TP 4 - Réseaux de neurones récurrents¶
L’objectif de ce TP est d’utiliser des réseaux de neurones récurrents pour l’analyse de données séquentielles.
Exercice 1 : Génération de poésie¶
Une première application va consister à apprendre à générer du texte. Nous allons partir d’une base de données d’un recueil de poésies, « les fleurs de mal » de Charles Baudelaire. On pourra récupérer le fichier d’entrée à l’adresse suivante: http://cedric.cnam.fr/~thomen/cours/US330X/fleurs_mal.txt.
a) Génération des données et étiquettes¶
On créera un script exo0.py pour générer les données et étiquettes. On va commencer par parser le ficher d’entrée pour récupérer le texte et effectuer quelques pré-traitements simples:
bStart = False
fin = open("fleurs_mal.txt", 'r' , encoding = 'utf8')
lines = fin.readlines()
lines2 = []
text = []
for line in lines:
line = line.strip().lower() # Remove blanks and capitals
if("Charles Baudelaire avait un ami".lower() in line and bStart==False):
print("START")
bStart = True
if("End of the Project Gutenberg EBook of Les Fleurs du Mal, by Charles Baudelaire".lower() in line):
print("END")
break
if(bStart==False or len(line) == 0):
continue
lines2.append(line)
fin.close()
text = " ".join(lines2)
chars = sorted(set([c for c in text]))
nb_chars = len(chars)
Question :
Comment s’interprète la variable chars ? Que représente nb_chars ?
Dans la suite, on va considérer chaque caractère du texte d’entrée par un encodage one-hot sur le dictionnaire de symboles.
On va appliquer un réseau de neurones récurrent qui va traiter une séquence de SEQLEN caractères, et dont l’objectif va être de prédire le caractère suivant en fonction de la séquence courante. On se situe donc dans le cas d’un problème d’apprentissage auto-supervisé, i.e. qui ne contient pas de label mais dont on va construire artificiellement une supervision.
Les données d’entraînement consisteront donc en un ensemble de séquences d’entraînement de taille SEQLEN, avec une étiquette cible correspondant au prochain caractère à prédire.
SEQLEN = 10 # Length of the sequence to predict next char
STEP = 1 # stride between two subsequent sequences
input_chars = []
label_chars = []
for i in range(0, len(text) - SEQLEN, STEP):
# Append input of size SEQLEN
# Append output (label) of size 1
nbex = len(input_chars)
On va maintenant vectoriser les données d’entraînement en utilisant le dictionnaire et un encodage one-hot pour chaque caractère.
# mapping char -> index in dictionary: used for encoding (here)
char2index = dict((c, i) for i, c in enumerate(chars))
# mapping char -> index in dictionary: used for decoding, i.e. generation - part c)
index2char = dict((i, c) for i, c in enumerate(chars)) # mapping index -> char in dictionary
Chaque séquence d’entraînement est donc représentée par une matrice de taille \(SEQLEN \times tdict\), correspondant à une longueur de \(SEQLEN\) caractères, chaque caratère étant encodé par un vecteur binaire correspondant à un encodage one-hot.
L’ensemble des données d’entraînement
Xseront donc constituées par un tenseur de taille \(nbex \times SEQLEN \times tdict\)L’ensemble des labels d’entraînement
yseront représentées par un tenseur de \(nbex \times tdict\), où la sortie pour chaque exemple correspond à l’indice dans le dictionnaire du caractère suivant la séquence
Question :
Compléter le code suivant pour créer les données et labels d’entraînement. N.B. : utiliser la variable char2index.
