Travaux pratiques - Ordonnancement Structuré¶
On va ici considérer un problème d’ordonnancement (ranking), et on va utiliser une instanciation pour apprendre un modèle de prédiction structurée dont l’objectif sera de minimiser la précision moyenne, Average Precision (AP).
Plus précisément, on considère un problème d’ordonnancement où les différents exemples (ici images de MNIST) présentent un étiquetage binaire de pertinence par rapport à une requête : typiquement la requête va correspondre à une classe (par exemple la classe des images de 8), et l’objectif de l’ordonnancement est de trier les images de sorte que les images pertinentes (label=1, e.g. les 8) soient classées devant les images non pertinentes (label=0, e.g. celles des autres classes que les 8).
Exercice 0 : Modèle baseline et mesure d”Average Precision (AP)¶
On va commencer par considérer une catégorie de la base MNIST comme la requête (e.g. les images de la classe 8). On se ramène donc à un problème de classification binaire, et le code suivant permet d’obtenir les données et labels binaire :
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# Class corresponding to the query
c = 8
# Generate binary labels for class c
y_trainb = np.zeros(60000)
y_testb = np.zeros(10000)
y_trainb[y_train==c] = 1
y_trainb[y_train!=c] = 0
y_testb[y_test==c] = 1
y_testb[y_test!=c] = 0
On va maintenant entraîner un modèle de régression logistique (TP d’introduction à l’apprentissage profond) pour apprendre à reconnaître les images pertinentes (e.g. les 8) des autres. On décrit d’abord l’architecture du modèle :
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD
model = Sequential()
model.add(Dense(1, input_dim=784, name='fc1'))
model.add(Activation('sigmoid'))
model.summary()
Puis on le compile (on choisit ici le loss binary_crossentropy) :
from keras.optimizers import SGD
learning_rate = 1.0
sgd = SGD(learning_rate)
model.compile(loss='binary_crossentropy',optimizer=sgd,metrics=['binary_accuracy'])
Et on l’entraîne sur un sous-ensemble des données d’apprentissage (ici 1000 exemples) :
nbex=1000
batch_size = 100
nb_epoch = 20
model.fit(X_train[0:nbex,:], y_trainb[0:nbex],batch_size=batch_size, epochs=nb_epoch,verbose=1)
On peut ensuite évaluer les performances de la métrique binary_accuracy en apprentissage et en test :
scorestrain = model.evaluate(X_train[0:nbex,:], y_trainb[0:nbex], verbose=0)
scorestest = model.evaluate(X_test, y_testb, verbose=0)
print("perfs train - %s: %.2f%%" % (model.metrics_names[1], scorestrain[1]*100))
print("perfrs test - %s: %.2f%%" % (model.metrics_names[1], scorestest[1]*100))
On va ici s’intéresser à mesurer l’Average Precision (AP) du modèle précédemment appris. Intuitivement l’AP mesure l’ordonnancement correct des exemples, i.e. le fait que les exemples pertinents aient un score supérieur aux exemples non pertinents. On va pour cela tracer une courbe Précision-Rappel (Precision-Recall), qui va calculer pour chaque valeur de score s :
Le rappel, i.e. le nombre d’éléments pertinents sur le nombre d’éléments total qui ont un score supérieur à s,
La précision, i.e. le nombre d’éléments pertinents qui ont un score supérieur à s sur le nombre total d’éléments pertinents.
