TP 5 - Vision et language¶
Dans ce TP, nous abordons le problème du légendage d’images (« image captioning »), qui consiste à décrire le contenu visuel d’une image par une phrase en language naturel. Nous allons mettre en place une version simplifié de l’approche « show and tell » [VTBE15].
Le modèle va analyser une image en entrée, et à partir d’un symbole de début de séquence (“<start>”), va apprendre à générer le mot suivant de la légende. D’une manière générale, à partit d’un sous-ensemble de mot de la phrase généré et l’image d’entrée, l’objectif va être d’apprendre au modèle à générer le mot suivant, jusqu’à arriver au symbole de fin de génération (“<end>”).
Exercice 1 : Simplification du vocabulaire¶
Pour accélérer le temps nécessaire à l’entraînement du modèle, nous allons considérer un sous-ensemble du vocabulaire de mots considéré au TP précédent (voir Exercice 2 : Embedding Vectoriel de texte). On pourra utiliser le code suivant pour extraire un histogramme d’occurrence des mots présents dans les légendes du sous-ensemble d’apprentissage de la base Flickr8k :
import pandas as pd
import _pickle as pickle
import matplotlib.pyplot as plt
import numpy as np
filename = 'flickr_8k_train_dataset.txt'
df = pd.read_csv(filename, delimiter='\t')
nb_samples = df.shape[0]
iter = df.iterrows()
bow = {}
nbwords = 0
for i in range(nb_samples):
x = iter.__next__()
cap_words = x[1][1].split() # split caption into words
cap_wordsl = [w.lower() for w in cap_words] # remove capital letters
nbwords += len(cap_wordsl)
for w in cap_wordsl:
if (w in bow):
bow[w] = bow[w]+1
else:
bow[w] = 1
bown = sorted([(value,key) for (key,value) in bow.items()], reverse=True)
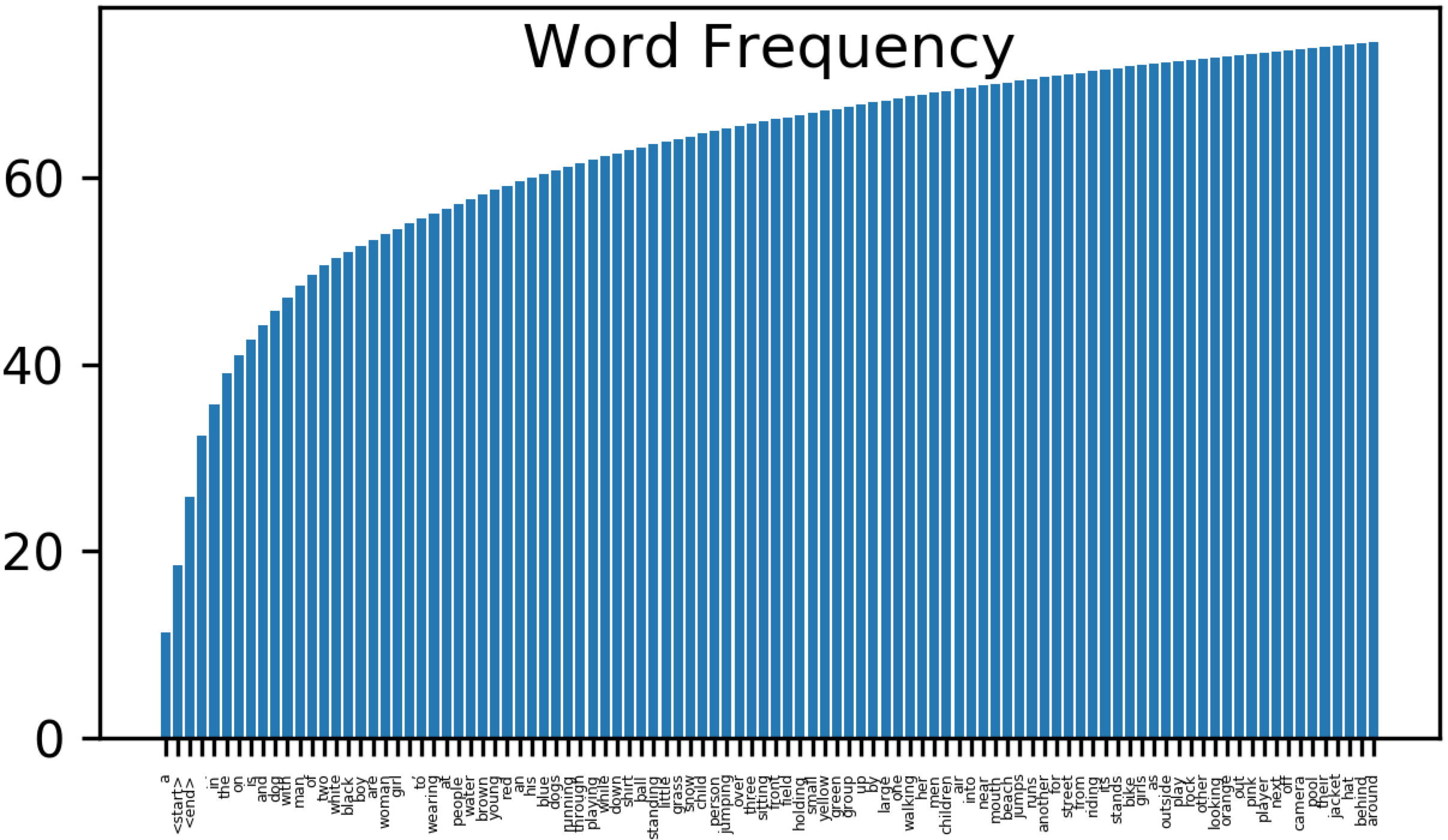
On pourra calculer la fréquence cumulée des 1000 premiers mots conservés :
nbkeep = 1000 # 100 is needed for fast processing
freqnc = np.cumsum([float(w[0])/nbwords*100.0 for w in bown])
print("number of kept words="+str(nbkeep)+" - ratio="+str(freqnc[nbkeep-1])+" %")
Et affichier la liste des 100 premiers mots :
x_axis = [str(bown[i][1]) for i in range(100)]
plt.figure(dpi=300)
plt.xticks(rotation=90, fontsize=3)
plt.ylabel('Word Frequency')
plt.bar(x_axis, freqnc[0:100])
On va charger le fichier d’embedding utilisé au TP précédent (que l’on peut récupérer ici : http://cedric.cnam.fr/~thomen/cours/US330X/Caption_Embeddings.p), et conserver les ``nbkeep`` (=1000) mots les plus fréquents, et sauvegarder le sous-ensemble de mots et les embeddings vectoriels Glove correspondants :
