Les jeux de données en haute dimension posent plusieurs problèmes lorsqu’il s’agit d’en faire une analyse descriptive. D’une part, lorsque le nombre de variables descriptives est grand, il est impossible de visualiser de façon satisfaisante ces données. D’autre part, le fléau de la dimension rend malaisée l’application des méthodes classiques de fouille de données à cause de l’éparsité des observations.
Une solution consiste à ne pas traiter la matrice d’observations originale mais plutôt à la remplacer par une représentation dans un espace de plus petite dimension, tout en conservant l’essentiel de l’information. Deux approches cohabitent :
la sélection de variables, permettant d’éliminer les variables superflues et donc de réduire le nombre de colonnes de la matrice d’observations, qui est étudiée dans le chapitre sur la sélection de variables ;
la réduction de dimension, qui remplace les variables originales par un nouveau jeu de variables plus petit, que nous allons voir ici.
En réalité, la réduction de dimension a déjà été abordée dans le chapitre concernant les méthodes factorielles. L’analyse en composantes principales (ACP) est un des exemples phares de la réduction de dimension : en projetant sur les \(k\) premières composantes principales, il est possible de réduire le nombre de variables décrivant un jeu de données \(\mathbf{X}\), tout en conservant le maximum de l’information (que l’on assimile dans ce cas à la variance).
Toutefois, les méthodes factorielles sont des techniques de réduction de dimension dites linéaires, c’est-à-dire que les variables de l’espace réduit \(\{y_1, y_2, \dots, y_d\} \in \mathcal{Y}\) sont des combinaisons linéaires des variables de l’espace de départ \(\{x_1, x_2, \dots, x_D\}\).
Or, ceci limite grandement les possibilités de réduction de dimension.
Considérons une matrice d’observations \(\mathbf{X}\) de dimension \((n \times D)\), c’est-à-dire à \(n\) observations (lignes) et \(D\) variables descriptives (colonnes).
L’objectif de la réduction de dimension est de déterminer \(\mathbf{\hat{X}}\) de dimensions \((n \times d)\) avec \(d < D\) qui représente bien la structure de \(\mathbf{X}\).
Par structure, on décide notamment de s’intéresser à la propriété suivante : deux observations réduites \({\mathbf{x}'}_i\) et \({\mathbf{x}'}_j\) sont voisines dans l’espace d’arrivée (ou espace réduit) si et seulement si les observations associées \(\mathbf{x}_i\) et \(\mathbf{x}_j\) dans l’espace de départ sont également voisines.
Autrement dit, on souhaite que notre réduction de dimension conserve la notion de voisinage entre les observations. Ce n’est pas le seul critère qui pourrait être imaginé pour conserver l’information contenue dans le jeu de données, mais c’est celui que nous allons utiliser en pratique.
L’algorithme Locally Linear Embedding ou LLE a été introduit par [RS00] en 2000. Le principe est le suivant : localement, le nuage d’observations \(\mathbf{X}\) peut être considéré comme linéaire, c’est-à-dire engendré par un sous-espace affine.
En pratique, LLE considère que chaque observation \(\mathbf{x}_i\) de ce nuage peut-être reconstruite comme une moyenne pondérée de ses voisins \(V_i = \{\mathbf{x}_{i_1}, \mathbf{x}_{i_2}, \dots, \mathbf{x}_{i_k}\}\). Dans l’espace d’arrivée, l’observation réduite correspondante \(\mathbf{y}_i\) doit donc pouvoir être reconstruite par la même combinaison linéaire de ses propres voisins réduits \(\mathbf{y}_{i_1}, \mathbf{y}_{i_2}, \dots, \mathbf{y}_{i_k}\).
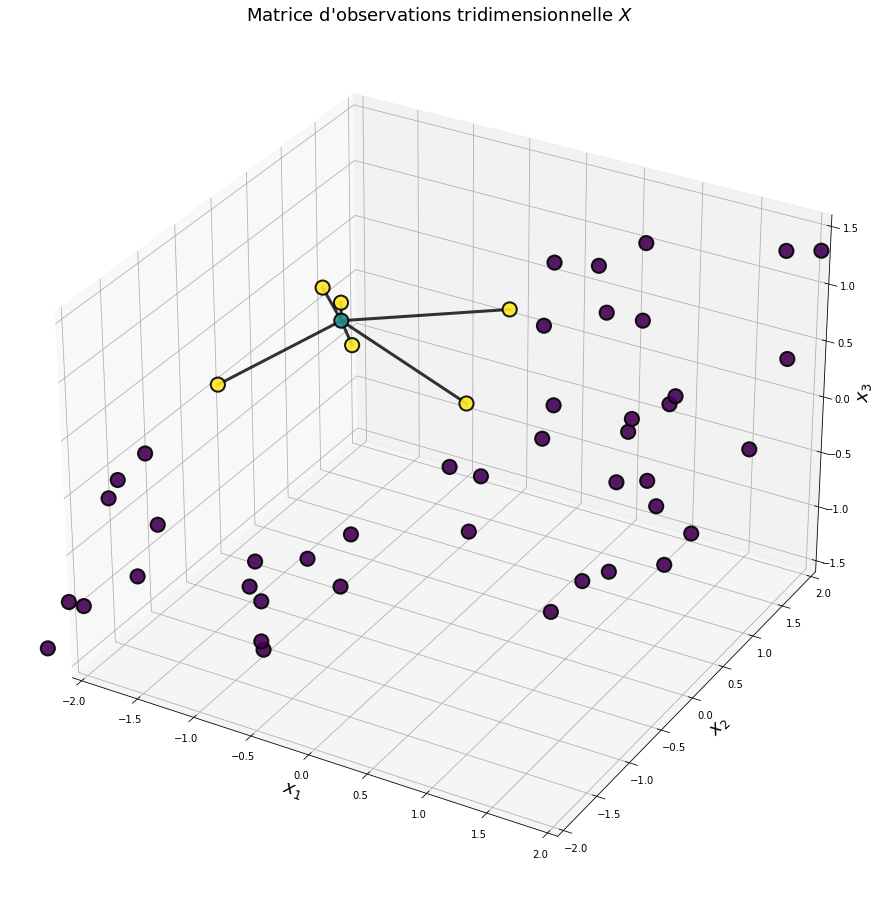
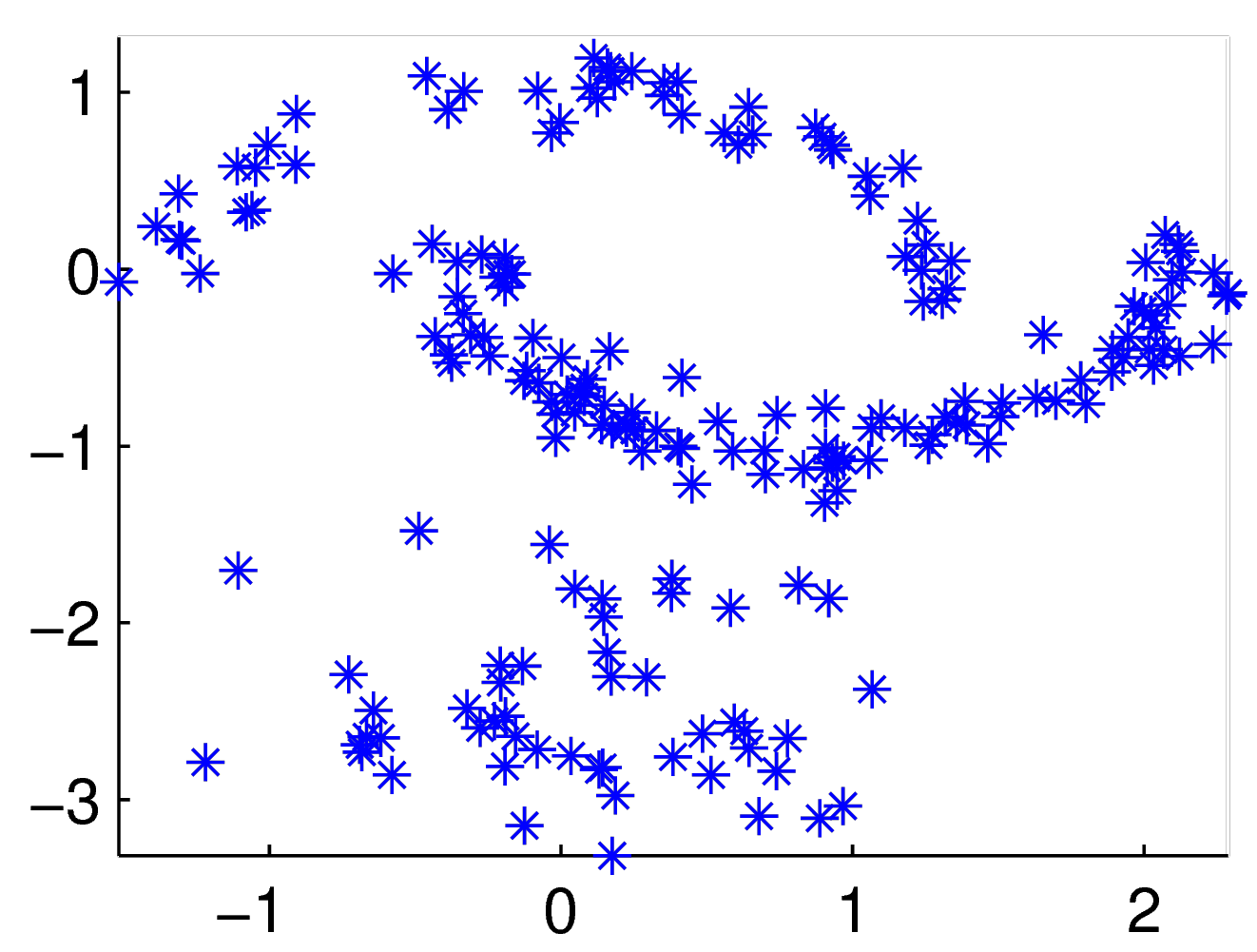
Fig. 108 Un nuage de points composé d’observations à 3 dimensions \(\mathbf{x} = (x_1, x_2, x_3)\). Considérons une observation particulière que l’on note \(\mathbf{x}_i\) (en bleu). Locally Linear Embedding suppose que cette observation peut se reconstruire comme une combinaison linéaire de ses voisins (en jaune) : \(\mathbf{x}_i = \sum_{\mathbf{x}_{j} \in V_i} w_{ij} \mathbf{x}_{j}\). La première étape de LLE consiste à rechercher les valeurs \(w_{ij}\) de pondération de cette combinaison linéaire.¶
