modèles décisionnels). Différentes techniques peuvent être employées pour imputer plusieurs fois les données manquantes, comme par ex. le tirage aléatoire du modèle d’imputation en suivant sa distribution a posteriori et ensuite l’imputation avec ce modèle. Pour des détails, voir par ex. [Rub87], [HKB11], [vBu12].
Hastie, T., R. Tibshirani, G. Sherlock, M. Eisen, P. Brown, and D. Botstein. Imputing missing data for gene expression arrays. Technical report, Division of Biostatistics, Stanford University, September 1999.






Comment caractériser l’absence de certaines données¶
Afin de mieux comprendre l’impact de différentes approches proposées pour faire face au problème des données manquantes, il est nécessaire d’examiner d’abord la nature de ce manque de données.
Considérons un tableau de \(n\) observations décrites par \(d\) variables, représenté par la matrice de données \(\mathbf{X}\) (\(n \times d\)) :
La matrice indicatrice des données manquantes (\(n \times d\) également) est \(\mathbf{M} = (m_{ij})\), avec \(m_{ij} = 1\) si la valeur \(x_{ij}\) est manquante et \(m_{ij} = 0\) sinon. Enfin, on note par \(\mathbf{X}_o\) les données observées et par \(\mathbf{X}_m\) les données manquantes.
L’analyse met en général en évidence les trois cas suivants :
Données manquant de façon complètement aléatoire (missing completely at random, MCAR). Dans ce cas, la probabilité d’absence d’une donnée (la valeur d’une variable) est identique pour toute observation (et toute variable à valeurs manquantes). En utilisant les notations définies ci-dessus, \(p(\mathbf{M} | \mathbf{X}) = p(\mathbf{M})\) (indépendance des données). Par exemple, pour les réponses à un sondage nous sommes dans cette situation (MCAR) si chaque personne interrogée décide de répondre à une question en lançant un dé et en refusant de répondre si la face 1 apparaît. Ce cas est malheureusement bien peu fréquent.
Données manquant de façon aléatoire (missing at random, MAR). Dans ce cas, la probabilité d’absence de la valeur d’une variable est indépendante de la valeur qu’aurait eu cette variable si elle n’avait pas été absente (c’est en ce sens que les données manquent « de façon aléatoire »). Mais cette probabilité dépend des valeurs prises par d’autres variables qui ont été observées. Avec les notations définies plus haut, \(p(\mathbf{M} | \mathbf{X}) = p(\mathbf{M} | \mathbf{X}_o)\). Par exemple, nous sommes dans cette situation (MAR) lorsqu’un participant a plus de chances de ne pas répondre à la question 2 s’il a donné une certaine réponse (bien enregistrée, non manquante) à la question 1. Un autre exemple : la note d’un candidat à un examen de rattrapage sera manquante si le candidat a obtenu une note de passage (connue) à l’examen principal.
Données manquant de façon non aléatoire (missing not at random, MNAR). Dans ce cas, la probabilité d’absence de la valeur d’une variable dépend de variables qui n’ont pas été observées. Par exemple, nous sommes dans cette situation (MNAR) si l’absence de réponse à une question dépend de la catégorie socioprofessionnelle de la personne interrogée et le sondage n’inclut aucune question sur la catégorie socioprofessionnelle (ou d’autres variables permettant de la prédire). Nous sommes encore dans cette situation MNAR si l’absence de réponse à une question dépend de la valeur qu’aurait cette réponse si elle était présente : par exemple, une des réponses à une question du sondage est souvent évitée car difficile à assumer par les personnes interrogées. Avec les notations définies plus haut, le cas MNAR est caractérisé par l’absence de réduction possible de \(p(\mathbf{M} | \mathbf{X})\) (car il y a dépendance de données manquantes \(\mathbf{X}_m\)) ou par le fait que \(p(\mathbf{M} | \mathbf{X})\) ne donne pas d’indication utile (car les variables pouvant expliquer \(\mathbf{M}\) ne sont pas dans \(\mathbf{X}\)).
Il n’est pas possible de savoir, uniquement à partir des observations disponibles concernant un problème de modélisation, si des données manquent de façon aléatoire ou non (cas MAR ou cas MNAR). Pour tenter de répondre à cette question il est conseillé de chercher d’autres travaux sur le même problème de modélisation (caractérisé par les données manquantes), travaux qui peuvent informer sur le mécanisme par lequel des données manquent. Il est également envisageable d’inclure dans l’étude (par ex. dans le questionnaire) un maximum de variables qui ont le potentiel d’expliquer les données manquantes ; cela permet de rendre le cas MAR plus probable (parmi les variables observées, on en trouve qui expliquent le manque de certaines valeurs pour d’autres variables) que le cas MNAR.
Lorsque les données manquent de façon non aléatoire (cas MNAR), par la définition même de ce cas, un modèle pour le manque de données est indisponible. Ici encore, des travaux antérieurs, même qualitatifs, sur le même problème de modélisation peuvent informer sur un modèle du manque de données et il est éventuellement possible de compléter la collecte (observer de nouvelles variables, explicatives pour le manque de données) afin de passer du cas MNAR au cas MAR.