Travaux pratiques - Perceptron multi-couche¶
L’objectif de cette seconde séance de travaux pratiques est d’étendre le modèle de régression logistique de la semaine précédente afin de mettre en place des modèles de prédictions plus riches. En particulier, on va s’intéresser aux Perceptron multi-couches (Multi-Layer Perceptron, MLP). Contrairement à la régression logistique qui se limite à des séparateurs linéaires, le Perceptron permet l’apprentissage de frontières de décisions non linéaires, et constituent des approximateurs universels de fonctions.
L’objectif de la séance de travaux pratiques est de mettre en place le code pour effectuer des prédiction et entraîner un Perceptron à une couche cachée.
Exercice 1 : Prédiction avec un Perceptron (Forward)¶
L’architecture du perpcetron à une couche cachée est montrée dans la figure ci-dessous.
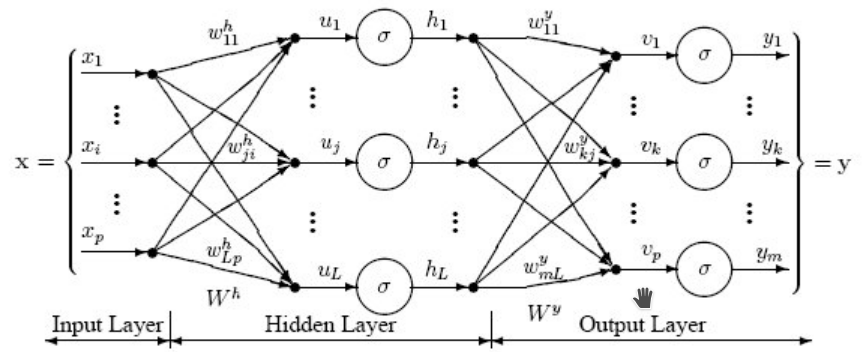
Si on considère les données de la base MNIST, chaque image est représentée par un vecteur de taille \(28^2=784\). Le perpcetron va effectuer les différentes étapes de transformation pour produire la prédiction finale, i.e. la catégorie sémantique de l’image :
Une étape de projection linéaire, qui va projeter chaque image sur un vecteur de taille \((1,L)\), e.g. \(L=100\). En considérant que chaque exemple \(\mathbf{x_i}\) est un vecteur ligne - taille \((1,784)\) - la projection linéaire peut être représentée par la matrice \(\mathbf{W^h}\) (taille \((784, L)\)), et le vecteur de biais \(\mathbf{b^h}\) (taille \((1, L)\)) : \(\mathbf{\hat{u_i}} =\mathbf{x_i} \mathbf{W^h} + \mathbf{b^h}\).
Une étape d’application de non linéarité, e.g. de type sigmoïde : \(\forall j \in \left\lbrace 1; L \right\rbrace ~ h_{i,j} = \frac{1}{1+exp(-u_{i,j})}\).
Une seconde étape de projection linéaire, qui va projeter le vecteur latent de taille \((1,L)\) sur un vecteur de taille \((1,K)=10\) (nombre de classes). Cette opération de projection linéaire sera représentée par la matrice \(\mathbf{W^y}\) (taille \((L, K)\)), et le vecteur de biais \(\mathbf{b^y}\) (taille \((1, K)\)) : \(\mathbf{\hat{v_i}} =\mathbf{h_i} \mathbf{W^y} + \mathbf{b^y}\).
Une étape d’application de non linéarité de type soft-max vue la semaine précédente pour la régression logistique : \(\forall j \in \left\lbrace 1; K \right\rbrace ~ y_{i,j} = \frac{exp(v_{i,j})}{\sum\limits_{i=1}^K exp(v_{i,k})}\)
On demande de mettre en place un script mlp.py qui implémente l’algorithme du Percpetron sur la base MNIST.
