Deep Learning et Manifold Untangling¶
On va maintenant illustrer la capacité des réseaux de neurones profonds à apprendre des représentations internes capables de résoudre le problème connu sous le nom de « manifold untangling » en neuroscience, c’est à dire de séparer les exemples des différentes classes dans l’espace de représentations appris.
Pour cela, on va utiliser des outils de visualisation étudiés dans l’exercice 1. Ces même outils vont permettre de projeter en 2D les représentations internes des réseaux de neurones, ce qui va permettre d’analyser la séparabilité des points et des classes dans l’espace d’entrée et dans les espaces de représentions appris par les modèles.
Exercice 5 : Visualisation des représentations internes des réseaux de neurones¶
On va maintenant s’intéresser à visualisation de l’effet de « manifold untangling » permis par les réseaux de neurones.
Créer un script exo5.py dont l’objectif va être d’utiliser la méthode t-SNE de l’exercice 1 pour projeter les couches cachés des réseaux de neurones dans un espace de dimension 2, ce qui permettra de visualiser la distribution des représentations internes et des labels.
Commencer par charger le Perceptron entraîné avec
Kerasdans la partie précédente, en utilisant la méthodeloadModel(savename)suivante:
from keras.models import model_from_yaml
def loadModel(savename):
with open(savename+".yaml", "r") as yaml_file:
model = model_from_yaml(yaml_file.read())
print "Yaml Model ",savename,".yaml loaded "
model.load_weights(savename+".h5")
print "Weights ",savename,".h5 loaded "
return model
On pourra vérifier l’architecture du modèle chargé avec la méthode
summary().On pourra également évaluer les performances du modèle chargé sur la base de test de MNIST pour vérifier son comportement. N.B : il faudra avoir compilé le modèle au préalable.
On veut maintenant extraire la couche cachée (donc un vecteur de dimension 100) pour chacune des images de la base de test.
Pour cela,on va utiliser la méthode
model.pop()(permettant de supprimer la couche au sommet du modèle) deux fois (on supprime la couche d’activation softmax et la couche complètement connectée). Ensuite on peut appliquer la méthodemodel.predict(X_test)sur l’ensemble des données de test.Finalement, on va utiliser la méthode t-SNE mise en place à l’exercice 1 pour visualiser les représentations internes des données.
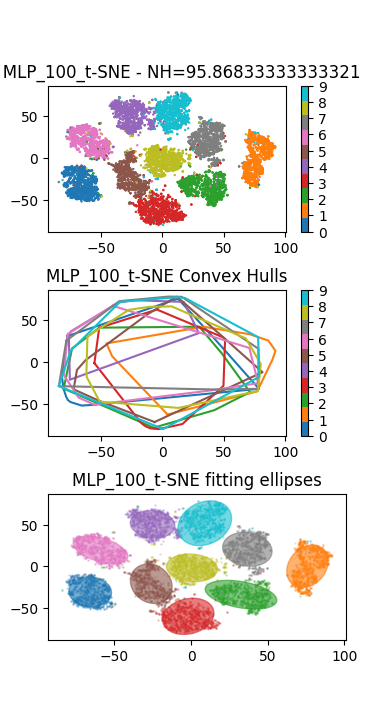
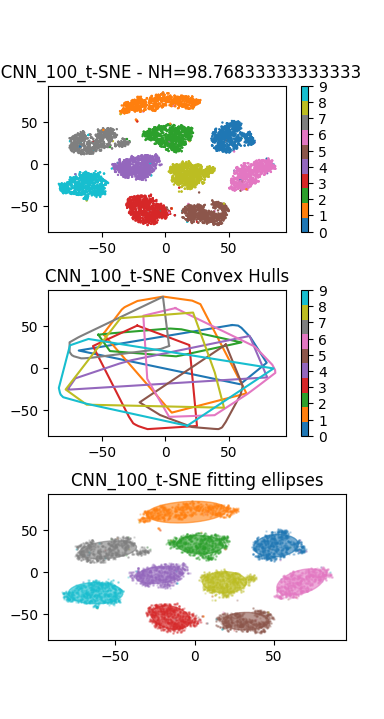
Conclure sur la capacité des réseaux de neurones à résoudre le problème du Manifold Untangling.
En plus du Perceptron précédent, on pourra visualiser les représentations internes apprises par un réseau convolutif de type LeNet de la partie précédente. Le résultat ci-dessous montre un résultat de visualisation obtenu avec un Perceptron (à gauche), et un réseau convolutif (à droite) :