La distribution des données dans l’espace vectoriel auquel elles appartiennent peut être utilement décrite par une fonction de densité de probabilité. Cette caractérisation de la distribution des données dans l’espace a de multiples intérêts :
Une meilleure compréhension des données : quelles sont les régions de densité élevée (où les données sont les plus denses), ces régions diffèrent-elles d’une classe à une autre (si les observations appartiennent à différentes classes), dans quelles directions les projections des données sont distribuées de façon particulière (par ex., la distribution présente plusieurs maxima bien distincts), etc.
Une caractérisation du support de la distribution, c’est à dire de la région où la densité ne peut pas être assimilée à 0. Cela peut permettre de détecter des données aberrantes (outliers) ou de réaliser un rejet de non représentativité (voir la séance introductive du cours).
La construction de modèles décisionnels de discrimination entre plusieurs classes sur la base des densités de probabilité des classes (sujet qui n’est pas directement abordé dans ce cours).
Étant donné un ensemble de \(N\) observations vectorielles \(\mathcal{D}_N = \{\mathbf{x}_1, \ldots, \mathbf{x}_N\}\) décrites par \(d\) variables, donc \(\mathcal{D}_N \subset \mathbb{R}^d\), l’objectif général de l’estimation de densité est de trouver la fonction de densité de probabilité \(f\) qui a généré l’échantillon aléatoire \(\mathcal{D}_N\).
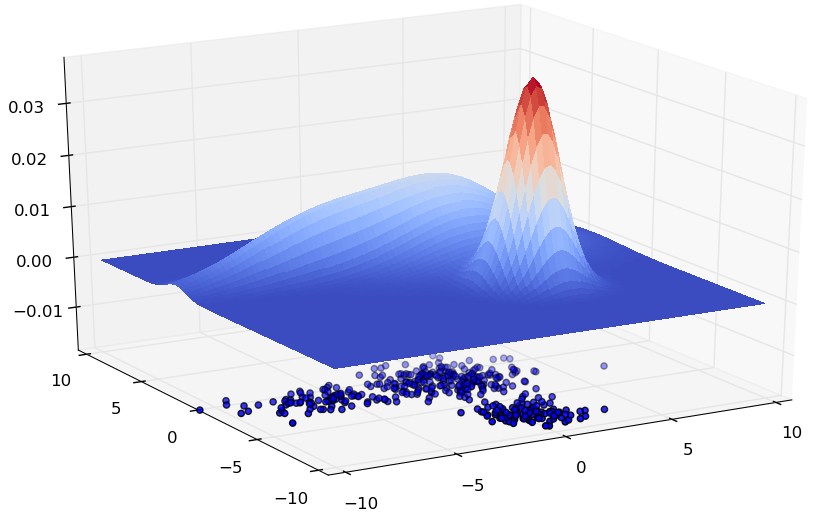
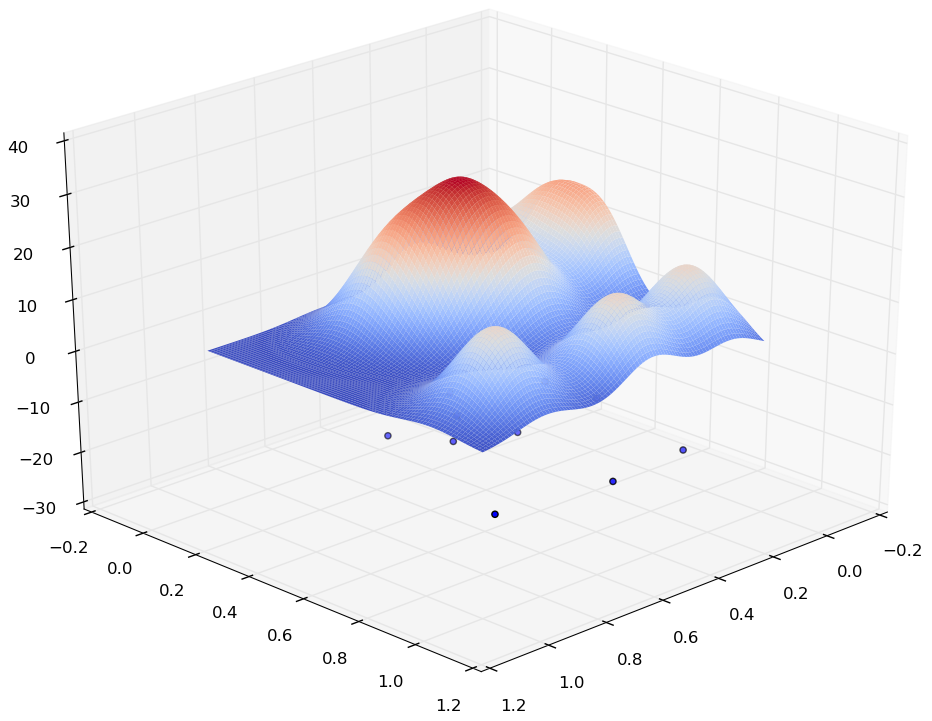
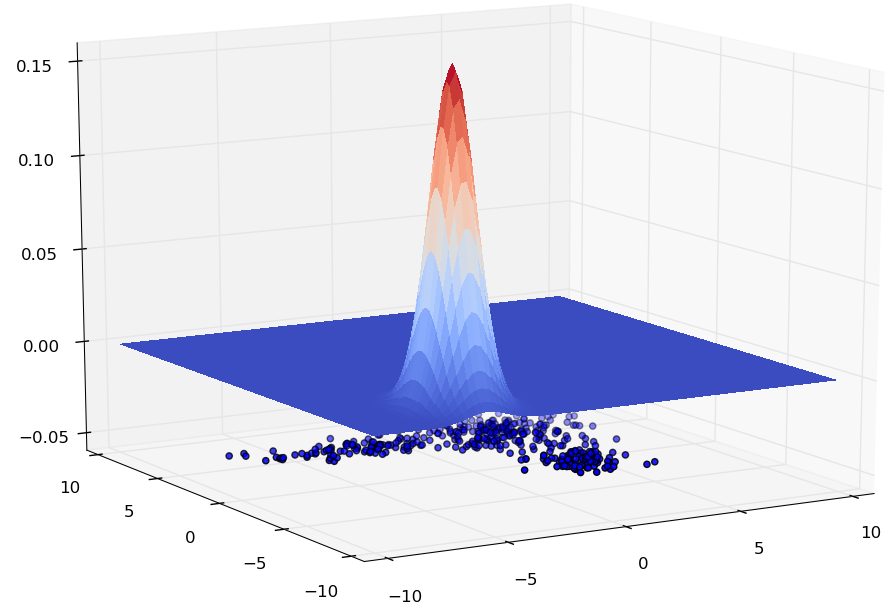
La figure suivante montre un exemple dans lequel les observations (représentées par les points bleus dans le plan horizontal) sont issues de \(\mathbb{R}^2\) et la densité qui a généré ces points est la surface courbe. Le sommet (en rouge) sur cette surface correspond à la région du plan horizontal où les observations (les points bleus) sont les plus denses.
Fig. 80 Exemple de données de \(\mathbb{R}^2\) et de densité estimée¶
L’estimation de densité peut être faite par des méthodes non paramétriques ou des méthodes paramétriques. Les méthodes non paramétriques ne font pas d’hypothèses sur l’appartenance de la fonction de densité recherchée \(f\) à une famille paramétrique (comme par ex. les lois normales multidimensionnelles). Parmi les méthodes non paramétriques nous pouvons mentionner l’estimation par histogramme, l’estimation par noyaux et l’estimation par \(k_n\) plus proches voisins.
Les méthodes paramétriques font des hypothèses sur l’appartenance de la fonction de densité recherchée \(f\) à une famille paramétrique (comme par ex. les mélanges additifs de lois normales multidimensionnelles) et visent ensuite à estimer les paramètres de la meilleure candidate \(\hat{f}^*\) au sein de cette famille. Les paramètres retenus sont en général ceux pour lesquels la fonction \(\hat{f}^*\) « explique le mieux » les observations de \(\mathcal{D}_N\) (maximisation de la vraisemblance). Si des connaissances a priori sont disponibles concernant les paramètres de \(f\), il est envisageable de chercher plutôt les paramètres pour lesquels la probabilité a posteriori est maximale, comme nous le verrons plus loin.
Cette méthode consiste à obtenir une représentation graphique de type histogramme pour la répartition des observations de \(\mathcal{D}_N\) et à considérer cet histogramme comme une approximation de la fonction de densité recherchée \(f\).
Les opérations nécessaires sont :
Délimitation du domaine \(\mathcal{C} \subset \mathbb{R}^d\) couvert par les données de \(\mathcal{D}_N \subset \mathbb{R}^d\). En général, ce domaine est défini à travers \(d\) intervalles unidimensionnels, un pour chaque variable, et est donc un (hyper)rectangle.
Découpage de ce domaine \(\mathcal{C}\) en intervalles de même volume \(v\). Nous reviendrons sur le choix du nombre d’intervalles (ou de leur largeur).
La densité en tout point \(\mathbf{x} \in \mathbb{R}^d\) de l’intervalle \(i\) qui contient \(k_i\) observations de \(\mathcal{D}_N\) (avec \(\sum_i k_i = N\)) est estimée par \(\widehat{f}(\mathbf{x}) = \frac{k_i/N}{v}\). Pour rappel, \(N\) est le nombre d’observations de \(\mathcal{D}_N\). A l’extérieur du domaine \(\mathcal{C}\) la densité est considérée nulle.
Nous pouvons vérifier que cette estimation est elle-même une fonction de densité : en intégrant la densité sur la totalité des intervalles de \(\mathcal{C}\) et en tenant compte du fait que la densité est nulle à l’extérieur de \(\mathcal{C}\) nous obtenons la valeur 1.
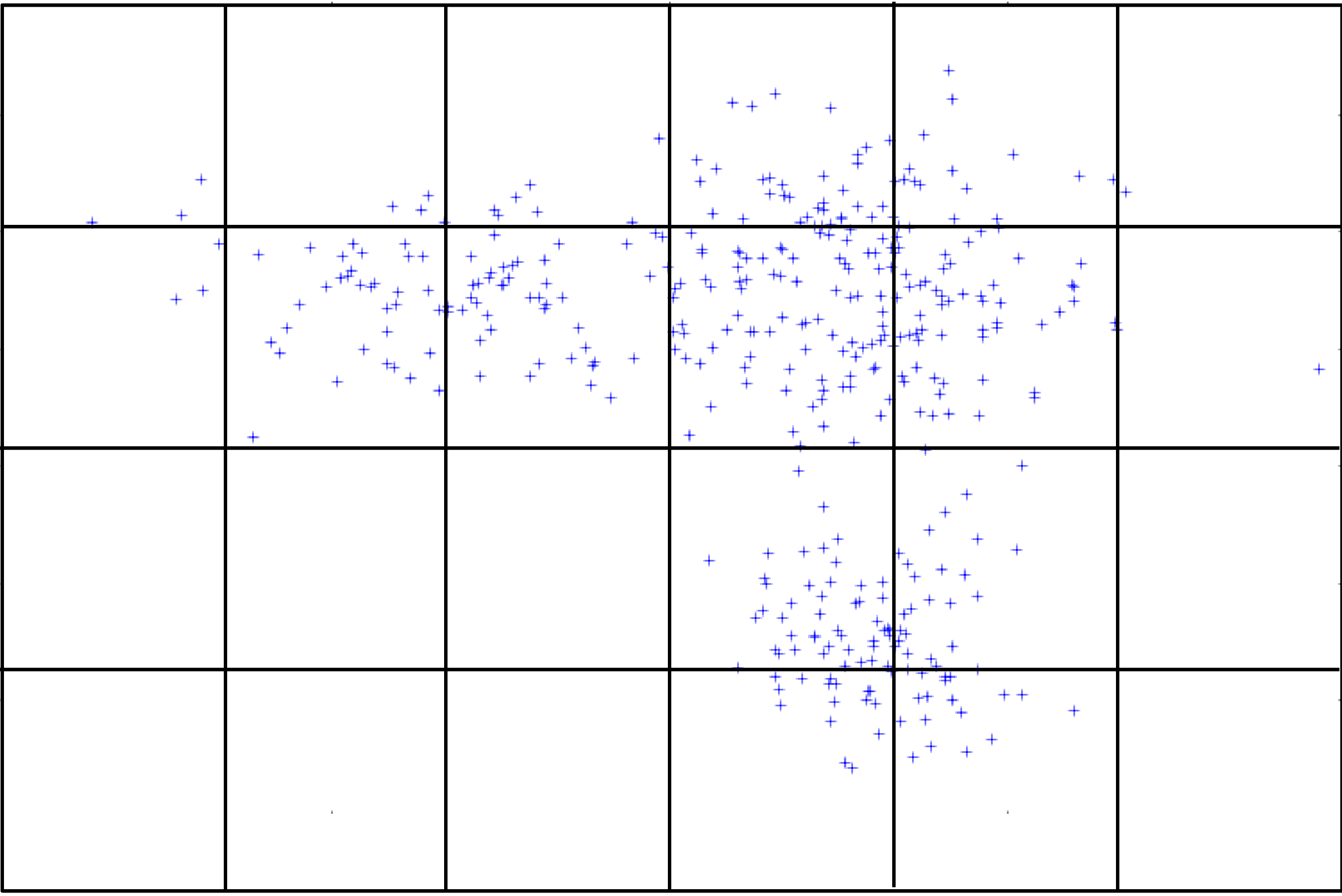
La figure suivante montre un ensemble d’observations de \(\mathcal{C} \subset \mathbb{R}^2\) et un découpage de ce domaine en intervalles carrés.
Fig. 81 Exemple de découpage d’un domaine bidimensionnel \(\mathcal{C}\) en intervalles 2D¶
Pour des données unidimensionnelles, un histogramme est facile à représenter, voir par ex. la figure Fig. 82. Pour des données bidimensionnelles une représentation par des colonnes en 3D est moins lisible car certaines colonnes cachent d’autres.
Afin de comprendre les caractéristiques de cette méthode d’estimation de densités, il est nécessaire de s’intéresser aux aspects suivants :
Comment varie l’estimation lors d’un décalage spatial du domaine \(\mathcal{C}\) et, donc, de son découpage en intervalles.
Quelle est la relation entre la qualité d’estimation (la proximité entre l’estimation et la vraie valeur) et la résolution de l’estimation (la précision spatiale).
Comment varie l’estimation lorsqu’elle est réalisée à partir d’un autre échantillon \({\mathcal{D}'}_N\) de même effectif \(N\) et issu de la même distribution.
Le décalage spatial du domaine \(\mathcal{C}\) et, donc, de son découpage en intervalles a un effet significatif sur l’estimation. Par exemple, la densité peut être nettement sous-évaluée dans une zone dense si elle est centrée sur une jonction de la grille, donc partagée entre plusieurs intervalles voisins.
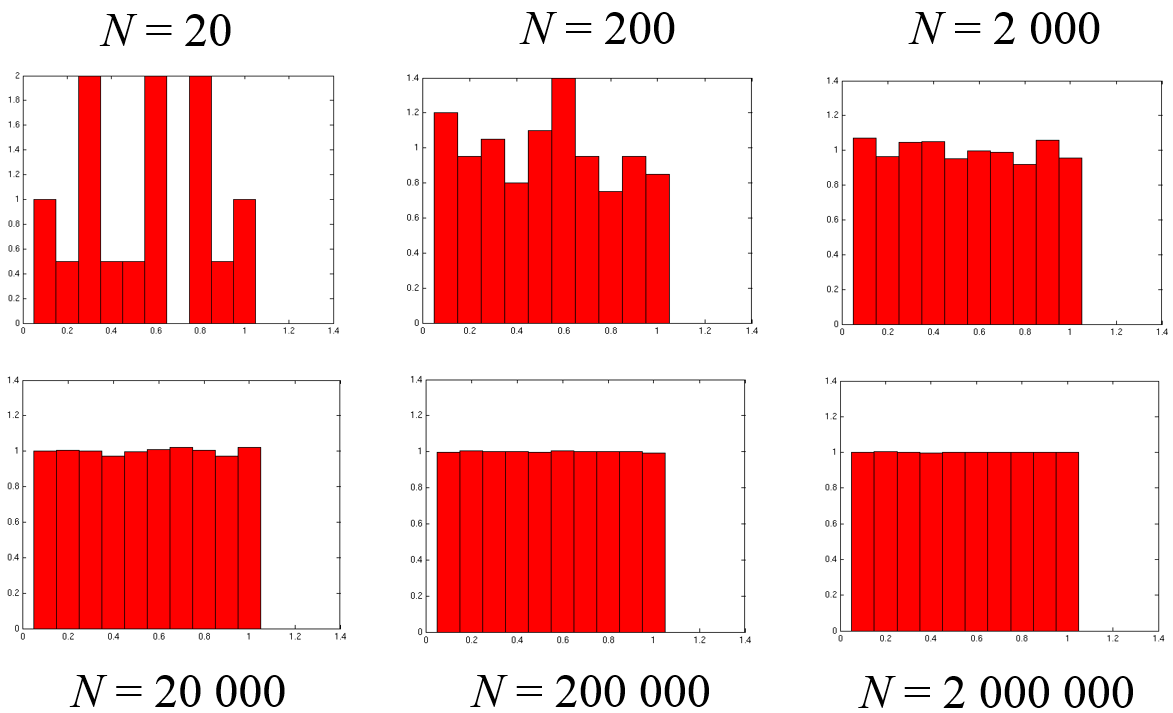
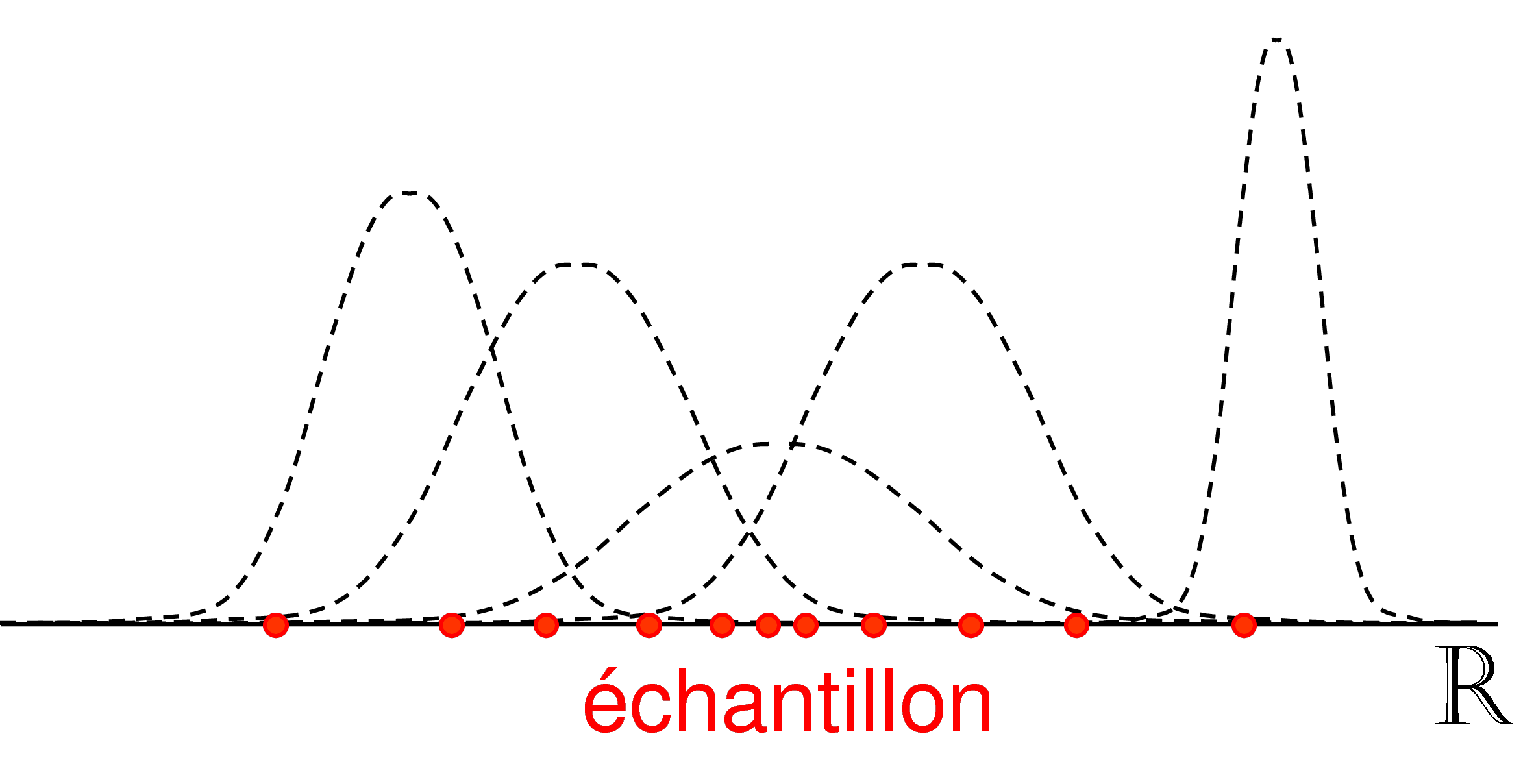
Pour étudier la relation entre la qualité d’estimation et la résolution de l’estimation, considérons un exemple unidimensionnel de données générées suivant une distribution uniforme dans l’intervalle \([0, 1]\). Considérons d’abord un découpage fixé et une taille de l’échantillon qui augmente. La figure suivante illustre cette situation.