nbkeep = 1000 # 100 is needed for fast processing
outfile = 'Caption_Embeddings.p'
[listwords, embeddings] = pickle.load( open( outfile, "rb" ) )
embeddings_new = np.zeros((nbkeep,102))
listwords_new = []
for i in range(nbkeep):
listwords_new.append(bown[i][1])
embeddings_new[i,:] = # COMPLETE WITH YOUR CODE
embeddings_new[i,:] /= np.linalg.norm(embeddings_new[i,:]) # Normalization
listwords = listwords_new
embeddings = embeddings_new
outfile = "Caption_Embeddings_"+str(nbkeep)+".p"
with open(outfile, "wb" ) as pickle_f:
pickle.dump( [listwords, embeddings], pickle_f)
Exercice 2 : Création des données d’apprentissage et de test¶
Nous allons maintenant stocker les données d’entraînement, *i.e.* les tenseurs contenant les données et les labels. Le tenseur des données \(\mathbf{X}\) sera de taille \(N_s \times L_s \times d\) où \(N_s\) est le nombre de séquence (légendes), \(L_s\) est la longueur de la séquence et \(d\) est la taille du vecteur décrivant chaque mot de la séquence.
Les fichiers sources contenant les identifiants des images et les légendes des images sont disponibles :
Ici pour l’apprentissage : http://cedric.cnam.fr/~thomen/cours/US330X/flickr_8k_train_dataset.txt
Ici pour le test : http://cedric.cnam.fr/~thomen/cours/US330X/flickr_8k_test_dataset.txt
Comme on doit utiliser des tenseurs de taille fixe avec keras, on va déterminer la longueur de la légende maximale dans les données d’entraînement :
filename = 'flickr_8k_train_dataset.txt'
df = pd.read_csv(filename, delimiter='\t')
nbTrain = df.shape[0]
iter = df.iterrows()
caps = [] # Set of captions
imgs = [] # Set of images
for i in range(nbTrain):
x = iter.__next__()
caps.append(x[1][1])
imgs.append(x[1][0])
maxLCap = 0
for caption in caps:
l=0
words_in_caption = caption.split()
for j in range(len(words_in_caption)-1):
current_w = words_in_caption[j].lower()
if(current_w in listwords):
l+=1
if(l > maxLCap):
maxLCap = l
print("max caption length ="+str(maxLCap))
Chaque élément \(e_i\) d’une séquence d’entrée va être décrit par par un vecteur \(x_i \in \mathbb{R}^d\) (avec ici \(d=202\)) correspondant à :
La description du contenu du \(i^{\grave{e}me}\) mot de la légende, pour laquelle on utilisera l’embedding vectoriel Glove (voir TP précédent Exercice 2 : Embedding Vectoriel de texte). Ceci correspondra aux 102 premières composantes de \(x_i\).
