TP 1 - Algorithme de rétro-propagation de l’erreur¶
L’objectif de cette première séance de travaux pratiques est de vous faire implémenter par vous même l’apprentissage de réseaux de neurones simples. Cettre prise en main sera très formatrice pour utiliser des modèles plus évolués, et comprendre le fonctionnement des libaries (comme Keras) où l’apprentissage est automatisé.
On va travailler avec la base de données image MNIST, constituée d’images de caractères manuscrits (60000 images en apprentissage, 10000 en test).
Voici un bout de code pour récupérer les données :
from keras.datasets import mnist # the data, shuffled and split between train and test sets (X_train, y_train), (X_test, y_test) = mnist.load_data() X_train = X_train.reshape(60000, 784) X_test = X_test.reshape(10000, 784) X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 X_test /= 255 print(X_train.shape[0], 'train samples') print(X_test.shape[0], 'test samples')
Exercice 0 : Visualisation¶
- On va commencer par afficher les 200 premières images de la base d’apprentissage.
Écrire un script
exo0.pyqui va récupérer les données avec le code précédentCompléter
exo0.pypour permettre l’affichage demandé en utilisant le code suivant :
import matplotlib as mpl import matplotlib.pyplot as plt plt.figure(figsize=(7.195, 3.841), dpi=100) for i in range(200): plt.subplot(10,20,i+1) plt.imshow(X_train[i,:].reshape([28,28]), cmap='gray') plt.axis('off') plt.show()
Le script exo0.py doit produire l’affichage ci-dessous :

Question :
Quel est l’espace dans lequel se trouvent les images ? Quel est sa taille ?
Exercice 1 : Régression Logistique¶
Modèle de prédiction¶
- On va d’abord commencer par créer un modèle de classification linéaire populaire, la régression logistique.
Ce modèle correspond à un réseau de neurones à une seule couche, qui va projeter le vecteur d’entrée \(\mathbf{x_i}\) pour une image MNIST (taille \(28^2=784\)) avec un vecteur de de paramètres \(\mathbf{w_{c}}\) pour chaque classe (plus un biais \(b_c\)). Pour correspondre à la matrice des données de l’exercice précédent, on considère que chaque exemple \(\mathbf{x_i}\) est un vecteur ligne - taille (1,784). En regroupant l’ensemble des jeux de paramètres \(\mathbf{w_{c}}\) pour les 10 classes dans une matrice \(\mathbf{W}\) (taille \(784\times 10\)), et les biais dans un vecteur \(\mathbf{b}\), on obtient un vecteur \(\mathbf{\hat{s_i}} =\mathbf{x_i} \mathbf{W} + \mathbf{b}\) de taille (1,10). Une fonction d’activation de type soft-max sur \(\mathbf{\hat{y_i}} =\)
softmax\((\mathbf{s_i})\) permet d’obtenir le vecteur de sortie prédit par le modèle \(\mathbf{\hat{y_i}}\) - de taille (1,10) - qui représente la probabilité a posteriori \(p(\mathbf{\hat{y_i}} | \mathbf{x_i})\) pour chacune des 10 classes:
Le schéma ci-dessous illustre le modèle de régression logistique avec un réseau de neurones.