import numpy as np
X = np.zeros((len(input_chars), SEQLEN, nb_chars), dtype=np.bool)
y = np.zeros((len(input_chars), nb_chars), dtype=np.bool)
for i, input_char in enumerate(input_chars):
for j, ch in enumerate(input_char):
# Fill X at correct index
# Fill y at correct index
On va maintenant séparer les données en deux ensembles d’apprentissage et de test, et les sauvegarder
import _pickle as pickle
ratio_train = 0.8
nb_train = int(round(len(input_chars)*ratio_train))
print("nb tot=",len(input_chars) , "nb_train=",nb_train)
X_train = X[0:nb_train,:,:]
y_train = y[0:nb_train,:]
X_test = X[nb_train:,:,:]
y_test = y[nb_train:,:]
print("X train.shape=",X_train.shape)
print("y train.shape=",y_train.shape)
print("X test.shape=",X_test.shape)
print("y test.shape=",y_test.shape)
outfile = "Baudelaire_len_"+str(SEQLEN)+".p"
with open(outfile, "wb" ) as pickle_f:
pickle.dump( [index2char, X_train, y_train, X_test, y_test], pickle_f)
b) Apprentissage d’un modèle auto-supervisé pour la génération de texte¶
On va maintenant créer exo1.py pour entraîner un réseau de neurone récurrent. On va commencer par charger les données précédentes :
SEQLEN = 10
outfile = "Baudelaire_len_"+str(SEQLEN)+".p"
[index2char, X_train, y_train, X_test, y_test] = pickle.load( open( outfile, "rb" ) )
Puis créer un modèle séquentiel :
from keras.layers.recurrent import SimpleRNN
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD, RMSprop
model = Sequential()
Puis on va ajouter une couche récurrente avec un modèle de type ``SimpleRNN`` :
HSIZE = 128
model.add(SimpleRNN(HSIZE, return_sequences=False, input_shape=(SEQLEN, nb_chars),unroll=True))
Question :
Expliquer à quoi correspond
return_sequences=False. N.B. :unroll=Truepermettra simplement d’accélérer les calculs.
On ajoutera enfin une couche complètement connectée suivie d’une fonction softmax for effectuer la classification du caractère suivant la séquence.
# ADD FULLY CONNECTED LAYER (output size ?)
# ADD SOFTMAX
Pour optimiser des réseaux récurrents, on utilise préférentiellement des méthodes adaptatives comme RMSprop [TH12]. On pourra donc compiler le modèle et utiliser la méthode summary() pour visualiser le nombre de paramètres du réseaux
BATCH_SIZE = 128
NUM_EPOCHS = 50
learning_rate = 0.001
# CREATE OPTIMIZER & COMPILE
model.summary()
L’entraînement sera effectuer comme habituellement avec la méthode fit():
# FIT MODEL TO DATA
# EVALUATE TRAINED MODEL
scores_train = model.evaluate(X_train, y_train, verbose=1)
scores_test = model.evaluate(X_test, y_test, verbose=1)
print("PERFS TRAIN: %s: %.2f%%" % (model.metrics_names[1], scores_train[1]*100))
print("PERFS TEST: %s: %.2f%%" % (model.metrics_names[1], scores_test[1]*100))
On pourra utiliser la méthode saveModel pour stocker le modèle appris :
from keras.models import model_from_yaml
def saveModel(model, savename):
# serialize model to YAML
model_yaml = model.to_yaml()
with open(savename+".yaml", "w") as yaml_file:
yaml_file.write(model_yaml)
print("Yaml Model ",savename,".yaml saved to disk")
# serialize weights to HDF5
model.save_weights(savename+".h5")
print("Weights ",savename,".h5 saved to disk")
Analyse de l’apprentissage
Quel taux de classification obtient-on en apprentissage ? Commenter les performances obtenues.
En quoi le problème est-il différents des problèmes de classification abordés jusqu’ici ? Par exemple, faire une recherche de la séquence d’entrée « la mort de », et analyser les labels cibles présents dans le corpus d’apprentissage.