La description du contenu visuel de l’image, obtenue par le calcul de « Deep Features » (voir TP 3 - Transfer Learning et Fine-Tuning), ici en utilisant un réseau convolutif profond de type VGG [SZ15]. La dimension du vecteur résultant (ici 4096) a été réduite à 100 par Analyse en Composantes Principales (ACP). Ceci correspondra aux 100 dernières composantes de \(x_i\). Ce vecteur de dimension 100 pour chaque image de la base est fourni : http://cedric.cnam.fr/~thomen/cours/US330X/encoded_images_PCA.p
La sortie du réseau récurrent est une séquence de la même taille que l’entrée, où chaque élément correspond à la prédiction du mot suivant. Chaque séquence de sortie se terminera donc toujours par “<end>”. Le vocabulaire ayant été simplifié à l’exercice 1, on ne conservera dans les séquences d’entrée et de sortie que les mots de la légende présents dans le dictionnaire réduit.
On demande de compléter le code suivant pour construire les tenseurs des données et des labels :
outfile = "Caption_Embeddings_"+str(nbkeep)+".p"
[listwords, embeddings] = pickle.load( open( outfile, "rb" ) ) # Loading reduced dictionary
indexwords = {} # Useful for tensor filling
for i in range(len(listwords)):
indexwords[listwords[i]] = i
# Loading images features
encoded_images = pickle.load( open( "encoded_images_PCA.p", "rb" ) )
# Allocating data and labels tensors
tinput = 202
tVocabulary = len(listwords)
X_train = np.zeros((nbTrain,maxLCap, tinput))
Y_train = np.zeros((nbTrain,maxLCap, tVocabulary), bool)
for i in range(nbTrain):
words_in_caption = caps[i].split()
indseq=0 # current sequence index (to handle mising words in reduced dictionary)
for j in range(len(words_in_caption)-1):
current_w = words_in_caption[j].lower()
if(current_w in listwords):
X_train[i,indseq,0:100] = # COMPLETE WITH YOUR CODE
X_train[i,indseq,100:202] = # COMPLETE WITH YOUR CODE
next_w = words_in_caption[j+1].lower()
if(next_w in listwords):
index_pred = # COMPLETE WITH YOUR CODE
Y_train[i,indseq,index_pred] = # COMPLETE WITH YOUR CODE
indseq += 1 # Increment index if target label present in reduced dictionary
outfile = 'Training_data_'+str(nbkeep)
np.savez(outfile, X_train=X_train, Y_train=Y_train) # Saving tensor
On fera la même chose pour les données de test, en allouant des tenseurs de la même taille que ceux d’entraînement (et pouvoir ainsi appliquer le modèle de prédiction ensuite).
Exercice 3 : Entraînement du modèle¶
On va maintenant définir l’architecture du modèle pour apprendre à prédire le mot suivant à partir d’une sous-séquence donnée et d’une image. Après avoir instancié un modèle Sequential vide, on va donc définir :
Une couche de
Masking, voir la documentation https://keras.io/layers/core/#masking. On doit préciser la taille d’entrée de chaque exemple (séquence), i.e. \(L_s \times d\) (\(L_s\) longueur de la séquence et \(d\) taille de chaque élément de la séquence).
Cette couche de
Maskingva permettre de ne pas calculer d’erreur dans les zones où le tenseur d’entrée sera à une valeur donné (e.g. 0), ce qui correspondra au zones de la séquence d’entrée où aucun mot n’est présent (du fait de la nécessité d’avoir un tenseur de taille fixe, donc une longeur de séquence correspondant à la séquence de longueur maximale dans la base d’apprentissage).
Une couche de réseau récurrent de type
SimpleRNN. On prendra 100 neurones dans la couche cachée. On utiliserreturn_sequences=Truepour renvoyer la prédiction pour chaque élément de la séquence d’entrée, et égalementunroll=True.Une couche complètement connectée, suivie d’une fonction d’activation softmax.