L’Average Precision (AP) correspond à l’aire sous la courbe Précision-Rappel. On peut tracer la courbe Précision-Rappel, la visualiser et calculer l’AP avec le code suivant (sur la base d’apprentissage, à adapter pour avoir le résultat sur la base de test) :
from sklearn.metrics import average_precision_score
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
# Computing prediction for the training set
predtrain = model.predict(X_train[0:nbex,:])
# Computing precision recall curve
precision, recall, _ = precision_recall_curve(y_trainb[0:nbex], predtrain)
# Computing Average Precision
APtrain = average_precision_score(y_trainb[0:nbex], predtrain)
print "Class ",c," - Average Precision TRAIN=", APtrain*100.0
plt.clf()
plt.plot(recall, precision, lw=2, color='navy',label='Precision-Recall curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('Precision-Recall TRAIN for class '+str(c)+' : AP={0:0.2f}'.format(APtrain*100.0))
plt.legend(loc="lower left")
plt.show()
Voici un exemple de résultat obtenu sur la base d’apprentissage et de test :
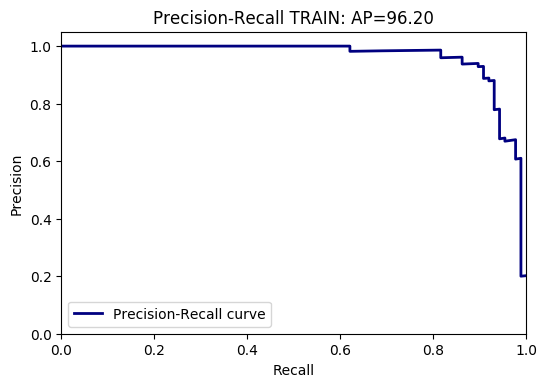
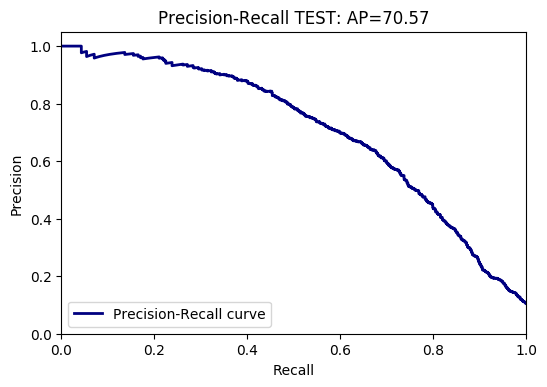
Question :
Quelle est la propriété intéressante de la métrique AP, par exemple par rapport à d’autres métriques comme l’aire sous la courbe ROC (Area Under Curve, AUC)?
Exercice 1 : Instanciation de prédiction structurée pour de l’ordonnancement¶
On va maintenant s’intéresser à mettre en place une instanciation d’un modèle de prédiction structurée pour de l’ordonnancement (ranking) évalué avec une métrique d’Average Precision (AP).
Formellement, dans cette instanciation :
L’entrée \(\mathbf{x} \in \mathcal{X} = \left\lbrace{ \mathbf{d_1},...,\mathbf{d_N} }\right\rbrace\) est un ensemble de N documents (images), où chaque document est un vecteur \(\mathbf{d_i}\) représenté par un vecteur \(\boldsymbol{\phi(d_i)} \in \mathbb{R}^d\) (dans notre cas une image de taille 784). On aura donc lors de l’entraînement un seul exemple constitué de l’ensemble des images.
La sortie structurée \(\mathbf{y} \in \mathcal{Y}\) représente l’ordonnancement de pertinence de chacun des N documents par rapport à une requête : dans notre cas la requête correspond à une classe d’images (par exemple, ordonner toutes les images de 8). Cette sortie sera donc représentée par une liste ordonnée dans laquelle les indices des images apparaissent par ordre de pertinence décroissant par rapport à la requête. On pourra utiliser la classe
RankingOutputpour représenter la sortie structurée :
class RankingOutput():
ranking = []
nbPlus=0
def __init__(self,ranking,nbPlus):
self.nbPlus = nbPlus
self.ranking = ranking
def labelsfromranking(self):
labels = [0 for i in range(len(self.ranking))]
for i in range(self.nbPlus):
labels[self.ranking[i]]=1
return labels
def __getitem__(self, key):
return self
N.B. : Soit \(N_+\) le nombre d’images pertinentes (resp. \(N_-\) le nombre d’images non pertinentes), on peut associer à une sortie donnée un étiquetage binaire des images : les images \(\oplus\) sont celles \(\in \left\lbrace{O; N_+-1}\right\rbrace\) (de la liste ordonnée), les images \(\ominus\) celles \(\in \left\lbrace{N_+;N}\right\rbrace\), voir la fonction labelsfromranking.
Question :
Quelle est la sortie \(\mathbf{y}^* \in \mathcal{Y}\) donnée par la supervision ?