c) Génération de texte avec le modèle appris¶
On va maintenant se servir du modèle précédemment entraîné pour générer du texte qui va « imiter » le style du corpus de poésie sur lequel il a été appris. On mettre en place un script
exo2.pypour cette partie.On va commencer par charger les données :
SEQLEN = 10
outfile = "Baudelaire_len_"+str(SEQLEN)+".p"
[index2char, X_train, y_train, X_test, y_test] = pickle.load( open( outfile, "rb" ) )
Et le réseau récurrent avec la fonction loadModel :
from keras.models import model_from_yaml
def loadModel(savename):
with open(savename+".yaml", "r") as yaml_file:
model = model_from_yaml(yaml_file.read())
print("Yaml Model ",savename,".yaml loaded ")
model.load_weights(savename+".h5")
print("Weights ",savename,".h5 loaded ")
return model
On pourra vérifier l’architecture du réseau avec la méthode summary, et évaluer les performances :
model = loadModel(nameModel)
model.compile(loss='categorical_crossentropy',optimizer='RMSprop',metrics=['accuracy'])
model.summary()
nb_chars = len(index2char)
On va maintenant sélectionner une chaîne de caractère initiale pour notre réseau, afin de prédire le caractère suivant :
seed =15608
char_init = ""
for i in range(SEQLEN):
char = index2char[np.argmax(X_train[seed,i,:])]
char_init += char
print("CHAR INIT: "+char_init)
On va convertir la séquence de départ au format one-hot pour appliquer le modèle de prédiction.
test = np.zeros((1, SEQLEN, nb_chars), dtype=np.bool)
test[0,:,:] = X_train[seed,:,:]
Au lieu de prédire directement la sortie de probabilité maximale, on va échantillonner une sortie tirée selon la distribution de probabilités du soft-max. Pour commencer on va utiliser un paramètre de température pour rendre la distribution plus ou moins piquée. On va transformer la distribution en sortie du soft-max de la façon suivante :
On pourra utiliser la fonction suivante pour effectuer l’échantillonage après transformation de distribution:
def sampling(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
predsN = pow(preds,1.0/temperature)
predsN /= np.sum(predsN)
probas = np.random.multinomial(1, predsN, 1)
return np.argmax(probas)
La figure ci-dessous montre l’impact sur la distribution de cette renormalisation :
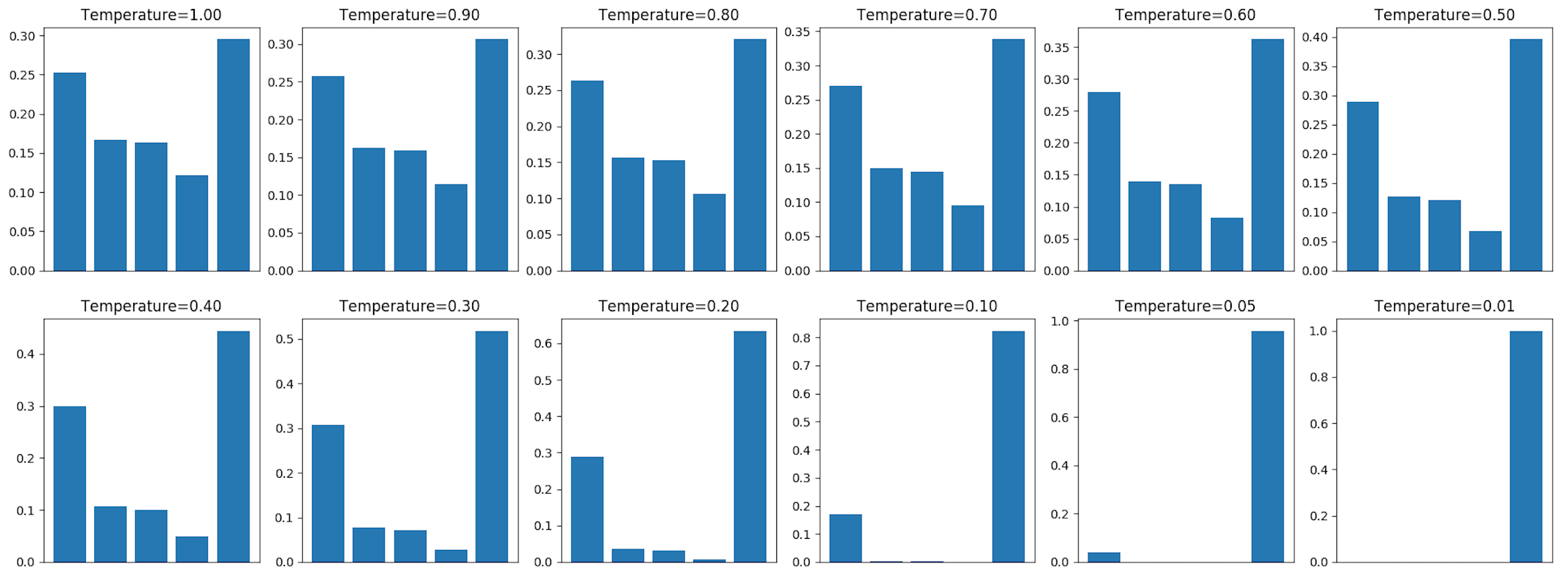
Questions
Quel va être le comportement de cet échantillonnage lorsque la température T augmente (\(T \rightarrow +\infty\)) ou diminue (\(T \rightarrow 0\)) ?