Pour apprendre le modèle, on va définir un fonction de coût d’entropie croisée, qui va être directement appliqué à chacun des élément de sortie. On utilisera l’optimiseur Adam, avec le pas de gradient par défaut. On choisira une taille de batch de 10 exemples (i.e. 10 légendes, l’erreur de classification sur chaque légende étant calculée comme une moyenne des prédictions sur chaque mot).
Une fois le modèle entraîné on le sauvera avec la fonction habituelle :
from keras.models import model_from_yaml
def saveModel(model, savename):
# serialize model to YAML
model_yaml = model.to_yaml()
with open(savename+".yaml", "w") as yaml_file:
yaml_file.write(model_yaml)
print("Yaml Model ",savename,".yaml saved to disk")
# serialize weights to HDF5
model.save_weights(savename+".h5")
print("Weights ",savename,".h5 saved to disk")
On évaluera les performances sur la base d’apprentissage avec la méthode
evaluate().
Exercice 4 : Évaluation du modèle¶
Finalement, on va utiliser le réseau récurrent pour générer une légende sur une image de test, et analyser qualitativement le résultat. On peut télécharger la base d’images ici : http://cedric.cnam.fr/~thomen/cours/US330X/Flickr8k_Dataset.zip
N.B. : en test, on dispose uniquement d’une image, et le système va, à partir du symbole “<start>”, itérativement produire une séquence de mots jusqu’à générer le symbole de fin de séquence”<end>”
On va commencer par charger un modèle appris, les données de test et les embeddings vectoriels avec le dictionnaire réduit :
def loadModel(savename):
with open(savename+".yaml", "r") as yaml_file:
model = model_from_yaml(yaml_file.read())
print "Yaml Model ",savename,".yaml loaded "
model.load_weights(savename+".h5")
print "Weights ",savename,".h5 loaded "
return model
# LOADING MODEL
nameModel = # COMPLETE with your model name
model = loadModel(nameModel)
optim = Adam()
model.compile(loss="categorical_crossentropy", optimizer=optim,metrics=['accuracy'])
# LOADING TEST DATA
outfile = 'Testing_data_'+str(nbkeep)+'.npz'
npzfile = np.load(outfile)
X_test = npzfile['X_test']
Y_test = npzfile['Y_test']
outfile = "Caption_Embeddings_"+str(nbkeep)+".p"
[listwords, embeddings] = pickle.load( open( outfile, "rb" ) )
indexwords = {}
for i in range(len(listwords)):
indexwords[listwords[i]] = i
On va ensuite sélectionner une image parmi l’ensemble de test, l’afficher, ainsi qu’une légende issues des annotations.
ind = np.random.randint(X_test.shape[0])
filename = 'flickr_8k_test_dataset.txt' # PATH IF NEEDED
df = pd.read_csv(filename, delimiter='\t')
iter = df.iterrows()
for i in range(ind+1):
x = iter.__next__()
imname = x[1][0]
print("image name="+imname+" caption="+x[1][1])
dirIm = "data/flickr8k/Flicker8k_Dataset/" # CHANGE WITH YOUR DATASET
img=mpimg.imread(dirIm+imname)
plt.figure(dpi=100)
plt.imshow(img)
plt.axis('off')
plt.show()
Pour effecteur la prédiction, on va partir du premier élément de la séquence (*i.e.* contenant l’image et le symbole “<start>”), et effectuer la prédiction :
pred = model.predict(X_test[ind:ind+1,:,:])
On va ensuite pouvoir effectuer plusieurs générations de légendes, en échantillonnant le mot de suivant à partir de la distribution *a posteriori* issue du softmax, comme ceci a été fait dans la partie c) Génération de texte avec le modèle appris du TP 4 - Réseaux de neurones récurrents (voir la fonction sampling). Une fois le mot suivant échantillonné, on place son embedding vectoriel comme entrée pour l’élément suivant de la séquence, et la prédiction continue (jusqu’à arriver au symbole de fin de séquence <”end”>).