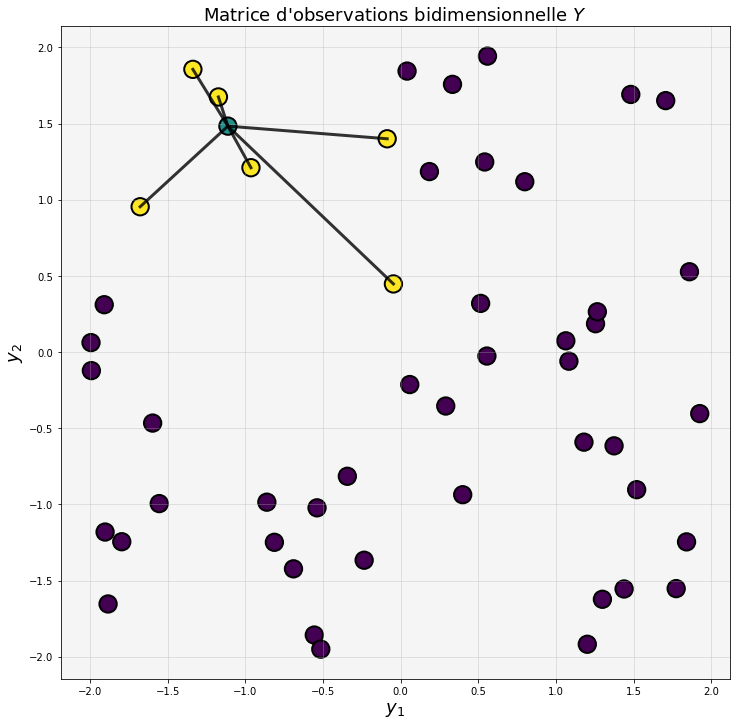
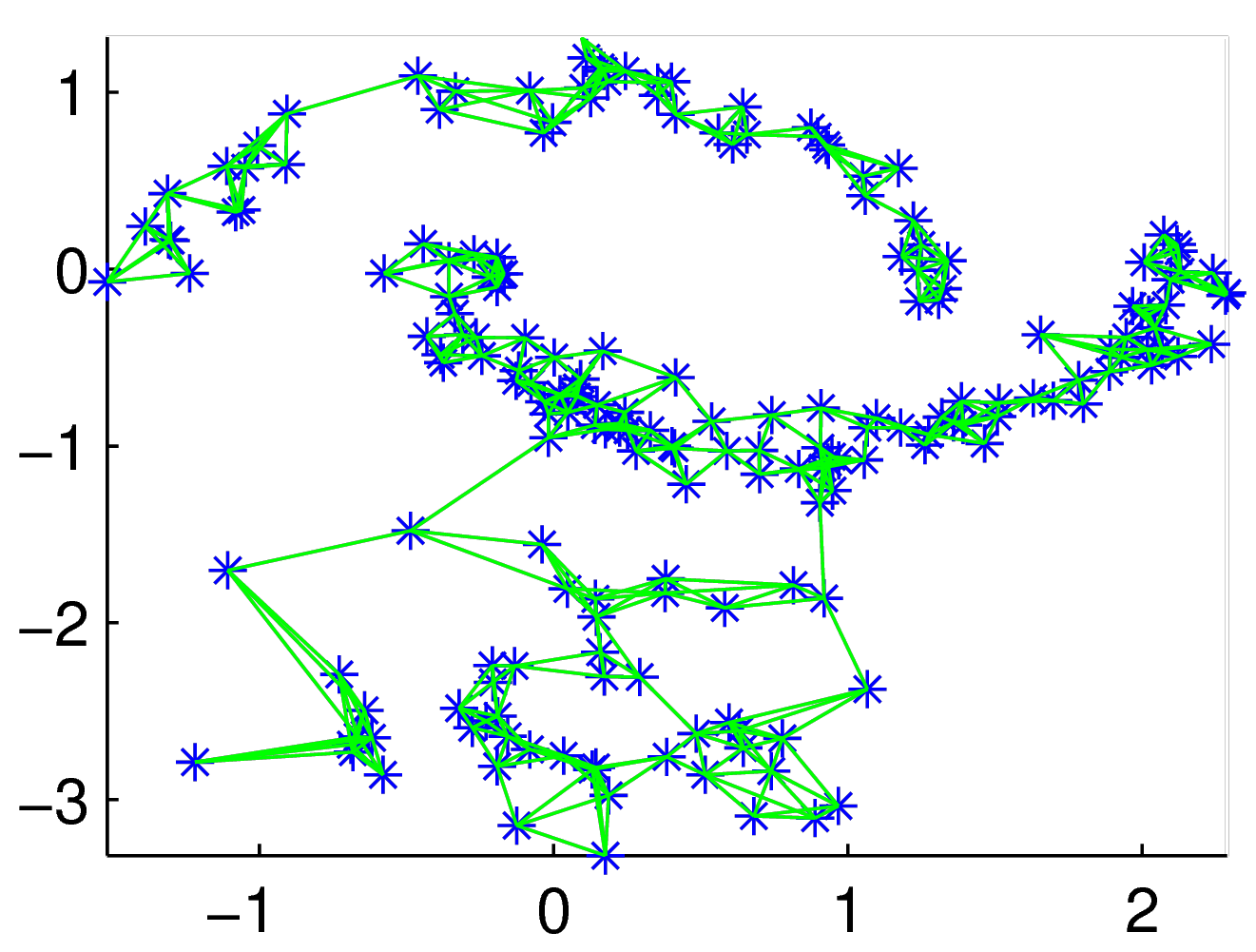
Fig. 109 Dans l’espace réduit à seulement deux dimensions, on cherche comment placer les voisins \(\mathbf{y}_{j}\) (en jaune) de l’observation correspondante \(\mathbf{y}_i^*\) (en bleu) de sorte à la reconstruire par la même combinaison linéaire. La deuxième étape de LLE consiste à déterminer les valeurs des coordonnées des observations réduites \(\mathbf{y}_i^*\) de sorte que \(\mathbf{y}_i^* \approx \sum_{j \, \mathrm{t.q.} \, \mathbf{x}_j \in V_i} w_{ij} \mathbf{y}_{j}^*\). Les pondérations \(w_{ij}\) sont celles déterminées à la première étape.¶
L’algorithme concret est donc le suivant :
Pour chaque point \(\mathbf{x}_i \in \mathbf{X} \subset \mathbb{R}^D\)
trouver ses \(k \geq 2\) plus proches voisins, notés \(V_i = \{\mathbf{x}_{j_1}, \mathbf{x}_{j_2}, \dots, \mathbf{x}_{j_k}\}\);
les plus proches voisins s’obtiennent en comparant les distances euclidiennes entre \(\mathbf{x}_i\) et chaque \(\mathbf{x}_j \in \mathbf{X}\).
Déterminer les coefficients permettant de reconstruire chaque observation par une combinaison linéaire de ses voisins, c’est-à-dire la matrice \(\mathbf{W}^*\) de dimensions \((n \times k)\) telle que
avec les contraintes \(\sum_j w_{ij} = 1\) pour tout \(i\).
Déterminer le nuage de points réduit représenté par la matrice \(\mathbf{Y}^*\) de dimensions \((n \times d)\) qui minimise l’erreur quadratique de reconstruction, c’est-à-dire
ce qui revient déterminer les valeurs des coordonnées des observations réduites \(\mathbf{y}_i\) qui se reconstruisent par les mêmes combinaisons linéaires de leurs voisins correspondants.
Remarquons que dans l’équation (46), la matrice \(\mathbf{W}^*\) des pondérations qui minimise l’erreur de reconstruction est indépendante de l’échelle. En effet, multiplier toutes les coordonnées par une constante \(\lambda\) multiplie les distances par ce même facteur, mais ne change pas les relations de voisinages. Il existe donc une infinité de solutions possibles, toutes les matrices de type \(\lambda \mathbf{W}^*\). La contrainte \(\sum_j w_{ij} = 1\) permet d’assurer l’unicité de la solution.
Le problème décrit par l’équation (46) est un problème d’optimisation aux moindres carrés. Ce problème admet une solution analytique qui s’obtient directement à partir de la matrice de covariance locale calculée sur le \(k\)-voisinage de \(\mathbf{x}_i\).
Le problème décrit par l’équation (47) se résoud quant à lui par le calcul des vecteurs propres d’une matrice bien choisie, dépendant uniquement de \(\mathbf{W}^*\).
Pour plus de détails concernant ces deux étapes d’optimisation, consulter les annexes A et B de [SR00].
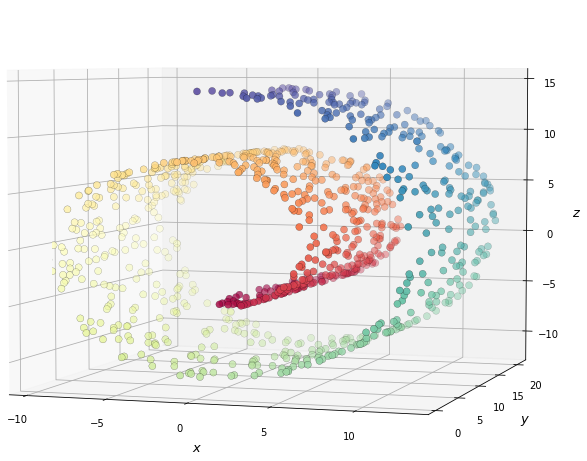
Pour mieux comprendre l’effet de Locally Linear Embedding, nous pouvons prendre un exemple-jouet régulièrement utilisé en réduction de dimension. Le « Gâteau roulé » (ou Swiss Roll, roulé suisse) est un jeu de données contenant des observations en trois dimensions. Néanmoins, bien qu’en trois dimensions, ce jeu de données peut être « déroulé » sur un plan bidimensionnel. Il existe donc une représentation naturelle de ce jeu de données à trois variables dans une version à seulement deux variables.
Fig. 110 Le jeu de données du « Gâteau roulé » (Swiss Roll) représente un rectangle 2D enroulé sur lui-même. Les couleurs permettent d’identifier les voisinages et ne sont présentes qu’à titre indicatif.¶
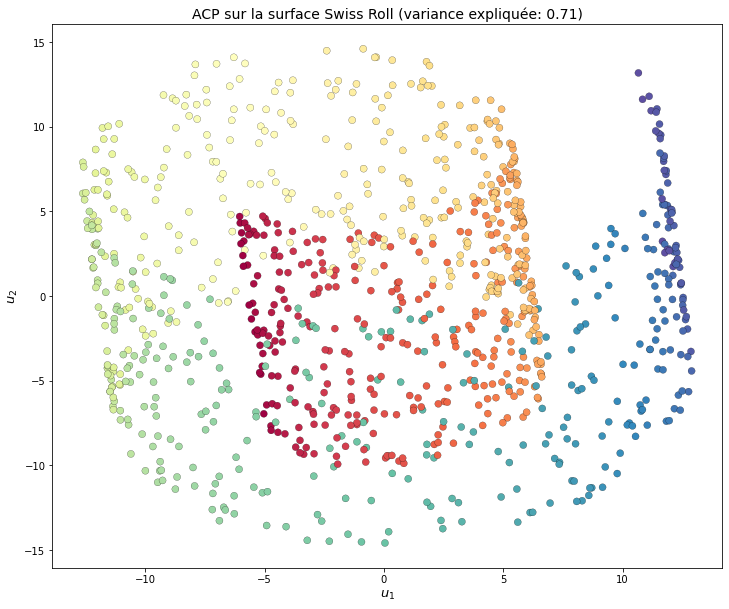
À titre de comparaison, nous pouvons appliquer une analyse en composantes principales (ACP) sur le Swiss Roll. Les directions qui expliquent le plus de variance sont néanmoins assez peu représentatives. En effet, la transformation qui permet de passer du gâteau roulé à trois dimensions à son alter ego déroulé n’est pas linéaire et l’ACP ne permet donc pas de construire une projection l’approchant.