Fig. 82 Nombre d’intervalles fixé, la taille de l’échantillon augmente¶
On constate dans ce cas une amélioration progressive de l’estimation (réduction de la variance) avec l’augmentation de la taille de l’échantillon. L’histogramme ressemble de plus en plus à la représentation d’une distribution uniforme.
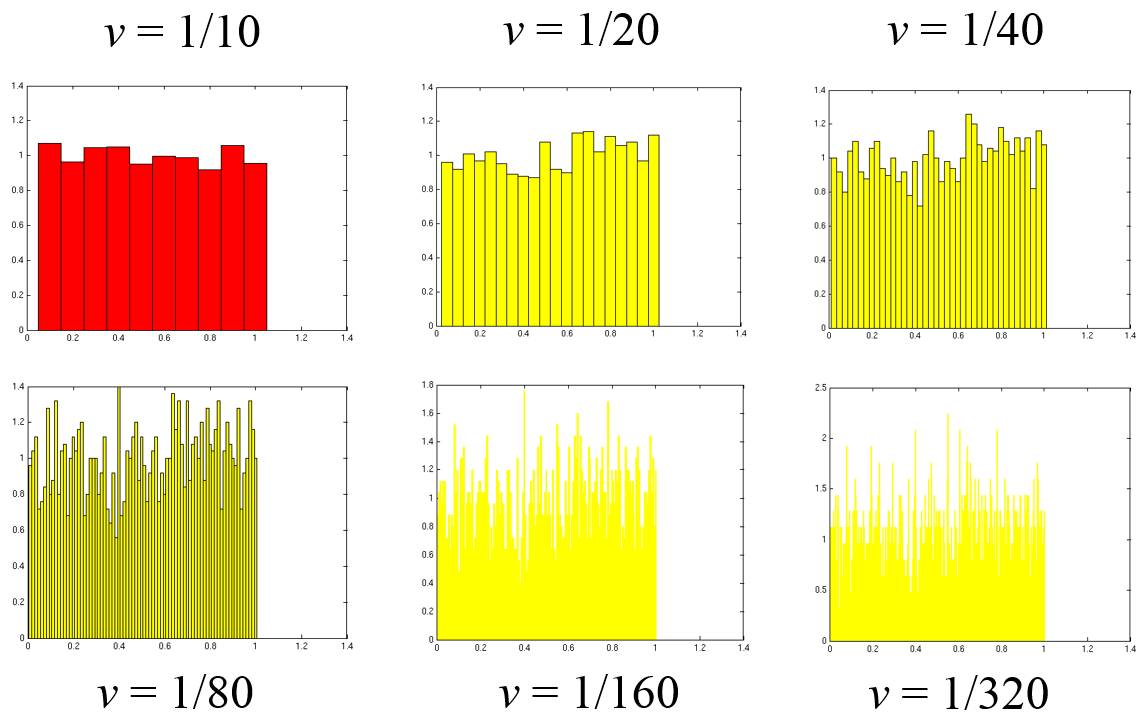
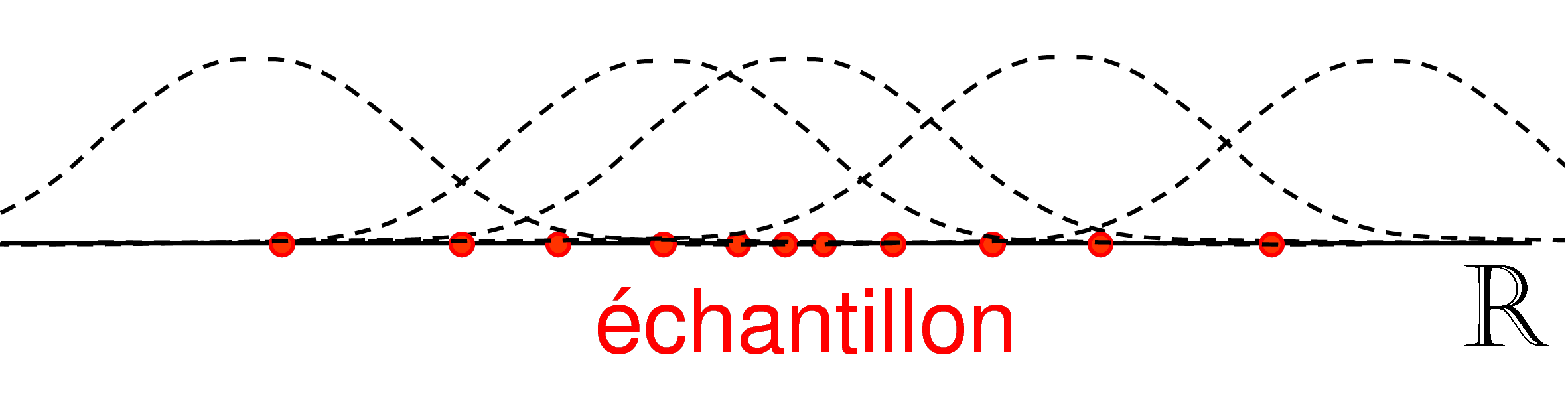
Considérons maintenant une taille d’échantillon fixe (\(N = 2000\)) et un nombre d’intervalles qui augmente, cas illustré dans la figure suivante.
Fig. 83 Échantillon fixé, le nombre d’intervalles augmente¶
Dans ce cas, la résolution spatiale s’améliore avec l’augmentation du nombre d’intervalles mais l’estimation se détériore (la variance augmente). L’histogramme ressemble de moins en moins à la représentation d’une distribution uniforme.
Enfin, la figure suivante montre un autre échantillon \({\mathcal{D}'}_N\) de même effectif \(N\) et issu de la même distribution. L’estimation varie de façon significative dans les intervalles où le nombre d’observations est relativement faible.
Fig. 84 Un autre échantillon issu de la même fonction de densité \(f\) produira des estimations par histogramme différentes¶
Pour résumer, les constats sont les suivants :
L’estimation de la densité varie de façon significative lors d’un décalage spatial du domaine \(\mathcal{C}\) et donc de son découpage en intervalles. Par ailleurs, en deux points \(\mathbf{x}\) et \(\mathbf{y}\) très proches entre eux mais appartenant à des intervalles différents (points choisis d’un côté et de l’autre de la frontière entre ces intervalles) l’estimation obtenue pour la densité peut être significativement différente.
Avec un nombre d’intervalles fixé (un volume \(v\) fixé par intervalle), la qualité d’estimation s’améliore avec l’augmentation de l’effectif \(N\) mais représente une moyenne sur un volume \(v\) assez large. Avec une taille \(N\) d’échantillon fixée, la résolution s’améliore avec la l’augmentation du nombre d’intervalles (la diminution de \(v\)) mais la qualité d’estimation se dégrade fortement.
La variance peut être élevée par rapport à l’échantillon ; des estimations différentes sont obtenues à partir de deux échantillons de même effectif issus de la même distribution.
Il est utile de faire en sorte que l’estimation de densité dépende essentiellement de l’échantillon\(\mathcal{D}_N\) et non de choix arbitraires comme la délimitation exacte du domaine \(\mathcal{C}\) ou son découpage en intervalles. Aussi, un lissage des estimations dans des régions voisines a pour effet une réduction de la variance des estimations par rapport à l’échantillon.
La méthode d’estimation par noyaux, initiée par Rosenblatt en 1956 et développée par Parzen en 1962, met en œuvre ces deux idées. Elle consiste à
Choisir une fonction noyau\(\Phi\) et un paramètre de lissage \(h\) (appelé aussi « fenêtre ») ;
Centrer un noyau \(\Phi_h\) sur chaque observation \(\mathbf{x}_i \in \mathcal{D}_N\) ;
La densité en un point \(\mathbf{x} \in \mathbb{R}^d\) est alors estimée par
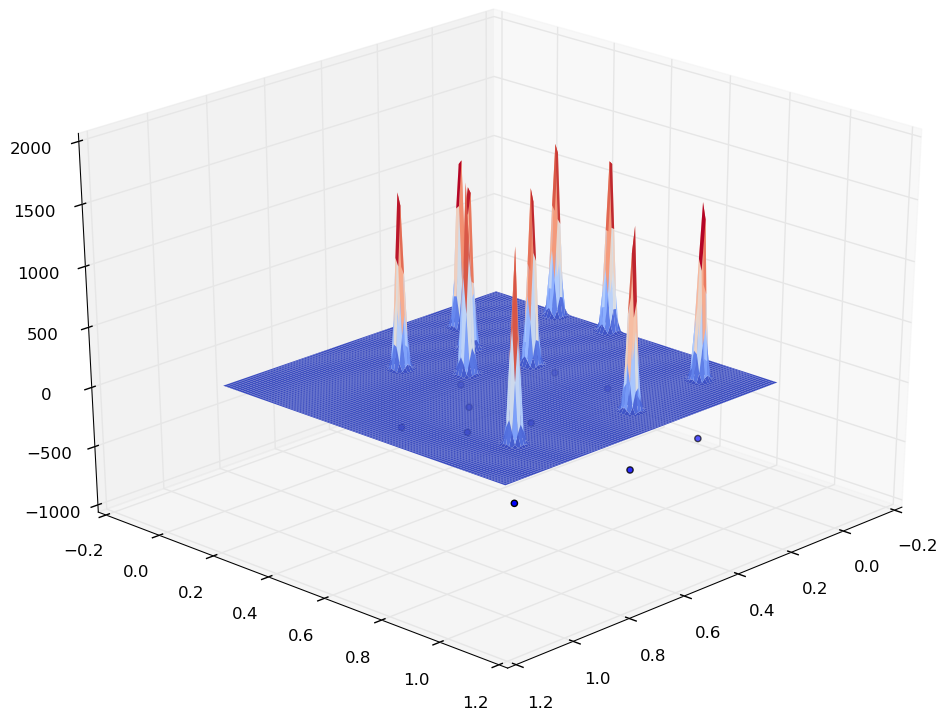
La figure suivante montre un exemple simple dans lequel les quelques observations (représentées par les points bleus dans le plan horizontal) sont issues de \(\mathbb{R}^2\). La fonction noyau employée est la loi normale et le paramètre de lissage est suffisamment faible pour que les noyaux individuels soient en général séparés dans la densité représentée par la surface courbe.
Fig. 85 Illustration d’une estimation de densité par noyaux¶
En général, les noyaux employés \(\Phi_h : \mathbb{R}^d \times \mathbb{R}^d \rightarrow \mathbb{R}^+\) sont obtenus à partir de noyaux unidimensionnels \(\phi : \mathbb{R} \rightarrow \mathbb{R}^+\) par \(\Phi_h(\mathbf{x},\mathbf{y}) = \frac{1}{h} \ \phi\left(\frac{\|\mathbf{x} - \mathbf{y}\|}{h}\right)\), où \(\|\cdot\|\) est la norme de la différence des deux vecteurs arguments de la fonction \(\Phi_h\).
Pour que l’estimation ainsi obtenue soit elle même une fonction de densité, il suffit de choisir comme fonction noyau une fonction densité de probabilité :
Les valeurs sont toutes positives (non strictement), \(\phi(u) \geq 0, \forall u \in \mathbb{R}\) ;
La condition de normalisation est respectée, \(\int_{\mathbb{R}} \phi(u) d u = 1\).
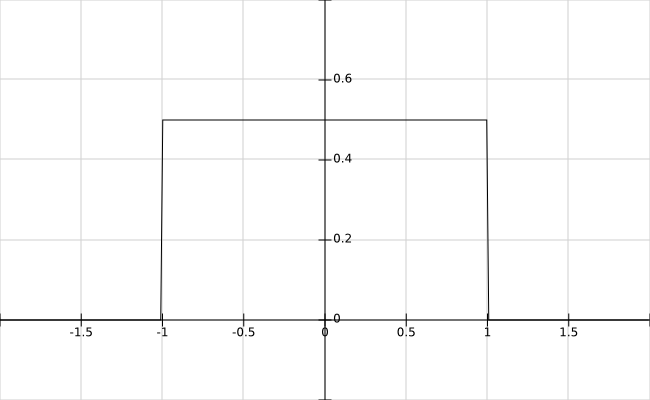
Les figures suivantes montrent trois exemples de fonctions noyaux qui satisfont ces conditions :
Fig. 86 Noyau uniforme \(\phi(u) = \frac{1}{2} \mathbf{1}_{|u| \leq 1}\) (introduit par Rosenblatt en 1956, n’apporte pas de lissage)¶
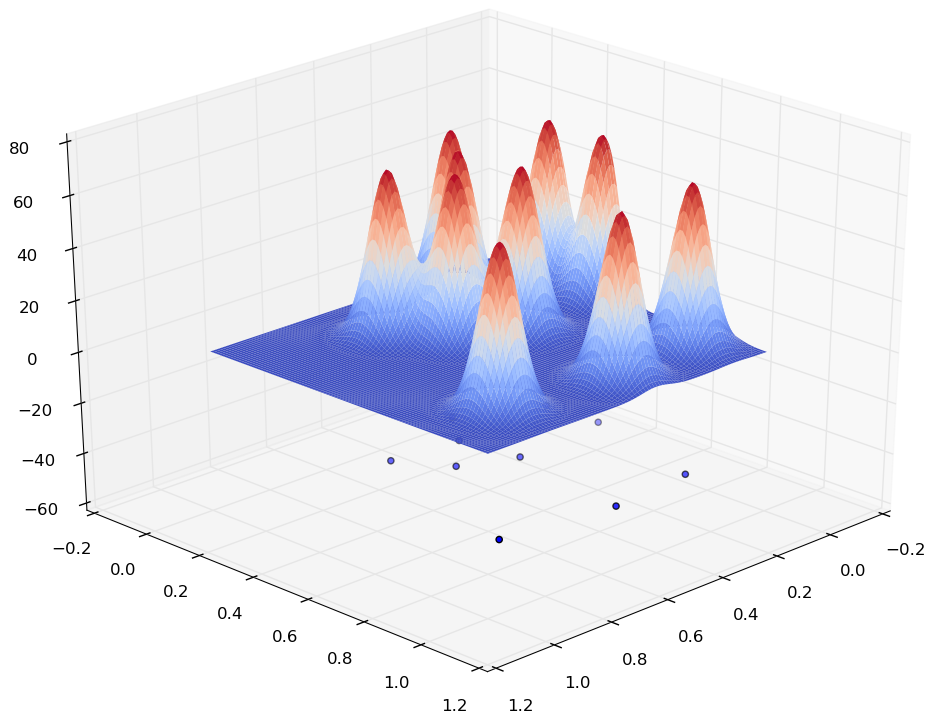
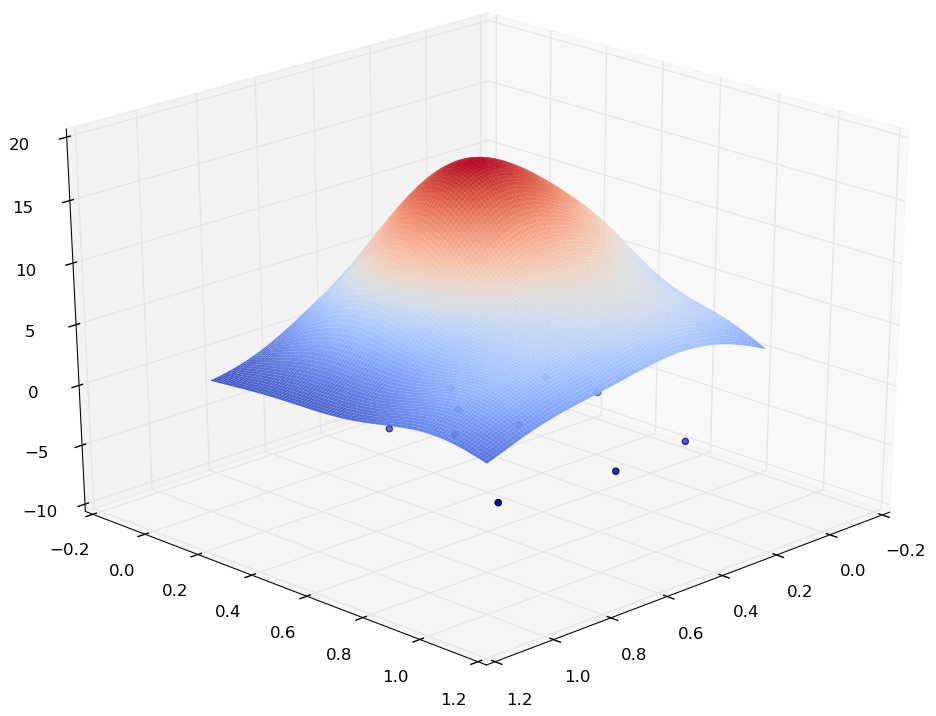
Si le choix de la fonction noyau a peu d’impact sur la qualité d’estimation (à condition que ce noyau soit lisse, comme par ex. le noyau gaussien ou le noyau logistique ci-dessus), la « largeur » \(h\) du noyau, appelée aussi paramètre de lissage, a un impact très significatif sur les résultats. Pour illustrer cela, considérons un échantillon \(\mathcal{D}_N \subset \mathbb{R}^2\) de 10 observations (que l’on peut voir aussi comme un détail spatial d’un échantillon plus grand et plus étalé) et examinons visuellement, à partir des quatre illustrations suivantes, l’estimation obtenue pour différentes valeurs du paramètre \(h\).
