Travaux pratiques : espace latent des GAN¶
Cette séance de travaux pratiques sert d’illustration à l’exploration d’un espace latent et à l’évaluation des modèles génératifs. L’objectif est de mieux comprendre comment manipuler et interpréter les codes latents.
Pour cette séance, nous allons utiliser le jeu de données de chiffres manuscrits MNIST mais les méthodes étudiées s’adaptent à n’importe quel ensemble d’observations.
# Dernière version de torchvision pour MNIST
%pip install -U torchvision
from six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from torch import nn
Qualité de la distribution apprise¶
Pour gagner du temps, nous allons récupérer des modèles préentraînés sur MNIST. En particulier nous allons réutiliser un générateur de DCGAN (Deep Convolutional GAN) entraîné sur MNIST, ainsi qu’une classifieur entraîné sur les observations d’apprentissage.
Note : ces modèles ont été mis à disposition par Chandan Singh, doctorant à UC Berkeley.
# Téléchargement des fichiers de poids
!wget -nc https://raw.githubusercontent.com/csinva/gan-vae-pretrained-pytorch/master/mnist_dcgan/weights/netG_epoch_99.pth
!wget -nc https://raw.githubusercontent.com/csinva/gan-vae-pretrained-pytorch/master/mnist_classifier/weights/lenet_epoch%3D12_test_acc%3D0.991.pth -O lenet.pth
Le classifieur est une architecture convolutive simple dite « LeNet5 ». Le code ci-dessous permet de construire un tel modèle.
from collections import OrderedDict
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.convnet = nn.Sequential(OrderedDict([
('c1', nn.Conv2d(1, 6, kernel_size=(5, 5))),
('relu1', nn.ReLU()),
('s2', nn.MaxPool2d(kernel_size=(2, 2), stride=2)),
('c3', nn.Conv2d(6, 16, kernel_size=(5, 5))),
('relu3', nn.ReLU()),
('s4', nn.MaxPool2d(kernel_size=(2, 2), stride=2)),
('c5', nn.Conv2d(16, 120, kernel_size=(5, 5))),
('relu5', nn.ReLU()),
('flatten', nn.Flatten())
]))
self.fc = nn.Sequential(OrderedDict([
('f6', nn.Linear(120, 84)),
('relu6', nn.ReLU()),
('f7', nn.Linear(84, 10)),
('sig7', nn.LogSoftmax(dim=-1))
]))
def forward(self, img):
output = self.convnet(img)
output = self.fc(output)
return output
lenet = LeNet5().eval()
lenet.load_state_dict(torch.load('lenet.pth'))
Le générateur est un réseau convolutif à 5 couches. La dimension de l’espace latent de ce modèle préappris est de 100. Les codes \(z\) ont été échantillonnés lors de l’apprentissage selon une loi normale.
class Generator(nn.Module):
def __init__(self, out_channels=1, latent_dim=100, n_planes=64):
super(Generator, self).__init__()
self.main = nn.Sequential(
# Le code Z est déconvolué
nn.ConvTranspose2d(latent_dim, n_planes * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(n_planes * 8),
nn.ReLU(inplace=True),
# Activations (n_planes*8) x 4 x 4
nn.ConvTranspose2d(n_planes * 8, n_planes * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(n_planes * 4),
nn.ReLU(inplace=True),
# Activations (n_planes*4) x 8 x 8
nn.ConvTranspose2d(n_planes * 4, n_planes * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(n_planes * 2),
nn.ReLU(inplace=True),
# Activations (n_planes*2) x 16 x 16
nn.ConvTranspose2d(n_planes * 2, n_planes, 4, 2, 1, bias=False),
nn.BatchNorm2d(n_planes),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(n_planes, out_channels, kernel_size=1, stride=1, padding=2, bias=False),
nn.Tanh()
)
def forward(self, input):
input = input.unsqueeze(-1).unsqueeze(-1)
output = self.main(input)
return output
G = Generator().eval()
G.load_state_dict(torch.load('netG_epoch_99.pth'), map_location=torch.device("cpu"))
Question
En utilisant le générateur, écrivez une fonction code2image qui
prend en entrée un ou plusieurs codes z (de dimensions
\((n, 100, 1, 1)\)) et renvoie un tenseur d’autant d’images (de
dimensions \((n, h, w)\)). Générez et affichez quelques images de
chiffres manuscrits synthétiques.