Fig. 111 L’analyse en composantes principales sur le gâteau roulé extrait les directions qui expliquent le plus la variance. La troisième dimension est masquée. Les voisins sont globalement peu préservés. La réduction de dimension « idéale » n’étant pas linéaire, l’ACP ne répond pas au besoin.¶
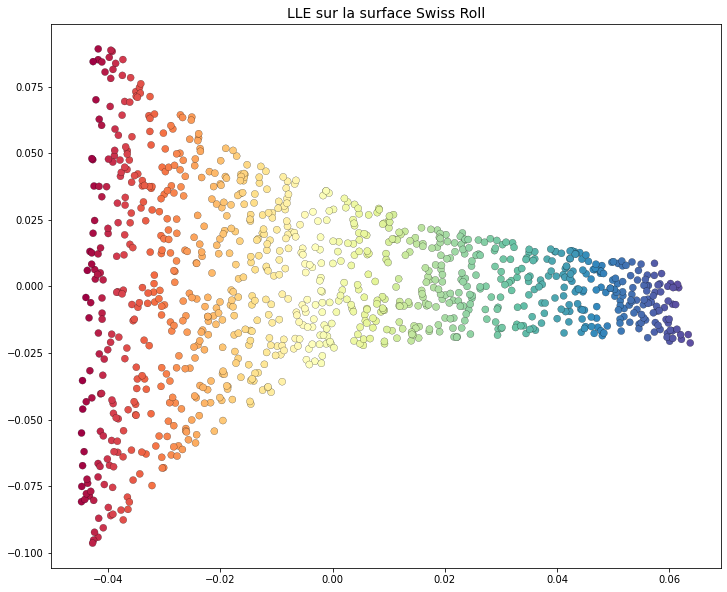
L’application de l’algorithme LLE permet toutefois d’obtenir une projection qui n’est que localement linéaire. Cet algorithme de réduction de dimension a donc une plus grande expressivité et permet de dérouler de façon satisfaisante le Swiss Roll. Par rapport à l’ACP, il est important de noter que LLE conserve les relations de voisinage : des observations voisines dans l’espace de départ demeurent voisines lorsqu’elles sont projetées dans l’espace réduit. Cette propriété est généralement celle que l’on cherche à conserver quand on s’intéresse à la réduction de dimension non-linéaire.
Fig. 112 L’application de Locally Linear Embedding permet de « dérouler » la surface du jeu de données. L’approche par voisinage permet de passer de proche en proche en respectant la structure locale (linéaire).¶
Le plongement dans l’espace à deux dimensions de la Fig. 112 illustre une notion particulièrement importante de la réduction non-linéaire de dimension. Notre objectif est de préserver la structure locale du jeu de données et, tout particulièrement, les relations de voisinage. LLE ne préserve donc pas les distances. C’est la raison pour laquelle nous observons cet effet « d’entonnoir ». Les points rouges sont plus éloignés les uns des autres que les points violets. Néanmoins, les voisinages sont invariants à l’échelle. Il n’y a donc aucune conclusion à en tirer. D’ailleurs, dans le roulé suisse de départ, les points rouges ne sont pas plus éloignés que les points bleus. Ce type de distorsion est fréquent dans les visualisations obtenues par LLE et ne doit pas être interprété comme représentatif de la structure des données. Seules les relations de voisinages (et donc la structure locale) est préservée par cet algorithme.
Représenter le voisinage d’un point par ses \(k\) plus proches voisins présente deux inconvénients. D’abord, là où les observations sont très denses les \(k\) plus proches voisins sont très proches alors que là où les observations sont peu denses les \(k\) plus proches voisins sont très éloignés, l’échelle des similarités conservées n’est pas du tout la même. Ensuite, cette séparation stricte entre voisins, pris en compte totalement, et non voisins, totalement ignorés, introduit des fragilités dans l’opération de réduction de dimension. Définir le voisinage par un rayon plutôt que par une valeur de \(k\) permet de conserver l’échelle et répond ainsi au premier inconvénient mais pas au second.
t-SNE[MH08] est un algorithme de réduction de dimension non-linéaire particulièrement populaire. Son principe général est similaire à celui de LLE : chercher un jeu de données dans un espace de dimension réduite qui présente les mêmes structures locales au voisinage de chaque point. Cependant, t-SNE généralise la notion de voisinage déterministe de LLE à une notion probabiliste. On cherchera non plus à conserver les voisins d’une observation, mais plutôt à conserver les probabilités que d’autres observations lui soient voisines. Nous présentons d’abord brièvement Stochastic Neighbor Embedding (SNE, [HR02]), qui introduit les idées principales, avant de décrire les évolutions présentes dans t-SNE.
Voisinages et probabilités : Stochastic Neighbor Embedding¶
Considérons une matrice d’observations \(\mathbf{X}\) de \(n\) observations de dimensions \(D\). Représentons le voisinage d’un point \(\mathbf{x}_i \in \mathbf{X}\) par une probabilité conditionnelle \(p_{j|i} = p(\mathbf{x}_j|\mathbf{x}_i)\) pour toute autre observation \(\mathbf{x}_j \in \mathbf{X}\), qu’on peut voir comme la probabilité que \(\mathbf{x}_j\) soit considéré un voisin de \(\mathbf{x}_i\). Cette valeur devra être entre 0 et 1 et décroître avec la distance entre \(\mathbf{x}_i\) et \(\mathbf{x}_j\).
L’objectif de Stochastic Neighbor Embedding (SNE, [HR02]) est de déterminer le nuage de points représenté par les observations réduites \(\mathbf{y}_i\) de telle sorte que \(p(\mathbf{y}_j|\mathbf{y}_i) \simeq p(\mathbf{x}_j|\mathbf{x}_i)\) pour tous les couples \((i,j)\).
Dans SNE la valeur de \(p_{j|i}\) est définie de la façon suivante :
avec par convention \(p_{i|i} = 0\) (\(\mathbf{x}_i\) n’est pas voisin de lui-même).
Le dénominateur de l’équation (48) permet de normaliser les probabilités conditionnelles de sorte que \(\sum_j p_{j|i} = 1\) pour tout \(i\).
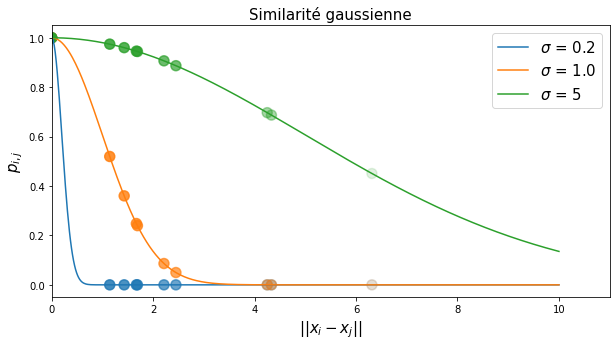
Le numérateur correspond à la similarité entre \(\mathbf{x}_i\) et \(\mathbf{x}_j\), représentée par la valeur de la densité d’une gaussienne (ou loi normale) centrée en \(\mathbf{x}_i\). Intuitivement, cela revient donc à placer un noyau gaussien d’écart-type \(\sigma\) centré sur l’observation \(\mathbf{x}_i\). Plus \(\sigma\) est faible, plus la probabilité décroît rapidement avec la distance entre \(\mathbf{x}_i\) et \(\mathbf{x}_j\).
Fig. 113 Valeur de la similarité gausienne en fonction de la distance euclidienne entre \(\mathbf{x}_i\) et \(\mathbf{x}_j\).¶
Le choix de \(\sigma\) peut être fait en fonction du nombre approximatif de voisins qu’on souhaite considérer pour chaque observation. Une évaluation continue de ce nombre est donnée par la perplexité définie, pour une distribution discrète de probabilités \(P_i\), par
\(H(P_i)\) étant l’entropie de la distribution \(P_i\). En considérant que \(P_i\) est la distribution des valeurs \(p_{j|i}\) (pour \(i\) fixé), nous pouvons constater que l’entropie \(H(P_i)\) augmente avec le rapprochement des valeurs des \(p_{j|i}\). Si les valeurs des \(p_{j|i}\) sont issues, comme ci-dessus, d’une loi normale d’écart-type \(\sigma\), alors l’augmentation de \(\sigma\) mène à une augmentation de l’entropie \(H(P_i)\) (car la gaussienne s’aplatit) et donc de la perplexité. Cette proportionalité entre \(\sigma\) et \(Perp(P_i)\) fait que parfois c’est \(\sigma\) (ou \(\sigma^2\)) qui est appelé « perplexité », comme dans [HR02] p.7.
Comme pour LLE, nous cherchons donc désormais une matrice réduite \(\mathbf{Y}\), de dimension \(d < D\), de sorte que les probabilités conditionnelles \(q_{j|i} = p(\mathbf{y}_j|\mathbf{y}_i)\) soient les plus proches possible des \(p_{j|i}\). Ici les points \(\mathbf{y}_i\) sont les images des observations de départ \(\mathbf{x}_i\) dans l’espace de dimension réduite que nous appelons aussi espace d’arrivée. Dans SNE ces probabilités sont définies par
ce qui revient à employer un noyau gaussien d’écart-type \(\sigma = \frac{1}{\sqrt{2}}\) dans l’espace d’arrivée. Une autre valeur de cet écart-type produirait simplement un changement d’échelle dans les résultats.
Une mesure usuelle de l’écart entre deux distributions de probabilité est la divergence de Kullback-Leibler. Si on note par \(P_i\) la distribution des probabilités conditionnelles dans l’espace de départ, \(p_{j|i}\), et par \(Q_i\) celle des probabilités conditionnelles dans l’espace d’arrivée, \(p_{j|i}\), la divergence de Kullback-Leibler entre les deux est
On peut montrer que cette mesure s’annule si et seulement si \(p_{j|i} = q_{j|i}\) pour tout \(j\).
SNE minimise la somme sur toutes les observations de ces divergences de Kullback-Leibler entre les distributions conditionnelles de l’espace de départ et celles de l’espace d’arrivée :
Cette minimisation est faite en utilisant la descente de gradient, une méthode itérative d’optimisation continue qui consiste à appliquer de petites modifications successives aux paramètres (ici les \(\mathbf{y}_i\)) du critère optimisé (ici \(L\)), dans le sens opposé au gradient du critère par rapport aux paramètres, jusqu’à l’atteinte d’un minimum de ce critère. Dans le chapitre Réseaux de neurones multicouches nous regardons de plus près la descente de gradient et son application aux réseaux de neurones.
t-SNE a été introduit dans [MH08] pour pallier à deux insuffisances de SNE, qui sont la complexité du problème d’optimisation et l”« agglutinement ».