On peut constater qu’une valeur trop faible pour \(h\) produit des résultats sans intérêt, la densité étant non nulle seulement à proximité immédiate des observations de \(\mathcal{D}_N\), alors qu’une valeur trop élevée produit un lissage excessif avec perte des détails.
Le choix du paramètre \(h\) est donc critique pour obtenir des résultats satisfaisants. Nous présentons dans la suite une méthode de choix de la valeur optimale de \(h\) qui est basée sur l’emploi de la validation croisée. Il n’est pas indispensable de suivre les détails de ce développement [1]. Par ailleurs, la validation croisée est largement employée pour la comparaison de modèles obtenus par apprentissage supervisé, voir par ex. cette présentation.
D’autres méthodes pour le choix de la valeur optimale de \(h\) emploient des estimations plug-in avec résolution d’équation de point fixe ou bootstrap avec lissage (voir par ex. [SJ91], [JMS96], [AVA06]).
Pour déterminer la valeur optimale de \(h\) il faut définir une mesure de l’écart entre la « vraie » densité (inconnue) \(f\) et son estimation \(\hat{f}_h\) obtenue par noyaux. L’écart quadratique moyen, \(\int \left(\hat{f}_h(\mathbf{x}) - f(\mathbf{x})\right)^2 d\mathbf{x}\), est une mesure efficace mais qui dépend non seulement de \(h\) mais aussi de l’échantillon \(\mathcal{D}_N\) (issu de la densité inconnue \(f\)) car \(\hat{f}_h\) est obtenue sur cet échantillon. Considérer plutôt l’espérance de l’écart quadratique moyen par rapport au choix de l’échantillon de taille \(N\) doit permettre, en principe, de se défaire de cette dépendance. Cette espérance est appelée écart quadratique moyen intégré (EQMI, ou mean integrated squared error, MISE) :
La valeur optimale de \(h\) est celle qui permet de minimiser l’EQMI. Observons que cette valeur dépend de \(N\) : plus le nombre d’observations de \(\mathcal{D}_N\) est élevé, plus on peut réduire \(h\) pour affiner localement l’estimation sans risquer de perdre la régularité qu’apporte le lissage. Le paramètre \(h\) devrait donc être indicé par \(N\) : \(h_N\). Pour faciliter la lecture, dans la suite nous avons omis cet indice.
En développant l’expression sous l’intégrale dans (25), tenant compte du fait que l’espérance est un opérateur linéaire, nous pouvons écrire :
Pour le dernier terme nous avons \(\mathbb{E}_\mathcal{D} \left[\int f(\mathbf{x})^2 d\mathbf{x}\right] = \int f(\mathbf{x})^2 d\mathbf{x}\) qui ne dépend pas de \(h\) (\(f\) est la vraie densité), ce dernier terme peut donc être exclu de la minimisation de l’EQMI pour déterminer \(h\).
Les deux autres termes ne peuvent pas être calculés car \(f\) est la densité inconnue, il faut donc les estimer.
Pour le premier terme, \(\mathbb{E}_\mathcal{D} \left[\int \hat{f}^2_h(\mathbf{x}) d\mathbf{x}\right]\), une estimation sans biais est simplement \(\int \hat{f}^2_h(\mathbf{x}) d\mathbf{x}\). L’expression de \(\int \hat{f}^2_h(\mathbf{x}) d\mathbf{x}\) peut être trouvée analytiquement pour certains noyaux \(\phi\), comme par exemple le noyau gaussien.
Pour le deuxième terme, observons d’abord que \(\int \hat{f}_h(\mathbf{x}) f(\mathbf{x}) d\mathbf{x} = \mathbb{E}_X \left[\hat{f}_h(X)\right]\) où \(X\) désigne une variable aléatoire de densité \(f\). En conséquence, \(\mathbb{E}_\mathcal{D} \left[\int \hat{f}_h(\mathbf{x}) f(\mathbf{x}) d\mathbf{x}\right] = \mathbb{E}_\mathcal{D} \left[\mathbb{E}_X \left[\hat{f}_h(X)\right]\right]\).
Introduisons \(\hat{f}_{h, -i}\) l’estimation de \(f\) obtenue en excluant l’observation \(\mathbf{x}_i\) de \(\mathcal{D}_N\) :
On peut montrer que \(\frac{1}{N} \sum_{i=1}^N \hat{f}_{h, -i}(\mathbf{x}_i)\) est une estimation sans biais de \(\mathbb{E}_\mathcal{D} \left[\mathbb{E}_X \left[\hat{f}_h(X)\right]\right]\), second terme de l’EQMI développé.
La valeur optimale de la constante de lissage (ou largeur de fenêtre) est alors :
Ici, l’expression \(\int \hat{f}^2_h(\mathbf{x}) d\mathbf{x} - \frac{2}{N} \sum_{i=1}^N \hat{f}_{h, -i}(\mathbf{x}_i)\) est l’estimation par validation croisée leave one out (LOO) de l’EQMI (25).
Avec la méthode des noyaux, la densité inconnue \(f\) est estimée par une moyenne non pondérée de noyaux (issus en général de fonctions de densité comme la loi normale). Chaque observation de \(\mathcal{D}_N\) produit une composante dans ce mélange additif (24). Lorsque la valeur de \(N\) est très élevée, cette solution devient très coûteuse car pour estimer la densité en un point il est nécessaire de faire \(N\) calculs de noyau. Le coût peut être réduit en tenant compte du fait que la valeur de \(\Phi_h(\mathbf{x},\mathbf{y})\) devient négligeable pour une distance suffisamment élevée entre \(\mathbf{x}\) et \(\mathbf{y}\) (qui dépend du noyau employé). Cela permet d’employer des index multidimensionnels ou métriques afin de trouver rapidement, pour une donnée \(\mathbf{x}\), les \(\mathbf{x}_i \in \mathcal{D}_N\) avec lesquels il est nécessaire de calculer \(\Phi_h(\mathbf{x},\mathbf{x}_i)\) (le résultat sera 0 avec les autres observations de \(\mathcal{D}_N\)). Un outil comme Scikit-learn propose pour cela le KD-tree ou le Ball tree. Il faut noter que de tels index ne sont efficaces dans la réduction des calculs que pour des données de dimension relativement faible, \(\mathbf{x} \in \mathbb{R}^d\) avec \(d < 10\).
Lorsque des connaissances a priori concernant les données nous indiquent que de bons candidats \(\hat{f}\) pour estimer la densité inconnue \(f\) peuvent être trouvés dans une famille paramétrique \(\mathcal{F}\) particulière (par ex. les lois normales multidimensionnelles), il est plus efficace de chercher directement la solution optimale \(\hat{f}^*\) dans cette famille, c’est à dire d’estimer les paramètres qui la définissent au sein de la famille. Si une loi élémentaire de la famille n’explique pas assez bien les données, il est possible alors d’envisager un mélange additif de plusieurs lois issues de cette même famille. Contrairement à la méthode des noyaux, ici le mélange contient un faible nombre de lois (\(m \ll N\)) mais ces lois peuvent avoir des paramètres différents ainsi que des pondérations différentes dans le mélange.
Le terme « efficace » est employé ci-dessus pour deux aspects bien distincts :
Une fois le modèle de mélange estimé, le calcul de la densité en un point \(\mathbf{x}\) est bien plus rapide car le mélange comporte \(m\) lois et non \(N\), avec \(m \ll N\).
Pour un même nombre \(N\) d’observations dans \(\mathcal{D}_N\), l’estimation paramétrique présente en général une meilleure précision (EQMI plus faible) que l’estimation non paramétrique par noyaux.
Si on considère une famille de fonctions de densité \(\mathcal{F}\) paramétrée par un vecteur \(\boldsymbol{\theta} \in \Omega\) (espace des paramètres), l’estimation paramétrique consiste donc à trouver le vecteur de paramètres optimal \(\hat{\boldsymbol{\theta}}^*\) qui définit la meilleure estimation \(f_{\hat{\boldsymbol{\theta}}^*}\) de la densité recherchée.
Comment trouver ce vecteur de paramètres à partir de \(\mathcal{D}_N\) ? Chaque vecteur \(\boldsymbol{\theta}\) définit une densité \(f_{\boldsymbol{\theta}}\) qui explique plus ou moins bien les observations de \(\mathcal{D}_N\). Considérons l’exemple illustré dans les deux figures suivantes, où les observations de \(\mathcal{D}_N \subset \mathbb{R}^2\) sont représentées par les points bleus dans le plan horizontal.
Dans la première figure, la densité représentée par la surface courbe prend des valeurs plus élevées là où les observations sont les plus denses. Dans la seconde figure, en revanche, la densité est élevée là où il n’y a pas d’observations et nulle (ou négligeable) dans les régions où les observations sont denses. La première densité « explique » donc bien mieux les observations de \(\mathcal{D}_N\) que la seconde.
Pour mesurer l’adéquation de la densité \(f_{\boldsymbol{\theta}}\) (appartenant à la famille \(\mathcal{F}\) et définie par le vecteur de paramètres \(\boldsymbol{\theta}\)) aux observations de \(\mathcal{D}_N\) on emploie \(p(\mathcal{D}_N | \boldsymbol{\theta})\). Si les observations \(\mathbf{x}_1, \ldots, \mathbf{x}_N \in \mathcal{D}_N\) correspondent à des tirages indépendants et identiquement distribués (suivant la densité recherchée), alors
Comme fonction de \(\boldsymbol{\theta}\) (avec \(\mathbf{x}_1, \ldots, \mathbf{x}_N\) fixés), \(p(\mathcal{D}_N | \boldsymbol{\theta})\) est la vraisemblance (likelihood) de \(\boldsymbol{\theta}\) par rapport à l’échantillon \(\mathcal{D}_N\).
Le vecteur de paramètres \(\hat{\boldsymbol{\theta}}^*\) qui définit la fonction de densité \(f_{\hat{\boldsymbol{\theta}}^*}\) la plus en accord avec les observations de \(\mathcal{D}_N\) est celui qui maximise la vraisemblance(26). Afin de le trouver il est nécessaire de faire appel à une procédure d’optimisation.
Lorsque les fonctions de densité sont définies avec une exponentielle on préfère en général travailler avec le logarithme de la vraisemblance (log-likelihood) :
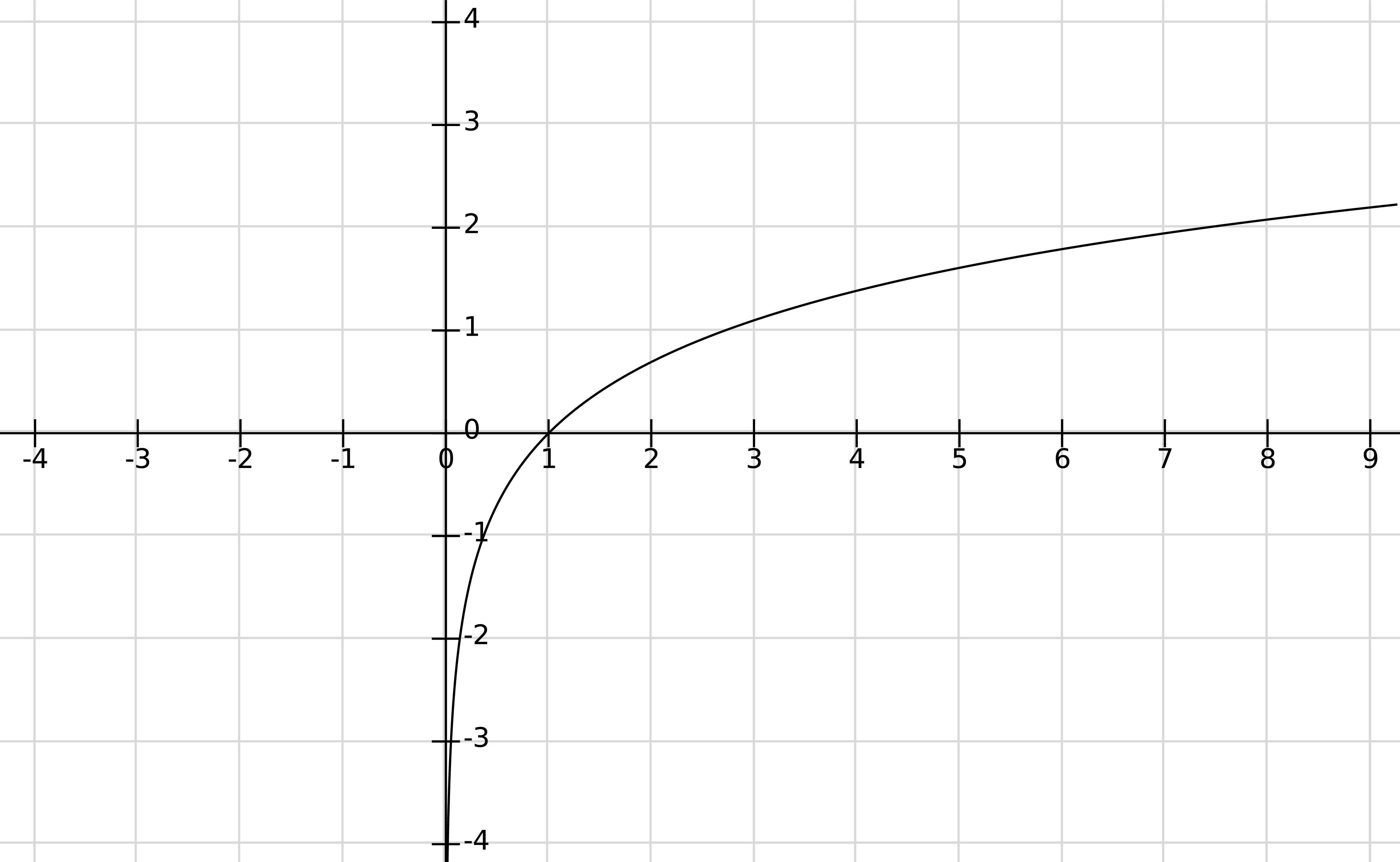
Pour ces fonctions de densité, l’application du logarithme permet une manipulation plus facile, comme nous le verrons dans la section suivante. Le logarithme en base \(> 1\) étant une fonction strictement croissante, l’argument \(\hat{\boldsymbol{\theta}}^*\) qui maximise la vraisemblance maximise aussi le logarithme de la vraisemblance (la log-vraisemblance) et réciproquement.
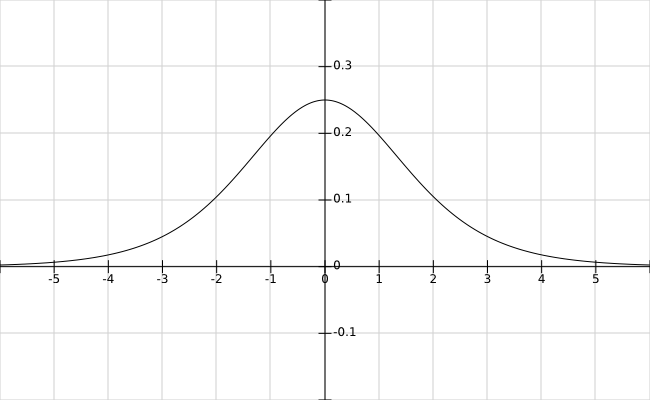
Fig. 95 Le logarithme en base \(> 1\) est une fonction strictement croissante¶
Un cas très simple est celui où les observations sont unidimensionnelles (\(d=1\)), \(\mathcal{D}_N \subset \mathbb{R}\), et ont été générées suivant une fonction de densité \(f\) qui fait partie de la famille des lois normales (unidimensionnelles), \(f \in \mathcal{F} = \mathcal{N}(\mu,\sigma)\). Une telle fonction de densité est définie par l’espérance \(\mu\) et l’écart-type \(\sigma\), donc le vecteur de paramètres est \(\boldsymbol{\theta} = \left[\begin{array}{c}\mu\\ \sigma\end{array}\right]\). Nous cherchons à estimer cette fonction de densité par \(\hat{f} \in \mathcal{F} = \mathcal{N}(\mu,\sigma)\), de paramètres \(\hat{\boldsymbol{\theta}} = \left[\begin{array}{c}\hat{\mu}\\ \hat{\sigma}\end{array}\right]\).
La figure suivante montre un ensemble de 11 observations unidimensionnelles (représentées par les points rouges) et différentes lois normales candidates pour expliquer cet échantillon.