De manière identique, la sortie structurée \(\mathbf{y} \in \mathcal{Y}\) peut être représentée par une matrice de ranking \(\mathbf{Y}\) de taille \(N\times N\) tq :
La fonction \(\Psi( \mathbf{x}, \mathbf{y})\) d’ordonnancement entre l’entrée \(\mathbf{x}\) et la sortie \(\mathbf{y}\) est définie de la manière suivante :
Question :
Quelle est, en utilisant la représentation matricielle \(\mathbf{Y}\) de la sortie structurée donnée à l’Eq. (), la sortie \(\mathbf{Y}^* = \left\lbrace{y_{ij}^{*}}\right\rbrace\), \((i,j) \in \oplus \times \ominus\), donnée par la supervision à l’Eq. () ?
Inférence¶
On rappelle que la sortie prédite par le modèle consiste à résoudre le problème d’inférence, i.e. :
Question :
Quelle est la taille \(|\mathcal{Y}|\) de l’espace \(\mathcal{Y}\) pour la sortie du ranking structuré ? Peut-on faire l’inférence en effectuant un parcours exhaustif de l’espace \(\mathcal{Y}\) ? Montrer que la solution au problème d’inférence de l’Eq. () pour la fonction \(\Psi\) de ranking de l’Eq. () peut être obtenue en triant les exemples par ordre décroissant de \(\langle \mathbf{w} ,\boldsymbol{\phi(d_i)} \rangle\).
Classe SRanking¶
On s’appuiera sur la classe SRanking suivante :
import numpy as np
from keras.utils import np_utils
from sklearn.metrics import average_precision_score
from sklearn.metrics import precision_recall_curve
class SRanking(SModel):
def __init__(self, rankingoutput, d, size, learning_rate=0.1, epochs=2):
SModel.__init__(self,learning_rate, epochs, size)
# Ground Truth labels
self.rankingoutput = rankingoutput
self.d = d
self.w = np.array([0 for i in range(d)])
print "w=",self.w.shape, "d=",d, "nb ex=",len(self.rankingoutput.ranking), " nbPlus=",self.rankingoutput.nbPlus
def predict(self, X):
# Inference: sorting elts wrt <w,x>
pred = -1.0*np.matmul(X,self.w)
# When predicting, number of + unknown, setting it to default value 0
return RankingOutput(list(np.argsort(pred[:])),0)
def delta(self, y1, y2):
# y2 assumed to be ground truth, y1 predicted ranking
labels = y2.labelsfromranking()
pred = [0 for i in range(len(y1.ranking)) ]
for i in range(len(y1.ranking)):
pred[y1.ranking[i]] = -i
return 1.0- average_precision_score(labels, pred)
def psi(self, X, output):
# COMPLETE WITH YOUR CODE
def lai(self, X, Y):
# COMPLETE WITH YOUR CODE
où la fonction predict fait l’inférence de l’Eq. () en effectuant le tri des exemples précédemment indiqué, et la fonction delta s’appuie sur l’Average Precision (AP) pour calculer la dissimilarité entre y2 (supposée être la sortie donnée par la supervision) et y1 (la sortie prédite).
Mise en place de la fonction psi¶
On demande ici d’implémenter la fonction psi de l’Eq. ().
Bonus : pour avoir un calcul efficace, on pourra remarquer que la double somme dans le calcul de l’Eq. () revient à pondérer chaque exemple d’apprentissage par un facteur entier. Si on note par \(X\) la matrice des tous les exemples (taille \(N \times 784\)), on pourra donc calculer \(\alpha * X\), où \(\alpha\) est un vecteur colonne (taille \(N \times 1\)). On obtiendra \(\alpha\) de la manière suivante : pour chaque exemple \(d_i \in \oplus\) pertinent, on déterminera :
Le nombre d’exemples non pertinents \(N_-^b\) qui ont un rang inférieur à \(d_i\) (resp. \(N_-^a\) qui ont un rang supérieur à \(d_i\)).
Le poids de \(d_i\) sera \(N_-^a-N_-^b\).
Le poids de chaque exemple non pertinent ayant un rang inférieur à \(d_i\) sera incrémenté de 1.
Le poids de chaque exemple non pertinent ayant un rang supérieur à \(d_i\) sera décrémenté de 1.