La première évolution est l’emploi dans t-SNE de distributions de probabilités jointes pour représenter les relations de voisinage et la minimisation d’une divergence de Kullback-Leibler unique entre ces distributions :
où on considère encore que \(p_{ii} = q_{ii} = 0\). Les probabilités jointes dans l’espace d’arrivée (de dimension réduite) seraient ainsi obtenues par :
On constate qu’au dénominateur la somme est faite sur toutes les paires de points distincts, afin de garantir la condition de normalisation.
Les auteurs considèrent que dans l’espace de départ l’équation equivalente engendre des difficultés pour bien contraindre la représentation des observations isolées et proposent plutôt d’employer
où \(n\) est le nombre d’observations et les \(p_{i|j}, p_{j|i}\) sont obtenues par l’équation de SNE (48).
La seconde évolution introduite dans t-SNE vise à résoudre le problème de l”« agglutinement ». Examinons la signification de ce problème et la solution apportée dans t-SNE.
La gaussienne, utilisée pour définir les \(p_{ij}\) et \(q_{ij}\), est une loi à décroissance rapide. Cela permet de facilement distinguer les voisins (données proches de \(\mathbf{x}_i\)) des non-voisins, pour qui la similarité sera quasi-nulle compte-tenu de la décroissance rapide de la gaussienne.
Cette propriété est utile dans l’espace de départ mais moins dans l’espace d’arrivée. Afin de voir pourquoi, supposons que l’on souhaite projeter les données dans un plan, donc un espace à deux dimensions, pour la visualisation. Si l’on utilise une similarité gaussienne, alors les voisins sont agglutinés pour être dans la zone non-nulle de la gaussienne. En effet, pour un même nombre de points, il y a moins de « volume » disponible en 2D que dans un espace à \(n\) dimensions. Les points qui sont voisins se retrouvent placés très proches les uns des autres, tandis que les non-voisins peuvent être placés n’importe où ailleurs, puisque la similarité vaut de toute façon zéro. Autrement dit, en utilisant une similarité gaussienne dans l’espace d’arrivée, on risque de produire une visualisation avec de nombreux points qui se chevauchent, séparés par de grandes régions vides. On appelle ce problème « agglutinement » (ou crowding).
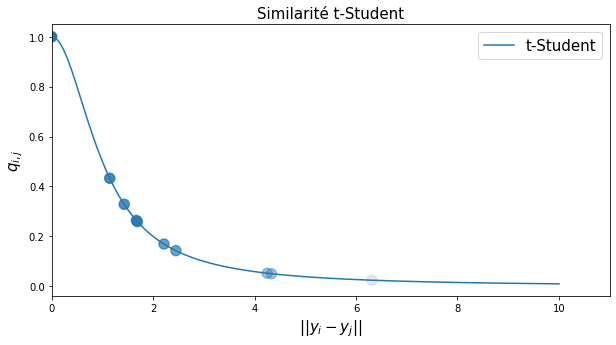
Pour éviter ce problème d’agglutinement, t-SNE emploie une autre définition de la probabilité conditionnelle dans l’espace réduit, qui encourage les points à se disperser dans le plan. Plutôt qu’employer une gaussienne (ou loi normale) comme dans l’équation (51), la similarité pour les observations réduites \(\mathbf{y}_i\) s’appuie alors sur une loi \(t\) (Student) à 1 degré de liberté (qui est d’ailleurs une loi de Cauchy) et s’écrit :
Fig. 114 Valeur de la similarité t (Student) en fonction de la distance euclidienne entre \(\mathbf{y}_i\) et \(\mathbf{y}_j\).¶
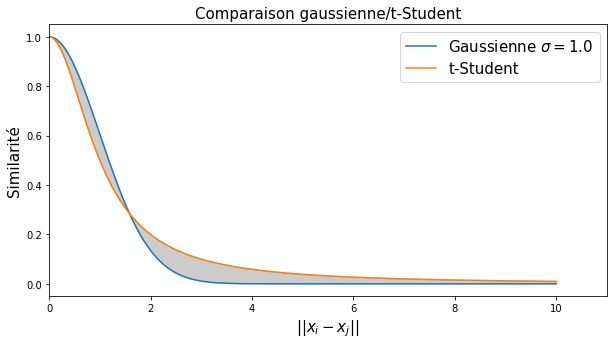
Cette fonction exhibe une décroissance assez rapide à proximité de l’espérance (mais moins rapide que la gaussienne) pour distinguer les voisins des non-voisins, mais assez lente au-delà pour mieux répartir les points dans l’espace d’arrivée, cf. Fig. 115.
Fig. 115 Comparaison de la similarité gaussienne et la similarité Student.¶
Dans t-SNE, nous voulons rapprocher les distributions \(p_{ij}\) et \(q_{ij}\). Comme nous venons de le voir, il suffit de minimiser leur divergence de Kullback-Leibler pour atteindre cet objectif. Pour ce faire, nous pouvons utiliser un algorithme de descente de gradient sur les points \(\mathbf{y}_i\) :
Pour chaque paire de points \((\mathbf{x}_i, \mathbf{x}_j)\), calculer les probabilités suivant les équations (52) et (48).
Initialisation : Placer aléatoirement les \(n\) points réduits \(\mathbf{y}_1, \mathbf{y}_2, \dots, \mathbf{y}_n\) dans l’espace de dimension \(d\).
Répétertantque l’optimisation n’a pas convergé et que le nombre maximal d’itérations n’est pas atteint :
Calculer les probabilités \(q_{ij}\) par l’équation (51).
Calculer le gradient de la divergence de Kullback-Leibler par rapport à \(\mathbf{y}_i\) :
Déplacer chaque point \(\mathbf{y}_i\) en suivant la plus forte pente dans le sens opposé au gradient (= descente de gradient) avec un pas \(\alpha > 0\) :
Le calcul permettant d’obtenir l’expression analytique du gradient de la fonction de coût, \(\frac{\partial L}{\partial \mathbf{y}_i}\), est détaillé dans l’annexe A de [MH08].
Autres fonctions de similarité
Remarquons que l’étape 1 de l’algorithme peut être ignorée s’il existe déjà une matrice de similarités \(\mathbf{S} = (p_{ij})\) pré-calculée sur le jeu de données. En pratique, il n’est donc pas indispensable d’utiliser la similarité gaussienne définie par (48). N’importe quelle métrique de similarité peut être employée pour construire la matrice des probabilités conditionnelles. Le module TSNE de Scikit-learn accepte notamment de nombreuses métriques, non nécessairement euclidiennes, et il est même possible de passer une matrice de similarité arbitraire précalculée. Cela peut être utile pour appliquer t-SNE sur des données mixtes, en utilisant une fonction ad hoc capable notamment de définir une similarité pour des variables non quantitatives.
Comme toutes les méthodes par descente de gradient, l’algorithme d’optimisation de t-SNE est sensible à son initialisation. Le placement initial des points \(\mathbf{y}_i\) étant aléatoire, les résultats obtenus par application de t-SNE peuvent fortement varier d’une exécution à une autre.
Par ailleurs, t-SNE ne préserve que les voisinages. C’est donc un algorithme qui se concentre sur la structure locale, au détriment de la préservation de la structure globale.
Pour pallier ces deux limitations, une alternative consiste à appliquer d’abord une analyse en composantes principales et conserver seulement les \(d\) premières composantes. Le nuage de points projeté peut ainsi servir d’initialisation aux observations réduites \(\mathbf{y}_i^0\) avant la phase d’optimisation par descente de gradient. D’un point de vue théorique, cette initialisation a deux avantages :
Une meilleure préservation de la structure globale grâce à l’ACP.
Une plus grande reproductibilité en supprimant la stochasticité liée à l’initialisation.
En pratique, cette initialisation est plus robuste et elle est généralement appliquée par défaut dans les bibliothèques qui implémentent t-SNE.
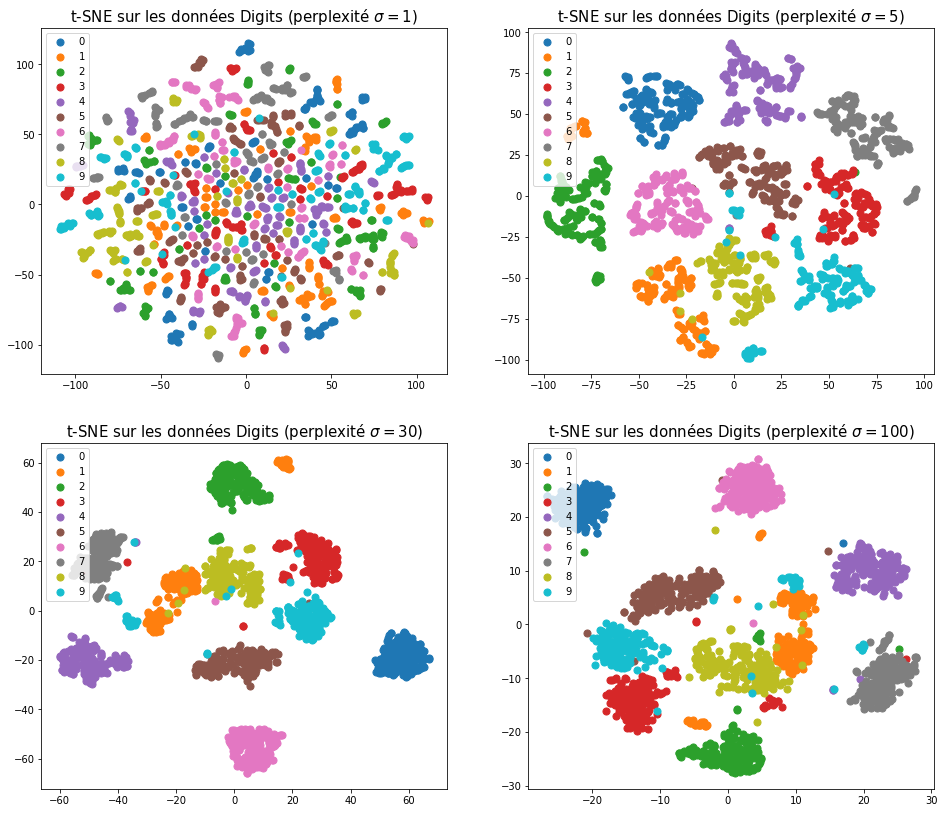
La perplexité est le principal paramètre à régler lors de l’application de t-SNE.
Une perplexité faible restreint fortement les observations qui sont définies comme voisines l’une de l’autre. Seules des observations très proches peuvent avoir une similarité non-nulle. Cela accentue la préservation de la structure locale au détriment de la structure globale. À l’inverse, une perplexité élevée inclut presque toutes les observations dans le voisinage de toutes les autres, à l’exception des plus éloignées. Cela permet ainsi de mieux capturer la structure globale du nuage de points, au détriment des détails locaux, comme illustré dans la Fig. 117.
Fig. 116 Exemple de digits manuscrits représentés par des matrices de 8x8 pixels¶
Fig. 117 Application de t-SNE sur le jeu de données Digits pour différentes valeurs de perplexité.¶
En pratique, il est recommandé d’expérimenter plusieurs valeurs de perplexité et de croiser les interprétations au niveau local et au niveau global.