Fig. 96 Quelques densités candidates pour expliquer l’échantillon¶
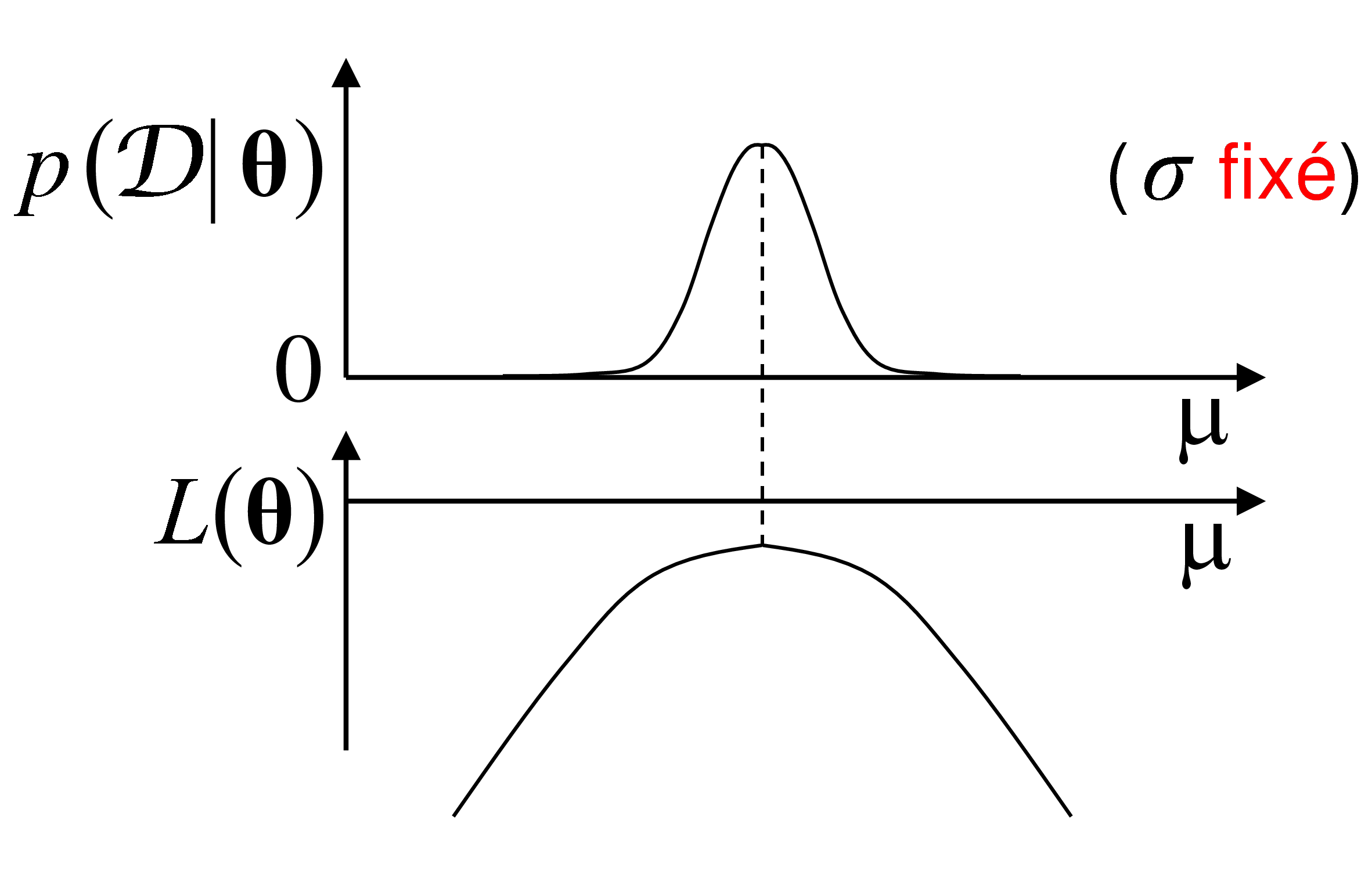
Pour mieux visualiser la variation de la vraisemblance nous pouvons fixer un des paramètres (l’écart-type \(\sigma\)) et faire varier l’autre (l’espérance, \(\mu\)) seulement (la position du centre de la « cloche ») :
Fig. 97 Quelques densités candidates avec \(\sigma\) fixé¶
La figure suivante montre la variation de la vraisemblance \(p(\mathcal{D}_N|\boldsymbol{\theta})\) et de la log-vraisemblance \(L(\boldsymbol{\theta})\) en fonction de l’espérance \(\mu\) (pour \(\sigma\) fixé) :
Fig. 98 Variation de la vraisemblance et de la log-vraisemblance pour \(\sigma\) fixé¶
Les valeurs maximales de la vraisemblance et de la log-vraisemblance sont atteintes pour la même valeur de l’espérance, \(\hat{\mu}^*\), qui est la plus en accord avec les observations de \(\mathcal{D}_N\).
Afin de trouver le vecteur de paramètres optimal \(\hat{\boldsymbol{\theta}}^* = \left[\begin{array}{c}\hat{\mu}^*\\ \hat{\sigma}^*\end{array}\right]\) il est nécessaire d’écrire l’expression de la (log-)vraisemblance et de déterminer son maximum. La loi normale (unidimensionnelle) de paramètre \(\boldsymbol{\theta}\) est
Comme fonction de \(\mu\) et respectivement \(\sigma\), pour \(\sigma > 0\), cette expression est indéfiniment dérivable par rapport aux deux variables. Nous obtenons les dérivées partielles premières suivantes :
qui est la variance empirique (biaisée) des observations.
En calculant les dérivées secondes dans \(\hat{\mu}^*\), \(\hat{\sigma}^*\) nous pouvons vérifier qu’elles sont négatives ; \(\hat{\boldsymbol{\theta}}^* = \left[\begin{array}{c}\hat{\mu}^*\\ \hat{\sigma}^*\end{array}\right]\) est donc bien l’argument qui maximise la log-vraisemblance \(\ln\left[p(\mathcal{D}_N | \boldsymbol{\theta})\right]\).
Deux observations s’imposent :
L’estimation \(\hat{\mu}^*\) est sans biais, c’est à dire son espérance sur les échantillons de taille \(N\) est égale à la vraie valeur de \(\mu\).
L’estimation \({\hat{\sigma}^*}^2\) est en revanche biaisée, bien qu’asymptotiquement sans biais : \(\lim_{N \rightarrow \infty} E\left({\hat{\sigma}^*}^2\right)\) est la vraie valeur de \(\sigma\). L’estimation sans biais suivante lui est préférée :
Estimation par une loi normale multidimensionnelle¶
Considérons maintenant le cas d’observations multidimensionnelles, \(\mathcal{D}_N \subset \mathbb{R}^d\) (\(d > 1\)), générées suivant une loi normale multidimensionnelle \(f \in \mathcal{F} = \mathcal{N}(\mathbf{\mu},\Sigma)\). Dans ce cas, le vecteur de paramètres \(\boldsymbol{\theta}\) regroupe à la fois les composantes de l’espérance multidimensionnelle \(\boldsymbol{\mu}\) et de la matrice de variance-covariance \(\boldsymbol{\Sigma}\). Nous cherchons à estimer cette fonction de densité par \(\hat{f} \in \mathcal{F}\), de paramètres \(\hat{\boldsymbol{\theta}} = \left[\begin{array}{c}\hat{\boldsymbol{\mu}}\\ \hat{\boldsymbol{\Sigma}}\end{array}\right]\).
La loi normale multidimensionnelle de paramètres \(\hat{\boldsymbol{\theta}}\) est :
Si notre connaissance du problème d’estimation de densité se réduit aux observations de \(\mathcal{D}_N\) et à l’adéquation de la famile paramétrique \(\mathcal{F}\), la solution du maximum de vraisemblance s’impose.
Et si nous disposons de connaissances supplémentaires nous incitant à privilégier certaines fonctions (c’est à dire certaines valeurs des paramètres) par rapport à d’autres ? Lorsque ces connaissances peuvent être exprimées sous la forme d’une fonction de densité a priori sur l’espace des paramètres \(\boldsymbol{\theta}\), le théorème de Bayes nous permet de déterminer la densité de probabilité a posteriori :
Ici, \(p(\boldsymbol{\theta})\) est la densité a priori (les paramètres correspondant à des valeurs élevées de \(p(\boldsymbol{\theta})\) sont privilégiés) et \(p(\mathcal{D}_N | \boldsymbol{\theta})\) la vraisemblance. Les trois composantes de (28) étant des densités de probabilité, plutôt que l’égalité nous avons employé le signe de proportionnalité \(\propto\) et omis la constante de normalisation.
La densité a posteriori, \(p(\boldsymbol{\theta} | \mathcal{D}_N)\), tient ainsi compte à la fois des observations (à travers la vraisemblance) et des connaissances supplémentaires (à travers l”a priori). La solution optimale est alors celle qui maximise la densité a posteriori (solution du maximum a posteriori).
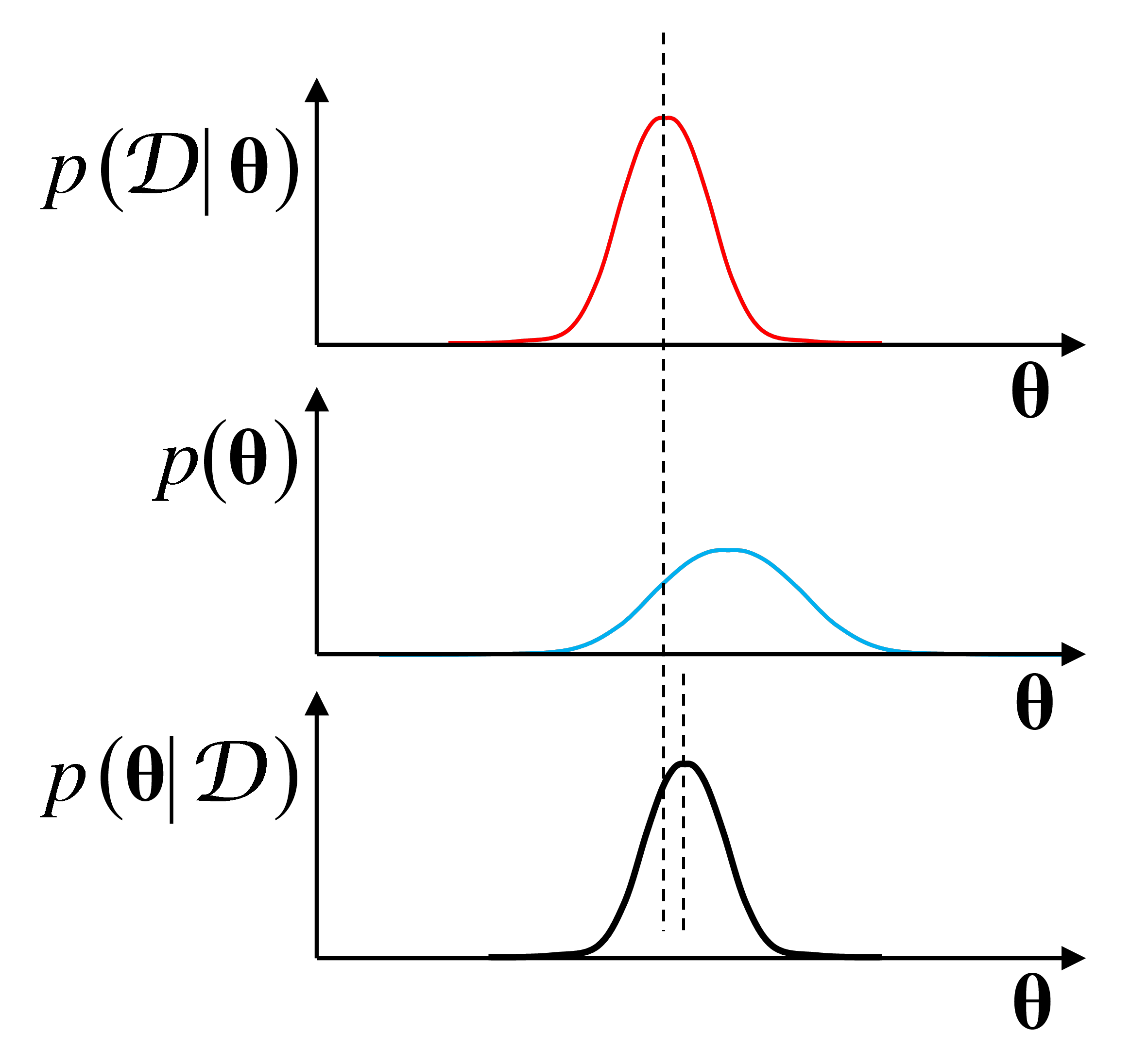
L’illustration suivante montre, pour un cas simplifié caractérisé par un paramètre \(\boldsymbol{\theta}\) unidimensionnel (par ex., pour l’estimation d’une loi normale unidimensionnelle, paramètre \(\mu\) avec \(\sigma\) fixé), les deux contributions dans le calcul de l”a posteriori. Sans connaissances a priori, le paramètre optimal correspondrait au maximum de la vraisemblance (en haut, en rouge). La densité a priori illustrée (au milieu, en bleu) privilégie des valeurs supérieures du paramètre. En conséquence, le paramètre optimal qui maximise l”a posteriori (en bas, en noir) peut être vu ici comme un compromis entre le choix qui serait fait sur la seule base des observations (maximum de la vraisemblance) et celui qui serait fait sur la seule base de l”a priori (maximum de la densité a priori).
Examinons maintenant le cas où une seule loi (fonction de densité) de la famille \(\mathcal{F}\) n’explique pas assez bien les données et il est nécessaire d’employer un mélange additif de plusieurs lois issues de cette même famille. Contrairement à la méthode des noyaux, ce mélange contient un faible nombre de lois (\(m \ll N\)) et ces lois ont des paramètres différents, ainsi que des pondérations différentes dans le mélange.
Nous chercherons donc des densités de la forme suivante :
\(m\) est le nombre de composantes (lois individuelles) du mélange, \(m \ll N\),
\(f_j(\mathbf{x} | \boldsymbol{\theta}_j)\) est la densité (loi de la famille \(\mathcal{F}\)) qui définit la composante \(j\) et est paramétrée par \(\boldsymbol{\theta}_j\),
\(\alpha_j\) sont les coefficients de mélange, qui doivent satisfaire la condition de normalisation \(\sum_{j=1}^m \alpha_j = 1\) pour que \(f_{\boldsymbol{\alpha}, \boldsymbol{\theta}}\) soit une fonction de densité,
\(\boldsymbol{\alpha}\) est la représentation vectorielle des \(m\) coefficients de mélange (ou pondérations des composantes),
\(\boldsymbol{\theta}\) est le vecteur qui regroupe tous les vecteurs de paramètres \(\boldsymbol{\theta}_j\) des \(m\) composantes.
L’illustration suivante montre un exemple d’ensemble \(\mathcal{D}_N\) d’observations bidimensionnelles et l’estimation obtenue pour leur densité avec un mélange additif de 3 lois normales bidimensionnelles. Deux des lois (celles qui composent la « colline allongée ») ont des variances plus grandes et des coefficients de mélange plus faibles, la troisième (représentée par la « colline abrupte » avec un sommet rouge) a des variances plus faibles et un coefficient de mélange plus élevé.
La densité sous forme de mélange additif (29) la plus en accord avec les observations disponibles \(\mathcal{D}_N\) est celle qui maximise la vraisemblance \(p(\mathcal{D}_N | f_{\boldsymbol{\alpha}, \boldsymbol{\theta}})\). Sachant que cette densité est définie par le choix de la famille \(\mathcal{F}\) et des paramètres \((\boldsymbol{\alpha}, \boldsymbol{\theta})\), nous exprimerons la vraisemblance sous la forme \(p(\mathcal{D}_N | \boldsymbol{\alpha}, \boldsymbol{\theta})\) (le choix de \(\mathcal{F}\) est sous-entendu).
On cherche donc à déterminer les paramètres \((\hat{\boldsymbol{\alpha}}^*, \hat{\boldsymbol{\theta}}^*)\) qui maximisent la vraisemblance par rapport aux observations \(\mathbf{x}_1, \ldots, \mathbf{x}_N \in \mathcal{D}_N\). Lorsque ces observations sont issues de tirages indépendants et identiquement distribués (suivant la densité recherchée), la vraisemblance \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\) devient
En explicitant \(f_{\boldsymbol{\alpha}, \boldsymbol{\theta}}(\mathbf{x}_i)\) comme un mélange additif (29), on obtient l’expression suivante pour le logarithme de la vraisemblance à maximiser
sous la contrainte de normalisation \(\sum_{j=1}^m \alpha_j = 1\).
En raison de la présence d’une somme sous le logarithme dans (31), nous n’avons pas de solution analytique à ce problème de maximisation même lorsque les composantes \(f_j\) sont des lois normales. Il est alors nécessaire de faire appel à des méthodes d’optimisation itératives pour déterminer \((\hat{\boldsymbol{\alpha}}^*, \hat{\boldsymbol{\theta}}^*)\).
Une étude plus attentive du cas où les composantes \(f_j\) sont des lois normales multidimensionnelles permet de mieux comprendre le principe de l’algorithme itératif d’optimisation qui est examiné plus loin.
Pour un mélange additif dont les composantes \(f_j\) sont des lois normales multidimensionnelles (27), la vraisemblance \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\) devient
La présence de la somme sous le logarithme ne permet pas d’obtenir une solution analytique au problème de maximisation de la (log-)vraisemblance. Par ailleurs, l’expression (32) vue comme une fonction des paramètres \((\boldsymbol{\alpha}, \boldsymbol{\theta})\) présente de multiples maxima locaux, c’est à dire des valeurs supérieures à celles du voisinage immédiat mais pas nécessairement de tout le domaine de variation des paramètres.
En examinant l’expression (32) nous pouvons constater que, si chaque observation \(\mathbf{x}_i\) était générée par une seule composante, connue, alors seul le terme correspondant à cette composante resterait de la somme sous le logarithme. Dans ce cas, l’application du logarithme à une exponentielle permettrait d’extraire l’argument de l’exponentielle et cette simplification ouvrirait la voie à une solution analytique.
L’idée de l’algorithme itératif d’optimisation décrit dans la suite est issue de ce constat. Cela consiste à trouver, à chaque itération, une approximation locale \(l(\boldsymbol{\alpha}, \boldsymbol{\theta})\) de la vraisemblance \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\), qui minore \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\) et qui peut être maximisée analytiquement car d’expression plus simple que \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\). Ce processus est itéré jusqu’à la convergence. La solution obtenue in fine peut néanmoins correspondre à un maximum local de la (log-)vraisemblance.
L’algorithme itératif employé en général pour estimer les modèles de mélange est appelé Espérance-Maximisation (Expectation-Maximization, EM). Cet algorithme a été introduit dans [DLR77] et ses applications vont au-delà des modèles de mélange. Dans la suite nous en faisons d’abord une présentation informelle, ensuite une déduction rapide des formules de calcul (cette partie est optionnelle dans ce cours) et enfin nous proposons des illustrations de son application aux mélanges de lois normales.
L’algorithme EM démarre par une initialisation des paramètres de la densité à estimer. Ensuite des itérations de modification des paramètres se succèdent jusqu’à la convergence. Chaque itération consiste en une étape E (Espérance) suivie d’une étape M (Maximisation). Les 8 figures suivantes illustrent le déroulement de l’algorithme.