Le vecteur final \(\Psi( \mathbf{x}, \mathbf{y})\) de l’Eq. () correspondra à sommer \(\alpha * X\) sur les lignes, pour obtenir un vecteur de taille 784.
Mise en place de la fonction lai¶
On rappelle que pour entraîner un modèle de prédiction structurée, il faut résoudre le problème du « Loss-Augmented Inference » (LAI). Dans le cas de l’ordonnancement, on dispose d’un unique exemple d’apprentissage \((\mathbf{\mathbf{x}},\mathbf{\mathbf{y^*}})\) et le LAI consiste en la maximisation suivante :
où \(\Psi(\mathbf{x}_i ,\mathbf{y} )\) est la feature map de ranking définie à l’Eq. (), et le loss \(\Delta(\mathbf{y}^*,\mathbf{y}) = 1-AP(\mathbf{y})\). La fonction lai prend en entrée la matrice \(X\) des données (taille \(N \times 784\)) et la sortie donnée par la supervision. On rappelle que le LAI peut être résolu dans ce cas de la manière suivante, en utilisant l’algorithme glouton optimal proposé dans [YFRJ07] :
On trie les exemples \(\oplus\) et \(\ominus\) par ordre de score décroissant. Pour cela on pourra utiliser le code suivant :
# Computing <w; x_i> for all examples
pred = np.matmul(X,self.w)
# Getting corresponding labels from ranking output Y
labels = Y.labelsfromranking()
# Dict structure
dict = {i : pred[i] for i in range(len(labels))}
iplus = np.where(np.array(labels[:])==1)[0]
iminus = np.where(np.array(labels[:])==0)[0]
nbPlus = len(iplus)
nbMinus = len(iminus)
nbTot = nbPlus+nbMinus
dictplus = {i:dict[i] for i in iplus}
dictminus = {i:dict[i] for i in iminus}
# Sorting dict for + examples and - examples
dictplus_s = sorted(dictplus.iteritems(), key=lambda (k,v): (v,k), reverse=True)
dictminus_s = sorted(dictminus.iteritems(), key=lambda (k,v): (v,k), reverse=True)
On va trouver l’insertion optimale de chacun des exemples \(\ominus\) dans la liste des \(\oplus\) triés pour donner la solution optimale au problème LAI. On rappelle que le \(j^{\grave{e}me}\) exemple \(\ominus\) trié va être placé à la position \(i^{*}\) des exemples \(\oplus\) triés, avec \(i^{*} = \underset{i} {arg\,max} ~\delta_j(i)\):
où \(s_k^p\) est le score du \(k^{\grave{e}me}\) exemple \(\oplus\) trié, et \(s_j^n\) est le score du \(j^{\grave{e}me}\) exemple \(\ominus\) trié. Le code suivant va permettre de calculer l’insertion optimale de l’Eq. () :
# Initializing list with + examples
list_lai = [dictplus_s[i][0] for i in range(len(dictplus_s))]
# Computing delta2 for each (+/-) pair in Eq 5
delta1 = 1.0/nbPlus* np.array( [[ ( float(j) / float(j+i) - (j-1.0)/(j+i-1.0)) -
( 2.0* (dictplus_s[i-1][1] - dictminus_s[j-1][1])/(nbMinus) ) for j in range(1,nbMinus+1) ] for i in range(1,nbPlus+1)])
delta2 = delta1
for i in range(nbPlus-2,-1,-1):
delta2[i,:] = delta2[i,:] + delta2[i+1,:]
# i* = argmax_i delta2 for all - examples
res = np.argmax(delta2,axis=0)
# If optimal value is <0, insert after the last + example
a = [delta2[res[j],j] for j in range(nbMinus)]
indexin = np.where(np.array(a[:])<0)[0]
res[indexin] +=1
# Creating the final list
for j in range(len(iminus)):
list_final.insert(res[j]+j, dictminus_s[j][0])
# Returning it as a RankingOutput class
return RankingOutput(list_lai,Y.nbPlus)
- YFRJ07
Yisong Yue, Thomas Finley, Filip Radlinski, and Thorsten Joachims. A support vector method for optimizing average precision. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR “07, 271–278. New York, NY, USA, 2007. ACM. doi:10.1145/1277741.1277790.