Dans cette section, nous souhaitons tout d’abord regarder la distribution des classes dans les chiffres synthétiques. Nous pouvons déjà regarder la distribution des classes dans la base d’images MNIST :
from torchvision.datasets import MNIST
from torchvision import transforms
from tqdm.notebook import tqdm, trange
mnist = MNIST(root="./mnist", train=True, download=True)
true_labels = np.array([label for _, label in mnist], dtype=int)
# Calcul du nombre d'occurrences de chaque valeur
occurrences = np.bincount(true_labels)
for i, count in enumerate(occurrences):
plt.bar(i, count)
plt.xticks(range(0, 10))
plt.title("Nombre d'exemples par classe (MNIST)")
plt.show()
Pour les données synthétiques produites par le générateur, nous n’avons pas l’information de la classe (le DCGAN utilisé pour générer ces observations n’est pas conditionnel). À défaut, nous pouvons toutefois utiliser un classifieur comme proxy pour étiqueter les images générées.
Le modèle LeNet5 prend en entrée des images de taille
\(32\times32\). Il est donc nécessaire de redimensionner les images
obtenues avec la fonction code2image qui produit des matrices
\(28\times28\). Vous pouvez utiliser la transformation ci-dessous à
cette fin :
from torchvision import transforms
resize = transforms.Resize(32)
# Sur une image PIL
print("-> Redimensionnement d'une image PIL")
print(mnist[0][0])
print(resize(mnist[0][0]))
# Sur un Tensor (dim n, w, h)
print("-> Redimensionnement d'un tenseur PyTorch")
tensor = torch.Tensor(image).unsqueeze(0)
print(tensor.shape)
print(resize(tensor).shape)
Question
Échantillonnez 1000 codes dans l’espace latent. Pour chaque code, calculez l’image synthétique correspondante et utilisez LeNet5 préentraîné pour obtenir la classe de chiffre associée. Affichez dans un histogramme le nombre d’occurrences de chaque classe de chiffres. Que constatez-vous ? Vérifiez si besoin avec les données réelles du jeu de données MNIST.
Séparabilité des classes¶
Une façon d’évaluer si le modèle reproduit correctement la structure de l’espace des données est considérer les frontières entre classes. Par exemple, les images correspondant au chiffre 0 générées par le GAN doivent se situer approximativement au même endroit dans l’espace des observations que les chiffres 0 réels.
Pour mesurer cette propriété, une façon de faire est la suivante : - étiqueter (manuellement ou avec un classifieur) \(n\) images synthétiques - apprendre une SVM linéaire sur le jeu de données d’entraînement - évaluer cette SVM linéaire un jeu de données de test - évaluer la SVM linéaire sur les données synthétiques
La SVM linéaire va trouver des hyperplans séparateurs dans l’espace des observations. Si le GAN conserve la structure de la distribution des données, alors ces hyperplans doivent également séparer les données synthétiques.
Question
Appliquez cette méthode aux données ci-dessous. Que peut-on déduire des scores relatifs de la SVM sur le jeu de test réel et sur le jeu de test synthétique ?
Exploration de l’espace latent et contrôle de la génération¶
Question
Que se passe-t-il quand la norme de \(z\) devient très grande ?
Question
En utilisant les images synthétiques obtenues précédemment et leurs pseudo-étiquettes, calculez pour chaque classe (chiffre) le barycentre \(m_i\) de celle-ci dans l’espace latent.
On définit pour chaque paire de classses \((i,j)\) la direction \(d_{i,j} = m_j - m_i\). Choisissez deux classes (par exemple 0 et 8) et calculez la direction. Calculez différents codes \(z' = z + \alpha \cdot d_{i,j}\) pour plusieurs valeurs de \(\alpha\) et générez les images correspondantes. On choisira un \(z\) qui correspond au chiffre de départ (par exemple 0). Comment l’image se transforme-t-elle lorsque l’on suit la direction choisie ?