L’algorithme décrit plus haut pour t-SNE passe sous silence une astuce d’implémentation qui permet d’accélérer la convergence de la descente de gradient. En pratique, t-SNE est implémenté en deux phases :
Une phase dite d’exagération précoce (early exaggeration), durant laquelle toutes les probabilités conditionnelles \(p_{ij}\) dans l’espace initial sont multipliées par un facteur \(\gamma\). Cela permet d’augmenter artificiellement, dans cette première étape, la séparation des groupes naturellement présents dans les données et de placer plus rapidement les observations réduites \(\mathbf{y}_i\) près de leur position optimale. Il faut noter que dans le calcul du gradient (54) ce sont surtout les différences entre les valeurs \(p_{ij}\) les plus élevées (associées aux voisins les plus proches) et les \(q_{ij}\) correspondants qui comptent ; lorsqu’on multiplie tous les \(p_{ij}\) par \(\gamma\), cela augmente l’écart entre les valeurs \(p_{ij}\) les plus élevées et les autres valeurs \(p_{ij}\), donc les valeurs \(p_{ij}\) les plus élevées ont encore plus d’impact sur le gradient lors des premières itérations de l’algorithme.
Une phase d’optimisation finale durant laquelle les valeurs réelles des probabilités conditionnelles sont utilisées, pour affiner le placement des observations réduites localement au sein de chaque groupe.
Des heuristiques plus ou moins sophistiquées existent afin de déterminer les valeurs des paramètres d’exagération et du pas d’apprentissage, comme celles décrites dans [BCA19]. Il n’est généralement pas utile de modifier ces paramètres.
En pratique, l’exagération précoce est appliquée pendant 250 itérations de la descente de gradient, puis l’optimisation se poursuit avec les valeurs normales des probabilités conditionnelles jusqu’à atteindre le critère d’arrêt (convergence ou nombre d’itérations maximal).
Pour mieux appréhender la flexibilité mais aussi les possibles erreurs d’interprétation des visualisations obtenues vec t-SNE il est utile de regarder les expériences proposées sur ce site.
UMAP : Uniform Manifold Approximation and Projection for Dimension Reduction¶
UMAP (Uniform Manifold Approximation & Projection) [MHM18] est un algorithme de réduction non-linéaire de dimension dont le principe est semblable à celui de t-SNE. Comme précédemment, nous recherchons une représentation des données en plus faible dimension qui présente la même topologie que le nuage des observations dans l’espace de départ. Pour ce faire, nous construisons une matrice des similarités entre les points dans l’espace de départ, puis nous cherchons l’ensemble des points dans l’espace d’arrivée qui vérifie le même graphe de similarité. La principale différence entre t-SNE et UMAP vient de leur définition de cette notion de similarité :
UMAP emploie une perplexité variable, qui dépend de la densité autour de chaque point, pour définir la similarité ;
UMAP considère une famille de fonctions de similarité plus large, inspirée de la loi \(t\) de Student, pour l’espace réduit.
\(k\) est un paramètre réglant le nombre de plus proches voisins à considérer, c’est-à-dire la taille du voisinage envisagé.
Cette similarité s’appuye donc sur un écart-type adaptatif pour le noyau gaussien, avec deux différences par rapport à t-SNE :
la similarité ne commence à décroître qu’au-delà du plus proche voisin (lorsque la distance \(d(\mathbf{x}_i, \mathbf{x}_j) > \rho_i\)),
la largeur du noyau (\(\sigma\)) dépend de la densité du voisinage : pour une même valeur de \(k\), dans un voisinage dense (beaucoup de points sont très proches de \(\mathbf{x}_i\)) l’équation (56) indique que la valeur de \(\sigma_i\) doit être plus faible que si le voisinage avait été moins dense (voisins plus éloignés de \(\mathbf{x}_i\)).
Note
Nous employons ici des notations \(p\) pour des similarités afin de les mettre en relation avec les mesures correspondantes dans t-SNE. Mais pour UMAP ces similarités ne sont pas des probabilités car les conditions de normalisation ne sont pas respectées.
Pour deux points \(\mathbf{x}_i\) et \(\mathbf{x}_j\), la similarité jointe \(p_{ij}\) devrait être symétrique (\(p_{ij} = p_{ji}\)). Dans UMAP cette symétrisation est obtenue grâce à la définition suivante :
La symétrisation est nécessaire car \(\rho_i \neq \rho_j\).
Pour rappel, t-SNE utilise une autre symétrisation : \(p_{ij} = \frac{p_{i|j} + p_{j|i}}{2n}\).
Comme pour t-SNE, on souhaite éviter l’agglutinement des points dans l’espace d’arrivée : de faibles variations de similarité dans l’espace de départ doivent correspondre à des variations plus significatives de distance dans l’espace d’arrivée pour éviter l’agglutinement malgré la réduction de dimension. Cela revient à s’appuyer sur une distribution à décroissance lente pour définir les similarités dans l’espace d’arrivée.
La solution adoptée par UMAP consiste à s’inspirer de la loi \(t\) de Student pour définir la similarité dans l’espace d’arrivée :
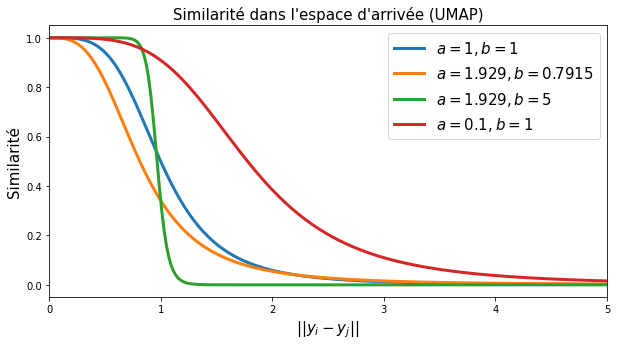
\[q_{ij} = \frac{1}{1 + a \|\mathbf{y}_i - \mathbf{y}_j\|^{2b}}\]
\(a\) et \(b\) étant des paramètres réglables. En pratique, la fonction idéale n’autoriserait jamais deux points dans l’espace d’arrivée à être plus proches qu’une certaine distance minimale min_dist. Sur le segment \([0, \text{min_dist}]\) la similarité serait considérée comme égale à 1, ensuite on tolérerait une décroissance exponentielle douce de la similarité. Cela correspond à une fonction définie par morceaux :
En pratique, c’est le paramètre min_dist que l’on peut régler dans UMAP. Dans la définition de la similarité, le choix des paramètres \(a\) et \(b\) est ainsi fait automatiquement de sorte que la similarité qui en résulte soit la plus proche possible de cette fonction idéale définie par morceaux. L’illustration suivante montre la variation de la similarité dans l’espace réduit suivant les paramètres \(a\) et \(b\).
Fig. 119 Similarité dans l’espace réduit (ou d’arrivée) suivant les paramètres de la fonction employée.¶
L’objectif est de trouver les points \(\mathbf{y}_i\) dans l’espace d’arrivée tels que les similarités \(q_{ij}\) s’approchent le plus possibles des similarités \(p_{ij}\). Autrement dit, on souhaite faire tendre les similarités \(q\) vers les similarités \(p\).
Pour UMAP cela est réalisé en minimsant une fonction objectif d’entropie croisée floue (fuzzy cross-entropy), qui mesure l’écart entre les deux distributions de similarités \(p\) et \(p\) :
L’entropie croisée floue est une extension de l’entropie croisée (définie au départ pour mesurer l’écart entre distributions de probabilités) au cas où les valeurs considérées (les \(p_{ij}\) et \(q_{ij}\)) sont individuellement entre 0 et 1 mais ne respectent pas les conditions de normalisation.
En développant les logarithmes, cette fonction objectif peut être écrite :
Le premier terme dépend uniquement des données de l’espace de départ et ne peut donc pas être modifié. Pour minimiser l’entropie croisée floue, seul le second terme est donc minimisé en modifiant les \(\mathbf{y}_i\) (les projections dans l’espace d’arrivée) et donc les \(q_{ij}\).
Contrairement à t-SNE qui minimise la fonction objectif par descente de gradient directe en calculant la fonction à optimiser sur l’ensemble des données, UMAP accélère le calcul en réalisant une descente de gradient stochastique et estime l’entropie croisée sur un échantillon de quelques dizaines ou quelques centaines de points. L’échantillon est construit de sorte à contenir un mélange de voisins (\(p_{ij} \simeq 1\)) et de non-voisins (\(p_{ij} \simeq 0\)) afin d’optimiser simultanément les composantes de l’entropie croisée.
La mise à jour des points dans l’espace d’arrivée se fait (de manière analogue à t-SNE) par :
où \(\alpha\) est le pas d’apprentissage de l’algorithme de descente de gradient. Le gradient \(\frac{\partial \text{CE}}{\partial \mathbf{y}_i}\) dispose d’une expression analytique.
Données : nuage de points \(\mathcal{E} = \{\mathbf{x}_i\}_{1 \leq i \leq N}\), nombre de plus proches voisins \(k\), dimension de l’espace d’arrivée \(d\), paramètres \((a,b)\) de la similarité \(q_{ij}\)
Sortie : nuage de points réduit \(\mathcal{F} = \{\mathbf{y}_i\}_{1 \leq i \leq N}\)
Déterminer pour chaque point \(\mathbf{x}_i\) ses \(k\) plus proches voisins
Calculer \(p_{ij}\) pour toutes les paires \((i,j)\)
Initialiser les points \(\mathcal{F} = \{\mathbf{y}_i\}\) à l’aide d’un plongement spectral dans \(\mathbb{R}^d\)
Répétertantque l’entropie croisée \(\operatorname{CE} \geq \varepsilon\) et l’algorithme n’a pas convergé :
Tirer aléatoirement un échantillon uniforme de \(m\) observations \(\mathbf{x}_i\)
Calculer \(q_{ij}\) pour les points de l’échantillon des \(\mathbf{y}_i\) correspondants
Calculer \(\operatorname{CE}(p,q)\) sur cet échantillon
Déplacer chaque point \(\mathbf{y}_i\) par : \(\mathbf{y}_i := \mathbf{y}_i - \alpha \frac{\partial \operatorname{CE}}{\partial \mathbf{y}_i}\)
Fintantque
Comme pour t-SNE, l’initialisation des points dans l’espace d’arrivée peut avoir un impact significatif sur le résultat de UMAP. Dans le cas de t-SNE avec early exaggeration il a été observé que la première phase de l’algorithme revient approximativement à réaliser un plongement spectral [LS19]. L’initialisation par défaut choisie pour UMAP consiste donc à réaliser directement un plongement spectral, méthode décrite dans la section Compléments : plongement spectral. Ce choix présente deux avantages : plus de déterminisme dans l’initialisation et convergence plus rapide de la descente de gradient stochastique.