L’algorithme reprendra le squelette du code de la régression logistique. Pour adapter ce code pour le Perceptron pour la partie prédiction, vous devez :
Modifier la fonction de prédiction, afin disposer la fonction
forward(batch, Wh, bh, Wy, by)qui reverra à la fois la prédiction pour le batch ainsi que la matrice des couches latentes.Si on considère un batch des données de taille \(t_b\times 784\), les paramètres \(\mathbf{W^h}\) (taille \(784\times L\)), \(\mathbf{b^h}\) (taille \(1\times L\)), \(\mathbf{W^y}\) (taille \(L\times K\)) et \(\mathbf{b^y}\) (taille \(1\times K\)), la fonction
forwardrenvoie la prédiction \(\mathbf{\hat{Y}}\) sur le batch (taille \(t_b\times K\)) et la matrice de variables latentes (taille \(t_b\times L\)).
Exercice 2 : Apprentissage du Perceptron (Backward)¶
Afin d’entraîner le Perceptron, on va utiliser l’algorithme de rétro-propagation de l’erreur. On rappelle que pour chaque batch d’exemples, l’algorithme va effectuer une passe forward (Exercice 1), permettant de calculer la prédiction du réseau.
Une fonction de coût (ici l’entropie croisée) entre la sortie prédite et la la sortie donnée par la supervision va permettre de calculer le gradient de l’erreur par rapport à tous les paramètres du modèle, i.e. \(\mathbf{W^y}\) (taille \((L, K)\)), \(\mathbf{b^y}\) (taille \((1, K)\)), \(\mathbf{W^h}\) (taille \((784, L)\)), et \(\mathbf{b^h}\) (taille \((1, L)\)).
On rappelle les équations des gradients, effectuées depuis la sortie vers l’entrée du réseau :
Mise à jour de \(\mathbf{W^y}\) et \(\mathbf{b^y}\) :
où \(\mathbf{H}\) est la matrice des couches cachées sur le batch (taille \(t_b\times L\)), \(\mathbf{\hat{Y}}\) est la matrice des labels prédits sur l’ensemble de la base d’apprentissage (taille \(t_b\times K\)) et \(\mathbf{Y^*}\) est la matrice des labels donnée issue de la supervision (« ground truth », taille \(t_b\times K\)), et \(\mathbf{\Delta^y}=\mathbf{\hat{Y}}-\mathbf{Y^*}\).
Mise à jour de \(\mathbf{W^h}\) et \(\mathbf{b^h}\) :
Montrer que :
En déduire que les gradients de \(\mathcal{L}\) par rapport à \(\mathbf{W^h}\) et \(\mathbf{b^h}\) s’écrivent matriciellement :
où \(\mathbf{X}\) est la matrice des données sur le batch (taille \(t_b\times 784\)), et \(\mathbf{\Delta^h}\) est la matrice des \(\delta^h_i\) sur le batch (taille \(t_b\times L\)).
Adapter la partie backward de l’algorithme pour entraîner le Perceptron :
Question : la fonction de coût de l’Eq. (3) est-elle convexe par rapport aux paramètres \(\mathbf{W}\), \(\mathbf{b}\) du modèle ? Avec un pas de gradient bien choisi, peut-on assurer la convergence vers le minimum global de la solution ?
Tester en initialisant les matrices à 0 comme pour la régression logistique. Quelles performances obtenez-vous ? Que peut-on en conclure ?
Vous testerez deux autres initialisations : une qui initialise les poids avec une loi normale de moyenne nulle et d’écart type à fixer, e.g. \(10^-1\), et une autre connue sous le nom de Xavier [GB10], qui divise la valeur de la gaussienne par \(\sqrt{ni}\), où \(ni\) est le nombre de neurone dans la couche d’entrée.
Évaluer les performances du modèle. Vous devez obtenir un score de l’ordre de 98% sur la base de test pour ce réseau de neurones à une couche cachée.
- GB10
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS’10). Society for Artificial Intelligence and Statistics. 2010.
Solution : http://cedric.cnam.fr/~thomen/cours/RCP209/codes/tme2/MLP.py.