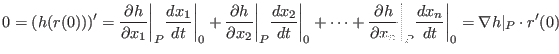Next: About this document ...
Daniel Porumbel
We take a first step towards showing how
the constrained optimum of a function has to satisfy
the (Karush-Kuhn-Tucker) KKT conditions. We will not prove that the presented KKT
conditions are necessary in the most general sense, because we will not discuss the regularity conditions
(Footnote 3). However, towards the end of this manuscript we will show the KKT
conditions are necessary and sufficient for a barrier linear program used in
interior point methods.
Consider differentiable functions
![]() and the program:
and the program:
Suppose this program has a constrained maximum at point
![]() such that
such that ![]() ,
, ![]() and
and ![]() .
We will show this point satisfies the KKT conditions by first addressing the
constraints individually and then joining the respective conditions. In fact, we
will see that the KKT conditions are verified by all local maxima of
.
We will show this point satisfies the KKT conditions by first addressing the
constraints individually and then joining the respective conditions. In fact, we
will see that the KKT conditions are verified by all local maxima of ![]() in above
program.
in above
program.
1) Let us first address the equality constraint individually.
Consider any (contour) curve
![]() on the surface of
on the surface of
![]() with
with
![]() and
and
![]() .
This curve has to satisfy
.
This curve has to satisfy ![]() . Differentiating this with respect to
. Differentiating this with respect to ![]() we obtain via the chain rule (and a notation abuse discussed below):
we obtain via the chain rule (and a notation abuse discussed below):
However, the gradient of ![]() in
in ![]() is thus perpendicular to (the tangent of) any curve1
is thus perpendicular to (the tangent of) any curve1![]() that belongs to the surface of
that belongs to the surface of
![]() . Consider now the
function
. Consider now the
function ![]() and
observe its derivative with respect to
and
observe its derivative with respect to ![]() in 0 needs to be zero, because
otherwise one could move away from
in 0 needs to be zero, because
otherwise one could move away from ![]() in some direction along
in some direction along ![]() and increase the value of
and increase the value of ![]() .
Using the chain rule as in (1),
we obtain:
.
Using the chain rule as in (1),
we obtain:
2) We now address the first inequality constraint individually.
Consider as above a curve
![]() such that
such that
![]() with
with
![]() and
and ![]() . We stated that we consider
. We stated that we consider
![]() . The intuition is that the curve starts at the constrained
optimum
. The intuition is that the curve starts at the constrained
optimum ![]() and then it goes inside (or on the surface of) the constraint. As
such, the right derivative in
and then it goes inside (or on the surface of) the constraint. As
such, the right derivative in ![]() at point 0 satisfies:
at point 0 satisfies:
![]() .
Using the chain rule as in (1), we obtain:
.
Using the chain rule as in (1), we obtain:
Since ![]() is a constrained maximum, the function
is a constrained maximum, the function ![]() needs to be decreasing
as we move along
needs to be decreasing
as we move along ![]() from
from ![]() . This means that the right
derivative in 0 satisfies
. This means that the right
derivative in 0 satisfies
![]() .
Analogously to (2), we obtain:
.
Analogously to (2), we obtain:
This shows there exists some ![]() such that
such that
![]() , because
, because
![]() is the only direction such that
(2) holds for all feasible curves
is the only direction such that
(2) holds for all feasible curves ![]() . Observe we need to state
. Observe we need to state
![]() because otherwise the signs of the above inequalities would be
reversed.
because otherwise the signs of the above inequalities would be
reversed.
3) We now address the last inequality constraint. Since
![]() , the evolution of
, the evolution of ![]() around
around ![]() does not depend on
does not depend on ![]() . We can
ignore
. We can
ignore ![]() , as it plays no role in ensuring that
, as it plays no role in ensuring that ![]() is a local optimum.
is a local optimum.
Let us now join the arguments of 1), 2) and 3).
The point 1) shows that any
objective function ![]() such that
such that
![]() (with
(with
![]() ) allows
) allows ![]() to be maximum. By moving along any curve
to be maximum. By moving along any curve ![]() on the level
surface of
on the level
surface of ![]() , we have
, we have
![]() .
.
The point 2) shows that any objective function ![]() such that
such that
![]() (with
(with ![]() ) allows
) allows ![]() to be maximum.
By moving along any curve
to be maximum.
By moving along any curve ![]() feasible with respect to
feasible with respect to
![]() , we
have
, we
have
![]() : by going inside the constraint, the objective
function decreases.