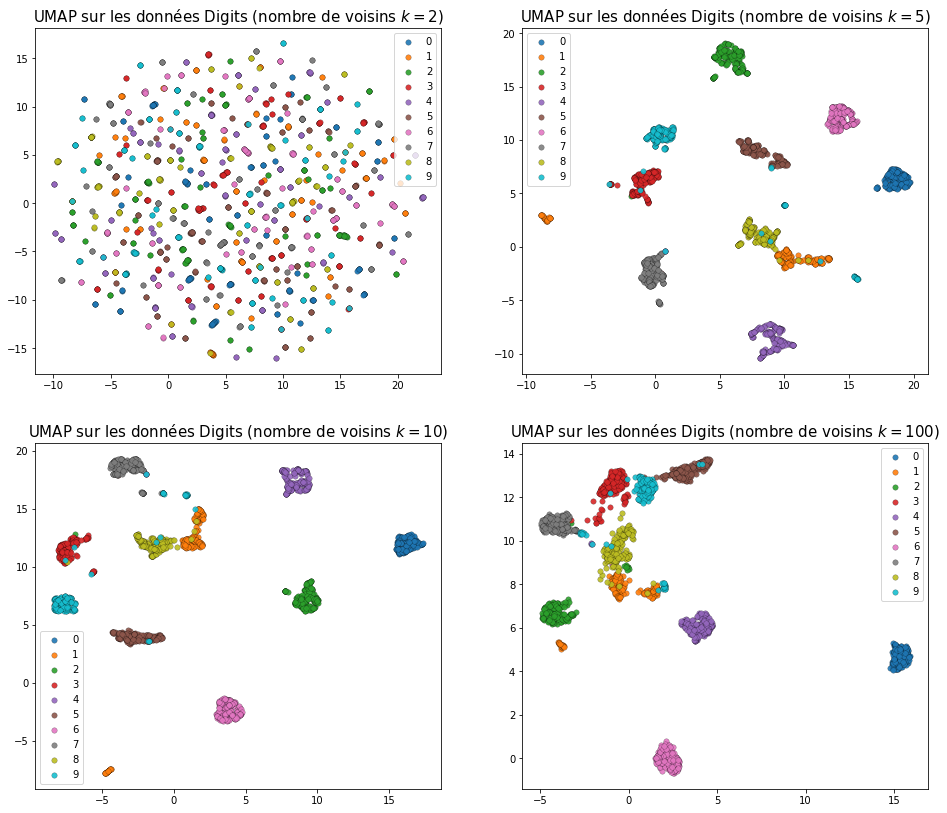
Les paramètres de la méthode UMAP sont la dimension (n_components) de l’espace euclidien réduit (ou d’arrivée), le nombre de voisins à considérer pour définir la similarité adaptative (n_neighbours) et la distance minimale autorisée entre deux points dans l’espace d’arrivée (min_dist).
La dimension de l’espace réduit dépend de l’objectif de la réduction : pour la visualisation cette dimension sera de 2 ou 3, alors que pour une modélisation ultérieure la dimension peut être plus élevée.
Les illustrations suivantes permettent de voir l’effet de la variation des valeurs pour n_neighbours et respectivement min_dist :
Fig. 120 Variation des résultats obtenus avec UMAP pour différentes valeurs de n_neighbours (avec min_dist = 0,1)¶
Fig. 121 Variation des résultats obtenus avec UMAP pour différentes valeurs de min_dist (avec n_neighbours = 5)¶
Nous pouvons constater que les résultats sont relativement robustes à la variation du nombre de voisins à considérer (n_neighbours). Une trop faible valeur pour le nombre de voisins conserve uniquement les relations avec les plus proches voisins et disperse les groupes (comme une valeur trop faible de la perplexité pour t-SNE). Une augmentation du nombre de voisins fait augmenter la taille des voisinages et permet de tenir compte également de l’organisation des données dans des voisinages plus grands. L’augmentation de min_dist permet d’éviter la superposition des observations dans l’espace réduit ; une augmentation trop forte peut dénaturer la visualisation des relations entre voisins plus éloignés.
Une contribution intéressante en pratique de UMAP est l’extension de la notion de similarité pour prendre en compte d’éventuelles connaissances a priori sur les données. Considérons un jeu de données contenant des étiquettes de groupes: \(\mathcal{X} = \{(\mathbf{x}_1, l_1), \dots, (\mathbf{x}_n, l_n)\}\) avec \(\mathbf{x}_i\) les observations et \(l_i\) les étiquettes (modalités d’une variable catégorielle).
Pour inclure la connaissance des étiquettes dans l’algorithme, UMAP définit une distance mixte sur le couple \((\mathbf{x}_i, l_i)\) :
où \(d^\text{obs}\) représente la distance habituelle dans l’espace de départ, qui s’applique sur les données \(\mathbf{x}_i\). Typiquement, dans la définition précédente, \(d^\text{obs}(\mathbf{x}_i, \mathbf{x}_j) = \lVert \mathbf{x}_i - \mathbf{x}_j \rVert\) (la distance euclidienne).
Cette nouvelle distance remplace ainsi la distance euclidienne dans (55).
Le paramètre \(\lambda\) permet de contrôler l’importance donnée à la sémantique ou aux données :
si \(\lambda = 0\) alors seule la distance entre les données \(d^\text{obs}(\mathbf{x}_i, \mathbf{x}_j)\) (\(= \lVert \mathbf{x}_i - \mathbf{x}_j\rVert\)) est prise en compte
si \(0 < \lambda < 1\) alors la distance totale est une moyenne pondérée entre la distance entre les observations et entre les étiquettes. Par défaut, \(\lambda = 0.5\) et il s’agit d’une moyenne équilibrée.
si \(\lambda = 1\) alors seule la distance entre les étiquettes \(d^\text{classe}(\mathbf{x}_i, \mathbf{x}_j)\) est prise en compte.
Comme t-SNE, UMAP est une méthode non inductive, il n’y a pas d’expression explicite de la projection d’un vecteur de l’espace de départ vers l’espace d’arrivée. Il est néanmoins possible d’approcher cette projection à l’aide d’un modèle de régression, par exemple d’un réseau de neurones de type perceptron multi-couches ; cette méthode est mise en œuvre dans la classe ParametricUMAP de la bibliothèque umap-learn. L’interpolation réalisée par un modèle de régression peut toutefois être de qualité variable.
Pour UMAP il est nécessaire de prendre des précautions lors de l’interprétation des résultats car la signification des densités des groupes dépend non seulement de l’organisation des données dans l’esoace de départ mais aussi, et même fortement, de la valeur de min_dist. Il faut également interpréter avec prudence les distances inter-groupes : pour une valeur faible de n_neighbours les relations entre groupes dans l’espace de départ peuvent être en grande mesure ignorées, pour une valeur plus élevée pour n_neighbours la solution trouvée ne tient pas nécessairement compte de façon équivalente des relations entre les différents groupes (la fonction minimisée par l’algorithme d’optimisation peut avoir des minima multiples).
On constate que pour UMAP les résultats sont moins sensibles au réglage du nombre de voisins (n_neighbours) que les résultats de t-SNE au réglage de la perplexité, notamment pour ce qui concerne les données isolées ou marginales des groupes. En effet, pour UMAP le \(\sigma\) augmente pour les données isolées afin de pouvoir considérer n_neighbours voisins, alors que pour t-SNE le \(\sigma\) a la même valeur pour toutes les données. Il est néanmoins important de comparer plusieurs visualisations avec des valeurs différentes (notamment pour n_neighbours) afin d’observer les structures locales et la structure globale.
Validation des méthodes de réduction de dimension¶
Comment vérifier la pertinence d’une projection obtenue par une des méthodes de réduction non linéaire de dimension ? Comment savoir ce qui peut être interprété et ce qui ne devrait pas être interprété ? Pour les méthodes de réduction linéaire de dimension, comme l’ACP et l’AFD, la linéarité même de la projection sur le sous-espace réduit permet de déduire certaines règles (par exemple, si A est à mi-distance entre B et C dans l’espace de départ, la projection de A sera à mi-distance entre les projections de B et respectivement C dans l’espace réduit). Par ailleurs, des aides à l’interprétation (comme la qualité de représentation ou la contribution relative dans le cas de l’ACP) permettent d’éviter d’interpréter la projection sur l’espace réduit des observations mal représentées. De tels outils ne sont pas disponibles pour t-SNE ou pour UMAP. Les deux approches suivantes sont en général employées pour caractériser la qualité de la réduction non linéaire de dimension obtenue :
Lorsque les données forment des classes connues ou des groupes dans l’espace de départ, la qualité globale de la réduction de dimension est évaluée à travers le maintien des performances de la classification par les k plus proches voisins (kppv ou kNN). Afin de classer une observation en utilisant les kppv on fait voter ses k plus proches voisins et on affecte l’observation à la classe qui s’avère être majoritaire. Si les performances de la classification par les kppv sont équivalentes ou supérieures dans l’espace d’arrivée par rapport aux performances dans l’espace de départ alors on considère que la réduction de dimension est de bonne qualité. Il faut veiller à choisir une valeur pour k qui soit cohérente par rapport aux paramètres de la méthode de réduction non linéaire (perplexité pour t-SNE ou nombre de voisins pour UMAP).
S’appuyer sur des critères spécifiques [SRH16]. Un critère plutôt général est la trustworthiness, qui permet d’évaluer dans quelle mesure on conserve l’ordonnancement des voisins :
où \(U^{(k)}_i\) sont les indices des kppv de l’observation \(i\) dans l’espace réduit et \(r(i,j)\) est le rang de l’observation \(j\) parmi les voisins de \(i\) dans l’espace de départ. \(T(k) \in [0, 1]\), plus la valeur est proche de 1, meilleure est la qualité.
Le plongement spectral cherche à représenter un ensemble d’observations dans un espace vectoriel de dimension donnée, en s’appuyant sur la matrice des similarités entre ces observations. Si nous disposons d’un ensemble d’observations représentées au départ par des vecteurs de dimension \(D\), nous pouvons calculer les similarits entre ces observations et ensuite, par plongement spectral, représenter ces observations dans un nouvel espace vectoriel de dimension \(d < D\) choisie. Naturellement, comme le plongement spectral s’appuie uniquement sur une matrice de similarités, il peut être appliqué aussi bien et même plus directement à des observations qui ne possèdent pas de représentation vectorielle au départ mais entre lesquelles des similarités peuvent être calculées.
Soit donc un ensemble \(\mathcal{E} = \{\mathbf{x}_i, 1 \leq i \leq N\}\) de \(N\) données décrites par une matrice de similarités \(\mathbf{S}\) telle que l’élément \(s_{ij} \geq 0\) soit la similarité entre \(\mathbf{x}_i\) et \(\mathbf{x}_j\). Le plongement spectral procède en deux étapes :
A partir de \(\mathbf{S}\) est obtenu un graphe de similarités. Pour une méthode de réduction de dimension comme t-SNE ou UMAP ces similarités sont calculées grâce à l’emploi des noyaux gaussiens, (48) et (55).
A l’aide du graphe, une représentation vectorielle « convenable » (du point de vue de la classification automatique !) des données est obtenue. Cette représentation peut être employée pour initialiser t-SNE ou UMAP.
Nous devons préciser qu’en poursuivant ces deux étapes par l’application d’un algorithme de classification automatique (comme K-means) à ces nouvelles représentations des observations nous pouvons obtenir des groupes disjoints de façon plus fiable qu’en appliquant directement cet algorithme de classification automatique sur les observations de départ. Ce processus constitue la classification spectrale, décrite de façon plus complète dans ce cours optionnel.