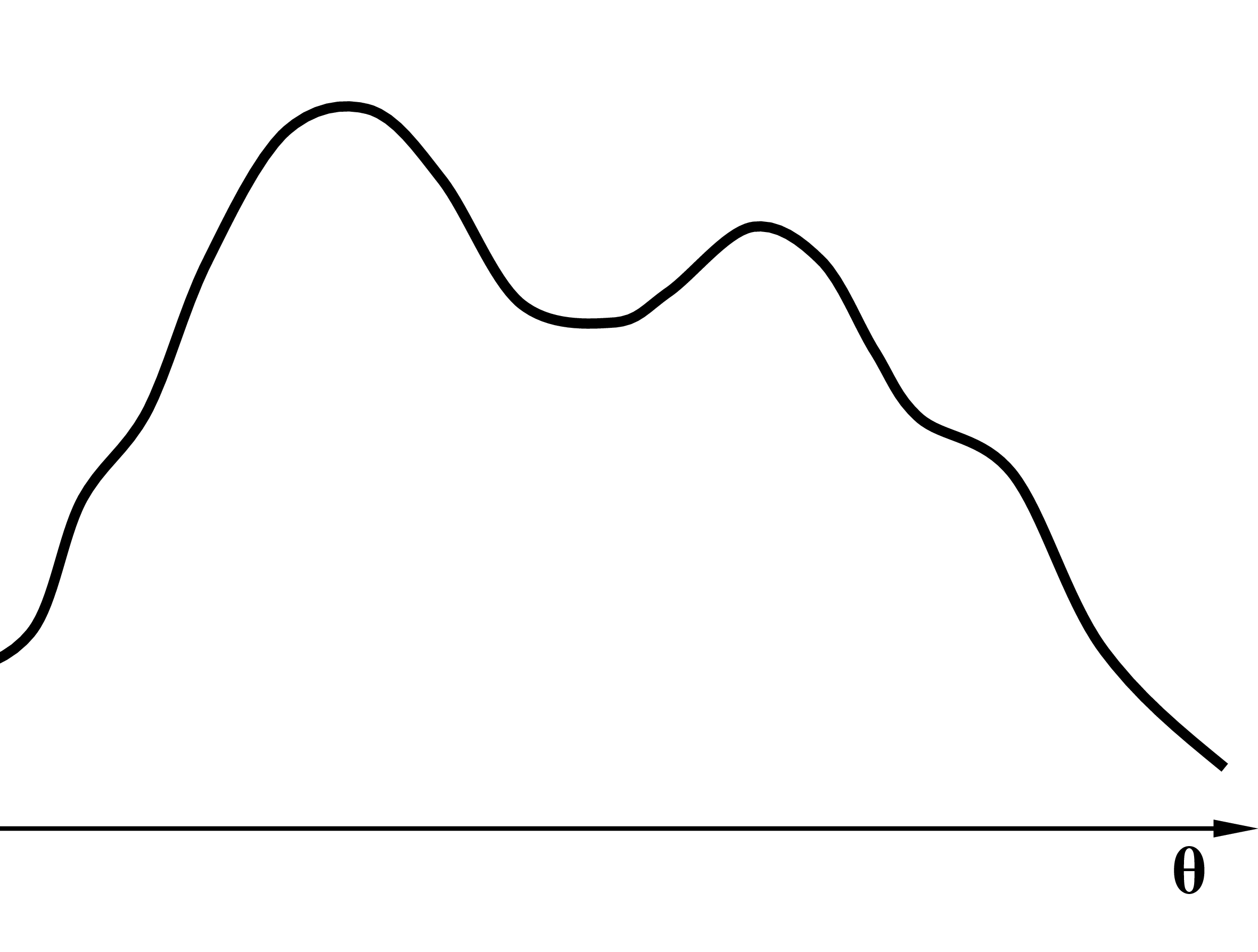
L’objectif de l’algorithme EM est de trouver le vecteur de paramètres \((\hat{\boldsymbol{\alpha}}^*, \hat{\boldsymbol{\theta}}^*)\) qui maximise la vraisemblance \(L(\boldsymbol{\alpha}, \boldsymbol{\theta})\) ou la log-vraisemblance \(\ln(L)\). Pour améliorer la lisibilité, dans les figures suivantes le vecteur de paramètres a été noté simplement par \(\boldsymbol{\theta}\) et représenté sur un seul axe (comme un scalaire). La (log-)vraisemblance à maximiser est illustrée par la courbe qui présente un maximum local (à droite) et un maximum global (à gauche).
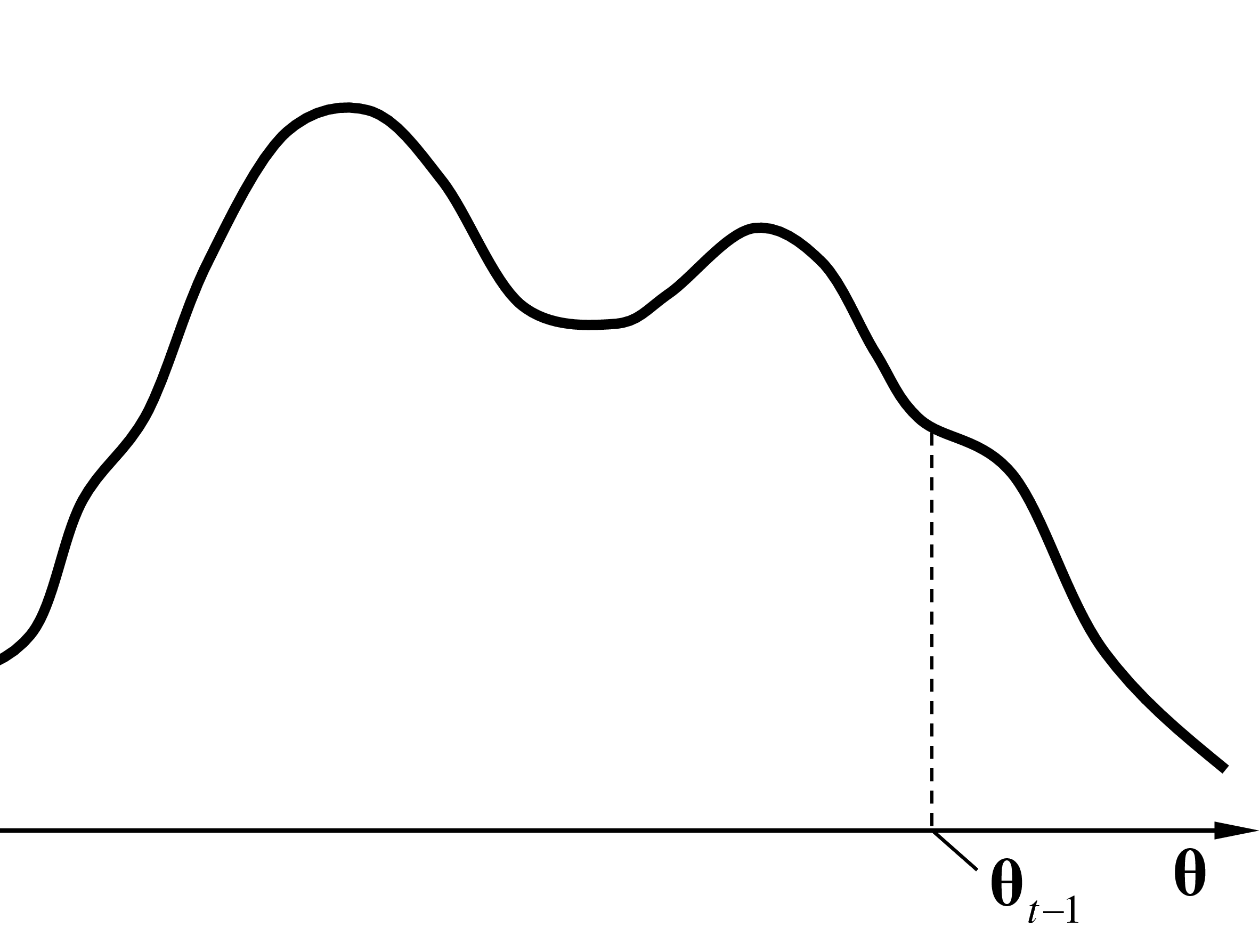
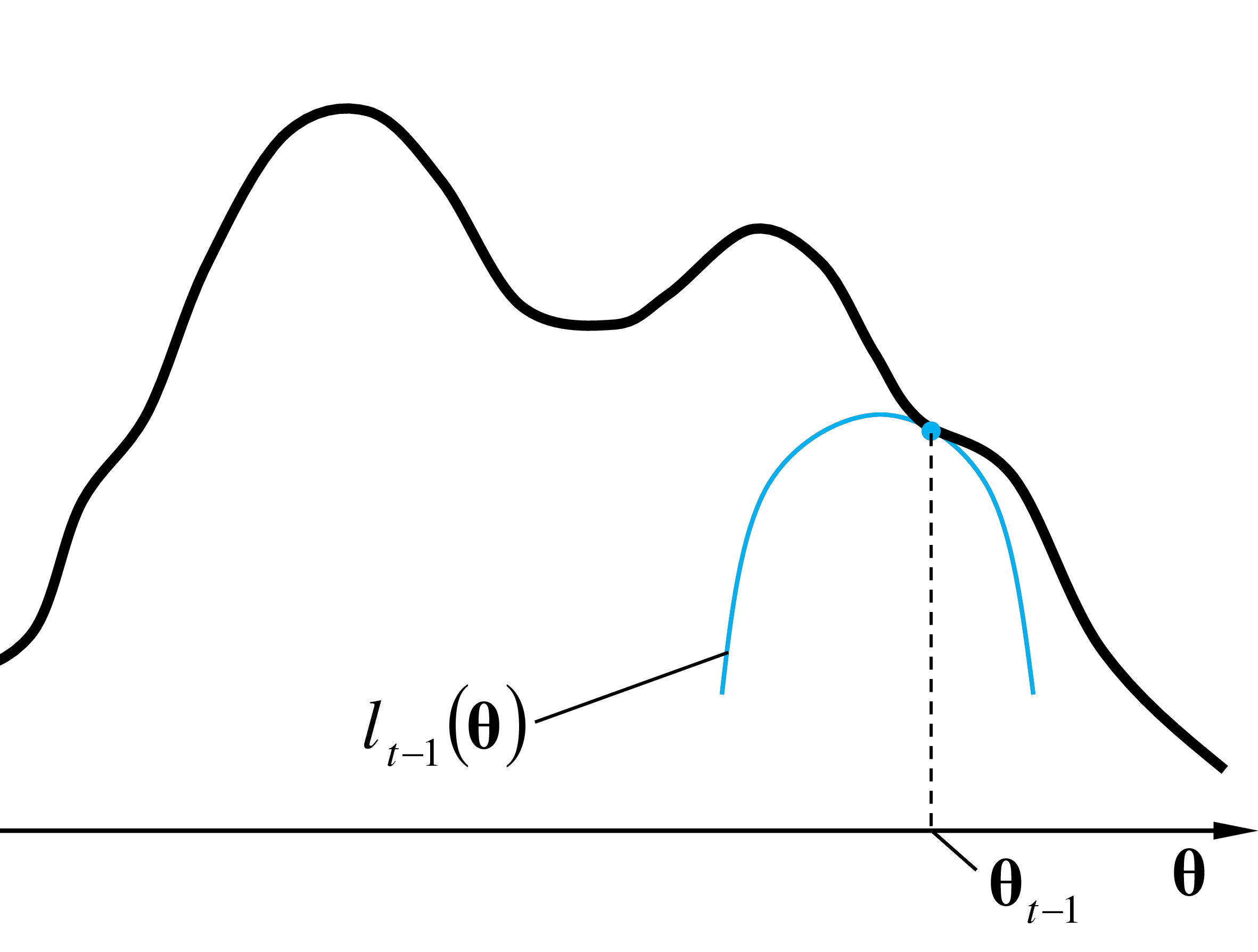
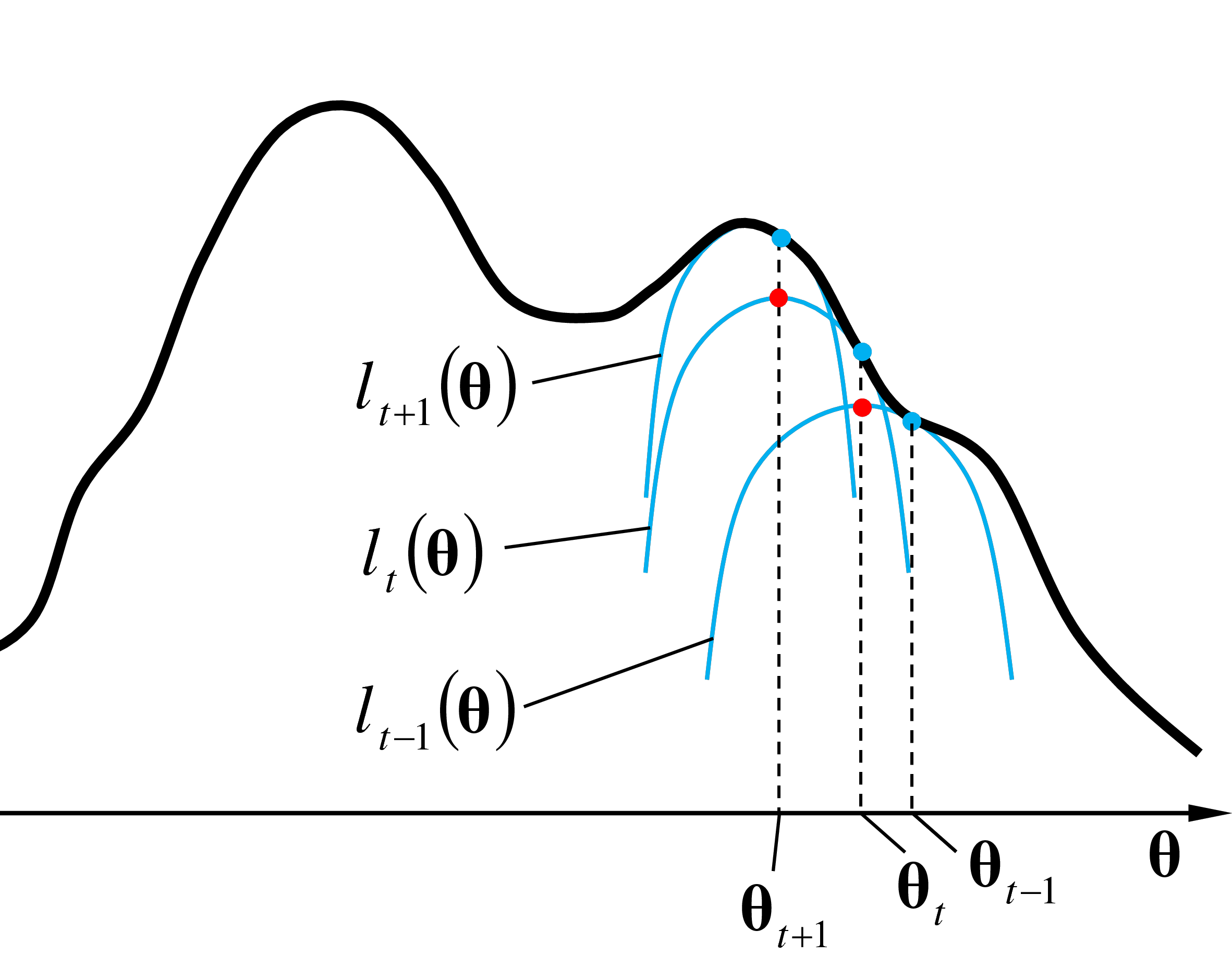
Lors de l’initialisation, des valeurs de départ sont choisies pour les paramètres. Sachant que l’algorithme EM peut converger vers un maximum local, une bonne initialisation est importante. Nous reviendrons sur l’initialisation ultérieurement, lors de l’examen de EM pour des modèles de mélange de lois normales. Dans la figure ci-dessous est représentée la valeur des paramètres à l’issue de l’itération précédente, \(\boldsymbol{\theta}_{t-1}\).
Lors de l’itération \(t\), dans l’étape E (espérance) est d’abord calculée (avec les paramètres actuels \(\boldsymbol{\theta}_{t-1}\)) l’approximation locale \(l_{t-1}(\boldsymbol{\theta})\) tangente à \(\ln(L)\) en \(\boldsymbol{\theta}_{t-1}\) et qui minore (qui est inférieure ou égale à) cette fonction à maximiser \(\ln(L)\). La figure suivante montre \(l_{t-1}(\boldsymbol{\theta})\).
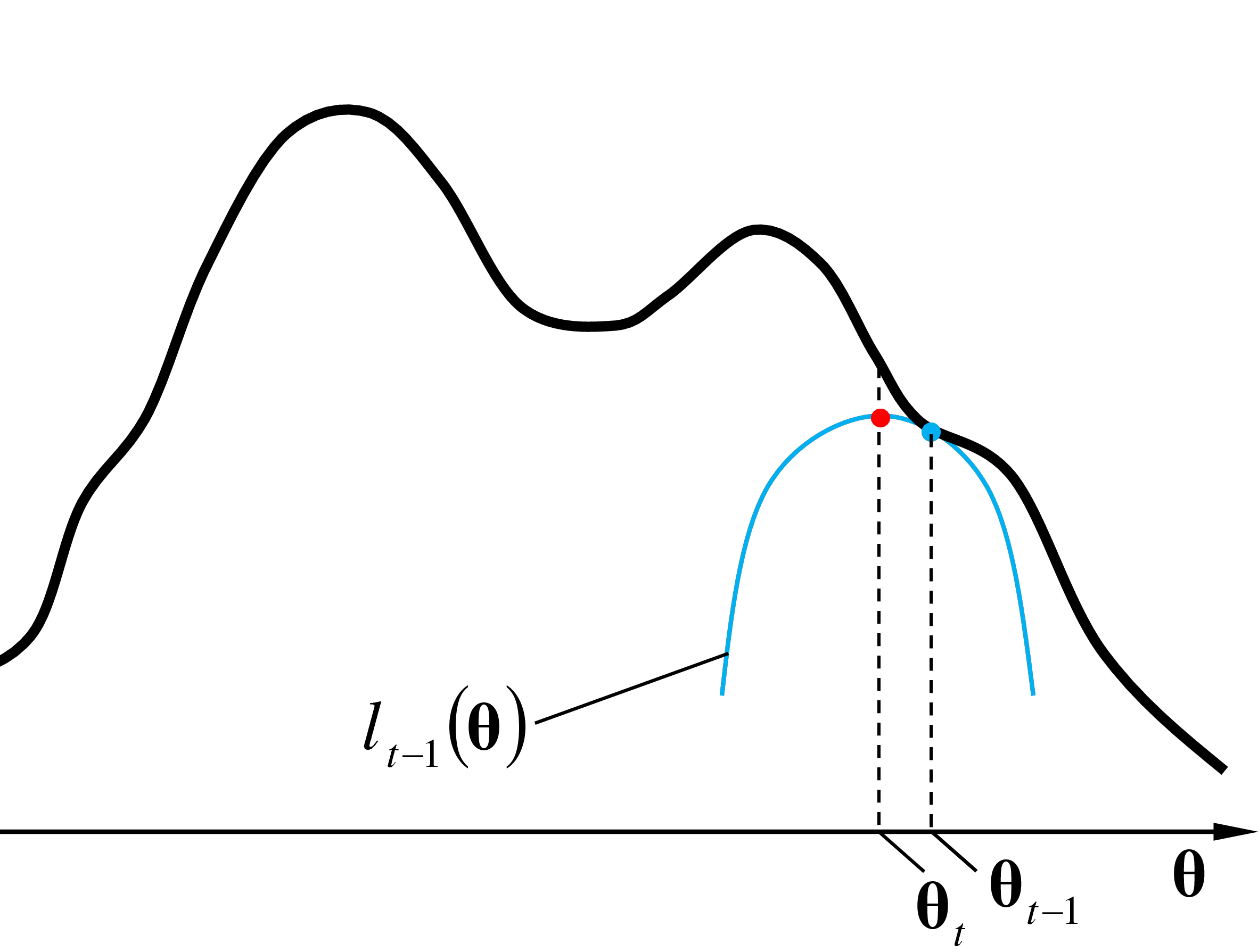
Dans l’étape M (maximisation) de la même itération sont trouvées les valeurs de paramètres qui maximisent l’approximation locale \(l_{t-1}(\boldsymbol{\theta})\). La forme de \(l_{t-1}(\boldsymbol{\theta})\), plus simple que celle de \(\ln(L)\), permet la détermination analytique des paramètres \(\boldsymbol{\theta}_{t}\) qui maximisent \(l_{t-1}(\boldsymbol{\theta})\). Ces paramètres \(\boldsymbol{\theta}_{t}\) sont employés comme condition initiale pour l’itération suivante.
