Travaux pratiques - Ordonnancement Structuré (2) : application et évaluation¶
Exercice 2 : Entraînement du modèle et évaluation des performances¶
Pour évaluer le modèle d’ordonnancement structuré mis en place au TP7, on va considérer une catégorie de la base VOC2007 comme la requête (e.g. les images de la classe “potted plant”) et évaluer la capacité du modèle à ordonner les exemples pertinents par rapport à la requête (e.g. les images de la classe “potted plant”) avant les exemples non pertinents (e.g. les images des autres classes que la classe “potted plant”).
On rappelle le code pour charger les données (« Deep Features ») du TP 7 :
outfile = 'DF_ResNet50_VOC2007.npz'
npzfile = np.load(outfile)
X_train = npzfile['X_train']
Y_train = npzfile['Y_train']
X_test = npzfile['X_test']
Y_test = npzfile['Y_test']
On va ensuite consiérer une classe requête :
LABELS = ['aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
# Query (class)
c=15
nbPlusTrain = np.where(Y_train[:,c]==1)[0].shape[0]
nbPlusTest = np.where(Y_test[:,c]==1)[0].shape[0]
print "nbPlusTrain=",nbPlusTrain, "nbPlusTest=", nbPlusTest
Le constructeur de la classe SRanking du TP 7 nécessite une annotation de type ranking RankingOutput. Créer les sorties structurées pour du ranking données par la supervision pour les données d’apprentissage :
# Getting RankingOutput supervision for train and test
output_train = # COMPLETE WITH YOUR CODE
output_test = # COMPLETE WITH YOUR CODE
Ensuite on pourra défnir un modèle de ranking structuré et l’entraîner :
from structured import SRanking
learning_rate = 0.5
nb_epoch = 40
# Ranking model instanciation
ranking_model = SRanking(output_train, X_train.shape[1], X_train.shape[1], learning_rate, nb_epoch)
# Fitting model to data
ranking_model.fit(X_train, output_train)
On pourra enfin évaluer les performances du modèle sur la base de test :
ranking_model.compute_RP_curve(X_train, Y_train[:,c])
ranking_model.compute_RP_curve(X_test, Y_test[:,c])
En ajoutant la fonction compute_RP_curve dans la classe SRanking :
def compute_RP_curve(self, X,labels):
pred = np.matmul(X,self.w)
AP = average_precision_score(labels, pred)
precision, recall, _ = precision_recall_curve(labels,pred)
plt.clf()
plt.plot(recall, precision, lw=2, color='navy',label='Precision-Recall curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('Precision-Recall example: AP={0:0.2f}'.format(AP*100.0))
plt.legend(loc="lower left")
plt.show()
Ci-dessous un exemple de résultat obtenu en test pour la classe “potted plant” :
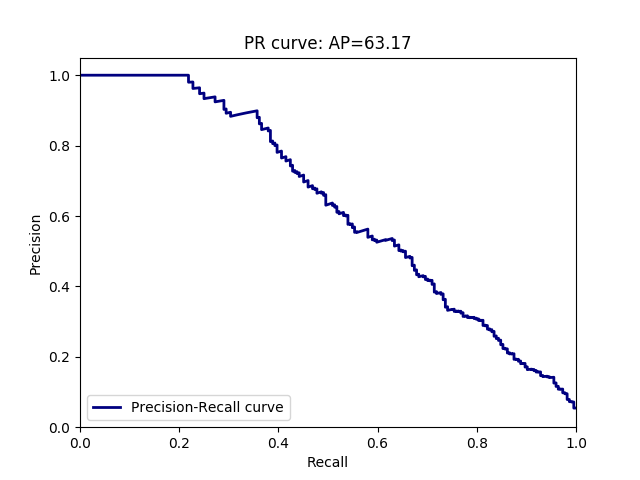
Commentaires :
Comparer les performances obtenues avec le modèle d’ordonnancement structuré par rapport à celles obtenues avec un modèle de classification binaire. Comment s’explique cette différence ?