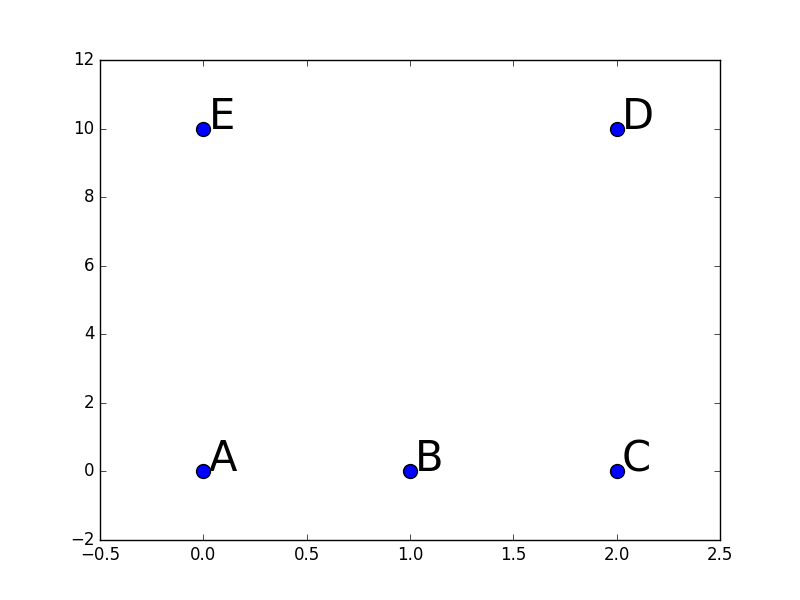
Afin d’illustrer le fonctionnement du plongement spectral, nous nous servons dans la suite de l’exemple donné dans [Lux07]. Les données sont des vecteurs dans l’espace bidimensionnel, illustrés dans la figure suivante par des étoiles bleues.
Fig. 122 Données (issues de [Lux07]) pour l’exemple de plongement spectral¶
A partir de ces données vectorielles, une matrice de similarités est obtenue et ensuite un graphe de similarités est déduit. Pour une méthode de réduction de dimension comme t-SNE ou UMAP ces similarités sont calculées grâce à l’emploi des noyaux gaussiens, (48) et (55). Dans l’exemple considéré nous pouvons illustrer un graphe de similarités par la figure suivante.
Fig. 123 Graphe de similarités pour l’exemple (issu de [Lux07])¶
Avant d’aller plus loin, il est nécessaire d’introduire (ou rappeler) quelques notions concernant les graphes.
Un graphe non orienté est un couple \(G = (V,E)\), où \(V = \{v_1, \ldots, v_N\}\) est l’ensemble des (\(N\)) sommets et \(E\) l’ensemble des arêtes. Voir l’exemple de graphe de la figure précédente, où les sommets sont les données (vecteurs de \(\mathbb{R}^2\) dans ce cas).
Les arêtes peuvent être pondérées : soit \(w_{ij} \geq 0\) le poids de l’arête qui lie les sommets \(v_i\) et \(v_j\), alors \(w_{ij} = 0\) si et seulement si (ssi) il n’y a pas d’arête entre les sommets \(v_i\) et \(v_j\). La matrice des poids est \(\mathbf{W}\) d’élément générique \(w_{ij}\).
Le degré du sommet \(v_i\) est la somme des poids des arêtes qui relient ce sommet à d’autres, \(d_i = \sum_{j=1}^N w_{ij}\). On peut considérer une matrice diagonale des degrés \(\mathbf{D}\) qui a \(\{d_1, \ldots, d_N\}\) sur la diagonale principale.
Une chaîne ou un chemin\(\mu(v_i,v_j)\) entre les sommets \(v_i\) et \(v_j\) est une suite d’arêtes de \(E\) permettant de relier les deux sommets.
Un sous-ensemble \(C \subset V\) forme une composante connexe du graphe \(G = (V,E)\) si
quels que soient deux sommets de \(C\), il existe une chaîne de \(G\) les reliant (\(\forall v_i,v_j \in C\), \(\exists \mu(v_i,v_j)\)) et
pour tout sommet \(v_i\) de \(C\) et toute chaîne avec des arêtes de \(E\) et partant de \(v_i\), le sommet terminal de la chaîne est également dans \(C\) (\(\forall v_i \in C, \forall \mu(v_i,v_p)\), \(v_p \in C\)).
Le vecteur indicateur d’un sous-ensemble \(C\) de \(V\) est le vecteur \(\mathbf{c}\) à \(N\) composantes binaires tel que \(c_i = 1\) si le sommet \(v_i \in C\) et \(c_i = 0\) sinon. La même définition s’applique lorsque \(C\) est une composante connexe.
Pour un graphe non orienté à arêtes pondérées, la matrice laplacienne (non normalisée) est définie par \(\mathbf{L} = \mathbf{D} - \mathbf{W}\). La matrice laplacienne possède plusieurs propriétés importantes :
pour tout vecteur \(\mathbf{x} \in \mathbb{R}^N\), nous avons \(\mathbf{x}^T \mathbf{L} \mathbf{x} = \frac{1}{2} \sum_{i,j=1}^N w_{ij} (x_i - x_j)^2\) ;
la matrice laplacienne \(\mathbf{L}\) est symétrique (\(\mathbf{L} = \mathbf{L}^T\)) et semi-définie positive (\(\forall \mathbf{x} \in \mathbb{R}^N\), \(\mathbf{x}^T \mathbf{L} \mathbf{x} \geq 0\));
la matrice laplacienne \(\mathbf{L}\) a \(N\) valeurs propres réelles \(0 = \lambda_1 \leq \lambda_2 \leq \ldots \leq \lambda_N\) ;
la valeur propre la plus faible de \(\mathbf{L}\) est 0, le vecteur propre correspondant étant le vecteur constant \(\mathbf{1}\) (toutes ses composantes sont égales à \(1\)) ; cela s’explique facilement par la définition même des degrés des sommets ;
la multiplicité de la valeur propre 0 de \(\mathbf{L}\) est égale au nombre de composantes connexes de \(G\) ;
les vecteurs indicateurs de ces composantes connexes sont des vecteurs propres de \(\mathbf{L}\) pour la valeur propre 0.
Plusieurs méthodes peuvent être employées pour normaliser la matrice laplacienne d’un graphe, notamment :
La normalisation « marche aléatoire » (random walk), où le résultat n’est plus une matrice symétrique : \(\mathbf{L}_{rw} = \mathbf{D}^{-1} \mathbf{L} \left(= \mathbf{I}_N - \mathbf{D}^{-1} \mathbf{W}\right)\).
Nous pouvons maintenant détailler l’étape 2 de la méthode de plongement spectral :
A partir de \(\mathbf{S}\) est produit un graphe de similarités \(G\), avec les pondérations \(w_{ij} = s_{ij}\).
A l’aide du graphe, une représentation vectorielle « convenable » (du point de vue de la classification automatique) des données est obtenue par la méthode suivante :
Calculer la matrice laplacienne \(\mathbf{L}\) ;
Calculer les \(k\) vecteurs propres \(\mathbf{u}_1, \ldots, \mathbf{u}_k\) associés aux \(k\) plus petites valeurs propres de \(\mathbf{L} \mathbf{u} = \lambda \mathbf{D} \mathbf{u}\) ;
Soit \(\mathbf{U}_k\) la matrice dont les colonnes sont les vecteurs \(\mathbf{u}_1, \ldots, \mathbf{u}_k\) ;
Soit \(\mathbf{y}_i \in \mathbb{R}^k, 1 \leq i \leq N\), les \(N\) lignes de la matrice \(\mathbf{U}_k\), chaque donnée (observation) \(i\) est représentée par le vecteur \(\mathbf{y}_i\).
Afin de mieux comprendre l’effet du plongement spectral sur le regroupement d’observations, examinons le lien entre plongement spectral et coupe normalisée dans un graphe. Considérons un graphe non orienté à arêtes pondérées \(G = (V, E)\), que nous souhaitons découper en \(k\) groupes (sous-ensembles) disjoints \(V_1, \ldots, V_k\) de sommets.
La coupe minimum est obtenue en choisissant les \(k\) groupes de sommets de façon à minimiser la somme des poids des arêtes qui relient des sommets appartenant à des groupes différents. Plus précisément, est minimisée la quantité \(\sum_{s=1}^k \omega(V_s, V-V_s)\), où \(\omega(V_s, V_t) = \sum_{v_i \in V_s, v_j \in V_t} w_{ij}\) et \(V-V_s\) est l’ensemble de sommets de \(V\) qui ne sont pas dans \(V_s\). Malheureusement, bien souvent la coupe minimum sépare le graphe en un nombre limité \(l \ll k\) de grands sous-graphes plus quelques sommets isolés, solution jugée en général peu intéressante.
Avec la coupe normalisée (normalized cut, Ncut), les sous-ensembles de sommets sont plus équilibrés. La coupe normalisée est obtenue en minimisant \(\sum_{s=1}^k \frac{\omega(V_s, V-V_s)}{\textrm{vol}(V_s)}\), où le « volume » d’une composante \(V_s\) est la somme des degrés des sommets de cette composante, \(\textrm{vol}(V_s) = \sum_{v_i \in V_s} d_i\). Malheureusement, si la solution obtenue est en général plus satisfaisante, ce problème de minimisation est NP-difficile !
Nous pouvons reformuler le problème de minimisation en utilisant un vecteur indicateur pour chaque sous-ensemble de sommets, avec une « relaxation » continue du problème discret : les composantes du vecteur indicateur ne sont pas binaires mais ont des valeurs dans l’intervalle \([0, 1]\).
Considérons la matrice \(\mathbf{U}_k\) dont les colonnes sont les vecteurs caractéristiques \(\mathbf{u}_1, \ldots, \mathbf{u}_k\) des \(k\) groupes recherchés et chacune des \(N\) lignes correspond à une des observations. Avec des groupes disjoints, chacune des observations appartient à un seul groupe et donc le vecteur \(\mathbf{y}_i\) qui représente l’observation \(i\) a une seule composante égale à 1 (la composante \(y_{ij}\) si l’observation \(i\) fait partie du groupe \(j\)), alors que les autres sont égales à 0. Avec la relaxation continue, ces composantes du vecteur ont toutes des valeurs dans l’intervalle \([0, 1]\) ; on peut les voir comme des degrés d’appartenance de cette observation aux différents groupes.
Avec cette relaxation continue, la coupe normalisée est ainsi traduite en un problème de minimisation sous contraintes d’égalité. Les contraintes d’égalité consistent à imposer, pour toute ligne de \(\mathbf{U}_k\), que la somme des composantes soit égale à 1 : \(\forall i \in \{1, \ldots, N\}, \sum_{j=1}^k y_{ij} = 1\).
Pour résoudre ce nouveau problème de minimisation, il faut trouver les \(k\) plus petites valeurs propres de \(\mathbf{L} \mathbf{u} = \lambda \mathbf{D} \mathbf{u}\) et les vecteurs propres associés (qui seront les colonnes de \(\mathbf{U}_k\)). En l’absence de sommets isolés, \(\mathbf{L} \mathbf{u} = \lambda \mathbf{D} \mathbf{u}\) devient \(\mathbf{D}^{-1} \mathbf{L} \mathbf{u} = \lambda \mathbf{u}\), ou encore \(\mathbf{L}_{rw} \mathbf{u} = \lambda \mathbf{u}\).