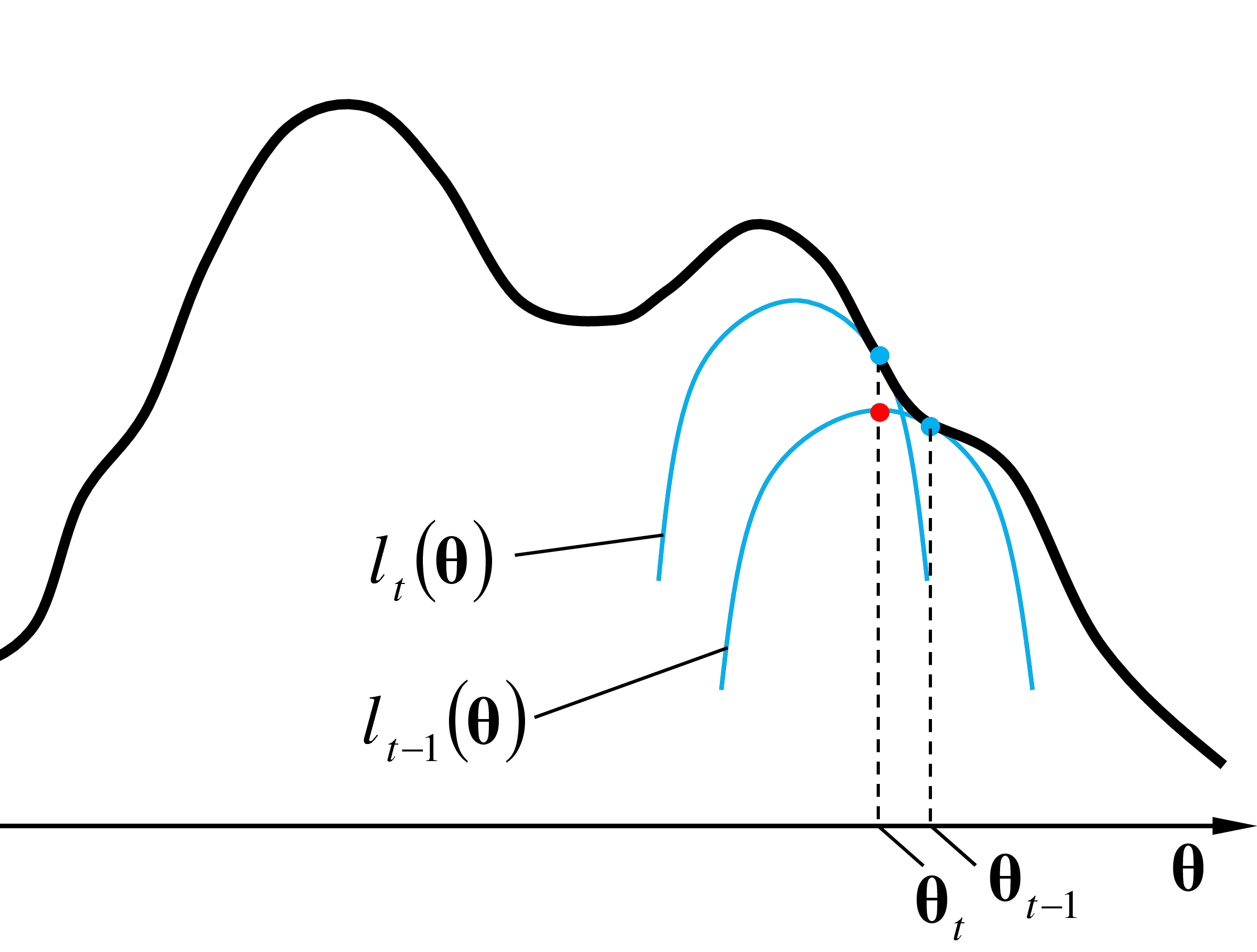
Lors de l’itération \(t+1\), dans l’étape E est calculée avec les paramètres \(\boldsymbol{\theta}_{t}\) l’approximation locale \(l_{t}(\boldsymbol{\theta})\) tangente à \(\ln(L)\) en \(\boldsymbol{\theta}_{t}\) (voir la figure suivante).
Dans l’étape M de l’itération \(t+1\) sont trouvées les valeurs de paramètres qui maximisent l’approximation locale \(l_{t}(\boldsymbol{\theta})\). Ces paramètres \(\boldsymbol{\theta}_{t+1}\) sont employés comme condition initiale pour l’itération suivante.
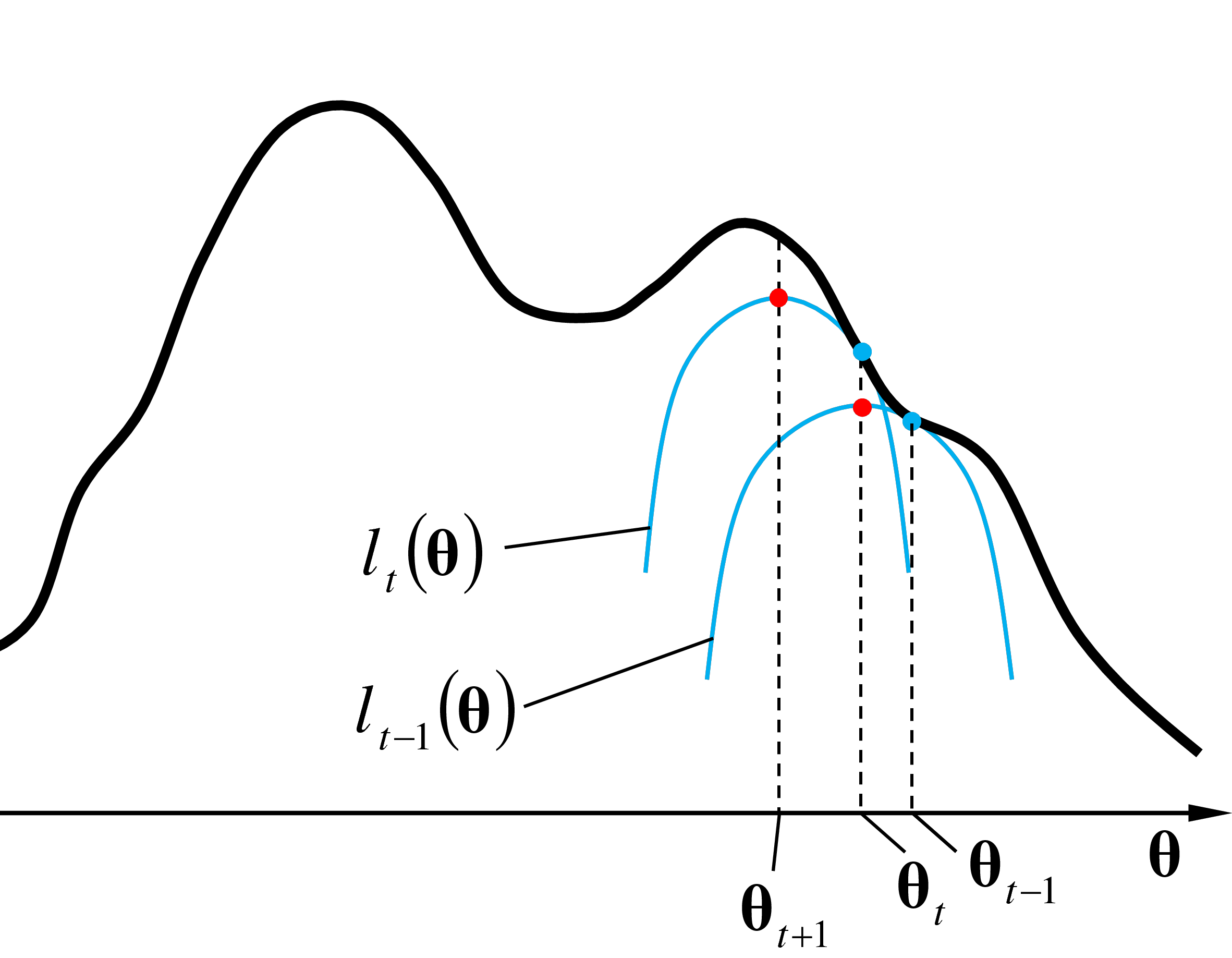
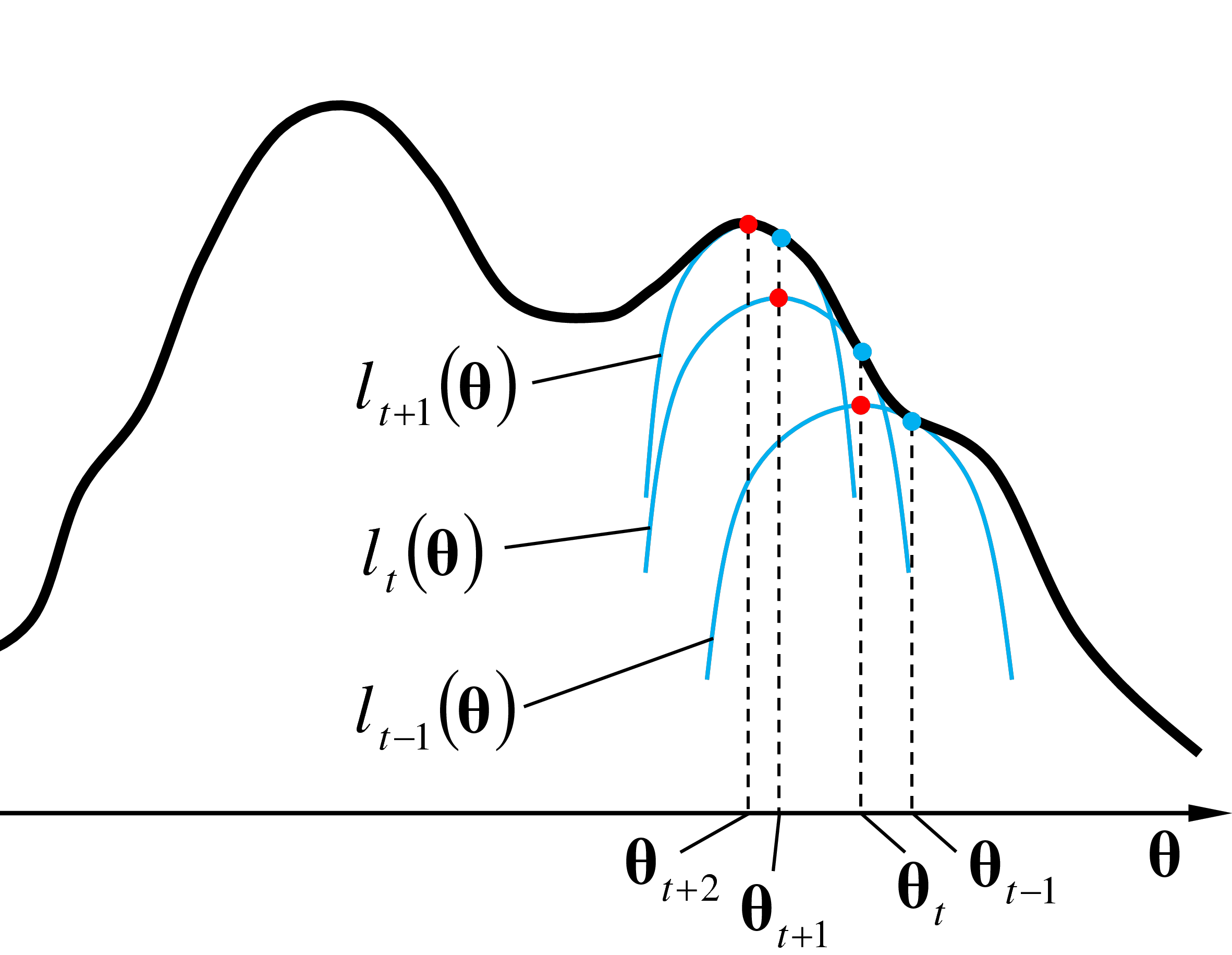
Lors de l’itération \(t+2\), dans l’étape E est calculée avec les paramètres \(\boldsymbol{\theta}_{t+1}\) l’approximation locale \(l_{t+1}(\boldsymbol{\theta})\) tangente à \(\ln(L)\) en \(\boldsymbol{\theta}_{t+1}\) (voir la figure suivante).
Dans l’étape M de l’itération \(t+2\) sont trouvées les valeurs de paramètres qui maximisent l’approximation locale \(l_{t+1}(\boldsymbol{\theta})\). Ces paramètres \(\boldsymbol{\theta}_{t+2}\) sont employés comme condition initiale pour l’itération suivante.
Les itérations se succèdent jusqu’à la convergence. Dans la pratique, on considère que la convergence est atteinte quand la différence entre les valeurs de la (log-)vraisemblance issues de deux itérations successives est inférieure à un seuil pré-établi.
Examinons maintenant de façon plus approfondie l’algorithme EM afin d’obtenir les formules de calcul. Cette partie est optionnelle dans le cours, vous pouvez poursuivre directement avec les explications de la section EM pour mélange gaussien.
De nombreuses présentations succinctes alternatives de l’algorithme EM (introduit dans [DLR77]) existent, vous pouvez par exemple regarder aussi celle de [Roc12].
EM a été proposé pour l’estimation de modèles à partir de données incomplètes. Considérons des données \(\mathcal{D} = \{\mathcal{D}_o, \mathcal{D}_m\}\) où
\(\mathcal{D}_o\) sont des données observées (connues, effectivement mesurées), de réalisations notées \(\mathbf{x}\), issues d’une densité de probabilité \(f_{\boldsymbol{\theta}} \in \mathcal{F}\), inconnue et paramétrée par \(\boldsymbol{\theta} \in \Omega\) (l’espace des paramètres est noté \(\Omega\)).
\(\mathcal{D}_m\) sont des données manquantes (inconnues), de réalisations notées \(\mathbf{y}\), issues d’une densité de probabilité \(g\) inconnue.
Nous cherchons le (vecteur de) paramètre(s) \(\hat{\boldsymbol{\theta}}^*\) qui maximise la log-vraisemblance \(\ln p(\mathcal{D}_o | \boldsymbol{\theta})\), appelée log-vraisemblance des données incomplètes. Cette log-vraisemblance sera notée dans la suite de façon simplifiée par \(L(\mathbf{x};\boldsymbol{\theta})\). La log-vraisemblance des données complètes, \(\ln p(\mathcal{D}_o, \mathcal{D}_m | \boldsymbol{\theta})\), sera notée par \(L\left((\mathbf{x},\mathbf{y});\boldsymbol{\theta}\right)\).
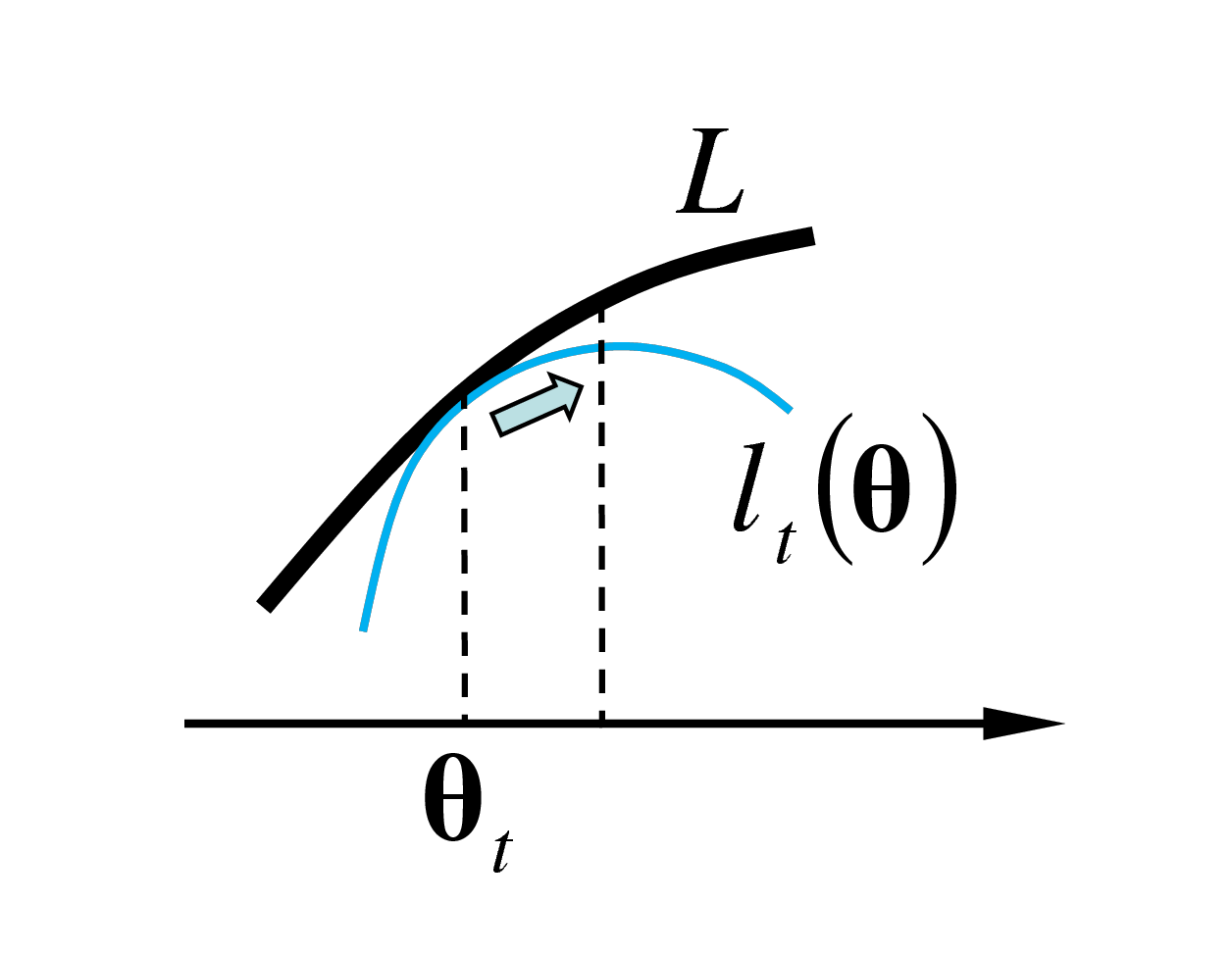
L’idée de base de EM est de trouver, pour tout vecteur de paramètres fixé \(\boldsymbol{\theta}_t\), une approximation locale \(l_t(\boldsymbol{\theta})\) de \(L(\mathbf{x};\boldsymbol{\theta})\) telle que
La figure suivante montre \(L(\mathbf{x};\boldsymbol{\theta})\) et son approximation locale \(l_t(\boldsymbol{\theta})\) à proximité du point de tangence d’argument \(\boldsymbol{\theta}_t\). L’argument qui maximise \(l_t(\boldsymbol{\theta})\) permet d’augmenter \(L(\mathbf{x};\boldsymbol{\theta})\).
En conséquence, maximiser (ou simplement augmenter !) \(l_t(\boldsymbol{\theta})\) permet de s’approcher du maximum de \(L(\mathbf{x};\boldsymbol{\theta})\). Bien entendu, l’approximation locale \(l_t(\boldsymbol{\theta})\) doit permettre de trouver facilement l’expression de l’argument \(\boldsymbol{\theta}_t^*\) qui la maximise (ou un argument qui augmente la valeur de \(l_t(\boldsymbol{\theta})\)).