On va maintenant mettre en place la génération de texte à partir d’une séquence de SEQLEN caractère initiaux. Compléter le code suivant :
nbgen = 400 # number of characters to generate (1,nb_chars)
gen_char = char_init
temperature = 0.5
for i in range(nbgen):
preds = model.predict(test)[0] # shape (1,nb_chars)
next_ind = # SAMPLING
next_char = # CONCERT INDEX -> CHAR
gen_char += next_char
for i in range(SEQLEN-1):
test[0,i,:] = test[0,i+1,:]
test[0,SEQLEN-1,:] = 0
test[0,SEQLEN-1,next_ind] = 1
print("Generated text: "+gen_char)
Analyse de la génération
Evaluer l’impact du paramètre de température dans la génération, ainsi que le nombre d’époques dans l’apprentissage. Commenter les points forts et points faibles du générateur.
Exercice 2 : Embedding Vectoriel de texte¶
Dans cet exercice, nous allons explorer l’embedding vectoriel de texte Glove [PSM14] qui sera utilisé dans la TP suivant pour décrire chaque mot d’un corpus dans un objectif de légendage d’images.
On va utiliser la base d’image FlickR8k (http://nlp.cs.illinois.edu/HockenmaierGroup/8k-pictures.html), pour laquelle chaque image est associée à 5 légendes différentes qui décrivent son contenu en langage naturel.
On va commencer par télécharger le fichier qui contient les légendes de la base d’image Flickr 8k : http://cedric.cnam.fr/~thomen/cours/US330X/flickr_8k_train_dataset.txt. La base d’apprentissage contient 6000 images, ce qui correspond à 30000 légendes.
a) Extraction des embedding Glove des légendes¶
On va créer un script exo3.py pour extraire les embedding vectoriaux Glove des légendes de la base Glove.
On utilisera le code suivant pour récupérer l’ensemble des mots présents :
import pandas as pd
filename = 'flickr_8k_train_dataset.txt'
df = pd.read_csv(filename, delimiter='\t')
nb_samples = df.shape[0]
iter = df.iterrows()
allwords = []
for i in range(nb_samples):
x = iter.__next__()
cap_words = x[1][1].split() # split caption into words
cap_wordsl = [w.lower() for w in cap_words] # remove capital letters
allwords.extend(cap_wordsl)
unique = list(set(allwords)) # List of different words in captions
print(len(unique))
On va maintenant télécharger le fichier contenant les Embeddings vectoriels Glove : http://cedric.cnam.fr/~thomen/cours/US330X/glove.6B.100d.txt :
GLOVE_MODEL = "glove.6B.100d.txt"
fglove = open(GLOVE_MODEL, "r")
On déterminer la liste des mots présents dans les légendes et dans le fichier Glove. Compléter le code suivant :
import numpy as np
cpt=0
for line in fglove:
row = line.strip().split()
# word = COMPLETE WITH YOUR CODE
if(word in unique or word=='unk'):
listwords.append(word)
# embedding = COMPLETE WITH YOUR CODE - use a numpy array with dtype="float32"
listembeddings.append(embedding)
cpt +=1
print("word: "+word+" embedded "+str(cpt))
fglove.close()
nbwords = len(listembeddings)
tembedding = len(listembeddings[0])
print("Number of words="+str(len(listembeddings))+" Embedding size="+str(tembedding))
N.B. : on a ajouté le mot “unk” qui est destiné à coder les mots des légendes absents du fichiers d’embedding.