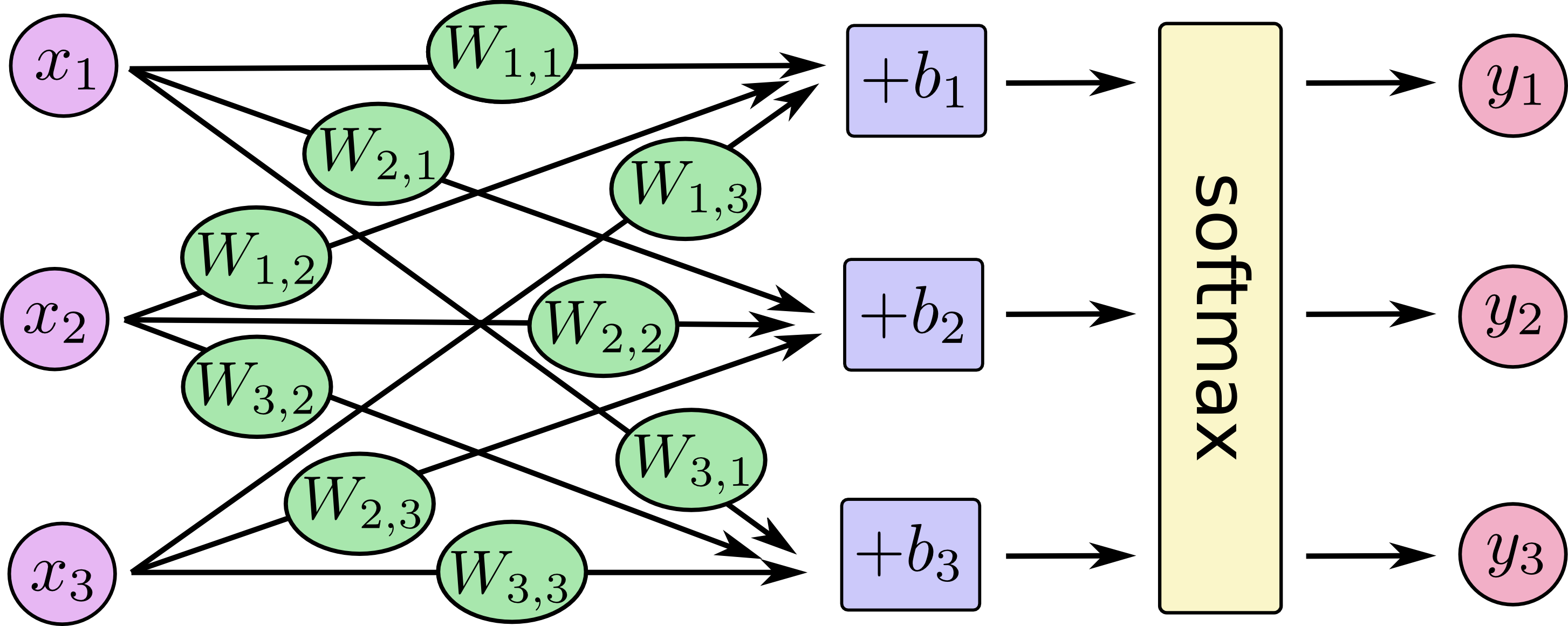
Quel est le nombre de paramètres du modèle ? Justifier le calcul.
Formulation du problème d’apprentissage¶
Afin d’entraîner le réseau de neurones, on va comparer, pour chaque exemple d’apprentissage, la sortie prédite \(\mathbf{\hat{y_i}}\) par le réseau (équation (1)) pour l’image \(\mathbf{x_i}\), avec la sortie réelle \(\mathbf{y_i^*}\) issue de la supervision qui correspond à la catégorie de l’image \(\mathbf{x_i}\): on utilisera en encodage de type « one-hot » pour \(\mathbf{y_i^*}\), i.e. :
Pour mesurer l’erreur de prédiction, on utilisera une fonction de coût de type entropie croisée (« cross-entropy ») entre \(\mathbf{\hat{y_i}}\) et \(\mathbf{y_i^*}\) (l’entropie croisée est lié à la divergence de Kullback-Leiber, qui mesure une dissimilarité entre distributions de probabilités) : \(\mathcal{L}(\mathbf{\hat{y_i}}, \mathbf{y_i^*}) = -\sum\limits_{c=1}^{10} y_{c,i}^* log(\hat{y}_{c,i}) = - log(\hat{y}_{c^*,i})\), où \(c^*\) correspond à l’indice de la classe donné par la supervision pour l’image \(\mathbf{x_i}\).
La fonction de coût finale consistera à moyenner l’entropie croisée sur l’ensemble de la base d’apprentissage \(\mathcal{D}\) consistuée de \(N=60000\) images :
Question :
La fonction de coût de l’Eq. (3) est-elle convexe par rapports aux paramètres \(\mathbf{W}\), \(\mathbf{b}\) du modèle ? Avec un pas de gradient bien choisi, peut-on assurer la convergence vers le minimum global de la solution ?