: by going inside the constraint, the objective
function decreases.
Consider now ![]() . By moving from
. By moving from ![]() along any curve
along any curve ![]() with
with ![]() that satisfies all constraints, we have
that satisfies all constraints, we have
![]() , because the first term yields
, because the first term yields
![]() given that
given that ![]() is feasible with respect to
is feasible with respect to ![]() and
the second term yields
and
the second term yields
![]() because
because ![]() is feasible with respect to
is feasible with respect to ![]() .
.
We conclude that ![]() can be a constrained maximum for any
objective
function
whose gradient
has the form:3
can be a constrained maximum for any
objective
function
whose gradient
has the form:3
The joining argument can be generalized to more functions
![]() and
and
![]() and we obtain the KKT conditions:
and we obtain the KKT conditions:
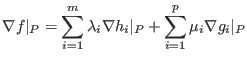
The first condition is often expressed as follows: the stationary point of the
Lagrangian
![]() in
in ![]() is zero. This condition can also be found by applying the Lagrangean
duality and by writing the Wolfe dual problem.
is zero. This condition can also be found by applying the Lagrangean
duality and by writing the Wolfe dual problem.
Notice that if all functions are linear, it is superfluous to evaluate the
gradient in ![]() , because the value of the gradient is the same in all points.
, because the value of the gradient is the same in all points.
(1,0)100
We now give a full proof of the KKT conditions for the following barrier problem
used by Interior Point Methods (IPMs) for linear programming (supposing the rows
![]() are linearly independent because otherwise they can be filtered).
are linearly independent because otherwise they can be filtered).
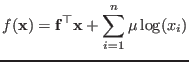 |
||
There is no chance of finding an optimum solution
![]() with some
with some ![]() close
to zero, because the log function exploses when its argument approaches zero.
Since all involved functions are convex, this program needs to have a unique solution
close
to zero, because the log function exploses when its argument approaches zero.
Since all involved functions are convex, this program needs to have a unique solution
![]() of minimum cost. We can prove that the KKT conditions are necessary and
sufficient to certify
of minimum cost. We can prove that the KKT conditions are necessary and
sufficient to certify
![]() is the optimal solution. The KKT conditions
discussed above actually reduce to:
is the optimal solution. The KKT conditions
discussed above actually reduce to:
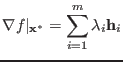
The necessity Take the optimal
![]() . The second condition is
clearly necessary from the definition of
. The second condition is
clearly necessary from the definition of
![]() . We prove the first condition
by contradiction. Assume for the sake of contradiction that
. We prove the first condition
by contradiction. Assume for the sake of contradiction that
![]() can not be written as a linear combination of vectors
can not be written as a linear combination of vectors
![]() ,
,
![]() ,
,
![]()
![]() . This means we can write
. This means we can write
![]() , where
, where
![]() belongs to the null space of
belongs to the null space of
![]() ,
,
![]() ,
,
![]()
![]() , i.e.,
, i.e.,
![]() .
Let us check what happens if one moves from
.
Let us check what happens if one moves from
![]() back or forward along
direction
back or forward along
direction ![]() . For this, it is enough to study the function
. For this, it is enough to study the function
![]() .
Using the chain rule, we can calculate
.
Using the chain rule, we can calculate
![]() . By taking a sufficiently
small
step from
. By taking a sufficiently
small
step from
![]() towards
towards
![]() , the function
, the function ![]() becomes smaller and the
constraints
becomes smaller and the
constraints ![]() (
(
![]() ) remain valid. This is a contradiction.
) remain valid. This is a contradiction.
The sufficiency For the sake of contradiction, we assume there is
some feasible
![]() such that
such that
![]() that satisfies
both KKT conditions, i.e,
that satisfies
both KKT conditions, i.e,
![]() is primal feasible at it can be written
is primal feasible at it can be written
![]() for some
for some
![]() .
Let us define the Lagrangian
.
Let us define the Lagrangian
![]() . Considering this fixed
. Considering this fixed
![]() indicated above, this Lagrangian function is convex in
the variables
indicated above, this Lagrangian function is convex in
the variables ![]() . Given that
. Given that
![]() , we obtain that
, we obtain that
![]() has to be the unique stationary point of the Lagrangian function in
has to be the unique stationary point of the Lagrangian function in ![]() , and
so,
, and
so,
![]() has to be the
unique minimizer of the Lagrangian.
This is a contradiction, because we have
has to be the
unique minimizer of the Lagrangian.
This is a contradiction, because we have
![]() .
.