Afin de trouver une forme adéquate pour l’approximation locale \(l_t(\boldsymbol{\theta})\), développons la log-vraisemblance des données incomplètes :
Dans la première égalité de (35), \(\ln p(\mathbf{x} | \boldsymbol{\theta})\) est la notation simplifiée de la log-vraisemblance des données incomplètes \(\ln p(\mathcal{D}_o | \boldsymbol{\theta}))\). Elle peut être obtenue en marginalisant la distribution jointe des données observées et des données manquantes par rapport aux données manquantes, ce qui est indiqué dans le deuxième égalité. Pour la troisième égalité nous avons simplement multiplié par \(1 = \frac{p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t)}{p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t)}\) sous l’intégrale. En échangeant \(p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t)\) et \(p(\mathbf{x},\mathbf{y} | \boldsymbol{\theta})\) nous obtenons la quatrième égalité. Enfin, l’inégalité finale ci-dessus résulte de l’inégalité de Jensen.
Nous avons donc défini l’approximation locale \(l_t(\boldsymbol{\theta})\) par
La première égalité ci-dessus est simplement la définition de (36). Pour la deuxième égalité nous avons exprimé la probabilité jointe à partir de la probabilité conditionnelle, \(p(\mathbf{x},\mathbf{y} | \boldsymbol{\theta}_t) = p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t) p(\mathbf{x} | \boldsymbol{\theta}_t))\). La troisième égalité ci-dessus résulte de la condition de normalisation \(\int p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t) dy = 1\) et du fait que \(\ln p(\mathbf{x} | \boldsymbol{\theta}_t)\) ne dépend pas de la variable d’intégration \(y\). Enfin, la dernière égalité ci-dessus correspond à la définition de la vraisemblance des données incomplètes \(L(\mathbf{x};\boldsymbol{\theta}_t)\).
Cela montre donc (34) et, avec (37), nous obtenons aussi (33).
Afin d’expliquer le nom « Espérance » (Expectation) pour l’étape E (calcul de \(l_t(\boldsymbol{\theta})\)), nous pouvons développer \(l_t(\boldsymbol{\theta})\) sachant que \(\ln \frac{A}{B} = \ln A - \ln B\) :
Ici, \(Q(\boldsymbol{\theta} | \boldsymbol{\theta}_t)\) est l’espérance conditionnelle de la log-vraisemblance des données complètes, \(L\left((\mathbf{x},\mathbf{y});\boldsymbol{\theta}\right)\), calculée pour des données manquantes qui suivent leur densité a posteriori\(p(\mathbf{y} | \mathbf{x},\boldsymbol{\theta}_t)\).
La différence entre \(l_t(\boldsymbol{\theta})\) et \(Q(\boldsymbol{\theta} | \boldsymbol{\theta}_t)\) ne dépendant pas de \(\boldsymbol{\theta}\), l’argument \(\boldsymbol{\theta}^*\) qui maximise \(l_t(\boldsymbol{\theta})\) maximise également \(Q(\boldsymbol{\theta} | \boldsymbol{\theta}_t)\) et réciproquement.
Nous nous contentons ici d’expliciter différentes formes de l’inégalité de Jensen sans la démontrer :
Si \(\phi : \mathcal{A} \in \mathbb{R} \rightarrow \mathbb{R}\) est une fonction convexe (pour tout \(x, y \in \mathcal{A}\) et tout \(t \in [0; 1]\), \(\phi\left(t x + (1-t) y\right) \leq t \phi(x) + (1-t) \phi(y)\)) et \(X\) une variable aléatoire à valeurs dans l’ensemble \(\mathcal{A}\), alors
Cas d’une densité de probabilité : soit \(g\) une fonction qui prend des valeurs dans \(\mathcal{A} \in \mathbb{R}\), \(\phi\) convexe sur \(\mathcal{A}\) (c’est à dire sur le co-domaine de \(g\)) et \(f\) une densité de probabilité, alors
Cas d’un échantillon (fini) : soit \(g\) une fonction qui prend des valeurs dans \(\mathcal{A} \in \mathbb{R}\), \(\phi\) convexe sur \(\mathcal{A}\) et \(N\) coefficients réels \(\lambda_i \geq 0\), \(1 \leq i \leq N\) qui satisfont la contrainte de normalisation \(\sum_{i=1}^N \lambda_i = 1\), alors
Si la fonction \(\phi\) est concave (pour tout \(x, y \in \mathcal{A}\) et tout \(t \in [0; 1]\), \(\phi\left(t x + (1-t) y\right) \geq t \phi(x) + (1-t) \phi(y)\)), comme le \(\ln\) (voir la Fig. 95), alors le sens des inégalités est inversé. C’est cette forme que nous avons employée plus haut pour démontrer (37).
Nous pouvons maintenant écrire de façon plus précise l’algorithme EM, qui est donc :
Initialiser les paramètres \(\boldsymbol{\theta}_0\);
Itérer jusqu’à la convergence :
2.1. Étape E : calculer \(l_t(\boldsymbol{\theta}) \leq L(\mathbf{x};\boldsymbol{\theta})\), avec égalité pour \(\boldsymbol{\theta} = \boldsymbol{\theta}_t\);
2.2. Étape M : trouver \(\boldsymbol{\theta}_{t+1}\) qui maximise \(l_t(\boldsymbol{\theta})\).
Les applications de l’algorithme EM font partie des deux catégories suivantes :
Estimation de modèles à partir de données qui présentent des valeurs manquantes pour une ou plusieurs variables (manques provoqués par exemple par des difficultés d’observation).
Introduction artificielle de variable(s) à valeurs manquantes pour faciliter la maximisation de la vraisemblance. La variable à valeurs manquantes est définie de façon à faciliter la maximisation des \(l_t(\boldsymbol{\theta})\) successives par rapport à une maximisation directe de \(L(\mathbf{x};\boldsymbol{\theta})\). L’application de EM à l’estimation de modèles de mélange entre dans cette catégorie.
Examinons l’application de l’algorithme EM à l’estimation de modèles de mélange (29). Pour cela, introduisons d’abord des variables aléatoires non observées (manquantes) \(\{Y_i\}_{i=1}^N\) à valeurs \(y_i \in \{1, \ldots, m\}\) (\(m\) est le nombre de composantes du mélange) dont la signification est la suivante : \(y_i = j\) si et seulement si l’observation \(\mathbf{x}_i\) a été générée par la composante \(j\) du mélange.
Notre objectif est de trouver les paramètres \(\left(\begin{array}{c}\hat{\boldsymbol{\alpha}}^*\\\hat{\boldsymbol{\theta}}^*\end{array}\right)\) qui maximisent \(\ln p(\mathcal{D}_o | \boldsymbol{\alpha},\boldsymbol{\theta})\), la log-vraisemblance des données incomplètes. Nous avons vu que EM permettait de remplacer ce problème par celui de la maximisation, à chaque itération, de l’approximation locale \(l_t(\boldsymbol{\alpha},\boldsymbol{\theta})\). Comme nous avons pu le constater plus haut, cela revient à maximiser \(Q(\boldsymbol{\alpha},\boldsymbol{\theta} | \boldsymbol{\alpha}_t,\boldsymbol{\theta}_t)\) qui diffère de \(l_t(\boldsymbol{\alpha},\boldsymbol{\theta})\) par une valeur indépendante des paramètres.
Examinons donc \(Q(\boldsymbol{\alpha},\boldsymbol{\theta} | \boldsymbol{\alpha}_t,\boldsymbol{\theta}_t)\). Les variables \(\{Y_i\}\) (à valeurs manquantes) prenant des valeurs discrètes plutôt que continues, l’intégration dans la définition de \(l\) ou de \(Q\) est remplacée par une somme. L’expression de \(Q(\boldsymbol{\alpha},\boldsymbol{\theta} | \boldsymbol{\alpha}_t,\boldsymbol{\theta}_t)\) devient
La première égalité ci-dessus correspond à la définition de \(Q\). Pour l’obtenir sous cette forme, le plus simple est de refaire (35) et (38) tenant compte de la définition de la vraisemblance des données incomplètes et du fait que maintenant les \(\{Y_i\}_{i=1}^N\) sont des variables à valeurs discrètes \(y_i \in \{1, \ldots, m\}\). La somme \(\sum_{i=1}^N\) est la conséquence de \(\ln p(\mathbf{x} | \boldsymbol{\alpha},\boldsymbol{\theta}) = \ln \prod_{i=1}^N p(\mathbf{x}_i | \boldsymbol{\alpha},\boldsymbol{\theta})\) (indépendance des observations) et \(\ln \prod_{i=1}^N p(\mathbf{x}_i | \boldsymbol{\alpha},\boldsymbol{\theta}) = \sum_{i=1}^N \ln p(\mathbf{x}_i | \boldsymbol{\alpha},\boldsymbol{\theta})\) (propriétés du logarithme)). Enfin, \(p(\mathbf{x}_i | \boldsymbol{\alpha},\boldsymbol{\theta}) = \sum_{k=1}^m p(\mathbf{x}_i, y_i=k | \boldsymbol{\alpha},\boldsymbol{\theta})\) (marginalisation).
On obtient la deuxième égalité de (39) en exprimant la probabilité jointe en fonction de la probabilité conditionnelle, \(p(\mathbf{x}_i,y_i=k | \boldsymbol{\alpha},\boldsymbol{\theta}) = p(\mathbf{x}_i | y_i=k, \boldsymbol{\alpha},\boldsymbol{\theta}) P(y_i=k | \boldsymbol{\alpha},\boldsymbol{\theta})\), et en tenant compte du fait que \(p(\mathbf{x}_i | y_i=k, \boldsymbol{\alpha},\boldsymbol{\theta}) = p(\mathbf{x}_i | y_i=k, \boldsymbol{\theta}_k)\), où \(\boldsymbol{\theta}_k\) sont les paramètres de la \(k\)-ème composante du mélange.
Enfin, la dernière égalité de (39) tient compte du fait que \(p(\mathbf{x}_i | y_i=k, \boldsymbol{\theta}_k) = f_k(\mathbf{x}_i | \boldsymbol{\theta}_k)\), la densité de la \(k\)-ème composante du mélange (de paramètres \(\boldsymbol{\theta}_k\)).
Comme nous pouvons le constater, l’expression obtenue dans (39) ne contient pas de somme sous le logarithme. Pour la maximisation de \(Q(\boldsymbol{\alpha},\boldsymbol{\theta} | \boldsymbol{\alpha}_t,\boldsymbol{\theta}_t)\) nous pouvons donc trouver une solution analytique lorsque les composantes font partie d’une famille convenable (par ex. celle des lois normales multidimensionnelles), ce qui n’est pas le cas pour la maximisation directe de la log-vraisemblance des données incomplètes, expression (31). Afin de trouver effectivement la solution nous pouvons employer le même procédé qui passe par l’identification des arguments pour lesquels s’annulent les dérivées premières et l’examen du signe des dérivées secondes (voir par ex. la section Estimation par une loi normale unidimensionnelle).
Pour un mélange de lois normales, en explicitant (39), nous obtenons in fine les relations suivantes pour les mises à jour lors des itérations de l’algorithme EM :
La mise à jour de \(P(y_i=k | \mathbf{x}_i,\boldsymbol{\alpha}_t,\boldsymbol{\mu}_t,\boldsymbol{\Sigma}_t)\), (40), contribue au calcul de \(Q(\boldsymbol{\alpha},\boldsymbol{\theta} | \boldsymbol{\alpha}_t,\boldsymbol{\theta}_t)\) (voir (39)) et fait donc partie de l’étape E (Espérance). En revanche, les mises à jour des coefficients de mélange (41) et des paramètres des composantes (42), (43) sont effectuées dans l’étape M (Maximisation).
Examinons maintenant de façon informelle le déroulement de l’algorithme EM à travers les trois illustrations suivantes.
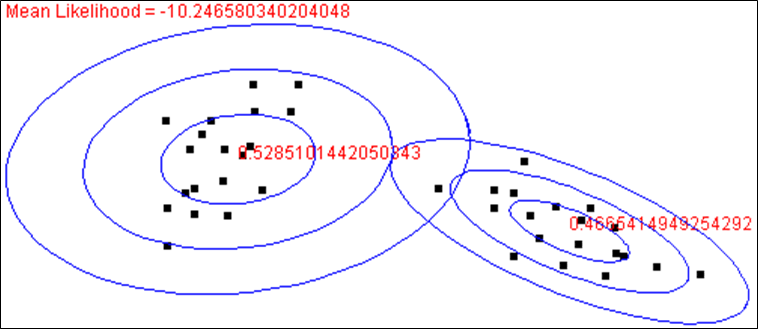
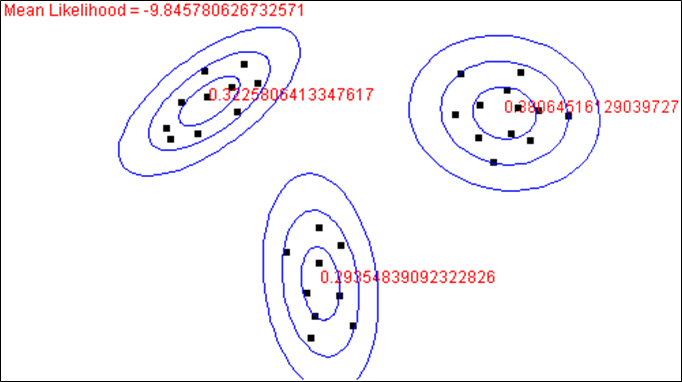
Dans cet exemple, les observations bidimensionnelles (représentées par les points noirs) de \(\mathcal{D}_N \in \mathbb{R}^2\) sont issues de deux lois normales bidimensionnelles. Nous cherchons à estimer la densité par un mélange additif de deux composantes (\(m = 2\)) qui sont des lois normales bidimensionnelles. Dans l’algorithme EM, après initialisation des paramètres (de ces lois et du mélange), à chaque itération les paramètres sont modifiés afin de maximiser \(l_t(\boldsymbol{\alpha},\boldsymbol{\theta})\). Dans les illustrations qui suivent, chaque loi normale bidimensionnelle est représentée par ses courbes de niveau qui sont des ellipses concentriques, l’ellipse intérieure correspondant à une valeur élevée de la loi normale et l’ellipse extérieure à une valeur faible de cette loi.
Lors de l’initialisation, étape sur laquelle nous revenons dans la suite, les composantes sont peu spécialisées : chacune couvre une large partie des observations de \(\mathcal{D}_N\). Rappelons que \(P(y_i=k | \mathbf{x}_i,\boldsymbol{\alpha},\boldsymbol{\theta}_t)\) est la probabilité que l’observation \(\mathbf{x}_i\) soit issue de la composante \(k\). Au départ ces valeurs sont relativement équilibrées, chaque observation est « expliquée » de façon relativement équivalente par les deux composantes (lois normales) qui justement ne sont pas encore spécialisées.
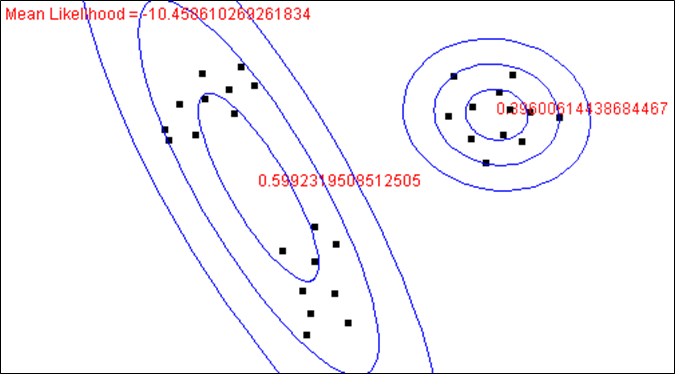
La figure suivante montre les deux composantes après la première itération de l’algorithme EM :
On constate déjà un début de spécialisation des deux composantes. La composante de droite (à laquelle nous donnons le numéro 1) explique assez bien les observations situées à droite et très mal celles situées à gauche (les valeurs de cette loi normale sont faibles pour ces observations, situées entre la deuxième et la troisième ellipse de cette loi). L’autre composante (à laquelle nous donnons le numéro 2) continue toutefois de couvrir assez bien toutes les observations, même si elle explique mieux celles situées à gauche (plus nombreuses dans l’ellipse intérieure).
En accord avec ce début de spécialisation, les \(P(y_i=k | \mathbf{x}_i,\boldsymbol{\alpha},\boldsymbol{\theta}_t)\) se différencient : de nombreuses observations sont bien mieux expliquées par une des composantes que par l’autre. Aussi, dans la mise à jour des paramètres de chaque loi, les observations que cette loi explique mieux contribuent plus que les observations que cette loi explique moins bien. Il y a ainsi une « double spécialisation » progressive : de chaque composante dans certaines observations (qu’elle explique mieux que les autres composantes) et de chaque observation dans une des composantes (à la mise à jour de laquelle cette observation contribuera plus qu’aux autres).
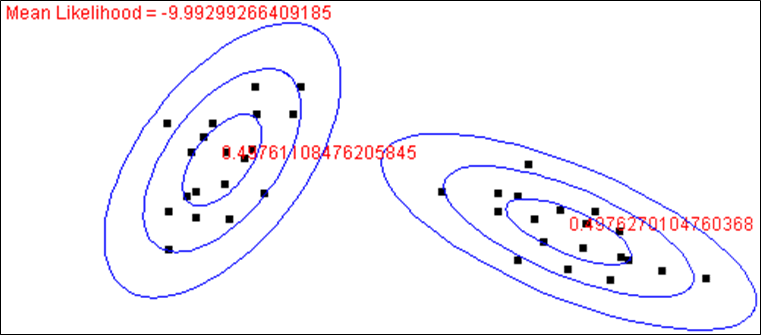
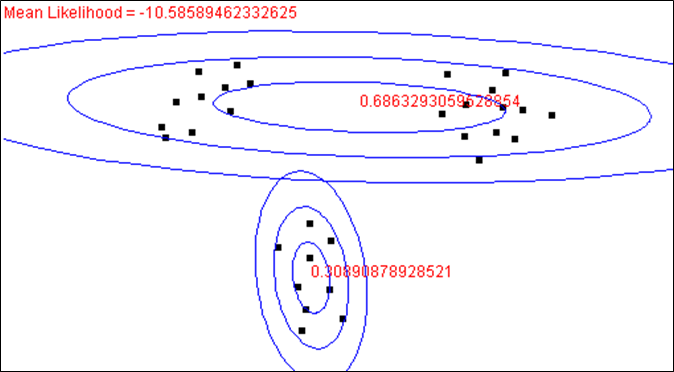
L’état des deux composantes après 4 itérations est montré dans la figure suivante :
La composante 1 est déjà bien spécialisée, elle explique pratiquement exclusivement les observations situées à droite. Pour ces données nous avons \(P(y_i=1 | \mathbf{x}_i,\boldsymbol{\alpha},\boldsymbol{\theta}_t) \approx 1\) (et donc \(P(y_i=2 | \mathbf{x}_i,\boldsymbol{\alpha},\boldsymbol{\theta}_t) \approx 0\)). Aussi, seules ces observations contribuent à la mise à jour de ses paramètres. Quant à la composante 2, elle est assez bien spécialisée dans les observations situées à gauche.