On va finalement créer la matrice des embedding, en ajoutant deux mots pour coder les mots “<start>” et “<end>” (utile pour le TP suivant) :
embeddings = np.zeros((len(listembeddings)+2,tembedding+2))
for i in range(nbwords):
embeddings[i,0:tembedding] = listembeddings[i]
listwords.append('<start>')
embeddings[7001,100] = 1
# APPEND <end> symbol
# FILL embeddings as requested
Question :
Expliquer la taille et le contenu de la matrice embeddings
Et sauvegarder la liste des mots et les vecteurs associés :
import _pickle as pickle
outfile = 'Caption_Embeddings.p'
with open(outfile, "wb" ) as pickle_f:
pickle.dump( [listwords, embeddings], pickle_f)
b) Analyse des embedding Glove des légendes¶
On va commencer par ouvrir le fichier des embeddings, puis à normaliser les vecteurs pour qu’ils aient une norme euclidienne unité :
import numpy as np
import _pickle as pickle
outfile = 'Caption_Embeddings.p'
[listwords, embeddings] = pickle.load( open( outfile, "rb" ) )
print("embeddings: "+str(embeddings.shape))
for i in range(embeddings.shape[0]):
# l2 NORMALIZATION
Question :
Expliquer l’objectif de la normalisation
On va maintenant effectuer un clustering dans l’espace des embeddings en 10 groupes avec l’algorithme du KMeans : https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html. On utilisera max_iter=1000 et init=”random”.
from sklearn.cluster import KMeans
kmeans = # COMPLETE WITH YOUR CODE - apply fit() method on embeddings
clustersID = kmeans.labels_
clusters = kmeans.cluster_centers_
Afin d’afficher les points le point le plus proche de chaque centre, ainsi que les 20 points suivants les plus proche du centre, on pourra utiliser le code suivant :
from sklearn.manifold import TSNE
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.cm as cm
pointsclusters = # INIT - COMPLETE WITH YOUR CODE
indclusters = # INIT - COMPLETE WITH YOUR CODE
for i in range(10):
norm = np.linalg.norm((clusters[i] - embeddings),axis=1)
inorms = np.argsort(norm)
indclusters[i][:] = inorms[:]
print("Cluster "+str(i)+" ="+listwords[indclusters[i][0]])
for j in range(1,21):
print(" mot: "+listwords[indclusters[i][j]])
Question :
Montrer le résultat des centre du clustering obtenu ainsi que les plus proches de chaque centre. Commenter le résultat par rapport à la sémantique des mots.
