TP 01 : Apprentissage incrémental / données en flot¶
Ce TP est à faire sous Python, en utilisant le paquetage sklearn.
1. Oubli catastrophique en dimension 2¶
Dans cette partie du TP nous allons investiguer sous Python le phénomène d’oubli catastrophique évoqué dans la première partie du cours, pour un classifieur en dimension 2.
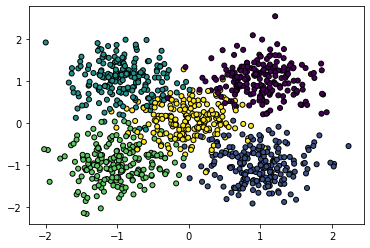
1. Commencez par créer un jeu de données contenant 5 classes relativement bien séparées en 2 dimensions, par exemple chacune tirée d’une distribution gaussienne. Prenez 200 échantillons par classe. Affichez le nuage de données. Supposons que les classes sont numérotées 0, 1, 2, 3 et 4.
Conseil : regardez sklearn.datasets.make_blobs()…
Exemple de résultat :
Générez un jeu de données de test et un autre pour l’entrainement.
2. Apprenez un sklearn.neural_network.MLPClassifier sur le jeu de données avec une seule couche cachée de 20 neurones. Affichez la surface de décision : d’abord on discrétise le domaine bidimensionnel avec un pas constant et ensuite on évalue le modèle sur chaque point de la grille. Affichez le score (accuracy) classe par classe. Utilisez la méthode partial_fit(…) pour apprendre. Pourquoi ? Attention : la méthode partial_fit() passe une seule fois dans les données, pour converger il faut itérer partial_fit() plusieurs fois (un nombre d’itérations de 300 est suffisant).
Exemple de résultat :
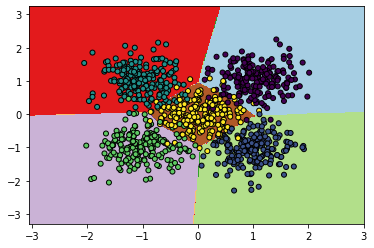
Accuracy : [0.975 0.935 0.955 0.96 0.835]
3. Générez un batch d’apprentissage contenant seulement les classes 0 et 1. Continuez l’apprentissage du classifieur avec ces données. Affichez la surface de décision. Que constatez-vous ? Quel est le score (accuracy) du classifieur classe par classe ?
Exemple de résultat :
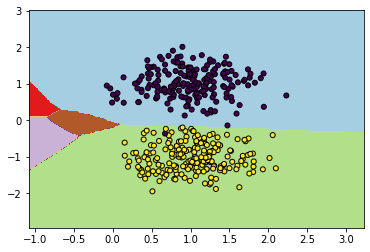
Accuracy : [1. 0.985 0.34 0.63 0.18]
Refaire l’exercice avec les classes 0, 1, 2, et ensuite 0, 1, 2, 3.
2. Simulation d’un apprentissage en flux¶
Dans cette 2eme partie du TP nous allons regarder la dégradation du score d’un MLPClassifier dans un environnement où une des classes disparait du flot à partir d’un moment donné.
On considère trois classes en dimension 150. Commencez par créer un jeu de test contenant 100 éléments par classe (blobs gaussiens).
Ensuite programmez une boucle de 100 itérations qui à chaque itération :
Génère un batch d’apprentissage avec 50 éléments pour chaque classe présente.
Entraîne le classifieur sur le batch généré (avec partial_fit() une seule fois)
Calcule l’accuracy pour chaque classe pour le batch courant
Passer au batch suivant
Conseil : mettez le code dans une fonction pour pouvoir l’appeler avec des paramètres différents.
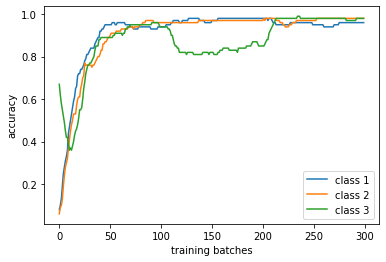
A la fin de la boucle vous obtenez la séquence des scores du classifieurs sur chaque classe. Affichez-la. Commencez par une étape ou les trois classes sont présentes, ensuite une deuxième étape ou une des classes disparaît complètement dans les batches d’apprentissage et ensuite une dernière étape ou les trois classes sont présentes de nouveau. A la fin affichez les courbes des score classe par classe. Expliquez.
Si à l’étape deux, la 2eme classe ne disparaît pas complètement (elle a juste moins d’échantillons que les autres classes), quel nombre d’échantillons sont nécessaires pour éviter le phénomène d’oubli catastrophique ?
Exemple de résultat (classe 3 disparaît complètement du flot) :
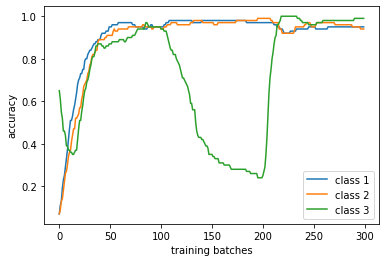
Exemple de résultat (il reste 10 échantillons de la classe 3 dans le flot, les autres classes ont 50 échantillons) :