Optimisation du modèle¶
Afin d’optimiser les paramètres \(\mathbf{W}\) et \(\mathbf{b}\) du modèle de régression logistique par descente de gradient, on va utiliser la règle des dérivées chaînées (chain rule) :
Montrer que :
En déduire que les gradients de \(\mathcal{L}\) par rapport aux paramètres du modèle s’écrivent :
Où \(\mathbf{X}\) est la matrice des données (taille \(60000\times 784\)), \(\mathbf{\hat{Y}}\) est la matrice des labels prédits sur l’ensemble de la base d’apprentissage (taille \(60000\times 10\)) et \(\mathbf{Y^*}\) est la matrice des labels donnée issue de la supervision (« ground truth », taille \(60000\times 10\)), et \(\mathbf{\Delta^y}=\mathbf{\hat{Y}}-\mathbf{Y^*}\).
Implémentation de l’apprentissage¶
Les gradients aux équations (4) et (5) s’écrivent sous forme « vectorielle », ce qui va rendre les calculs efficaces avec des librairies de calculs scientifique comme numpy. Après calcul du gradient, les paramètres
seront mis à jour de la manière suivante :
où \(\eta\) est le pas de gradient (learning rate).
Pour implémenter l’algorithme d’apprentissage, on utuilisera une descente de gradient stochastique, c’est à dire que les gradients aux équations (4) et (5) ne seront pas calculés sur l’ensemble des \(N=60000\) images d’apprentissage, mais sur un sous ensemble appelé batch. Cette technique permet une mise à jour des paramètres plus fréquente qu’avec une descente de gradient classique, et une convergence plus rapide (au détriment d’un calcul de gradient approximé).
On demande de mettre en place un script exo1.py qui implémente l’alogorithme de régression logistique sur la base MNIST.
Après avoir chargé les données (exercice 0), on utilisera le code suivant pour générer des labels au format 0-1 encoding - équation (2).
from keras.utils import np_utils
K=10
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, K)
Y_test = np_utils.to_categorical(y_test, K)
On mettra alors en place un code dont le squellette est donné ci-dessous :
N = X_train.shape[0]
d = X_train.shape[1]
W = np.zeros((d,K))
b = np.zeros((1,K))
numEp = 20 # Number of epochs for gradient descent
eta = 1e-1 # Learning rate
batch_size = 100
nb_batches = int(float(N) / batch_size)
gradW = np.zeros((d,K))
gradb = np.zeros((1,K))
for epoch in range(numEp):
for ex in range(nb_batches):
# FORWARD PASS : compute prediction with current params for examples in batch
# BACKWARD PASS :
# 1) compute gradients for W and b
# 2) update W and b parameters with gradient descent
Pour compléter ce code, vous devez :
Mettre en place une fonction
forward(batch, W, b)qui va calculer la prédiction pour un batch de données. La fonctionforwardsera appelée pour chaque itération de la double boucle précédente.
Si on considère un batch des données de taille \(tb\times 784\), les paramètres \(\mathbf{W}\) (taille \(784\times 10\)) et \(\mathbf{b}\) (taille \(1\times 10\)), la fonction
forwardrenvoie la prédiction \(\mathbf{\hat{Y}}\) sur le batch (taille \(tb\times 10\)).On pourra utiliser la fonction suivante pour calculer la fonction softmax sur chaque élément de de la matrice de la projection linéraire (taille \(tb\times 10\)) :
def softmax(X):
# Input matrix X of size Nbxd - Output matrix of same size
E = np.exp(X)
return (E.T / np.sum(E,axis=1)).T
Compléter le code pour la passe backward, consistant à : - Calculer les gradient comme indiqué aux équations (4) et (5). - Mettre à jour les paramètres par descente de gradient comme indiqué aux équations (6) et (7).