Pour revenir à des vecteurs caractéristiques binaires, dans la dernière étape de l’algorithme une méthode de classification automatique de base (comme K-means) est appliqué aux lignes de \(\mathbf{U}_k\) et ainsi chaque donnée est affectée à un groupe (chaque sommet est affecté à une composante du graphe). Le plongement spectral a ainsi permis de rapprocher plus dans l’espace d’arrivée les données déjà proches dans l’espace de départ et d’éloigner les groupes qui n’étaient pas très proches dans l’espace de départ. C’est ce qui facilite le travail ultérieur de l’algorithme de classification automatique qui produit le découpage final du graphe.
Un exemple numérique aide à mieux comprendre comment est obtenu le plongement spectral des données. Considérons les 5 observations bidimensionnelles qui sont les lignes de la matrice suivante :
La figure suivante illustre cet exemple (attention, l’échelle n’est pas la même sur les deux axes) :
Fig. 124 Données pour l’exemple numérique de plongement spectral¶
La matrice des similarités est obtenue à partir du noyau gaussien de variance 1 appliqué à la distance euclidienne entre les observations. En arrondissant les valeurs à 6 décimales nous obtenons:
Avec la précision de représentation considérée, les similarités entre les observations de l’ensemble {A, B, C} et celles de l’ensemble {D, E} sont nulles (valeurs représentées en gras dans la matrice), le graphe associé possède donc deux composantes connexes, {A, B, C} et {D, E}.
La matrice laplacienne normalisée asymétrique \(\mathbf{L}_{rw} = \mathbf{D}^{-1} \mathbf{L} \left(= \mathbf{I}_N - \mathbf{D}^{-1} \mathbf{W}\right)\) résultante (valeurs arrondies à 6 décimales) est :
Les valeurs propres de \(\mathbf{L}_{rw}\) en ordre croissant sont 0.0, 0.0, 1.0474, 1.9525 et 2.0000. La valeur propre 0 est donc de multiplicité 2, ce qui indique qu’il y a bien 2 composantes connexes dans le graphe. La matrice \(\mathbf{U}_2\) dont les colonnes sont les 2 vecteurs propres correspondant à la même valeur propre 0 (de multiplicité 2) est :
Il faut noter que le choix exact des deux vecteurs propres est arbitraire dans le sous-espace propre à 2 dimensions correspondant à la valeur propre 0 (la dimension de l’espace propre est égale à la multiplicité de la valeur propre). Les seules contraintes sont l’orthogonalité de ces deux vecteurs propres et le fait que chacun doit avoir une norme égale à 1.
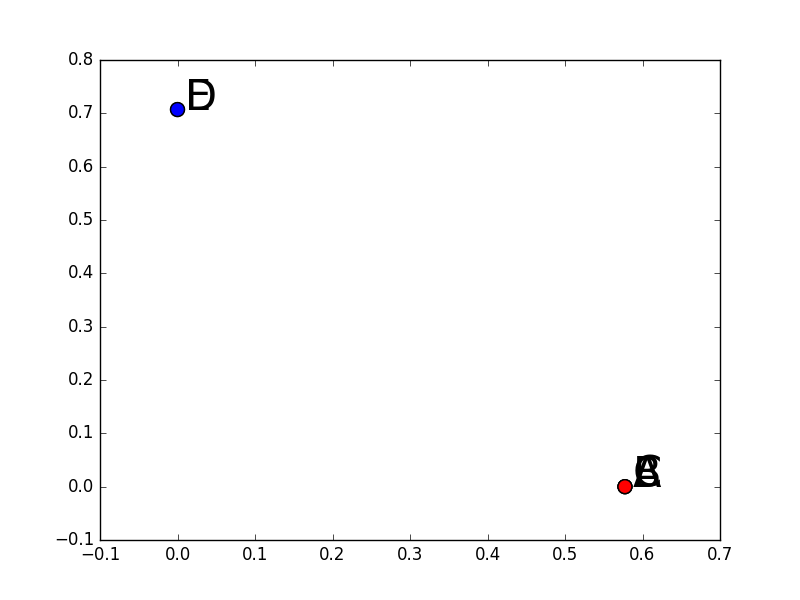
Les nouvelles représentations des données sont alors les lignes de la matrice \(\mathbf{U}_2\). On obtient une réduction de dimension (de 2 à 1 dans le cas présent) en considérant soit les composantes sur le première colonne, soit celles sur la seconde colonne. L’illustration suivante montre que pour cet exemple les projections sur ces 2 vecteurs propres des observations A, B et C sont confondues et différentes des projections de D et E qui sont également confondues :
Fig. 125 Nouvelles représentations des données pour l’exemple numérique : les projections sur le premier axe ou les projections sur le deuxième axe.¶
Ici nous pouvons choisir aussi bien les projections sur le premier axe ou les projections sur le deuxième axe car les deux axes correspondent à une même valeur propre de 0. Si le deuxième axe avait été associé à une valeur propre différente de 0 alors les projections sur le premier axe auraient été un meilleur choix du point de vue du plongement spectral : rapprocher plus les observations proches et les éloigner plus des observations éloignées.
Nous pouvons voir qu’en appliquant le plongement spectral nous pouvons obtenir une meilleure initialisation pour t-SNE ou pour UMAP qu’en utilisant une initialisation aléatoire. En effet, dans l’initialisation aléatoire des observations proches dans l’espace de départ peuvent avoir des images éloignées dans l’espace réduit et des observations éloignées dans l’espace de départ peuvent avoir des images proches dans l’espace réduit. L’utilisation du plongement spectral comme méthode d’initialisation est en général meilleure aussi que l’emploi de l’ACP pour l’initialisation, car l’ACP peut écraser un sous-espace (manifold) non linéaire.
Nous pouvons voir également que l’utilisation du plongement spectral seul pour réduire la dimension mène à des résultats grossiers dans le sens où les similarités fortes sont encore renforcées et les similarités faible diminuées. Il est donc nécessaire d’appliquer ensuite t-SNE ou UMAP (suivant qu’on souhaite être plus ou moins dépendant de la densité local) pour obtenir une réduction de dimension qui reflète de façon plus fine les similarité entre données dans l’espace de départ.
La notion de complexe simplicial est employée dans l’étude de la topologie des ensembles de vecteurs. Elle nous permettra aussi de mieux comprendre le choix fait pour UMAP par rapport à t-SNE.
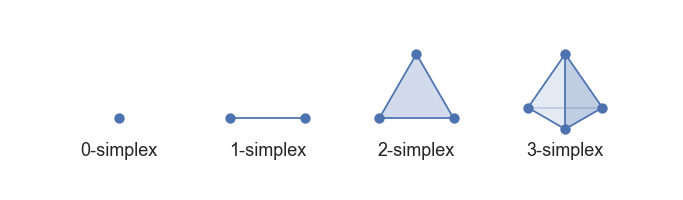
Considérons \(\mathcal{E} \in \mathbb{R}^k\) un ensemble de points dans un espace vectoriel de dimension \(k\). Un simplexe de dimension \(k\) est défini comme étant l’enveloppe convexe de \(k+1\) points \(\{\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_{k+1}\} \subset \mathcal{E}\). Le simplexe est donc un objet multi-dimensionnel à \(k+1\) sommets pour \(k+1\) côtés (ou faces). Pour \(k=0\) nous obtenons un point, pour \(k=1\) un segment, pour \(k=2\) un triangle, pour \(k=3\) un tétraèdre et ainsi de suite.
Un complexe simplicial\(\mathcal{K}\) de \(\mathcal{E}\) est défini comme un ensemble de simplexes reliés par au moins une face, c’est-à-dire :
\(\mathcal{K} = \{S_1, S_2, \ldots, S_m\}\)
\(\forall 1 \leq i \leq m, ~S_i\) est un \(k\)-simplexe de \(\mathcal{E}\)
\(\forall 1 \leq i \leq m, \exists 1 \leq j \leq m, j \neq i\) tel que \(S_i\) et \(S_j\) partagent une face en commun.
Afin de caractériser la topologie d’un nuage de points \(\mathcal{E} = \{\mathbf{x}_i, 1 \leq i \leq n\} \subset \mathbb{R}^k\), il est intéressant d’examiner le complexe simplicial qui « couvre » tous les points, voir également les Fig. 127 et Fig. 128 :
Chaque point \(\mathbf{x}_i\) est relié aux voisins qui sont dans une boule ouverte de rayon \(r\).
Si deux boules ouvertes s’intersectent (si \(\mathbf{x}_i\) et \(\mathbf{x}_j\) sont voisins), on place un 1-simplexe reliant \(\mathbf{x}_i\) et \(\mathbf{x}_j\).
Si \(k\) boules ouvertes s’intersectent (si \(\mathbf{x}_{i_1}, \mathbf{x}_{i_2}, \dots, \mathbf{x}_{i_k}\) sont voisins), on place un \(k\)-simplexe reliant tous ces points.
Fig. 127 Couverture par des boules de rayon fixe. Figure issue de cette source.¶
Fig. 128 Graphe issu de la couverture par des boules de rayon fixe. Figure issue de la même source.¶
Le choix du rayon \(r\) de la boule ouverte est toutefois difficile :
si les boules sont nettes (ou strictes) alors les résultats sont fragiles par rapport au choix du rayon \(r\) ;
si \(r\) est fixe alors les boules sont uniformes, or les données sont en général non uniformément réparties ;
si \(r\) est variable alors comment savoir quelle valeur prendre pour un \(\mathbf{x}_i\) donné ?
Employer un complexe simplicial « flou » (boules floues) et obtenir donc un graphe pondéré apporte une solution au premier problème. Chaque arête du graphe dispose alors d’un poids \(w_{ij}\) qui peut s’obtenir à partir de la similarité entre les observations (dans l’espace de départ).
Ensuite, les choix divergent :
Pour t-SNE, la perplexité prend une valeur unique partout et définit la forme de la fonction de similarité. Les boules sont floues mais de même rayon partout.
Pour UMAP, la métrique locale est normalisée par la distance au \(k^{\textrm{ième}}\) voisin et les boules floues sont donc de rayon variable adapté à la densité locale. La valeur considérée pour le nombre de voisins (n_neighbours) permet de faire un réglage sur l’ensemble des observations, sans toutefois imposer un rayon unique. La Fig. 129 permet d’illustrer ce choix :
Fig. 129 Couverture par des boules floues de rayon variable. Figure issue de la même source.¶
A.C. Belkina, C. O. Ciccolella, R. Anno, R. Halpert, J. Spidlen, et J. E. Snyder-Cappione. Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets. Nature Communications. 10(1):5415, Nov. 2019.
G.E. Hinton et S.T. Roweis. Stochastic Neighbor Embedding. In Advances in Neural Information Processing Systems, volume 15, pages 833-840, Cambridge, MA, USA, 2002. The MIT Press.