On pourra donc compléter le code suivant pour générer les légendes :
nbGen = 5
temperature=0.1 # Temperature param for peacking soft-max distribution
for s in range(nbGen):
wordpreds = "Caption n° "+str(s+1)+": "
indpred = sampling(pred[0,0,:], temperature)
wordpred = listwords[indpred]
wordpreds +=str(wordpred)+ " "
X_test[ind:ind+1,1,100:202] = # COMPLETE WITH YOUR CODE
cpt=1
while(str(wordpred)!='<end>' and cpt<30):
pred = model.predict(X_test[ind:ind+1,:,:])
indpred = sampling(pred[0,cpt,:], temperature)
wordpred = listwords[indpred]
wordpreds += str(wordpred)+ " "
cpt+=1
X_test[ind:ind+1,cpt,100:202] = # COMPLETE WITH YOUR CODE
print(wordpreds)
Résultats :
Présentez des résultas de légendage sur différentes images. Vous pouvez tester avec un vocabulaire simplifié à 100 mots puis à 1000 mots. Voici quelques résultats obtenus avec un vocabulaire de taille 1000 :






Enfin, on va pouvoir calculer la métrique de blue score après avoir déterminé les prédictions de tous les exemples. On pourra se baser sur le code suivant :
from keras.optimizers import RMSprop, Adam
from keras.models import model_from_yaml
import pandas as pd
import numpy as np
import nltk
# LOADING TEST DATA
nbkeep = 1000
outfile = "path" # REPLACE WITH YOUR DATA PATH
outfile += 'Testing_data_'+str(nbkeep)+'.npz'
npzfile = np.load(outfile)
X_test = npzfile['X_test']
Y_test = npzfile['Y_test']
# LOADING MODEL
nameModel = "" REPLACE WITH YOUR MODEL NAME
model = loadModel(nameModel)
# COMPILING MODEL
optim = Adam()
model.compile(loss="categorical_crossentropy", optimizer=optim,metrics=['accuracy'])
scores_test = model.evaluate(X_test, Y_test, verbose=1)
print("PERFS TEST: %s: %.2f%%" % (model.metrics_names[1], scores_test[1]*100))
# LOADING TEXT EMBEDDINGS
outfile = "Caption_Embeddings_"+str(nbkeep)+".p"
[listwords, embeddings] = pickle.load( open( outfile, "rb" ) )
indexwords = {}
for i in range(len(listwords)):
indexwords[listwords[i]] = i
# COMPUTING CAPTION PREDICTIONS ON TEST SET
predictions = []
nbTest = X_test.shape[0]
for i in range(0,nbTest,5):
pred = model.predict(X_test[i:i+1,:,:])
wordpreds = []
indpred = np.argmax(pred[0,0,:])
wordpred = listwords[indpred]
wordpreds.append(str(wordpred))
X_test[i,1,100:202] = embeddings[indpred]
cpt=1
while(str(wordpred)!='<end>' and cpt<(X_test.shape[1]-1)):
pred = model.predict(X_test[i:i+1,:,:])
indpred = np.argmax(pred[0,cpt,:])
wordpred = listwords[indpred]
if(wordpred !='<end>'):
wordpreds.append(str(wordpred))
cpt+=1
X_test[i,cpt,100:202] = embeddings[indpred]
if(i%1000==0):
print("i="+str(i)+" "+str(wordpreds))
predictions.append(wordpreds)
# LOADING GROUD TRUTH CAPTIONS ON TEST SET
references = []
filename = 'flickr_8k_test_dataset.txt'
df = pd.read_csv(filename, delimiter='\t')
iter = df.iterrows()
ccpt =0
for i in range(nbTest//5):
captions_image = []
for j in range(5):
x = iter.__next__()
ll = x[1][1].split()
caption = []
for k in range(1,len(ll)-1):
caption.append(ll[k])
captions_image.append(caption)
ccpt+=1
references.append(captions_image)
# COMPUTING BLUE-1, BLUE-2, BLUE-3, BLUE-4
blue_scores = np.zeros(4)
weights = np.zeros((4,4))
weights[0,0] = 1
weights[1,0] = 0.5
weights[1,1] = 0.5
weights[2,0] = 1.0/3.0
weights[2,1] = 1.0/3.0
weights[2,2] = 1.0/3.0
weights[3,:] = 1.0/4.0
for i in range(4):
blue_scores[i] = nltk.translate.bleu_score.corpus_bleu(references, predictions, weights = (weights[i,0], weights[i,1], weights[i,2], weights[i,3]) )
print("blue_score - "+str(i)+"="+str( blue_scores[i]))
Question :
Quelles valeurs de blue scores obtenez-vous ?
- SZ15
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations (ICLR). 2015.
- VTBE15
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015.