Enfin vous pouvez utiliser la fonction accuracy(W, b, images, labels) fournie pour calculer le taux de bonne reconnaissance du modèle. Ceci permettra de mesurer l’évolution des performances au cours des époques de l’algorithme d’apprentissage, et sur la base de test une fois le modèle appris.
Vous devez obtenir un score de l’ordre de 92% sur la base de test pour ce modèle de régression logistique.
def accuracy(W, b, images, labels):
pred = forward(images, W,b )
return np.where( pred.argmax(axis=1) != labels.argmax(axis=1) , 0.,1.).mean()*100.0
Exercice 2 : Perceptron multi-couches (MLP)¶
L’objectif de ce second exercice est d’étendre le modèle de régression logistique afin de mettre en place des modèles de prédictions plus riches. En particulier, on va s’intéresser aux Perceptron multi-couches (Multi-Layer Percpetron, MLP). Contrairement à la régression logistique qui se limite à des séparateurs linéaires, le Perceptron permet l’apprentissage de frontières de décisions non linéaires, et constituent des approximateurs universels de fonctions.
L’objectif de la séance de travaux pratiques est de mettre en place le code pour effectuer des prédictions et entraîner un Perceptron à une couche cachée.
Prédiction avec un Perceptron (Forward)¶
L’architecture du perpcetron à une couche cachée est montrée à la figure ci-dessous.
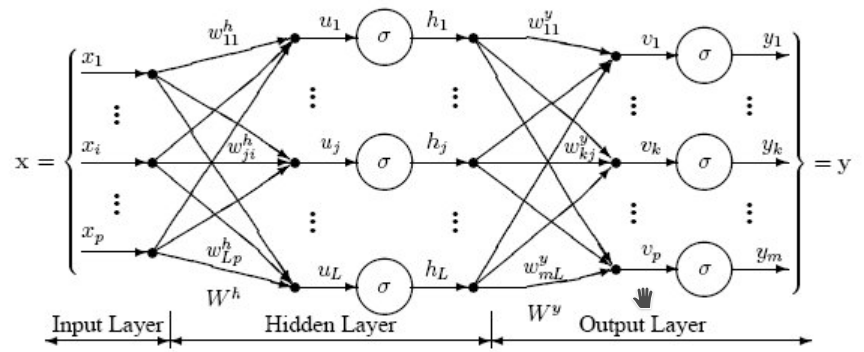
Si on considère les données de la base MNIST, chaque image est représentée par un vecteur de taille \(28^2=784\). Le perpcetron va effecteur les différentes étape de transformation pour produire la prédiction finale, i.e. la catégorie sémantique de l’image :
Une étape de projection linéaire, qui va projeter chaque image sur un vecteur de taille \((1,L)\), e.g. \(L=100\). En considérant chaque exemple \(\mathbf{x_i}\) est un vecteur ligne - taille \((1,784)\) - la projection linéaire peut être représentée par la matrice \(\mathbf{W^h}\) (taille \((784, L)\)), et le vecteur de biais \(\mathbf{b^h}\) (taille \((1, L)\)) : \(\mathbf{\hat{u_i}} =\mathbf{x_i} \mathbf{W^h} + \mathbf{b^h}\).
Une étape de non linéarité, e.g. de type sigmoïde : \(\forall j \in \left\lbrace 1; L \right\rbrace ~ h_{i,j} = \frac{1}{1+exp(-u_{i,j})}\)
Une seconde étape de projection linéaire, qui va projeter le vecteur latent de taille \((1,L)\) sur un vecteur de taille \((1,K)=10\) (nombre de classes). Cette opération de projection linéaire sera représentée par la matrice \(\mathbf{W^y}\) (taille \((L, K)\)), et le vecteur de biais \(\mathbf{b^y}\) (taille \((1, K)\)) : \(\mathbf{\hat{v_i}} =\mathbf{h_i} \mathbf{W^y} + \mathbf{b^y}\).