Lorsque les codes \(z\) de l’espace latent sont échantillonnés selon une loi normale plutôt qu’une loi uniforme, il est en général considéré préférable d’utiliser une interpolation sphérique plutôt qu’une interpolation linéaire. En effet, pour une gaussienne, les courbes d’iso-probabilité suivent les grands cercles.
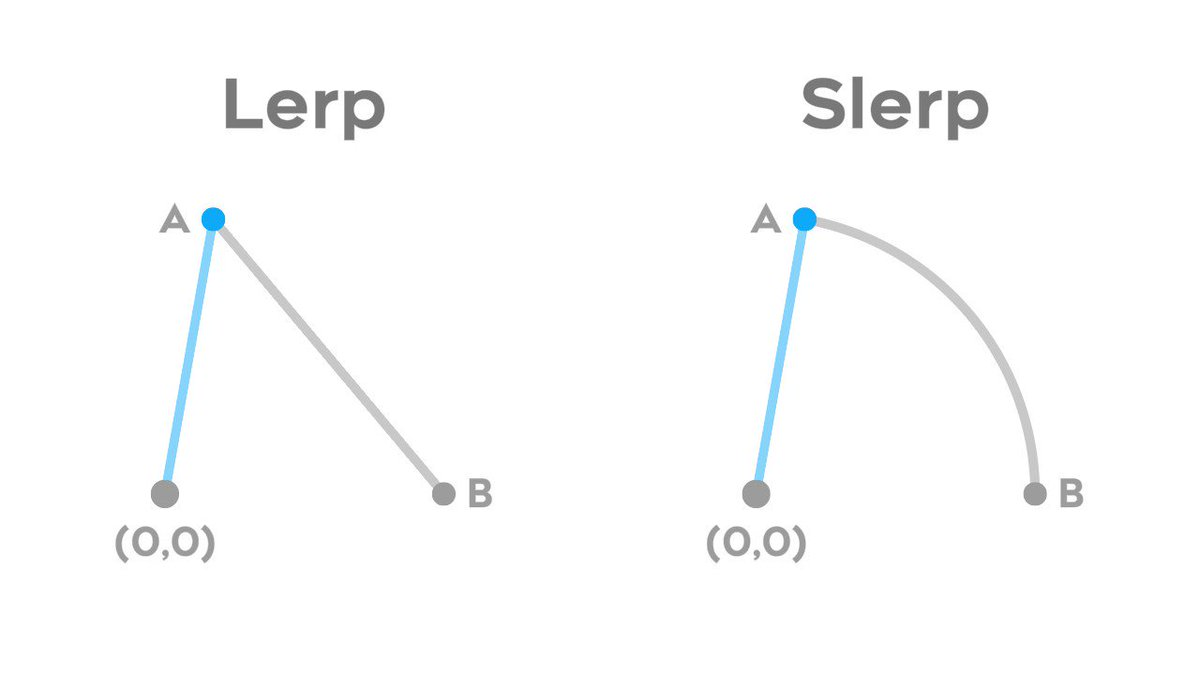
La fonction slerp ci-dessous implémente une telle interpolation
selon le grand cercle :
def slerp(val, low, high):
omega = np.arccos(np.clip(np.dot(low/np.linalg.norm(low), high/np.linalg.norm(high)), -1, 1))
so = np.sin(omega)
if so == 0:
return (1.0-val) * low + val * high # L'Hopital's rule/LERP
return np.sin((1.0-val)*omega) / so * low + np.sin(val*omega) / so * high
Question
Appliquez la même technique mais en utilisant une interpolation sphérique plutôt qu’une interpolation linéaire. Visualisez la norme des codes interpolés et comparez là à celle des codes obtenus par interpolation linéaires. Commentez.
Visualisez les images interpolées. Qu’en pensez-vous ?