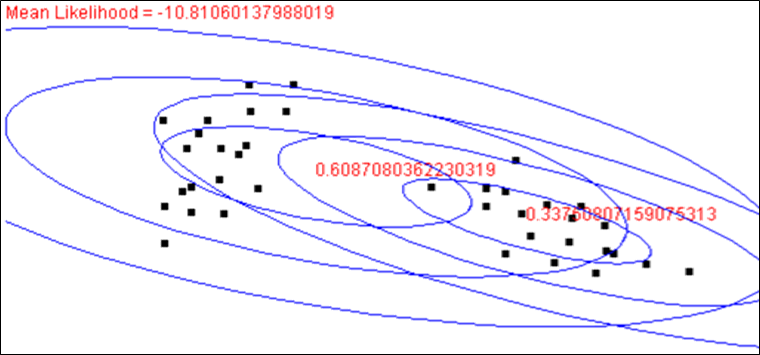
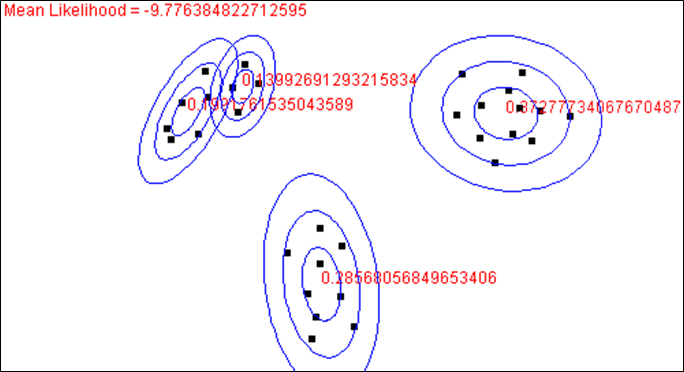
Après la 5ème itération l’algorithme a convergé. Dans l’illustration suivante nous pouvons constater que chaque composante est bien spécialisée dans une partie des données. La valeur de la log-vraisemblance (Mean likelihood en rouge dans les figures) augmente au fil des itérations, comme attendu.
Il faut noter que cet exemple est particulier et, en général, les composantes peuvent être moins spécialisées in fine si les données ne forment pas de groupes aussi bien séparés.
Une méthode simple d’initialisation des paramètres du modèle de mélange au lancement de l’algorithme EM est la suivante :
Estimer une loi normale multidimensionnelle à partir de la totalité des observations de \(\mathcal{D}_N\).
Perturber aléatoirement l’espérance multidimensionnelle \(\boldsymbol{\mu}\) de cette loi normale pour obtenir les espérances multidimensionnelles de départ \(\boldsymbol{\mu}_k\) des composantes du mélange.
Perturber aléatoirement la matrice de variances-covariances \(\boldsymbol{\Sigma}\) de cette loi normale pour obtenir les matrices de variances-covariances de départ \(\boldsymbol{\Sigma}_k\) des composantes du mélange.
D’autres méthodes d’initialisation emploient, par exemple, l’algorithme de classification K-means (initialisé à son tour avec K-means++) pour obtenir les espérances multidimensionnelles de départ \(\boldsymbol{\mu}_k\) des composantes du mélange. Les matrices de variances-covariances correspondantes \(\boldsymbol{\Sigma}_k\) sont ensuite estimées à partir des données de chaque groupe obtenu avec K-means et les variances sont augmentées afin d’éviter une spécialisation trop rapide pouvant mener à un maximum local de la log-vraisemblance.
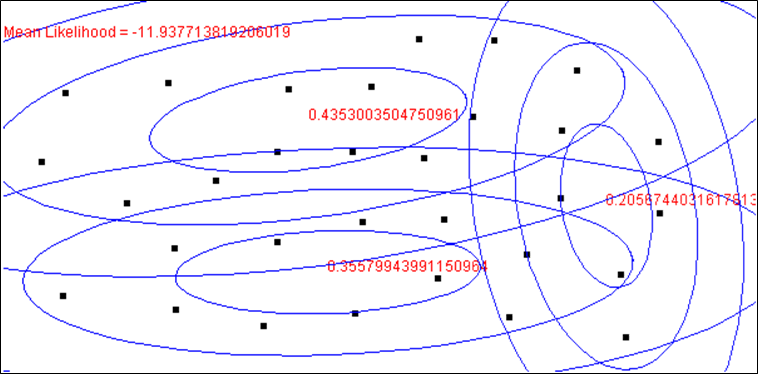
Comme pour la classification automatique, nous pouvons nous demander quel est le résultat de la recherche d’un modèle lorsque les données sont issues d’une densité de probabilité qui ne correspond pas aux hypothèses du modèle. Par exemple, la recherche avec EM d’un mélange de lois normales pour des données issues d’une densité uniforme sur un intervalle bidimensionnel. Les quatre figures suivantes montrent les résultats obtenus sur les mêmes données avec quatre initialisations différentes de l’algorithme EM :
Nous pouvons constater que, lorsque les données ne respectent pas les hypothèses de modélisation, les résultats obtenus présentent une grande variabilité et ne sont pas pertinents. Cette variabilité peut être employée comme outil de diagnostic pour identifier ces situations où les hypothèses de modélisation ne sont pas conformes aux observations.
Enfin, avant d’examiner des méthodes pour choisir le nombre \(m\) de composantes du modèle, regardons les résultats obtenus avec différentes valeurs de \(m\) sur un autre exemple bidimensionnel dans lequel les données sont issues de trois lois normales relativement bien séparées.
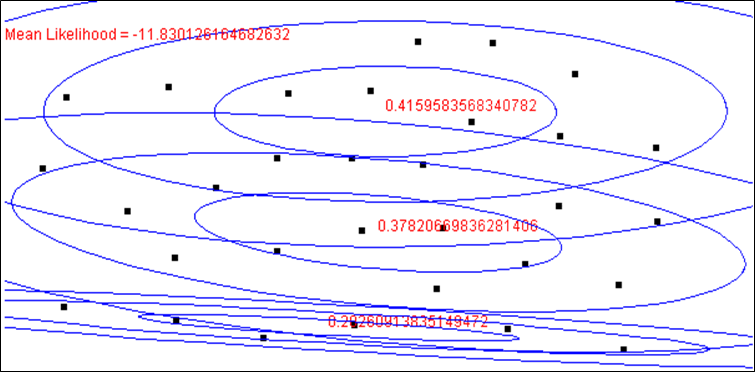
Lorsque \(m = 3\), qui est la valeur adéquate dans cet exemple, la solution systématiquement obtenue (quelle que soit l’initialisation, à condition qu’elle n’engendre pas une spécialisation précoce des composantes) est celle présentée dans la figure suivante :
Si le nombre de composantes recherchées est insuffisant, \(m = 2\), dans la solution une des composantes explique un groupe d’observations et l’autre composante explique les deux autres groupes. Les deux figures suivantes montrent deux solutions obtenues (parmi les trois possibles) pour des initialisations différentes :
Si le nombre de composantes est trop élevé, \(m = 4\), dans la solution deux des composantes correspondent chacune à un groupe d’observations et l’autre groupe est partagé entre deux composantes. La figure suivante montre une des solutions obtenues pour des initialisations différentes :
La complexité d’un modèle de mélange est donnée par
Le nombre de composantes du modèle : chaque nouvelle composante ajoute comme paramètres son coefficient de mélange et les coefficients qui définissent sa densité (par exemple, pour une loi normale multidimensionnelle, son espérance et sa matrice de variances-covariances).
Les caractéristiques particulières des lois composantes. Par exemple, la matrice des variances-covariances peut être quelconque (variances et covariances non nulles), ou diagonale (covariances nulles), ou encore diagonale avec tous les éléments identiques sur la diagonale principale (toutes les variances identiques entre elles, loi « sphérique »). Si la dimension de la matrice est \(d \times d\), dans le premier cas le nombre de paramètres est \(\frac{d (d+1)}{2}\), dans le deuxième cas \(d\) et dans le troisième seulement \(1\).
En général, l’augmentation du nombre de paramètres du modèle recherché a pour conséquence l’augmentation de la valeur maximale que peut atteindre la log-vraisemblance \(\ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\) à la fin de l’algorithme d’estimation (comme Espérance-Maximisation présenté ci-dessus). Cela veut dire qu’une augmentation du nombre de paramètres mène à un modèle qui « explique mieux » les observations de \(\mathcal{D}_N\). Faut-il alors préférer systématiquement un modèle plus complexe ? Nous avons déjà rencontré une question de même type pour la classification automatique. La réponse est non : un modèle de mélange qui aurait \(N\) composantes, chacune très « pointue » et centrée sur chaque observation de \(\mathcal{D}_N\), expliquerait parfaitement ces observations mais probablement très mal d’autres observations issues de la même densité que \(\mathcal{D}_N\).
Il est donc nécessaire de disposer de méthodes permettant de bien choisir la complexité du modèle de mélange et notamment le bon nombre \(m\) de composantes. La log-vraisemblance seule ne peut pas servir de critère de choix de la complexité car sa valeur maximale augmente avec la complexité.
Parmi les familles de méthodes qui ont été proposées (voir par ex. [OBM05] pour une liste plus complète avec des références spécifiques), nous pouvons citer :
Les tests d’hypothèses : inspirés par LRTS (likelihood ratio test statistic), ils permettent de tester l’intérêt d’ajouter une \(m+1\)-ème composante au mélange.
Les critères « d’information », qui consistent à ajouter à la \(-\)log-vraisemblance (\(- \ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\)) des pénalités qui augmentent avec le nombre de paramètres libres. Le meilleur modèle n’est pas celui qui a la log-vraisemblance la plus élevée mais celui qui présente le meilleur compromis entre la maximisation de la log-vraisemblance et minimisation de la pénalité. Nous examinerons les deux critères les plus connus dans la suite.
Les critères de classification consistent à évaluer la capacité du mélange obtenu à produire des groupes bien séparés. Ici chaque groupe correspond aux observations de \(\mathcal{D}_N\) qui sont mieux expliquées par une des composantes du mélange. Pour une valeur trop faible de \(m\) certaines composantes rassemblent plusieurs groupes, alors que pour une valeur trop élevée de \(m\) certains groupes sont partagés entre plusieurs composantes (comme nous l’avons vu plus haut dans des exemples). Bien entendu, de tels critères sont intéressants seulement si les observations forment des groupes bien séparés.
Ce critère (Akaike Information Criterion, AIC), introduit par Akaike en 1971, ajoute une pénalité qui dépend uniquement, et de façon linéaire, du nombre \(k\) de paramètres libres à estimer (\(k \geq 0\)) :
Lorsque le nombre de paramètres \(k\) augmente, la log-vraisemblance \(\ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\) (qui a toujours une valeur négative) augmente également (se rapproche de 0, c’est à dire devient moins négative) et donc le terme \(-2 \ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\) (qui a toujours une valeur positive) diminue (se rapproche de 0). En revanche, lorsque le nombre de paramètres augmente, la pénalité correspondante (le terme \(2 k\)) augmente également. Est préféré le modèle qui minimise AIC : il présente une log-vraisemblance relativement élevée (explique bien les observations), tout en ayant une pénalité relativement faible.
Un modèle qui a un nombre très insuffisant de paramètres (par ex. un nombre \(m\) de composantes trop faible) a une log-vraisemblance faible (très négative, donc le terme \(-2 \ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\) est positif très élevé). Le biais du modèle est élevé, le nombre insuffisant de paramètres ne lui permet pas de bien expliquer les données. Ce modèle bénéficie en revanche d’une pénalité faible.
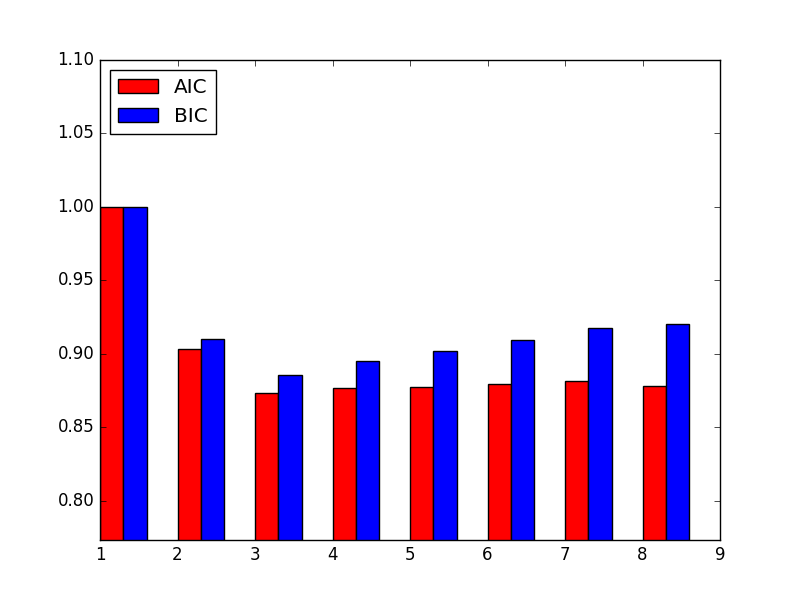
En partant d’un modèle trop « simple » qui explique mal les données, au fur et à mesure que le nombre de paramètres augmente, les modèles sont de mieux en mieux capables d’expliquer les données mais leurs pénalités sont également plus fortes. Au début la log-vraisemblance augmente rapidement, donc la log-vraisemblance négative diminue rapidement ; si cette diminution est plus rapide que l’augmentation de la pénalité, la valeur du critère AIC diminue. Au-delà d’une certaine valeur de \(k\), la log-vraisemblance augmente très lentement avec le nombre de paramètres (la log-vraisemblance négative diminue très lentement), alors que l’augmentation de la pénalité reste linéaire ; donc la valeur du critère AIC finit par augmenter. On constate qu’il y a une valeur de \(k\) (parfois plusieurs) pour laquelle le critère atteint sa valeur minimale. La figure ci-dessous (issue de la séance de travaux pratiques) illustre cela pour AIC ainsi que pour le critère suivant, BIC ; attention, sur cette illustration il ne faut pas comparer AIC et BIC car les valeurs ont été normalisées par rapport à la valeur la plus élevée de chaque critère. Il est important de noter que des minima locaux sont possibles aussi pour la valeur du critère AIC, il est donc important d’explorer une plage assez large de valeurs de \(k\) (et notamment de \(m\)) pour trouver le minimum le plus bas.
Fig. 106 Exemple générique d’évolution des critères AIC et BIC avec l’augmentation de \(m\)¶
Rappelons qu’un modèle trop complexe (qui a trop de paramètres, par ex. le nombre \(m\) de composantes est trop élevé) explique très bien les observations de \(\mathcal{D}_N\) sur lesquelles ces paramètres ont été optimisés (avec l’algorithme EM, par exemple) mais très mal d’autres observations issues de la même densité de probabilité. Sur un autre échantillon \(\mathcal{D}'_N\) qui serait généré à partir de la même densité recherchée, avec la même complexité (le même nombre de paramètres) un modèle très différent serait obtenu. Il y a donc une forte variance dans les valeurs résultantes des paramètres du modèle, qui dépendent ainsi beaucoup de l’échantillon d’observations, pourtant issu de la même densité. Cette variance augmente avec \(k\), d’où l’utilisation de \(k\) dans le terme de pénalité de AIC.
Ainsi, en cherchant à minimiser la somme entre un terme qui augmente avec le biais (terme \(\ln p(\mathcal{D}_o | \hat{\boldsymbol{\theta}})\)) et un terme qui augmente avec la variance (terme \(k\)), AIC vise à trouver le meilleur compromis entre biais et variance.
Ce critère, introduit par Schwartz en 1978 sur des considérations bayésiennes (d’où le nom Bayesian Information Criterion, BIC), tient compte également du nombre \(N\) d’observations :
Nous remarquerons que le nombre \(N\) d’observations doit être bien supérieur au nombre de paramètres du modèle, \(N \gg k\). Aussi, la pénalité augmente avec le logarithme du nombre d’observations.
Nous ne détaillerons pas ici la justification du critère BIC (mais une dérivation peut être trouvée dans ce document). BIC vise à maximiser la probabilité a posteriori du modèle, en considérant une distribution a priori non informative sur les modèles et sur les paramètres de chaque modèle.
Des définitions (44) et (45) résulte que la pénalité BIC est plus forte que la pénalité AIC dès que \(N \geq 8 \left(\ln N > 2\right)\). Avec BIC nous obtenons ainsi souvent des modèles plus simples (avec une valeur inférieure pour \(k\)) qu’avec AIC.
Pour l’estimation de densités nous avons étudié des méthodes issues de deux familles : méthodes non paramétriques et méthodes paramétriques. Chacune de ces deux familles présente certains avantages qui sont résumés dans la suite.
Avantages des méthodes non paramétriques :
Le principal avantage est la généralité due à l’absence d’hypothèses sur la nature et sur le nombre de lois qui doivent être additionnées pour obtenir une (très) bonne estimation de la vraie densité (recherchée) dont sont issues les observations de \(\mathcal{D}_N\). Malgré cette absence d’hypothèses, la convergence vers la vraie densité est garantie (quelle que soit cette vraie densité) si l’échantillon est suffisant, c’est à dire si \(N\) est assez grand.
Il y a un seul paramètre à déterminer, la fenêtre (ou constante de lissage) \(h\).
Avantages des méthodes paramétriques :
Si les hypothèses concernant le type de modèle (loi simple ou mélange additif, nature des lois de densité employées) sont valides, il est possible d’obtenir une bonne estimation avec des échantillons de taille comparativement faible. Il est possible d’examiner, lorsque le nombre \(N\) d’observations de \(\mathcal{D}_N\) augmente, à quelle « vitesse » la meilleure estimation de la densité converge vers la vraie densité qui a généré l’échantillon. On peut ainsi montrer que pour l’estimation par noyaux (utilisant aussi une bonne méthode pour déterminer la constante de lissage) la vitesse de convergence est de l’ordre de \(N^{1/5}\) à \(N^{4/5}\), alors que pour l’estimation par modèle de mélange (avec un bon critère pour le choix du nombre de paramètres) la vitesse de convergence est plus élevée, de l’ordre de \(N\).
Après l’estimation du modèle, le coût du calcul de la densité en un point précis est plus faible pour un modèle de mélange que pour un modèle basé sur les noyaux car le modèle de mélange nécessite un nombre de calculs de l’ordre de \(m\) (nombre de composantes) alors que le modèle basé sur les noyaux demande de l’ordre de \(N\) calculs, or \(m \ll N\).
Archambeau, C., M. Valle, A. Assenza, and M. Verleysen. Assessment of probability density estimation methods: Parzen window and finite gaussian mixtures. In ISCAS. IEEE, 2006.
Dempster, A. P., N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B, 39: 1–38, 1977.
Jones, M. C., J. S. Marron, and S. J. Sheather. A brief survey of bandwidth selection for density estimation. Journal of the American Statistical Association, 91(433): 401–407, 1996.
Oliveira-Brochado, A. and F. V. Martins. Assessing the Number of Components in Mixture Models: a Review. FEP Working Papers 194, Universidade do Porto, Faculdade de Economia do Porto, Nov. 2005.
Sheather, S. J., and M. C. Jones. A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. Journal of the Royal Statistical Society. Series B (Methodological), vol. 53, no. 3, [Royal Statistical Society, Wiley], 1991, pp. 683–90.