Une étape de non linéarité de type soft-max vue la semaine précédente pour la régression logistique : \(\forall j \in \left\lbrace 1; K \right\rbrace ~ y_{i,j} = \frac{exp(v_{i,j})}{\sum\limits_{i=1}^K exp(v_{i,k})}\)
On demande de mettre en place un script mlp.py qui implémente l’alogorithme du Percpetron sur la base MNIST.
- L’algorithme reprendra le squelette du code de la régression logistique. Pour adapter ce code pour le Perceptron pour la partie prédiction, vous devez :
Modifier la fonction de prédiction, afin disposer la fonction
forward(batch, Wh, bh, Wy, by)qui reverra à la fois la prédiction pour le batch ainsi que la matrice des couches latentes.
Si on considère un batch des données de taille \(t_b\times 784\), les paramètres \(\mathbf{W^h}\) (taille \(784\times L\)), \(\mathbf{b^h}\) (taille \(1\times L\)), \(\mathbf{W^y}\) (taille \(L\times K\)) et \(\mathbf{b^y}\) (taille \(1\times K\)), la fonction
forwardrenvoie la prédiction \(\mathbf{\hat{Y}}\) sur le batch (taille \(t_b\times K\)) et la matrice de variables latentes (taille \(t_b\times L\)).
Apprentissage du Perceptron (Backward)¶
Afin d’entraîner le Perceptron, on va utiliser l’algorithme de rétro-propagation de l’erreur. On rappelle que pour chaque batch d’exemples, l’algorithme va effectuer une passe forward (Exercice 1), permettant de calculer la prédiction du réseau.
Une fonction de coût (ici l’entropie croisée) entre la sortie prédite et la la sortie donnée par la supervision va permettre de calculer le gradient de l’erreur par rapport à tous les paramètres paramètres du modèle, i.e. \(\mathbf{W^y}\) (taille \((L, K)\)), \(\mathbf{b^y}\) (taille \((1, K)\)), \(\mathbf{W^h}\) (taille \((784, L)\)), et \(\mathbf{b^h}\) (taille \((1, L)\)).
On rappelle les équation des gradients, effectuées depuis le haut vers le bas du réseau :
Mise à jour de \(\mathbf{W^y}\) et \(\mathbf{b^y}\) :
Où \(\mathbf{H}\) est la matrice des couches cachées sur le batch (taille \(t_b\times L\)), \(\mathbf{\hat{Y}}\) est la matrice des labels prédits sur l’ensemble de la base d’apprentissage (taille \(t_b\times K\)) et \(\mathbf{Y^*}\) est la matrice des labels donnée issue de la supervision (« ground truth », taille \(t_b\times K\)), et \(\mathbf{\Delta^y}=\mathbf{\hat{Y}}-\mathbf{Y^*}\).
Mise à jour de \(\mathbf{W^h}\) et \(\mathbf{b^h}\) :
Où \(\mathbf{X}\) est la matrice des données sur le batch (taille \(t_b\times 784\)), et \(\mathbf{\Delta^h}\) est la matrice des \(\delta^h_i\) sur le batch (taille \(t_b\times L\)).
Adapter la partie backward de l’algorithme pour entraîner le Perceptron. On Choisira un pas de gradient \(\eta=1.0\) et 100 époques.
Question : la fonction de coût de l’Eq. (3) est-elle convexe par rapports aux paramètres \(\mathbf{W}\), \(\mathbf{b}\) du modèle ? Avec un pas de gradient bien choisi, peut-on assurer la convergence vers le minimum global de la solution ?
Tester en initialisant les matrices à 0 comme pour la régression logistique. Quelles performances obtenez-vous ? Que peut-on en conclure ?
Vous testerez deux autres initialisations : une qui initialise les poids avec une loi normale de moyenne nulle et d’écart type à fixer, e.g. \(10^-1\), et une autre connue sous le nom de Xavier, qui divise la valeur de la Gaussienne par \(\sqrt{ni}\), où ni est le nombre de neurone dans la couche d’entrée.
Évaluer les performances du modèle. Vous devez obtenir un score de l’ordre de 98% sur la base de test pour ce réseau de neurones à une couche cachée.