Pour visualiser la répartition des points dans l’espace d’embedding, on pourra utiliser la méthode t-SNE:
tsne = TSNE(n_components=2, perplexity=30, verbose=2, init='pca', early_exaggeration=24)
points2D = tsne.fit_transform(embeddings)
Et afficher les points des différents clusters ainsi que le centre avec un croix ainsi :
for i in range(10):
pointsclusters[i,:] = points2D[int(indclusters[i][0])]
cmap =cm.tab10
plt.figure(figsize=(3.841, 7.195), dpi=100)
plt.set_cmap(cmap)
plt.subplots_adjust(hspace=0.4 )
plt.scatter(points2D[:,0], points2D[:,1], c=clustersID, s=3,edgecolors='none', cmap=cmap, alpha=1.0)
plt.scatter(pointsclusters[:,0], pointsclusters[:,1], c=range(10),marker = '+', s=1000, edgecolors='none', cmap=cmap, alpha=1.0)
plt.colorbar(ticks=range(10))
plt.show()
Voici un exemple de visualisation :
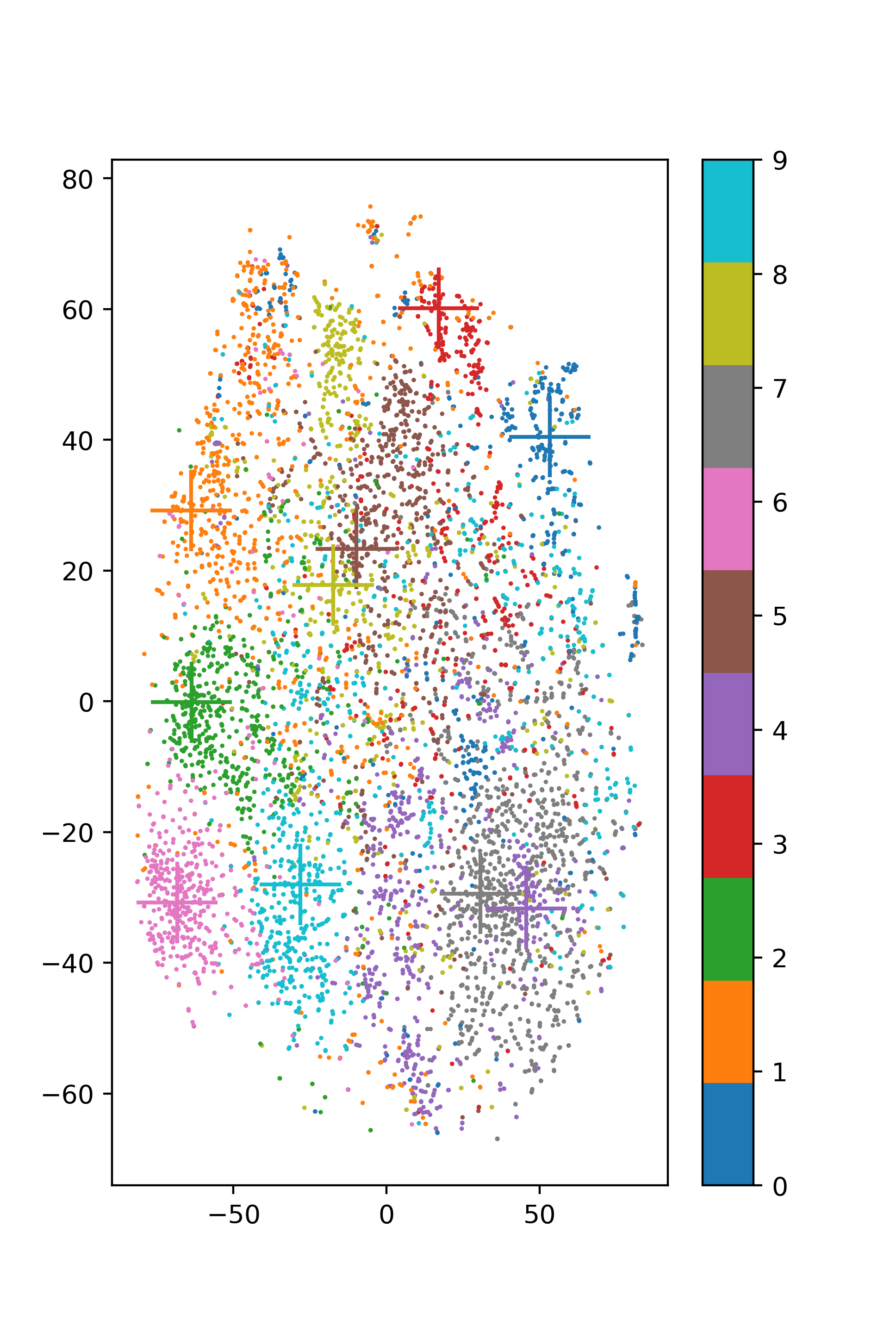
- PSM14
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: global vectors for word representation. In In EMNLP. 2014.
- TH12
T. Tieleman and G. Hinton. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012.